 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTao Hu
Bracketing Image Restoration and Enhancement with High-Low Frequency Decomposition
Apr 24, 2024
In real-world scenarios, due to a series of image degradations, obtaining high-quality, clear content photos is challenging. While significant progress has been made in synthesizing high-quality images, previous methods for image restoration and enhancement often overlooked the characteristics of different degradations. They applied the same structure to address various types of degradation, resulting in less-than-ideal restoration outcomes. Inspired by the notion that high/low frequency information is applicable to different degradations, we introduce HLNet, a Bracketing Image Restoration and Enhancement method based on high-low frequency decomposition. Specifically, we employ two modules for feature extraction: shared weight modules and non-shared weight modules. In the shared weight modules, we use SCConv to extract common features from different degradations. In the non-shared weight modules, we introduce the High-Low Frequency Decomposition Block (HLFDB), which employs different methods to handle high-low frequency information, enabling the model to address different degradations more effectively. Compared to other networks, our method takes into account the characteristics of different degradations, thus achieving higher-quality image restoration.
ID-Animator: Zero-Shot Identity-Preserving Human Video Generation
Apr 23, 2024Generating high fidelity human video with specified identities has attracted significant attention in the content generation community. However, existing techniques struggle to strike a balance between training efficiency and identity preservation, either requiring tedious case-by-case finetuning or usually missing the identity details in video generation process. In this study, we present ID-Animator, a zero-shot human-video generation approach that can perform personalized video generation given single reference facial image without further training. ID-Animator inherits existing diffusion-based video generation backbones with a face adapter to encode the ID-relevant embeddings from learnable facial latent queries. To facilitate the extraction of identity information in video generation, we introduce an ID-oriented dataset construction pipeline, which incorporates decoupled human attribute and action captioning technique from a constructed facial image pool. Based on this pipeline, a random face reference training method is further devised to precisely capture the ID-relevant embeddings from reference images, thus improving the fidelity and generalization capacity of our model for ID-specific video generation. Extensive experiments demonstrate the superiority of ID-Animator to generate personalized human videos over previous models. Moreover, our method is highly compatible with popular pre-trained T2V models like animatediff and various community backbone models, showing high extendability in real-world applications for video generation where identity preservation is highly desired. Our codes and checkpoints will be released at https://github.com/ID-Animator/ID-Animator.
X-Ray: A Sequential 3D Representation for Generation
Apr 22, 2024In this paper, we introduce X-Ray, an innovative approach to 3D generation that employs a new sequential representation, drawing inspiration from the depth-revealing capabilities of X-Ray scans to meticulously capture both the external and internal features of objects. Central to our method is the utilization of ray casting techniques originating from the camera's viewpoint, meticulously recording the geometric and textural details encountered across all intersected surfaces. This process efficiently condenses complete objects or scenes into a multi-frame format, just like videos. Such a structure ensures the 3D representation is composed solely of critical surface information. Highlighting the practicality and adaptability of our X-Ray representation, we showcase its utility in synthesizing 3D objects, employing a network architecture akin to that used in video diffusion models. The outcomes reveal our representation's superior performance in enhancing both the accuracy and efficiency of 3D synthesis, heralding new directions for ongoing research and practical implementations in the field.
CRNet: A Detail-Preserving Network for Unified Image Restoration and Enhancement Task
Apr 22, 2024In real-world scenarios, images captured often suffer from blurring, noise, and other forms of image degradation, and due to sensor limitations, people usually can only obtain low dynamic range images. To achieve high-quality images, researchers have attempted various image restoration and enhancement operations on photographs, including denoising, deblurring, and high dynamic range imaging. However, merely performing a single type of image enhancement still cannot yield satisfactory images. In this paper, to deal with the challenge above, we propose the Composite Refinement Network (CRNet) to address this issue using multiple exposure images. By fully integrating information-rich multiple exposure inputs, CRNet can perform unified image restoration and enhancement. To improve the quality of image details, CRNet explicitly separates and strengthens high and low-frequency information through pooling layers, using specially designed Multi-Branch Blocks for effective fusion of these frequencies. To increase the receptive field and fully integrate input features, CRNet employs the High-Frequency Enhancement Module, which includes large kernel convolutions and an inverted bottleneck ConvFFN. Our model secured third place in the first track of the Bracketing Image Restoration and Enhancement Challenge, surpassing previous SOTA models in both testing metrics and visual quality.
