 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenhang Ge
X-Ray: A Sequential 3D Representation for Generation
Apr 22, 2024
In this paper, we introduce X-Ray, an innovative approach to 3D generation that employs a new sequential representation, drawing inspiration from the depth-revealing capabilities of X-Ray scans to meticulously capture both the external and internal features of objects. Central to our method is the utilization of ray casting techniques originating from the camera's viewpoint, meticulously recording the geometric and textural details encountered across all intersected surfaces. This process efficiently condenses complete objects or scenes into a multi-frame format, just like videos. Such a structure ensures the 3D representation is composed solely of critical surface information. Highlighting the practicality and adaptability of our X-Ray representation, we showcase its utility in synthesizing 3D objects, employing a network architecture akin to that used in video diffusion models. The outcomes reveal our representation's superior performance in enhancing both the accuracy and efficiency of 3D synthesis, heralding new directions for ongoing research and practical implementations in the field.
Ref-NeuS: Ambiguity-Reduced Neural Implicit Surface Learning for Multi-View Reconstruction with Reflection
Mar 20, 2023
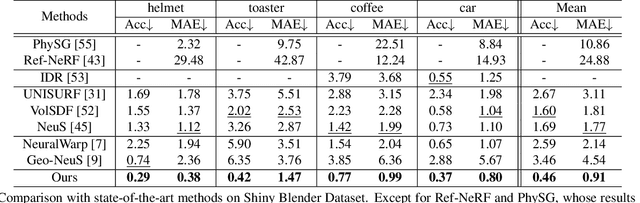
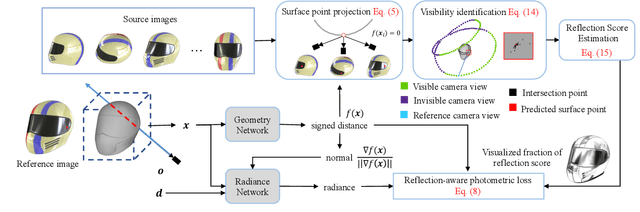
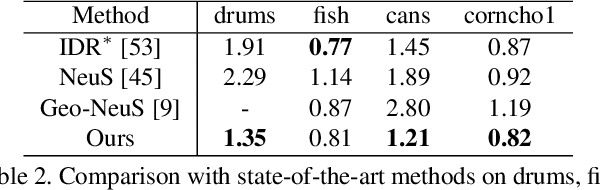
Neural implicit surface learning has shown significant progress in multi-view 3D reconstruction, where an object is represented by multilayer perceptrons that provide continuous implicit surface representation and view-dependent radiance. However, current methods often fail to accurately reconstruct reflective surfaces, leading to severe ambiguity. To overcome this issue, we propose Ref-NeuS, which aims to reduce ambiguity by attenuating the importance of reflective surfaces. Specifically, we utilize an anomaly detector to estimate an explicit reflection score with the guidance of multi-view context to localize reflective surfaces. Afterward, we design a reflection-aware photometric loss that adaptively reduces ambiguity by modeling rendered color as a Gaussian distribution, with the reflection score representing the variance. We show that together with a reflection direction-dependent radiance, our model achieves high-quality surface reconstruction on reflective surfaces and outperforms the state-of-the-arts by a large margin. Besides, our model is also comparable on general surfaces.
