 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeng Zhang
pFedAFM: Adaptive Feature Mixture for Batch-Level Personalization in Heterogeneous Federated Learning
Apr 27, 2024
Model-heterogeneous personalized federated learning (MHPFL) enables FL clients to train structurally different personalized models on non-independent and identically distributed (non-IID) local data. Existing MHPFL methods focus on achieving client-level personalization, but cannot address batch-level data heterogeneity. To bridge this important gap, we propose a model-heterogeneous personalized Federated learning approach with Adaptive Feature Mixture (pFedAFM) for supervised learning tasks. It consists of three novel designs: 1) A sharing global homogeneous small feature extractor is assigned alongside each client's local heterogeneous model (consisting of a heterogeneous feature extractor and a prediction header) to facilitate cross-client knowledge fusion. The two feature extractors share the local heterogeneous model's prediction header containing rich personalized prediction knowledge to retain personalized prediction capabilities. 2) An iterative training strategy is designed to alternately train the global homogeneous small feature extractor and the local heterogeneous large model for effective global-local knowledge exchange. 3) A trainable weight vector is designed to dynamically mix the features extracted by both feature extractors to adapt to batch-level data heterogeneity. Theoretical analysis proves that pFedAFM can converge over time. Extensive experiments on 2 benchmark datasets demonstrate that it significantly outperforms 7 state-of-the-art MHPFL methods, achieving up to 7.93% accuracy improvement while incurring low communication and computation costs.
Real-Time 4K Super-Resolution of Compressed AVIF Images. AIS 2024 Challenge Survey
Apr 25, 2024This paper introduces a novel benchmark as part of the AIS 2024 Real-Time Image Super-Resolution (RTSR) Challenge, which aims to upscale compressed images from 540p to 4K resolution (4x factor) in real-time on commercial GPUs. For this, we use a diverse test set containing a variety of 4K images ranging from digital art to gaming and photography. The images are compressed using the modern AVIF codec, instead of JPEG. All the proposed methods improve PSNR fidelity over Lanczos interpolation, and process images under 10ms. Out of the 160 participants, 25 teams submitted their code and models. The solutions present novel designs tailored for memory-efficiency and runtime on edge devices. This survey describes the best solutions for real-time SR of compressed high-resolution images.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
Adapting to Covariate Shift in Real-time by Encoding Trees with Motion Equations
Apr 08, 2024Input distribution shift presents a significant problem in many real-world systems. Here we present Xenovert, an adaptive algorithm that can dynamically adapt to changes in input distribution. It is a perfect binary tree that adaptively divides a continuous input space into several intervals of uniform density while receiving a continuous stream of input. This process indirectly maps the source distribution to the shifted target distribution, preserving the data's relationship with the downstream decoder/operation, even after the shift occurs. In this paper, we demonstrated how a neural network integrated with Xenovert achieved better results in 4 out of 5 shifted datasets, saving the hurdle of retraining a machine learning model. We anticipate that Xenovert can be applied to many more applications that require adaptation to unforeseen input distribution shifts, even when the distribution shift is drastic.
pFedMoE: Data-Level Personalization with Mixture of Experts for Model-Heterogeneous Personalized Federated Learning
Feb 11, 2024Federated learning (FL) has been widely adopted for collaborative training on decentralized data. However, it faces the challenges of data, system, and model heterogeneity. This has inspired the emergence of model-heterogeneous personalized federated learning (MHPFL). Nevertheless, the problem of ensuring data and model privacy, while achieving good model performance and keeping communication and computation costs low remains open in MHPFL. To address this problem, we propose a model-heterogeneous personalized Federated learning with Mixture of Experts (pFedMoE) method. It assigns a shared homogeneous small feature extractor and a local gating network for each client's local heterogeneous large model. Firstly, during local training, the local heterogeneous model's feature extractor acts as a local expert for personalized feature (representation) extraction, while the shared homogeneous small feature extractor serves as a global expert for generalized feature extraction. The local gating network produces personalized weights for extracted representations from both experts on each data sample. The three models form a local heterogeneous MoE. The weighted mixed representation fuses generalized and personalized features and is processed by the local heterogeneous large model's header with personalized prediction information. The MoE and prediction header are updated simultaneously. Secondly, the trained local homogeneous small feature extractors are sent to the server for cross-client information fusion via aggregation. Overall, pFedMoE enhances local model personalization at a fine-grained data level, while supporting model heterogeneity.
