 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaogang Xu
Towards Better Adversarial Purification via Adversarial Denoising Diffusion Training
Apr 22, 2024
Recently, diffusion-based purification (DBP) has emerged as a promising approach for defending against adversarial attacks. However, previous studies have used questionable methods to evaluate the robustness of DBP models, their explanations of DBP robustness also lack experimental support. We re-examine DBP robustness using precise gradient, and discuss the impact of stochasticity on DBP robustness. To better explain DBP robustness, we assess DBP robustness under a novel attack setting, Deterministic White-box, and pinpoint stochasticity as the main factor in DBP robustness. Our results suggest that DBP models rely on stochasticity to evade the most effective attack direction, rather than directly countering adversarial perturbations. To improve the robustness of DBP models, we propose Adversarial Denoising Diffusion Training (ADDT). This technique uses Classifier-Guided Perturbation Optimization (CGPO) to generate adversarial perturbation through guidance from a pre-trained classifier, and uses Rank-Based Gaussian Mapping (RBGM) to convert adversarial pertubation into a normal Gaussian distribution. Empirical results show that ADDT improves the robustness of DBP models. Further experiments confirm that ADDT equips DBP models with the ability to directly counter adversarial perturbations.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
NTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.
Boosting Image Restoration via Priors from Pre-trained Models
Mar 19, 2024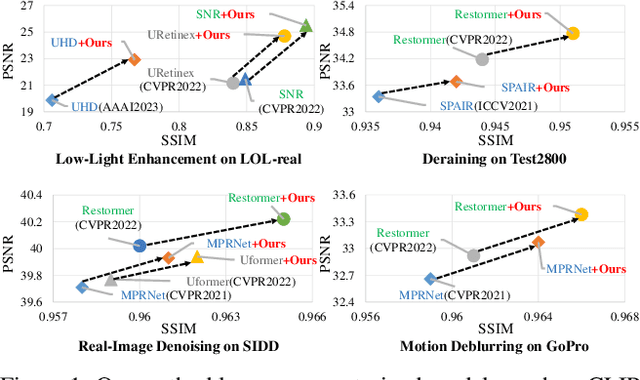

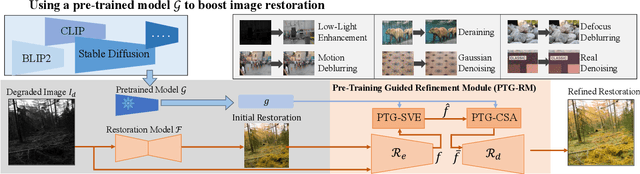
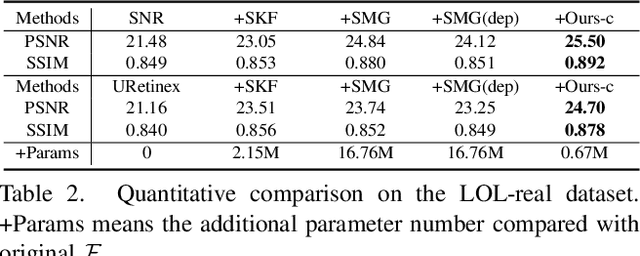
Pre-trained models with large-scale training data, such as CLIP and Stable Diffusion, have demonstrated remarkable performance in various high-level computer vision tasks such as image understanding and generation from language descriptions. Yet, their potential for low-level tasks such as image restoration remains relatively unexplored. In this paper, we explore such models to enhance image restoration. As off-the-shelf features (OSF) from pre-trained models do not directly serve image restoration, we propose to learn an additional lightweight module called Pre-Train-Guided Refinement Module (PTG-RM) to refine restoration results of a target restoration network with OSF. PTG-RM consists of two components, Pre-Train-Guided Spatial-Varying Enhancement (PTG-SVE), and Pre-Train-Guided Channel-Spatial Attention (PTG-CSA). PTG-SVE enables optimal short- and long-range neural operations, while PTG-CSA enhances spatial-channel attention for restoration-related learning. Extensive experiments demonstrate that PTG-RM, with its compact size ($<$1M parameters), effectively enhances restoration performance of various models across different tasks, including low-light enhancement, deraining, deblurring, and denoising.
