 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKai Zhao
Unleashing the Potential of Fractional Calculus in Graph Neural Networks with FROND
Apr 26, 2024
We introduce the FRactional-Order graph Neural Dynamical network (FROND), a new continuous graph neural network (GNN) framework. Unlike traditional continuous GNNs that rely on integer-order differential equations, FROND employs the Caputo fractional derivative to leverage the non-local properties of fractional calculus. This approach enables the capture of long-term dependencies in feature updates, moving beyond the Markovian update mechanisms in conventional integer-order models and offering enhanced capabilities in graph representation learning. We offer an interpretation of the node feature updating process in FROND from a non-Markovian random walk perspective when the feature updating is particularly governed by a diffusion process. We demonstrate analytically that oversmoothing can be mitigated in this setting. Experimentally, we validate the FROND framework by comparing the fractional adaptations of various established integer-order continuous GNNs, demonstrating their consistently improved performance and underscoring the framework's potential as an effective extension to enhance traditional continuous GNNs. The code is available at \url{https://github.com/zknus/ICLR2024-FROND}.
PointDifformer: Robust Point Cloud Registration With Neural Diffusion and Transformer
Apr 22, 2024Point cloud registration is a fundamental technique in 3-D computer vision with applications in graphics, autonomous driving, and robotics. However, registration tasks under challenging conditions, under which noise or perturbations are prevalent, can be difficult. We propose a robust point cloud registration approach that leverages graph neural partial differential equations (PDEs) and heat kernel signatures. Our method first uses graph neural PDE modules to extract high dimensional features from point clouds by aggregating information from the 3-D point neighborhood, thereby enhancing the robustness of the feature representations. Then, we incorporate heat kernel signatures into an attention mechanism to efficiently obtain corresponding keypoints. Finally, a singular value decomposition (SVD) module with learnable weights is used to predict the transformation between two point clouds. Empirical experiments on a 3-D point cloud dataset demonstrate that our approach not only achieves state-of-the-art performance for point cloud registration but also exhibits better robustness to additive noise or 3-D shape perturbations.
NTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.
Empowering Segmentation Ability to Multi-modal Large Language Models
Mar 21, 2024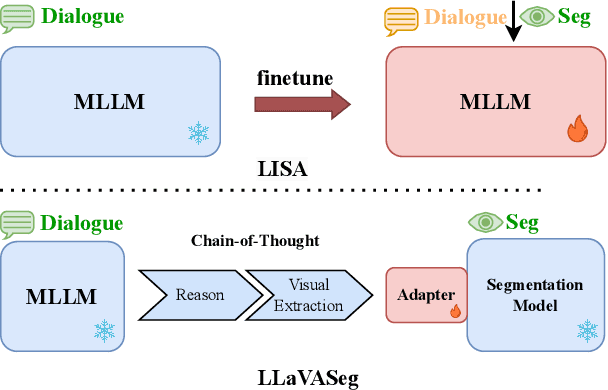
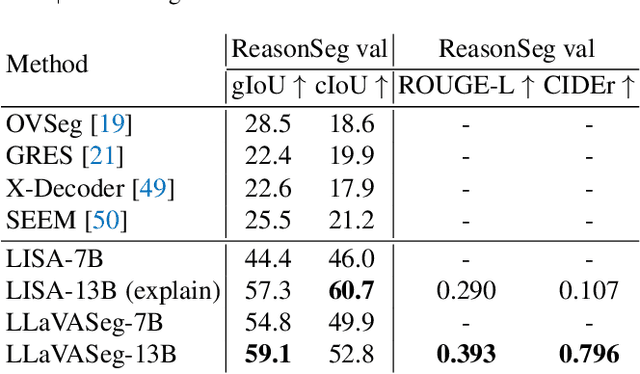
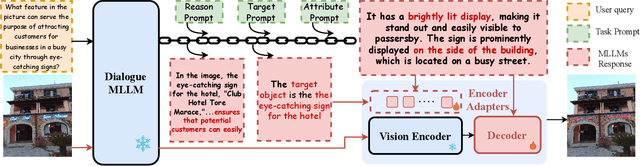
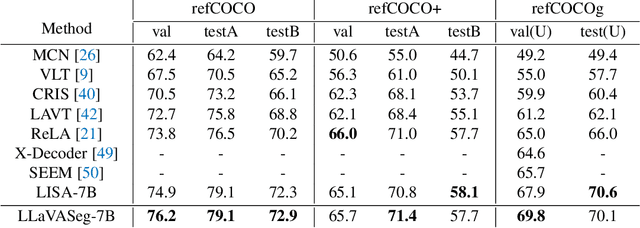
