 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWei Deng
Real-Time 4K Super-Resolution of Compressed AVIF Images. AIS 2024 Challenge Survey
Apr 25, 2024
This paper introduces a novel benchmark as part of the AIS 2024 Real-Time Image Super-Resolution (RTSR) Challenge, which aims to upscale compressed images from 540p to 4K resolution (4x factor) in real-time on commercial GPUs. For this, we use a diverse test set containing a variety of 4K images ranging from digital art to gaming and photography. The images are compressed using the modern AVIF codec, instead of JPEG. All the proposed methods improve PSNR fidelity over Lanczos interpolation, and process images under 10ms. Out of the 160 participants, 25 teams submitted their code and models. The solutions present novel designs tailored for memory-efficiency and runtime on edge devices. This survey describes the best solutions for real-time SR of compressed high-resolution images.
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
Can multiple-choice questions really be useful in detecting the abilities of LLMs?
Mar 28, 2024
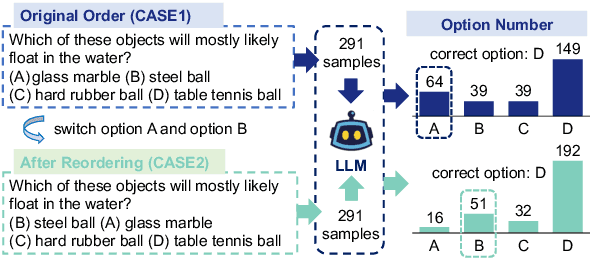
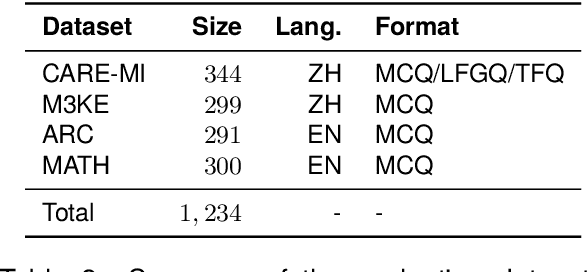

Multiple-choice questions (MCQs) are widely used in the evaluation of large language models (LLMs) due to their simplicity and efficiency. However, there are concerns about whether MCQs can truly measure LLM's capabilities, particularly in knowledge-intensive scenarios where long-form generation (LFG) answers are required. The misalignment between the task and the evaluation method demands a thoughtful analysis of MCQ's efficacy, which we undertake in this paper by evaluating nine LLMs on four question-answering (QA) datasets in two languages: Chinese and English. We identify a significant issue: LLMs exhibit an order sensitivity in bilingual MCQs, favoring answers located at specific positions, i.e., the first position. We further quantify the gap between MCQs and long-form generation questions (LFGQs) by comparing their direct outputs, token logits, and embeddings. Our results reveal a relatively low correlation between answers from MCQs and LFGQs for identical questions. Additionally, we propose two methods to quantify the consistency and confidence of LLMs' output, which can be generalized to other QA evaluation benchmarks. Notably, our analysis challenges the idea that the higher the consistency, the greater the accuracy. We also find MCQs to be less reliable than LFGQs in terms of expected calibration error. Finally, the misalignment between MCQs and LFGQs is not only reflected in the evaluation performance but also in the embedding space. Our code and models can be accessed at https://github.com/Meetyou-AI-Lab/Can-MC-Evaluate-LLMs.