An Intraoperative Force Perception and Signal Decoupling Method on Capsulorhexis Forceps
Nov 14, 2023Force perception on medical instruments is critical for understanding the mechanism between surgical tools and tissues for feeding back quantized force information, which is essential for guidance and supervision in robotic autonomous surgery. Especially for continuous curvilinear capsulorhexis (CCC), it always lacks a force measuring method, providing a sensitive, accurate, and multi-dimensional measurement to track the intraoperative force. Furthermore, the decoupling matrix obtained from the calibration can decorrelate signals with acceptable accuracy, however, this calculating method is not a strong way for thoroughly decoupling under some sensitive measuring situations such as the CCC. In this paper, a three-dimensional force perception method on capsulorhexis forceps by installing Fiber Bragg Grating sensors (FBGs) on prongs and a signal decoupling method combined with FASTICA is first proposed to solve these problems. According to experimental results, the measuring range is up to 1 N (depending on the range of wavelength shifts of sensors) and the resolution on x, y, and z axial force is 0.5, 0.5, and 2 mN separately. To minimize the coupling effects among sensors on measuring multi-axial forces, by unitizing the particular parameter and scaling the corresponding vector in the mixing matrix and recovered signals from FastICA, the signals from sensors can be decorrelated and recovered with the errors on axial forces decreasing up to 50% least. The calibration and calculation can also be simplified with half the parameters involved in the calculation. Experiments on thin sheets and in vitro porcine eyes were performed, and it was found that the tearing forces were stable and the time sequence of tearing forceps was stationary or first-order difference stationary during roughly circular crack propagating.
Symmetrical SyncMap for Imbalanced General Chunking Problems
Oct 16, 2023Recently, SyncMap pioneered an approach to learn complex structures from sequences as well as adapt to any changes in underlying structures. This is achieved by using only nonlinear dynamical equations inspired by neuron group behaviors, i.e., without loss functions. Here we propose Symmetrical SyncMap that goes beyond the original work to show how to create dynamical equations and attractor-repeller points which are stable over the long run, even dealing with imbalanced continual general chunking problems (CGCPs). The main idea is to apply equal updates from negative and positive feedback loops by symmetrical activation. We then introduce the concept of memory window to allow for more positive updates. Our algorithm surpasses or ties other unsupervised state-of-the-art baselines in all 12 imbalanced CGCPs with various difficulties, including dynamically changing ones. To verify its performance in real-world scenarios, we conduct experiments on several well-studied structure learning problems. The proposed method surpasses substantially other methods in 3 out of 4 scenarios, suggesting that symmetrical activation plays a critical role in uncovering topological structures and even hierarchies encoded in temporal data.