Multi-modal large language models (MLLMs) can understand image-language prompts and demonstrate impressive reasoning ability. In this paper, we extend MLLMs' output by empowering MLLMs with the segmentation ability. The extended MLLMs can both output language responses to the image-language prompts and segment the regions that the complex question or query in the language prompts focuses on. To this end, the existing work, LISA, enlarges the original word embeddings with an additional segment token and fine-tunes dialogue generation and query-focused segmentation together, where the feature of the segment token is used to prompt the segment-anything model. Although they achieve superior segmentation performance, we observe that the dialogue ability decreases by a large margin compared to the original MLLMs. To maintain the original MLLMs' dialogue ability, we propose a novel MLLMs framework, coined as LLaVASeg, which leverages a chain-of-thought prompting strategy to instruct the MLLMs to segment the target region queried by the user. The MLLMs are first prompted to reason about the simple description of the target region from the complicated user query, then extract the visual attributes of the target region according to the understanding of MLLMs to the image. These visual attributes, such as color and relative locations, are utilized to prompt the downstream segmentation model. Experiments show that the proposed method keeps the original dialogue ability and equips the MLLMs' model with strong reasoning segmentation ability. The code is available at https://github.com/YuqiYang213/LLaVASeg.
CasSR: Activating Image Power for Real-World Image Super-Resolution
Mar 18, 2024
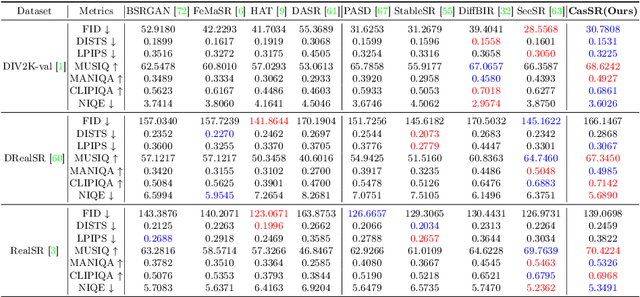


The objective of image super-resolution is to generate clean and high-resolution images from degraded versions. Recent advancements in diffusion modeling have led to the emergence of various image super-resolution techniques that leverage pretrained text-to-image (T2I) models. Nevertheless, due to the prevalent severe degradation in low-resolution images and the inherent characteristics of diffusion models, achieving high-fidelity image restoration remains challenging. Existing methods often exhibit issues including semantic loss, artifacts, and the introduction of spurious content not present in the original image. To tackle this challenge, we propose Cascaded diffusion for Super-Resolution, CasSR , a novel method designed to produce highly detailed and realistic images. In particular, we develop a cascaded controllable diffusion model that aims to optimize the extraction of information from low-resolution images. This model generates a preliminary reference image to facilitate initial information extraction and degradation mitigation. Furthermore, we propose a multi-attention mechanism to enhance the T2I model's capability in maximizing the restoration of the original image content. Through a comprehensive blend of qualitative and quantitative analyses, we substantiate the efficacy and superiority of our approach.
