 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmogh Joshi
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024
This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
NTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.
FEDORA: Flying Event Dataset fOr Reactive behAvior
May 22, 2023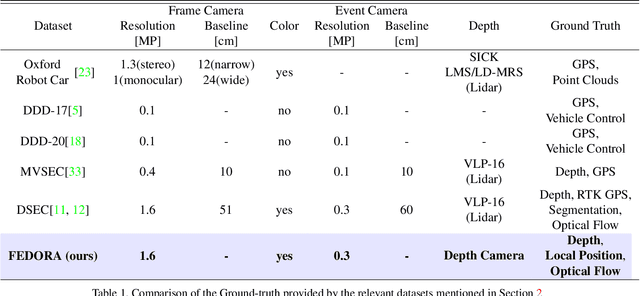



The ability of living organisms to perform complex high speed manoeuvers in flight with a very small number of neurons and an incredibly low failure rate highlights the efficacy of these resource-constrained biological systems. Event-driven hardware has emerged, in recent years, as a promising avenue for implementing complex vision tasks in resource-constrained environments. Vision-based autonomous navigation and obstacle avoidance consists of several independent but related tasks such as optical flow estimation, depth estimation, Simultaneous Localization and Mapping (SLAM), object detection, and recognition. To ensure coherence between these tasks, it is imperative that they be trained on a single dataset. However, most existing datasets provide only a selected subset of the required data. This makes inter-network coherence difficult to achieve. Another limitation of existing datasets is the limited temporal resolution they provide. To address these limitations, we present FEDORA, a first-of-its-kind fully synthetic dataset for vision-based tasks, with ground truths for depth, pose, ego-motion, and optical flow. FEDORA is the first dataset to provide optical flow at three different frequencies - 10Hz, 25Hz, and 50Hz
Standardizing and Centralizing Datasets to Enable Efficient Training of Agricultural Deep Learning Models
Aug 04, 2022
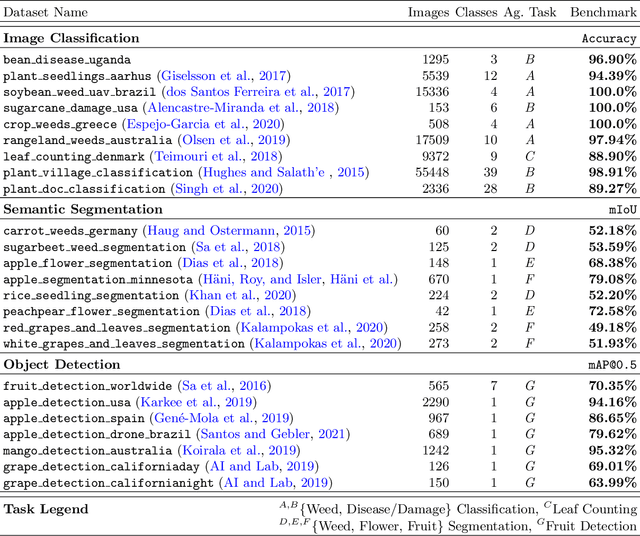

In recent years, deep learning models have become the standard for agricultural computer vision. Such models are typically fine-tuned to agricultural tasks using model weights that were originally fit to more general, non-agricultural datasets. This lack of agriculture-specific fine-tuning potentially increases training time and resource use, and decreases model performance, leading an overall decrease in data efficiency. To overcome this limitation, we collect a wide range of existing public datasets for three distinct tasks, standardize them, and construct standard training and evaluation pipelines, providing us with a set of benchmarks and pretrained models. We then conduct a number of experiments using methods which are commonly used in deep learning tasks, but unexplored in their domain-specific applications for agriculture. Our experiments guide us in developing a number of approaches to improve data efficiency when training agricultural deep learning models, without large-scale modifications to existing pipelines. Our results demonstrate that even slight training modifications, such as using agricultural pretrained model weights, or adopting specific spatial augmentations into data processing pipelines, can significantly boost model performance and result in shorter convergence time, saving training resources. Furthermore, we find that even models trained on low-quality annotations can produce comparable levels of performance to their high-quality equivalents, suggesting that datasets with poor annotations can still be used for training, expanding the pool of currently available datasets. Our methods are broadly applicable throughout agricultural deep learning, and present high potential for significant data efficiency improvements.