FashionEngine: Interactive Generation and Editing of 3D Clothed Humans
Apr 05, 2024We present FashionEngine, an interactive 3D human generation and editing system that allows us to design 3D digital humans in a way that aligns with how humans interact with the world, such as natural languages, visual perceptions, and hand-drawing. FashionEngine automates the 3D human production with three key components: 1) A pre-trained 3D human diffusion model that learns to model 3D humans in a semantic UV latent space from 2D image training data, which provides strong priors for diverse generation and editing tasks. 2) Multimodality-UV Space encoding the texture appearance, shape topology, and textual semantics of human clothing in a canonical UV-aligned space, which faithfully aligns the user multimodal inputs with the implicit UV latent space for controllable 3D human editing. The multimodality-UV space is shared across different user inputs, such as texts, images, and sketches, which enables various joint multimodal editing tasks. 3) Multimodality-UV Aligned Sampler learns to sample high-quality and diverse 3D humans from the diffusion prior for multimodal user inputs. Extensive experiments validate FashionEngine's state-of-the-art performance for conditional generation/editing tasks. In addition, we present an interactive user interface for our FashionEngine that enables both conditional and unconditional generation tasks, and editing tasks including pose/view/shape control, text-, image-, and sketch-driven 3D human editing and 3D virtual try-on, in a unified framework. Our project page is at: https://taohuumd.github.io/projects/FashionEngine.
StructLDM: Structured Latent Diffusion for 3D Human Generation
Apr 02, 2024Recent 3D human generative models have achieved remarkable progress by learning 3D-aware GANs from 2D images. However, existing 3D human generative methods model humans in a compact 1D latent space, ignoring the articulated structure and semantics of human body topology. In this paper, we explore more expressive and higher-dimensional latent space for 3D human modeling and propose StructLDM, a diffusion-based unconditional 3D human generative model, which is learned from 2D images. StructLDM solves the challenges imposed due to the high-dimensional growth of latent space with three key designs: 1) A semantic structured latent space defined on the dense surface manifold of a statistical human body template. 2) A structured 3D-aware auto-decoder that factorizes the global latent space into several semantic body parts parameterized by a set of conditional structured local NeRFs anchored to the body template, which embeds the properties learned from the 2D training data and can be decoded to render view-consistent humans under different poses and clothing styles. 3) A structured latent diffusion model for generative human appearance sampling. Extensive experiments validate StructLDM's state-of-the-art generation performance and illustrate the expressiveness of the structured latent space over the well-adopted 1D latent space. Notably, StructLDM enables different levels of controllable 3D human generation and editing, including pose/view/shape control, and high-level tasks including compositional generations, part-aware clothing editing, 3D virtual try-on, etc. Our project page is at: https://taohuumd.github.io/projects/StructLDM/.
SurMo: Surface-based 4D Motion Modeling for Dynamic Human Rendering
Apr 02, 2024Dynamic human rendering from video sequences has achieved remarkable progress by formulating the rendering as a mapping from static poses to human images. However, existing methods focus on the human appearance reconstruction of every single frame while the temporal motion relations are not fully explored. In this paper, we propose a new 4D motion modeling paradigm, SurMo, that jointly models the temporal dynamics and human appearances in a unified framework with three key designs: 1) Surface-based motion encoding that models 4D human motions with an efficient compact surface-based triplane. It encodes both spatial and temporal motion relations on the dense surface manifold of a statistical body template, which inherits body topology priors for generalizable novel view synthesis with sparse training observations. 2) Physical motion decoding that is designed to encourage physical motion learning by decoding the motion triplane features at timestep t to predict both spatial derivatives and temporal derivatives at the next timestep t+1 in the training stage. 3) 4D appearance decoding that renders the motion triplanes into images by an efficient volumetric surface-conditioned renderer that focuses on the rendering of body surfaces with motion learning conditioning. Extensive experiments validate the state-of-the-art performance of our new paradigm and illustrate the expressiveness of surface-based motion triplanes for rendering high-fidelity view-consistent humans with fast motions and even motion-dependent shadows. Our project page is at: https://taohuumd.github.io/projects/SurMo/
Generating Content for HDR Deghosting from Frequency View
Apr 01, 2024Recovering ghost-free High Dynamic Range (HDR) images from multiple Low Dynamic Range (LDR) images becomes challenging when the LDR images exhibit saturation and significant motion. Recent Diffusion Models (DMs) have been introduced in HDR imaging field, demonstrating promising performance, particularly in achieving visually perceptible results compared to previous DNN-based methods. However, DMs require extensive iterations with large models to estimate entire images, resulting in inefficiency that hinders their practical application. To address this challenge, we propose the Low-Frequency aware Diffusion (LF-Diff) model for ghost-free HDR imaging. The key idea of LF-Diff is implementing the DMs in a highly compacted latent space and integrating it into a regression-based model to enhance the details of reconstructed images. Specifically, as low-frequency information is closely related to human visual perception we propose to utilize DMs to create compact low-frequency priors for the reconstruction process. In addition, to take full advantage of the above low-frequency priors, the Dynamic HDR Reconstruction Network (DHRNet) is carried out in a regression-based manner to obtain final HDR images. Extensive experiments conducted on synthetic and real-world benchmark datasets demonstrate that our LF-Diff performs favorably against several state-of-the-art methods and is 10$\times$ faster than previous DM-based methods.