XPSR: Cross-modal Priors for Diffusion-based Image Super-Resolution
Mar 08, 2024
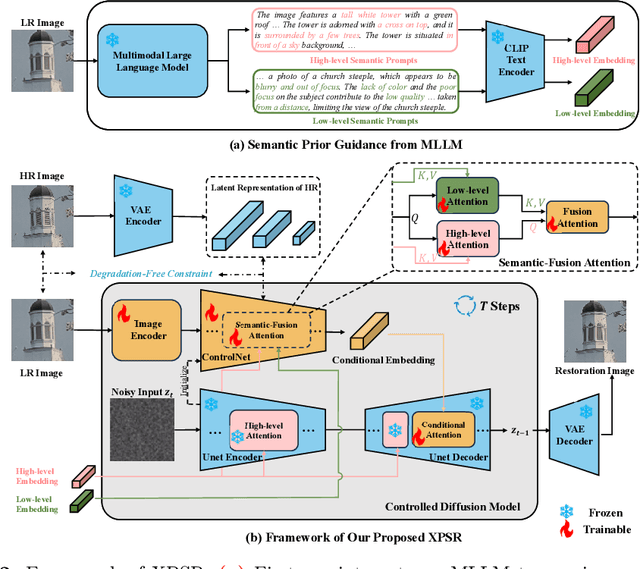
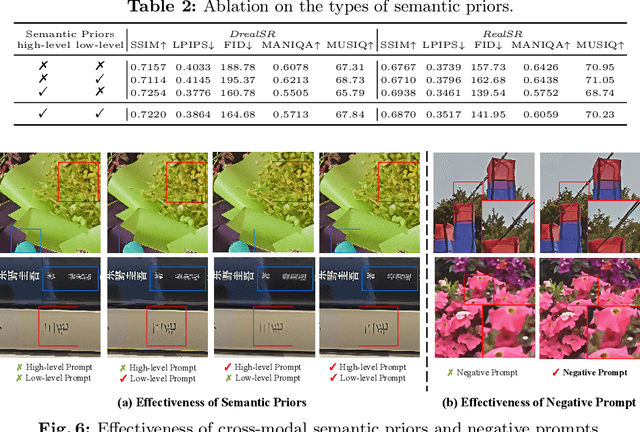
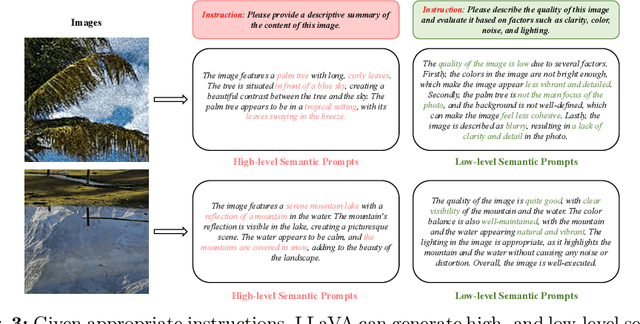
Diffusion-based methods, endowed with a formidable generative prior, have received increasing attention in Image Super-Resolution (ISR) recently. However, as low-resolution (LR) images often undergo severe degradation, it is challenging for ISR models to perceive the semantic and degradation information, resulting in restoration images with incorrect content or unrealistic artifacts. To address these issues, we propose a \textit{Cross-modal Priors for Super-Resolution (XPSR)} framework. Within XPSR, to acquire precise and comprehensive semantic conditions for the diffusion model, cutting-edge Multimodal Large Language Models (MLLMs) are utilized. To facilitate better fusion of cross-modal priors, a \textit{Semantic-Fusion Attention} is raised. To distill semantic-preserved information instead of undesired degradations, a \textit{Degradation-Free Constraint} is attached between LR and its high-resolution (HR) counterpart. Quantitative and qualitative results show that XPSR is capable of generating high-fidelity and high-realism images across synthetic and real-world datasets. Codes will be released at \url{https://github.com/qyp2000/XPSR}.
Uncertainty-driven and Adversarial Calibration Learning for Epicardial Adipose Tissue Segmentation
Feb 23, 2024Epicardial adipose tissue (EAT) is a type of visceral fat that can secrete large amounts of adipokines to affect the myocardium and coronary arteries. EAT volume and density can be used as independent risk markers measurement of volume by noninvasive magnetic resonance images is the best method of assessing EAT. However, segmenting EAT is challenging due to the low contrast between EAT and pericardial effusion and the presence of motion artifacts. we propose a novel feature latent space multilevel supervision network (SPDNet) with uncertainty-driven and adversarial calibration learning to enhance segmentation for more accurate EAT volume estimation. The network first addresses the blurring of EAT edges due to the medical images in the open medical environments with low quality or out-of-distribution by modeling the uncertainty as a Gaussian distribution in the feature latent space, which using its Bayesian estimation as a regularization constraint to optimize SwinUNETR. Second, an adversarial training strategy is introduced to calibrate the segmentation feature map and consider the multi-scale feature differences between the uncertainty-guided predictive segmentation and the ground truth segmentation, synthesizing the multi-scale adversarial loss directly improves the ability to discriminate the similarity between organizations. Experiments on both the cardiac public MRI dataset (ACDC) and the real-world clinical cohort EAT dataset show that the proposed network outperforms mainstream models, validating that uncertainty-driven and adversarial calibration learning can be used to provide additional information for modeling multi-scale ambiguities.