Learning to Remove Wrinkled Transparent Film with Polarized Prior
Mar 07, 2024
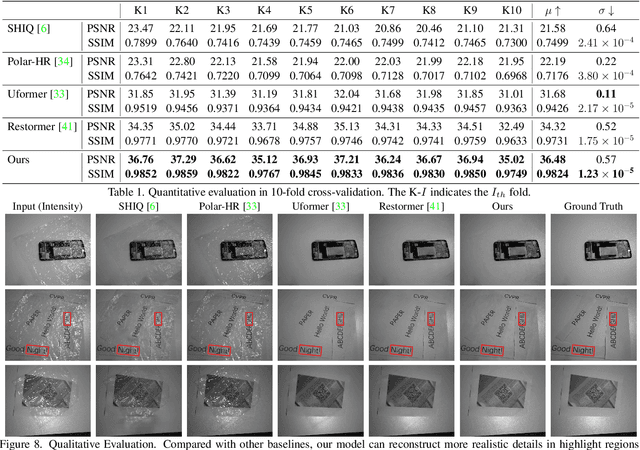
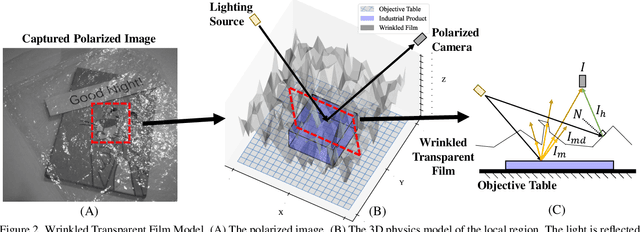
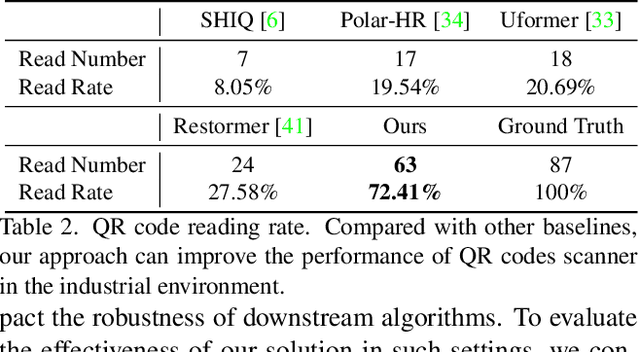
In this paper, we study a new problem, Film Removal (FR), which attempts to remove the interference of wrinkled transparent films and reconstruct the original information under films for industrial recognition systems. We first physically model the imaging of industrial materials covered by the film. Considering the specular highlight from the film can be effectively recorded by the polarized camera, we build a practical dataset with polarization information containing paired data with and without transparent film. We aim to remove interference from the film (specular highlights and other degradations) with an end-to-end framework. To locate the specular highlight, we use an angle estimation network to optimize the polarization angle with the minimized specular highlight. The image with minimized specular highlight is set as a prior for supporting the reconstruction network. Based on the prior and the polarized images, the reconstruction network can decouple all degradations from the film. Extensive experiments show that our framework achieves SOTA performance in both image reconstruction and industrial downstream tasks. Our code will be released at \url{https://github.com/jqtangust/FilmRemoval}.
UniMODE: Unified Monocular 3D Object Detection
Feb 28, 2024
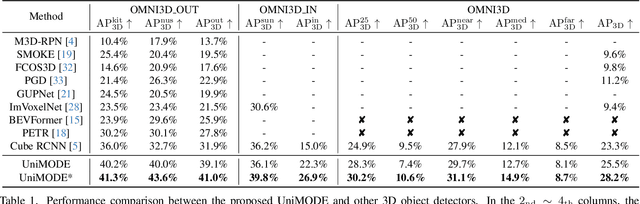


Realizing unified monocular 3D object detection, including both indoor and outdoor scenes, holds great importance in applications like robot navigation. However, involving various scenarios of data to train models poses challenges due to their significantly different characteristics, e.g., diverse geometry properties and heterogeneous domain distributions. To address these challenges, we build a detector based on the bird's-eye-view (BEV) detection paradigm, where the explicit feature projection is beneficial to addressing the geometry learning ambiguity when employing multiple scenarios of data to train detectors. Then, we split the classical BEV detection architecture into two stages and propose an uneven BEV grid design to handle the convergence instability caused by the aforementioned challenges. Moreover, we develop a sparse BEV feature projection strategy to reduce computational cost and a unified domain alignment method to handle heterogeneous domains. Combining these techniques, a unified detector UniMODE is derived, which surpasses the previous state-of-the-art on the challenging Omni3D dataset (a large-scale dataset including both indoor and outdoor scenes) by 4.9% AP_3D, revealing the first successful generalization of a BEV detector to unified 3D object detection.
