 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaokang Yang
IPAD: Industrial Process Anomaly Detection Dataset
Apr 23, 2024
Video anomaly detection (VAD) is a challenging task aiming to recognize anomalies in video frames, and existing large-scale VAD researches primarily focus on road traffic and human activity scenes. In industrial scenes, there are often a variety of unpredictable anomalies, and the VAD method can play a significant role in these scenarios. However, there is a lack of applicable datasets and methods specifically tailored for industrial production scenarios due to concerns regarding privacy and security. To bridge this gap, we propose a new dataset, IPAD, specifically designed for VAD in industrial scenarios. The industrial processes in our dataset are chosen through on-site factory research and discussions with engineers. This dataset covers 16 different industrial devices and contains over 6 hours of both synthetic and real-world video footage. Moreover, we annotate the key feature of the industrial process, ie, periodicity. Based on the proposed dataset, we introduce a period memory module and a sliding window inspection mechanism to effectively investigate the periodic information in a basic reconstruction model. Our framework leverages LoRA adapter to explore the effective migration of pretrained models, which are initially trained using synthetic data, into real-world scenarios. Our proposed dataset and method will fill the gap in the field of industrial video anomaly detection and drive the process of video understanding tasks as well as smart factory deployment.
Infusion: Preventing Customized Text-to-Image Diffusion from Overfitting
Apr 22, 2024Text-to-image (T2I) customization aims to create images that embody specific visual concepts delineated in textual descriptions. However, existing works still face a main challenge, concept overfitting. To tackle this challenge, we first analyze overfitting, categorizing it into concept-agnostic overfitting, which undermines non-customized concept knowledge, and concept-specific overfitting, which is confined to customize on limited modalities, i.e, backgrounds, layouts, styles. To evaluate the overfitting degree, we further introduce two metrics, i.e, Latent Fisher divergence and Wasserstein metric to measure the distribution changes of non-customized and customized concept respectively. Drawing from the analysis, we propose Infusion, a T2I customization method that enables the learning of target concepts to avoid being constrained by limited training modalities, while preserving non-customized knowledge. Remarkably, Infusion achieves this feat with remarkable efficiency, requiring a mere 11KB of trained parameters. Extensive experiments also demonstrate that our approach outperforms state-of-the-art methods in both single and multi-concept customized generation.
Rethinking Clothes Changing Person ReID: Conflicts, Synthesis, and Optimization
Apr 19, 2024Clothes-changing person re-identification (CC-ReID) aims to retrieve images of the same person wearing different outfits. Mainstream researches focus on designing advanced model structures and strategies to capture identity information independent of clothing. However, the same-clothes discrimination as the standard ReID learning objective in CC-ReID is persistently ignored in previous researches. In this study, we dive into the relationship between standard and clothes-changing~(CC) learning objectives, and bring the inner conflicts between these two objectives to the fore. We try to magnify the proportion of CC training pairs by supplementing high-fidelity clothes-varying synthesis, produced by our proposed Clothes-Changing Diffusion model. By incorporating the synthetic images into CC-ReID model training, we observe a significant improvement under CC protocol. However, such improvement sacrifices the performance under the standard protocol, caused by the inner conflict between standard and CC. For conflict mitigation, we decouple these objectives and re-formulate CC-ReID learning as a multi-objective optimization (MOO) problem. By effectively regularizing the gradient curvature across multiple objectives and introducing preference restrictions, our MOO solution surpasses the single-task training paradigm. Our framework is model-agnostic, and demonstrates superior performance under both CC and standard ReID protocols.
Tendency-driven Mutual Exclusivity for Weakly Supervised Incremental Semantic Segmentation
Apr 19, 2024Weakly Incremental Learning for Semantic Segmentation (WILSS) leverages a pre-trained segmentation model to segment new classes using cost-effective and readily available image-level labels. A prevailing way to solve WILSS is the generation of seed areas for each new class, serving as a form of pixel-level supervision. However, a scenario usually arises where a pixel is concurrently predicted as an old class by the pre-trained segmentation model and a new class by the seed areas. Such a scenario becomes particularly problematic in WILSS, as the lack of pixel-level annotations on new classes makes it intractable to ascertain whether the pixel pertains to the new class or not. To surmount this issue, we propose an innovative, tendency-driven relationship of mutual exclusivity, meticulously tailored to govern the behavior of the seed areas and the predictions generated by the pre-trained segmentation model. This relationship stipulates that predictions for the new and old classes must not conflict whilst prioritizing the preservation of predictions for the old classes, which not only addresses the conflicting prediction issue but also effectively mitigates the inherent challenge of incremental learning - catastrophic forgetting. Furthermore, under the auspices of this tendency-driven mutual exclusivity relationship, we generate pseudo masks for the new classes, allowing for concurrent execution with model parameter updating via the resolution of a bi-level optimization problem. Extensive experiments substantiate the effectiveness of our framework, resulting in the establishment of new benchmarks and paving the way for further research in this field.
NTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.