Faceptor: A Generalist Model for Face Perception
Mar 14, 2024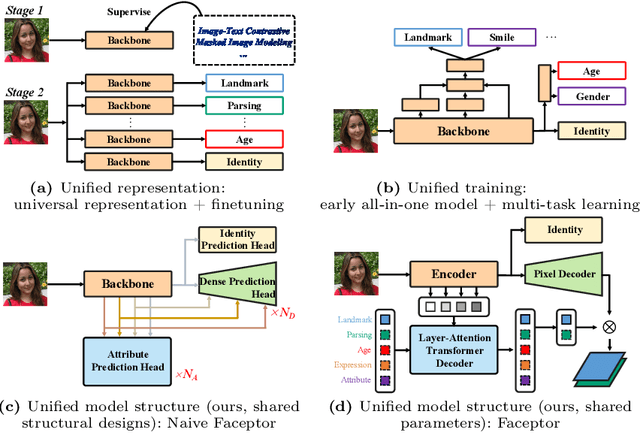
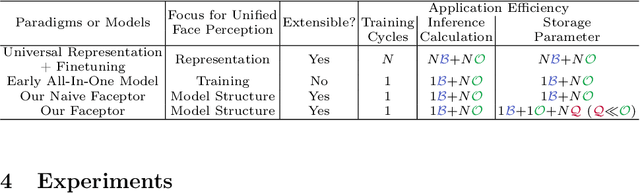
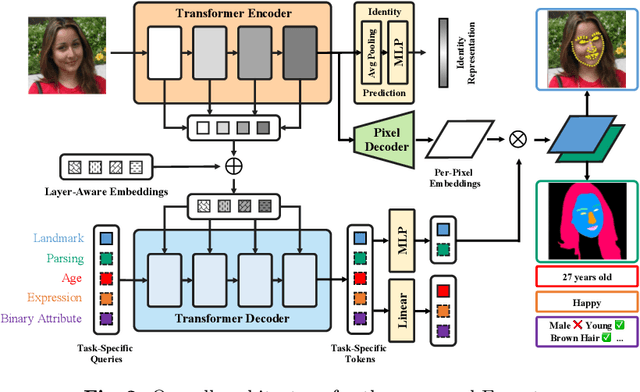
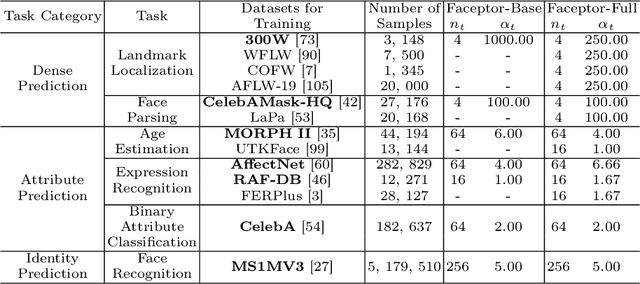
With the comprehensive research conducted on various face analysis tasks, there is a growing interest among researchers to develop a unified approach to face perception. Existing methods mainly discuss unified representation and training, which lack task extensibility and application efficiency. To tackle this issue, we focus on the unified model structure, exploring a face generalist model. As an intuitive design, Naive Faceptor enables tasks with the same output shape and granularity to share the structural design of the standardized output head, achieving improved task extensibility. Furthermore, Faceptor is proposed to adopt a well-designed single-encoder dual-decoder architecture, allowing task-specific queries to represent new-coming semantics. This design enhances the unification of model structure while improving application efficiency in terms of storage overhead. Additionally, we introduce Layer-Attention into Faceptor, enabling the model to adaptively select features from optimal layers to perform the desired tasks. Through joint training on 13 face perception datasets, Faceptor achieves exceptional performance in facial landmark localization, face parsing, age estimation, expression recognition, binary attribute classification, and face recognition, achieving or surpassing specialized methods in most tasks. Our training framework can also be applied to auxiliary supervised learning, significantly improving performance in data-sparse tasks such as age estimation and expression recognition. The code and models will be made publicly available at https://github.com/lxq1000/Faceptor.
BlackJAX: Composable Bayesian inference in JAX
Feb 22, 2024BlackJAX is a library implementing sampling and variational inference algorithms commonly used in Bayesian computation. It is designed for ease of use, speed, and modularity by taking a functional approach to the algorithms' implementation. BlackJAX is written in Python, using JAX to compile and run NumpPy-like samplers and variational methods on CPUs, GPUs, and TPUs. The library integrates well with probabilistic programming languages by working directly with the (un-normalized) target log density function. BlackJAX is intended as a collection of low-level, composable implementations of basic statistical 'atoms' that can be combined to perform well-defined Bayesian inference, but also provides high-level routines for ease of use. It is designed for users who need cutting-edge methods, researchers who want to create complex sampling methods, and people who want to learn how these work.
Widely Linear Matched Filter: A Lynchpin towards the Interpretability of Complex-valued CNNs
Jan 31, 2024A recent study on the interpretability of real-valued convolutional neural networks (CNNs) {Stankovic_Mandic_2023CNN} has revealed a direct and physically meaningful link with the task of finding features in data through matched filters. However, applying this paradigm to illuminate the interpretability of complex-valued CNNs meets a formidable obstacle: the extension of matched filtering to a general class of noncircular complex-valued data, referred to here as the widely linear matched filter (WLMF), has been only implicit in the literature. To this end, to establish the interpretability of the operation of complex-valued CNNs, we introduce a general WLMF paradigm, provide its solution and undertake analysis of its performance. For rigor, our WLMF solution is derived without imposing any assumption on the probability density of noise. The theoretical advantages of the WLMF over its standard strictly linear counterpart (SLMF) are provided in terms of their output signal-to-noise-ratios (SNRs), with WLMF consistently exhibiting enhanced SNR. Moreover, the lower bound on the SNR gain of WLMF is derived, together with condition to attain this bound. This serves to revisit the convolution-activation-pooling chain in complex-valued CNNs through the lens of matched filtering, which reveals the potential of WLMFs to provide physical interpretability and enhance explainability of general complex-valued CNNs. Simulations demonstrate the agreement between the theoretical and numerical results.