Diving Deep into Regions: Exploiting Regional Information Transformer for Single Image Deraining
Feb 25, 2024Transformer-based Single Image Deraining (SID) methods have achieved remarkable success, primarily attributed to their robust capability in capturing long-range interactions. However, we've noticed that current methods handle rain-affected and unaffected regions concurrently, overlooking the disparities between these areas, resulting in confusion between rain streaks and background parts, and inabilities to obtain effective interactions, ultimately resulting in suboptimal deraining outcomes. To address the above issue, we introduce the Region Transformer (Regformer), a novel SID method that underlines the importance of independently processing rain-affected and unaffected regions while considering their combined impact for high-quality image reconstruction. The crux of our method is the innovative Region Transformer Block (RTB), which integrates a Region Masked Attention (RMA) mechanism and a Mixed Gate Forward Block (MGFB). Our RTB is used for attention selection of rain-affected and unaffected regions and local modeling of mixed scales. The RMA generates attention maps tailored to these two regions and their interactions, enabling our model to capture comprehensive features essential for rain removal. To better recover high-frequency textures and capture more local details, we develop the MGFB as a compensation module to complete local mixed scale modeling. Extensive experiments demonstrate that our model reaches state-of-the-art performance, significantly improving the image deraining quality. Our code and trained models are publicly available.
Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
Jan 19, 2024This work presents Depth Anything, a highly practical solution for robust monocular depth estimation. Without pursuing novel technical modules, we aim to build a simple yet powerful foundation model dealing with any images under any circumstances. To this end, we scale up the dataset by designing a data engine to collect and automatically annotate large-scale unlabeled data (~62M), which significantly enlarges the data coverage and thus is able to reduce the generalization error. We investigate two simple yet effective strategies that make data scaling-up promising. First, a more challenging optimization target is created by leveraging data augmentation tools. It compels the model to actively seek extra visual knowledge and acquire robust representations. Second, an auxiliary supervision is developed to enforce the model to inherit rich semantic priors from pre-trained encoders. We evaluate its zero-shot capabilities extensively, including six public datasets and randomly captured photos. It demonstrates impressive generalization ability. Further, through fine-tuning it with metric depth information from NYUv2 and KITTI, new SOTAs are set. Our better depth model also results in a better depth-conditioned ControlNet. Our models are released at https://github.com/LiheYoung/Depth-Anything.
Video Frame Interpolation with Region-Distinguishable Priors from SAM
Dec 26, 2023In existing Video Frame Interpolation (VFI) approaches, the motion estimation between neighboring frames plays a crucial role. However, the estimation accuracy in existing methods remains a challenge, primarily due to the inherent ambiguity in identifying corresponding areas in adjacent frames for interpolation. Therefore, enhancing accuracy by distinguishing different regions before motion estimation is of utmost importance. In this paper, we introduce a novel solution involving the utilization of open-world segmentation models, e.g., SAM (Segment Anything Model), to derive Region-Distinguishable Priors (RDPs) in different frames. These RDPs are represented as spatial-varying Gaussian mixtures, distinguishing an arbitrary number of areas with a unified modality. RDPs can be integrated into existing motion-based VFI methods to enhance features for motion estimation, facilitated by our designed play-and-plug Hierarchical Region-aware Feature Fusion Module (HRFFM). HRFFM incorporates RDP into various hierarchical stages of VFI's encoder, using RDP-guided Feature Normalization (RDPFN) in a residual learning manner. With HRFFM and RDP, the features within VFI's encoder exhibit similar representations for matched regions in neighboring frames, thus improving the synthesis of intermediate frames. Extensive experiments demonstrate that HRFFM consistently enhances VFI performance across various scenes.
Geometric-Aware Low-Light Image and Video Enhancement via Depth Guidance
Dec 26, 2023Low-Light Enhancement (LLE) is aimed at improving the quality of photos/videos captured under low-light conditions. It is worth noting that most existing LLE methods do not take advantage of geometric modeling. We believe that incorporating geometric information can enhance LLE performance, as it provides insights into the physical structure of the scene that influences illumination conditions. To address this, we propose a Geometry-Guided Low-Light Enhancement Refine Framework (GG-LLERF) designed to assist low-light enhancement models in learning improved features for LLE by integrating geometric priors into the feature representation space. In this paper, we employ depth priors as the geometric representation. Our approach focuses on the integration of depth priors into various LLE frameworks using a unified methodology. This methodology comprises two key novel modules. First, a depth-aware feature extraction module is designed to inject depth priors into the image representation. Then, Hierarchical Depth-Guided Feature Fusion Module (HDGFFM) is formulated with a cross-domain attention mechanism, which combines depth-aware features with the original image features within the LLE model. We conducted extensive experiments on public low-light image and video enhancement benchmarks. The results illustrate that our designed framework significantly enhances existing LLE methods.