Monocular Identity-Conditioned Facial Reflectance Reconstruction
Mar 30, 2024Recent 3D face reconstruction methods have made remarkable advancements, yet there remain huge challenges in monocular high-quality facial reflectance reconstruction. Existing methods rely on a large amount of light-stage captured data to learn facial reflectance models. However, the lack of subject diversity poses challenges in achieving good generalization and widespread applicability. In this paper, we learn the reflectance prior in image space rather than UV space and present a framework named ID2Reflectance. Our framework can directly estimate the reflectance maps of a single image while using limited reflectance data for training. Our key insight is that reflectance data shares facial structures with RGB faces, which enables obtaining expressive facial prior from inexpensive RGB data thus reducing the dependency on reflectance data. We first learn a high-quality prior for facial reflectance. Specifically, we pretrain multi-domain facial feature codebooks and design a codebook fusion method to align the reflectance and RGB domains. Then, we propose an identity-conditioned swapping module that injects facial identity from the target image into the pre-trained autoencoder to modify the identity of the source reflectance image. Finally, we stitch multi-view swapped reflectance images to obtain renderable assets. Extensive experiments demonstrate that our method exhibits excellent generalization capability and achieves state-of-the-art facial reflectance reconstruction results for in-the-wild faces. Our project page is https://xingyuren.github.io/id2reflectance/.
UAlign: Pushing the Limit of Template-free Retrosynthesis Prediction with Unsupervised SMILES Alignment
Mar 25, 2024Retrosynthesis planning poses a formidable challenge in the organic chemical industry, particularly in pharmaceuticals. Single-step retrosynthesis prediction, a crucial step in the planning process, has witnessed a surge in interest in recent years due to advancements in AI for science. Various deep learning-based methods have been proposed for this task in recent years, incorporating diverse levels of additional chemical knowledge dependency. This paper introduces UAlign, a template-free graph-to-sequence pipeline for retrosynthesis prediction. By combining graph neural networks and Transformers, our method can more effectively leverage the inherent graph structure of molecules. Based on the fact that the majority of molecule structures remain unchanged during a chemical reaction, we propose a simple yet effective SMILES alignment technique to facilitate the reuse of unchanged structures for reactant generation. Extensive experiments show that our method substantially outperforms state-of-the-art template-free and semi-template-based approaches. Importantly, Our template-free method achieves effectiveness comparable to, or even surpasses, established powerful template-based methods. Scientific contribution: We present a novel graph-to-sequence template-free retrosynthesis prediction pipeline that overcomes the limitations of Transformer-based methods in molecular representation learning and insufficient utilization of chemical information. We propose an unsupervised learning mechanism for establishing product-atom correspondence with reactant SMILES tokens, achieving even better results than supervised SMILES alignment methods. Extensive experiments demonstrate that UAlign significantly outperforms state-of-the-art template-free methods and rivals or surpasses template-based approaches, with up to 5\% (top-5) and 5.4\% (top-10) increased accuracy over the strongest baseline.
EndoGSLAM: Real-Time Dense Reconstruction and Tracking in Endoscopic Surgeries using Gaussian Splatting
Mar 22, 2024

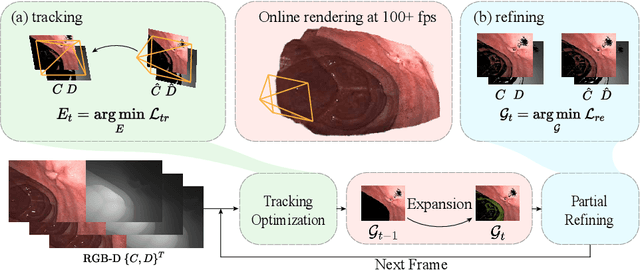