Accelerating Approximate Thompson Sampling with Underdamped Langevin Monte Carlo
Jan 22, 2024Approximate Thompson sampling with Langevin Monte Carlo broadens its reach from Gaussian posterior sampling to encompass more general smooth posteriors. However, it still encounters scalability issues in high-dimensional problems when demanding high accuracy. To address this, we propose an approximate Thompson sampling strategy, utilizing underdamped Langevin Monte Carlo, where the latter is the go-to workhorse for simulations of high-dimensional posteriors. Based on the standard smoothness and log-concavity conditions, we study the accelerated posterior concentration and sampling using a specific potential function. This design improves the sample complexity for realizing logarithmic regrets from $\mathcal{\tilde O}(d)$ to $\mathcal{\tilde O}(\sqrt{d})$. The scalability and robustness of our algorithm are also empirically validated through synthetic experiments in high-dimensional bandit problems.
Reflected Schrödinger Bridge for Constrained Generative Modeling
Jan 06, 2024Diffusion models have become the go-to method for large-scale generative models in real-world applications. These applications often involve data distributions confined within bounded domains, typically requiring ad-hoc thresholding techniques for boundary enforcement. Reflected diffusion models (Lou23) aim to enhance generalizability by generating the data distribution through a backward process governed by reflected Brownian motion. However, reflected diffusion models may not easily adapt to diverse domains without the derivation of proper diffeomorphic mappings and do not guarantee optimal transport properties. To overcome these limitations, we introduce the Reflected Schrodinger Bridge algorithm: an entropy-regularized optimal transport approach tailored for generating data within diverse bounded domains. We derive elegant reflected forward-backward stochastic differential equations with Neumann and Robin boundary conditions, extend divergence-based likelihood training to bounded domains, and explore natural connections to entropic optimal transport for the study of approximate linear convergence - a valuable insight for practical training. Our algorithm yields robust generative modeling in diverse domains, and its scalability is demonstrated in real-world constrained generative modeling through standard image benchmarks.
Short-Term Multi-Horizon Line Loss Rate Forecasting of a Distribution Network Using Attention-GCN-LSTM
Dec 19, 2023Accurately predicting line loss rates is vital for effective line loss management in distribution networks, especially over short-term multi-horizons ranging from one hour to one week. In this study, we propose Attention-GCN-LSTM, a novel method that combines Graph Convolutional Networks (GCN), Long Short-Term Memory (LSTM), and a three-level attention mechanism to address this challenge. By capturing spatial and temporal dependencies, our model enables accurate forecasting of line loss rates across multiple horizons. Through comprehensive evaluation using real-world data from 10KV feeders, our Attention-GCN-LSTM model consistently outperforms existing algorithms, exhibiting superior performance in terms of prediction accuracy and multi-horizon forecasting. This model holds significant promise for enhancing line loss management in distribution networks.
Toward Real World Stereo Image Super-Resolution via Hybrid Degradation Model and Discriminator for Implied Stereo Image Information
Dec 13, 2023Real-world stereo image super-resolution has a significant influence on enhancing the performance of computer vision systems. Although existing methods for single-image super-resolution can be applied to improve stereo images, these methods often introduce notable modifications to the inherent disparity, resulting in a loss in the consistency of disparity between the original and the enhanced stereo images. To overcome this limitation, this paper proposes a novel approach that integrates a implicit stereo information discriminator and a hybrid degradation model. This combination ensures effective enhancement while preserving disparity consistency. The proposed method bridges the gap between the complex degradations in real-world stereo domain and the simpler degradations in real-world single-image super-resolution domain. Our results demonstrate impressive performance on synthetic and real datasets, enhancing visual perception while maintaining disparity consistency. The complete code is available at the following \href{https://github.com/fzuzyb/SCGLANet}{link}.