* 40 pages, 19 figures
Decompose Semantic Shifts for Composed Image Retrieval
Sep 18, 2023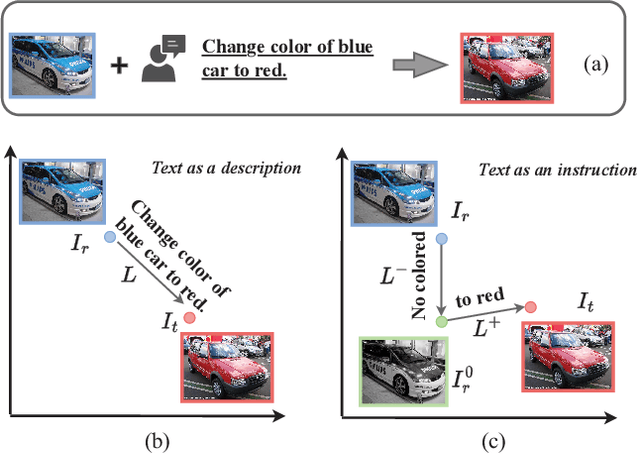
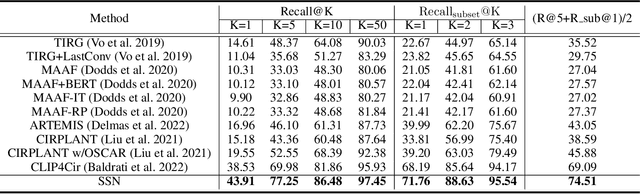

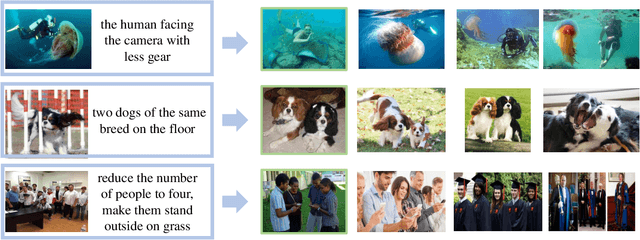
Composed image retrieval is a type of image retrieval task where the user provides a reference image as a starting point and specifies a text on how to shift from the starting point to the desired target image. However, most existing methods focus on the composition learning of text and reference images and oversimplify the text as a description, neglecting the inherent structure and the user's shifting intention of the texts. As a result, these methods typically take shortcuts that disregard the visual cue of the reference images. To address this issue, we reconsider the text as instructions and propose a Semantic Shift network (SSN) that explicitly decomposes the semantic shifts into two steps: from the reference image to the visual prototype and from the visual prototype to the target image. Specifically, SSN explicitly decomposes the instructions into two components: degradation and upgradation, where the degradation is used to picture the visual prototype from the reference image, while the upgradation is used to enrich the visual prototype into the final representations to retrieve the desired target image. The experimental results show that the proposed SSN demonstrates a significant improvement of 5.42% and 1.37% on the CIRR and FashionIQ datasets, respectively, and establishes a new state-of-the-art performance. Codes will be publicly available.
Refining 6-DoF Grasps with Context-Specific Classifiers
Aug 14, 2023
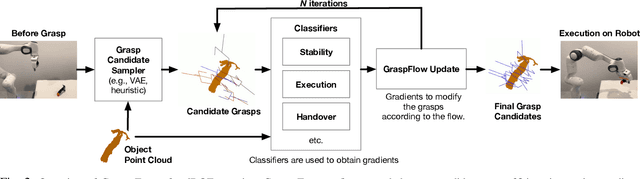
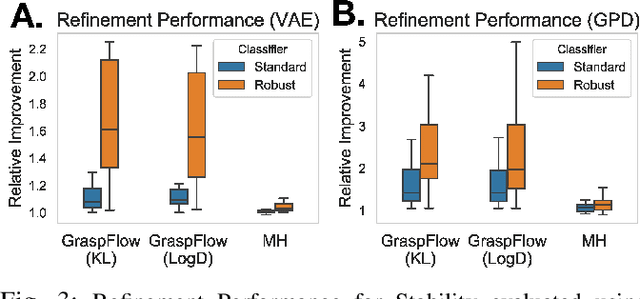
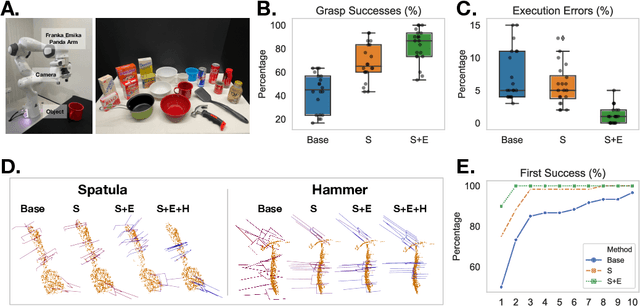
In this work, we present GraspFlow, a refinement approach for generating context-specific grasps. We formulate the problem of grasp synthesis as a sampling problem: we seek to sample from a context-conditioned probability distribution of successful grasps. However, this target distribution is unknown. As a solution, we devise a discriminator gradient-flow method to evolve grasps obtained from a simpler distribution in a manner that mimics sampling from the desired target distribution. Unlike existing approaches, GraspFlow is modular, allowing grasps that satisfy multiple criteria to be obtained simply by incorporating the relevant discriminators. It is also simple to implement, requiring minimal code given existing auto-differentiation libraries and suitable discriminators. Experiments show that GraspFlow generates stable and executable grasps on a real-world Panda robot for a diverse range of objects. In particular, in 60 trials on 20 different household objects, the first attempted grasp was successful 94% of the time, and 100% grasp success was achieved by the second grasp. Moreover, incorporating a functional discriminator for robot-human handover improved the functional aspect of the grasp by up to 33%.