Precise camera tracking, high-fidelity 3D tissue reconstruction, and real-time online visualization are critical for intrabody medical imaging devices such as endoscopes and capsule robots. However, existing SLAM (Simultaneous Localization and Mapping) methods often struggle to achieve both complete high-quality surgical field reconstruction and efficient computation, restricting their intraoperative applications among endoscopic surgeries. In this paper, we introduce EndoGSLAM, an efficient SLAM approach for endoscopic surgeries, which integrates streamlined Gaussian representation and differentiable rasterization to facilitate over 100 fps rendering speed during online camera tracking and tissue reconstructing. Extensive experiments show that EndoGSLAM achieves a better trade-off between intraoperative availability and reconstruction quality than traditional or neural SLAM approaches, showing tremendous potential for endoscopic surgeries. The project page is at https://EndoGSLAM.loping151.com
ReGenNet: Towards Human Action-Reaction Synthesis
Mar 18, 2024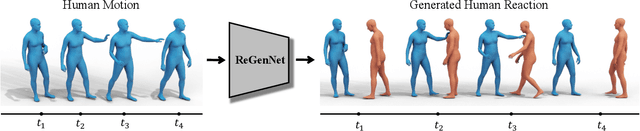
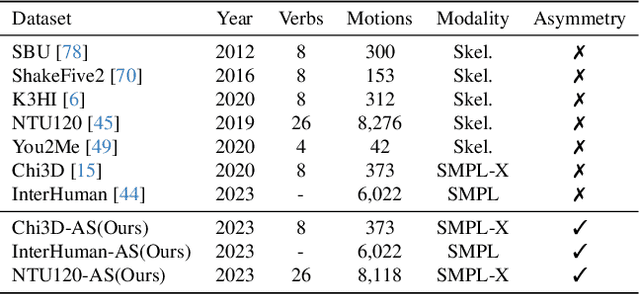

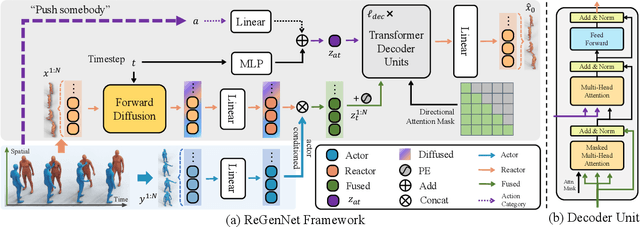
Humans constantly interact with their surrounding environments. Current human-centric generative models mainly focus on synthesizing humans plausibly interacting with static scenes and objects, while the dynamic human action-reaction synthesis for ubiquitous causal human-human interactions is less explored. Human-human interactions can be regarded as asymmetric with actors and reactors in atomic interaction periods. In this paper, we comprehensively analyze the asymmetric, dynamic, synchronous, and detailed nature of human-human interactions and propose the first multi-setting human action-reaction synthesis benchmark to generate human reactions conditioned on given human actions. To begin with, we propose to annotate the actor-reactor order of the interaction sequences for the NTU120, InterHuman, and Chi3D datasets. Based on them, a diffusion-based generative model with a Transformer decoder architecture called ReGenNet together with an explicit distance-based interaction loss is proposed to predict human reactions in an online manner, where the future states of actors are unavailable to reactors. Quantitative and qualitative results show that our method can generate instant and plausible human reactions compared to the baselines, and can generalize to unseen actor motions and viewpoint changes.
Boundary Matters: A Bi-Level Active Finetuning Framework
Mar 15, 2024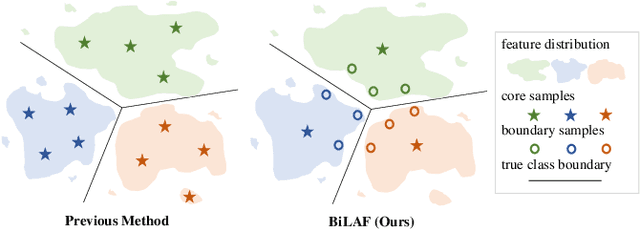
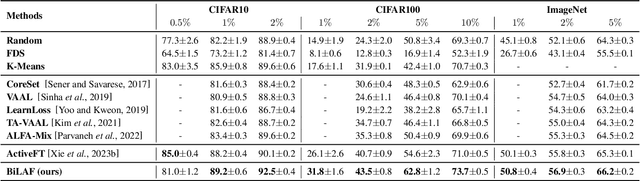
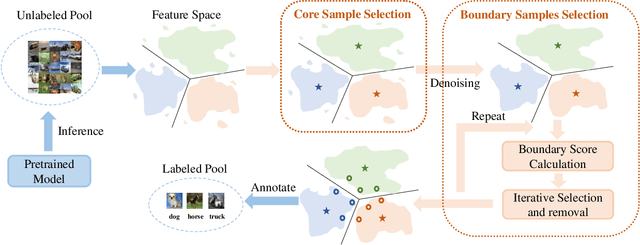
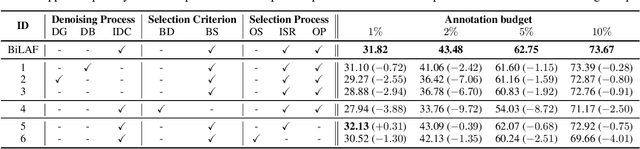
The pretraining-finetuning paradigm has gained widespread adoption in vision tasks and other fields, yet it faces the significant challenge of high sample annotation costs. To mitigate this, the concept of active finetuning has emerged, aiming to select the most appropriate samples for model finetuning within a limited budget. Traditional active learning methods often struggle in this setting due to their inherent bias in batch selection. Furthermore, the recent active finetuning approach has primarily concentrated on aligning the distribution of selected subsets with the overall data pool, focusing solely on diversity. In this paper, we propose a Bi-Level Active Finetuning framework to select the samples for annotation in one shot, which includes two stages: core sample selection for diversity, and boundary sample selection for uncertainty. The process begins with the identification of pseudo-class centers, followed by an innovative denoising method and an iterative strategy for boundary sample selection in the high-dimensional feature space, all without relying on ground-truth labels. Our comprehensive experiments provide both qualitative and quantitative evidence of our method's efficacy, outperforming all the existing baselines.