Boosting Image Restoration via Priors from Pre-trained Models
Mar 19, 2024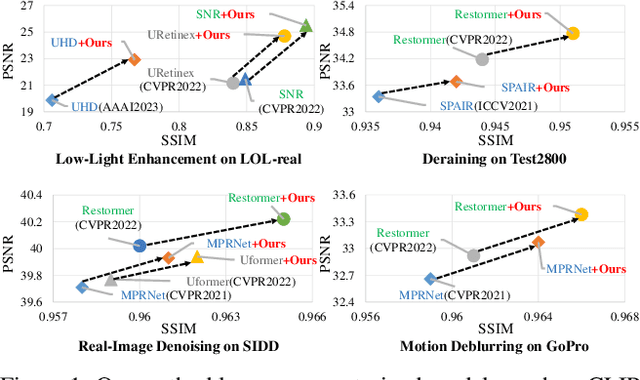

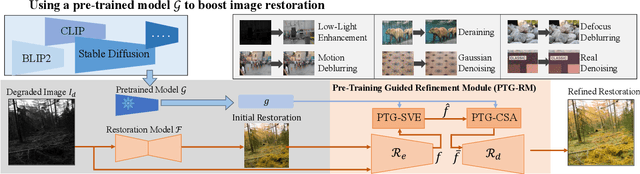
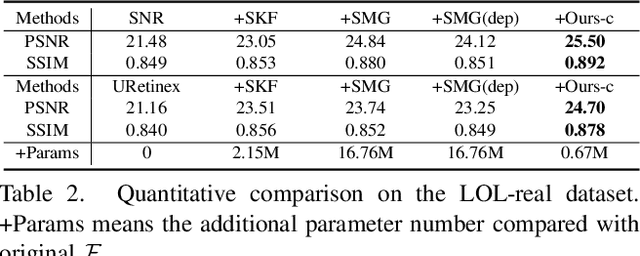
Pre-trained models with large-scale training data, such as CLIP and Stable Diffusion, have demonstrated remarkable performance in various high-level computer vision tasks such as image understanding and generation from language descriptions. Yet, their potential for low-level tasks such as image restoration remains relatively unexplored. In this paper, we explore such models to enhance image restoration. As off-the-shelf features (OSF) from pre-trained models do not directly serve image restoration, we propose to learn an additional lightweight module called Pre-Train-Guided Refinement Module (PTG-RM) to refine restoration results of a target restoration network with OSF. PTG-RM consists of two components, Pre-Train-Guided Spatial-Varying Enhancement (PTG-SVE), and Pre-Train-Guided Channel-Spatial Attention (PTG-CSA). PTG-SVE enables optimal short- and long-range neural operations, while PTG-CSA enhances spatial-channel attention for restoration-related learning. Extensive experiments demonstrate that PTG-RM, with its compact size ($<$1M parameters), effectively enhances restoration performance of various models across different tasks, including low-light enhancement, deraining, deblurring, and denoising.
AI prediction of cardiovascular events using opportunistic epicardial adipose tissue assessments from CT calcium score
Jan 29, 2024Background: Recent studies have used basic epicardial adipose tissue (EAT) assessments (e.g., volume and mean HU) to predict risk of atherosclerosis-related, major adverse cardiovascular events (MACE). Objectives: Create novel, hand-crafted EAT features, 'fat-omics', to capture the pathophysiology of EAT and improve MACE prediction. Methods: We segmented EAT using a previously-validated deep learning method with optional manual correction. We extracted 148 radiomic features (morphological, spatial, and intensity) and used Cox elastic-net for feature reduction and prediction of MACE. Results: Traditional fat features gave marginal prediction (EAT-volume/EAT-mean-HU/ BMI gave C-index 0.53/0.55/0.57, respectively). Significant improvement was obtained with 15 fat-omics features (C-index=0.69, test set). High-risk features included volume-of-voxels-having-elevated-HU-[-50, -30-HU] and HU-negative-skewness, both of which assess high HU, which as been implicated in fat inflammation. Other high-risk features include kurtosis-of-EAT-thickness, reflecting the heterogeneity of thicknesses, and EAT-volume-in-the-top-25%-of-the-heart, emphasizing adipose near the proximal coronary arteries. Kaplan-Meyer plots of Cox-identified, high- and low-risk patients were well separated with the median of the fat-omics risk, while high-risk group having HR 2.4 times that of the low-risk group (P<0.001). Conclusion: Preliminary findings indicate an opportunity to use more finely tuned, explainable assessments on EAT for improved cardiovascular risk prediction.