A Survey on Reservoir Computing and its Interdisciplinary Applications Beyond Traditional Machine Learning
Jul 27, 2023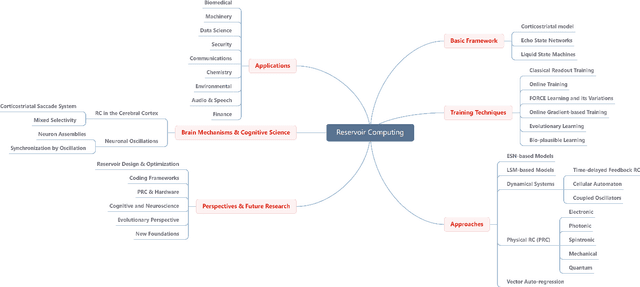

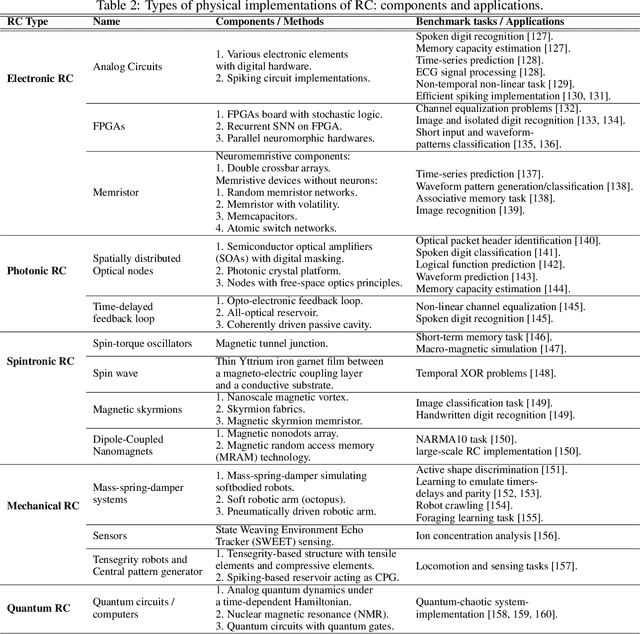
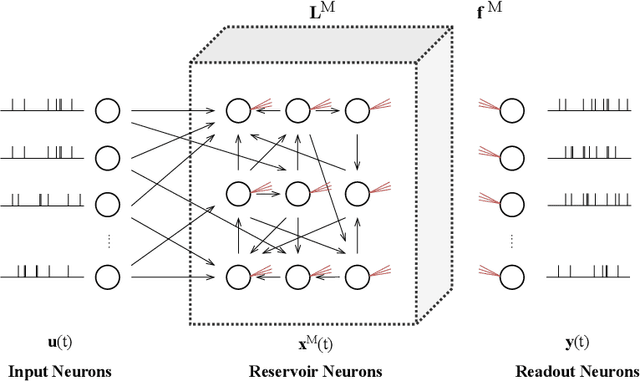
Reservoir computing (RC), first applied to temporal signal processing, is a recurrent neural network in which neurons are randomly connected. Once initialized, the connection strengths remain unchanged. Such a simple structure turns RC into a non-linear dynamical system that maps low-dimensional inputs into a high-dimensional space. The model's rich dynamics, linear separability, and memory capacity then enable a simple linear readout to generate adequate responses for various applications. RC spans areas far beyond machine learning, since it has been shown that the complex dynamics can be realized in various physical hardware implementations and biological devices. This yields greater flexibility and shorter computation time. Moreover, the neuronal responses triggered by the model's dynamics shed light on understanding brain mechanisms that also exploit similar dynamical processes. While the literature on RC is vast and fragmented, here we conduct a unified review of RC's recent developments from machine learning to physics, biology, and neuroscience. We first review the early RC models, and then survey the state-of-the-art models and their applications. We further introduce studies on modeling the brain's mechanisms by RC. Finally, we offer new perspectives on RC development, including reservoir design, coding frameworks unification, physical RC implementations, and interaction between RC, cognitive neuroscience and evolution.