Uni-RLHF: Universal Platform and Benchmark Suite for Reinforcement Learning with Diverse Human Feedback
Feb 04, 2024Reinforcement Learning with Human Feedback (RLHF) has received significant attention for performing tasks without the need for costly manual reward design by aligning human preferences. It is crucial to consider diverse human feedback types and various learning methods in different environments. However, quantifying progress in RLHF with diverse feedback is challenging due to the lack of standardized annotation platforms and widely used unified benchmarks. To bridge this gap, we introduce Uni-RLHF, a comprehensive system implementation tailored for RLHF. It aims to provide a complete workflow from real human feedback, fostering progress in the development of practical problems. Uni-RLHF contains three packages: 1) a universal multi-feedback annotation platform, 2) large-scale crowdsourced feedback datasets, and 3) modular offline RLHF baseline implementations. Uni-RLHF develops a user-friendly annotation interface tailored to various feedback types, compatible with a wide range of mainstream RL environments. We then establish a systematic pipeline of crowdsourced annotations, resulting in large-scale annotated datasets comprising more than 15 million steps across 30+ popular tasks. Through extensive experiments, the results in the collected datasets demonstrate competitive performance compared to those from well-designed manual rewards. We evaluate various design choices and offer insights into their strengths and potential areas of improvement. We wish to build valuable open-source platforms, datasets, and baselines to facilitate the development of more robust and reliable RLHF solutions based on realistic human feedback. The website is available at https://uni-rlhf.github.io/.
Coupling Graph Neural Networks with Fractional Order Continuous Dynamics: A Robustness Study
Jan 09, 2024In this work, we rigorously investigate the robustness of graph neural fractional-order differential equation (FDE) models. This framework extends beyond traditional graph neural (integer-order) ordinary differential equation (ODE) models by implementing the time-fractional Caputo derivative. Utilizing fractional calculus allows our model to consider long-term memory during the feature updating process, diverging from the memoryless Markovian updates seen in traditional graph neural ODE models. The superiority of graph neural FDE models over graph neural ODE models has been established in environments free from attacks or perturbations. While traditional graph neural ODE models have been verified to possess a degree of stability and resilience in the presence of adversarial attacks in existing literature, the robustness of graph neural FDE models, especially under adversarial conditions, remains largely unexplored. This paper undertakes a detailed assessment of the robustness of graph neural FDE models. We establish a theoretical foundation outlining the robustness characteristics of graph neural FDE models, highlighting that they maintain more stringent output perturbation bounds in the face of input and graph topology disturbances, compared to their integer-order counterparts. Our empirical evaluations further confirm the enhanced robustness of graph neural FDE models, highlighting their potential in adversarially robust applications.
PosDiffNet: Positional Neural Diffusion for Point Cloud Registration in a Large Field of View with Perturbations
Jan 06, 2024Point cloud registration is a crucial technique in 3D computer vision with a wide range of applications. However, this task can be challenging, particularly in large fields of view with dynamic objects, environmental noise, or other perturbations. To address this challenge, we propose a model called PosDiffNet. Our approach performs hierarchical registration based on window-level, patch-level, and point-level correspondence. We leverage a graph neural partial differential equation (PDE) based on Beltrami flow to obtain high-dimensional features and position embeddings for point clouds. We incorporate position embeddings into a Transformer module based on a neural ordinary differential equation (ODE) to efficiently represent patches within points. We employ the multi-level correspondence derived from the high feature similarity scores to facilitate alignment between point clouds. Subsequently, we use registration methods such as SVD-based algorithms to predict the transformation using corresponding point pairs. We evaluate PosDiffNet on several 3D point cloud datasets, verifying that it achieves state-of-the-art (SOTA) performance for point cloud registration in large fields of view with perturbations. The implementation code of experiments is available at https://github.com/AI-IT-AVs/PosDiffNet.