Text-Adaptive Multiple Visual Prototype Matching for Video-Text Retrieval
Sep 27, 2022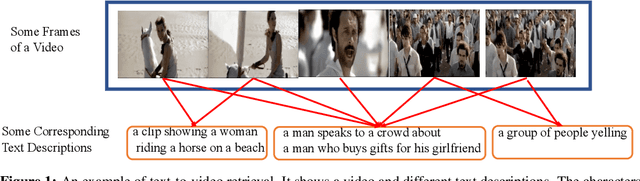
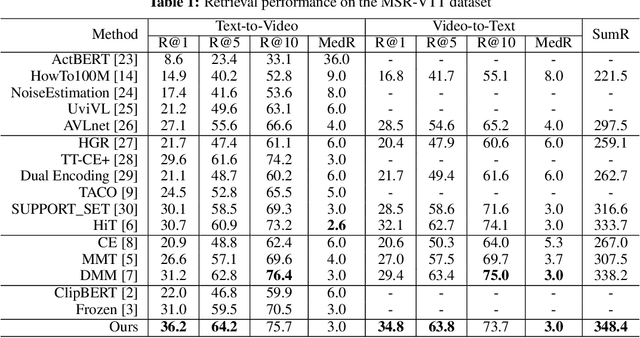
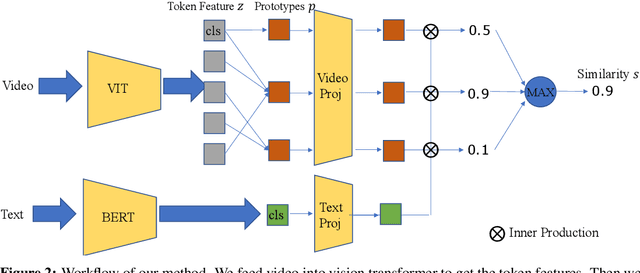
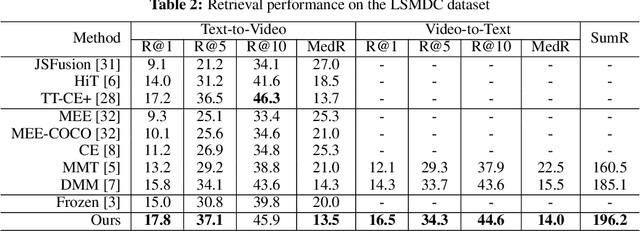
Cross-modal retrieval between videos and texts has gained increasing research interest due to the rapid emergence of videos on the web. Generally, a video contains rich instance and event information and the query text only describes a part of the information. Thus, a video can correspond to multiple different text descriptions and queries. We call this phenomenon the ``Video-Text Correspondence Ambiguity'' problem. Current techniques mostly concentrate on mining local or multi-level alignment between contents of a video and text (\textit{e.g.}, object to entity and action to verb). It is difficult for these methods to alleviate the video-text correspondence ambiguity by describing a video using only one single feature, which is required to be matched with multiple different text features at the same time. To address this problem, we propose a Text-Adaptive Multiple Visual Prototype Matching model, which automatically captures multiple prototypes to describe a video by adaptive aggregation of video token features. Given a query text, the similarity is determined by the most similar prototype to find correspondence in the video, which is termed text-adaptive matching. To learn diverse prototypes for representing the rich information in videos, we propose a variance loss to encourage different prototypes to attend to different contents of the video. Our method outperforms state-of-the-art methods on four public video retrieval datasets.
* NIPS2022
Camera-Conditioned Stable Feature Generation for Isolated Camera Supervised Person Re-IDentification
Apr 04, 2022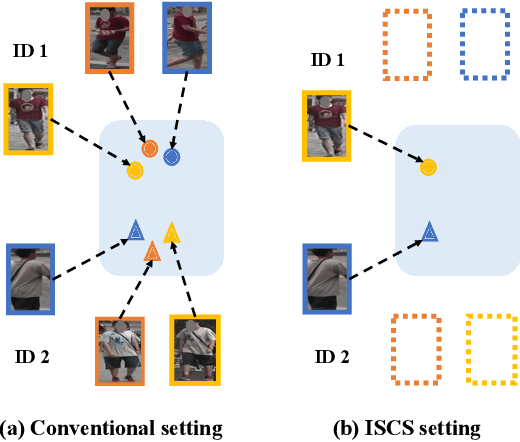
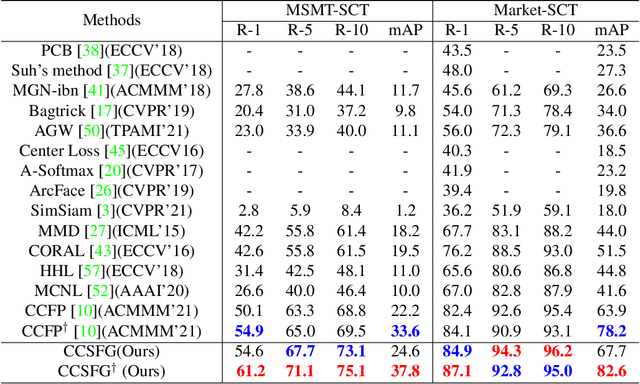
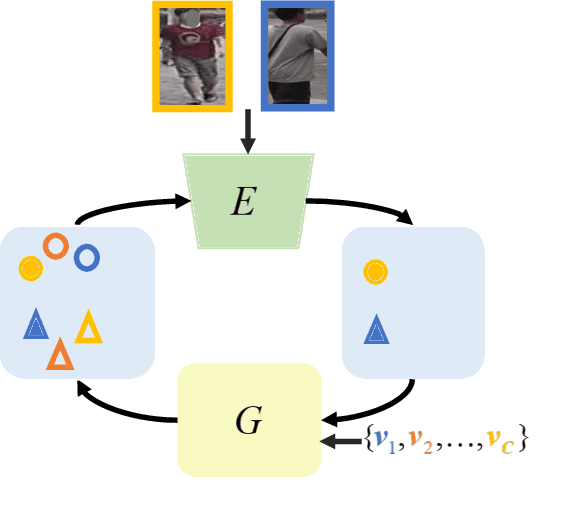
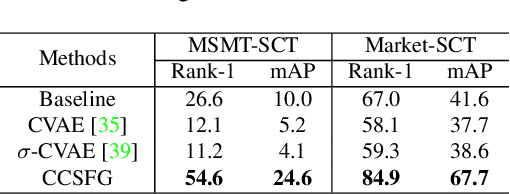
To learn camera-view invariant features for person Re-IDentification (Re-ID), the cross-camera image pairs of each person play an important role. However, such cross-view training samples could be unavailable under the ISolated Camera Supervised (ISCS) setting, e.g., a surveillance system deployed across distant scenes. To handle this challenging problem, a new pipeline is introduced by synthesizing the cross-camera samples in the feature space for model training. Specifically, the feature encoder and generator are end-to-end optimized under a novel method, Camera-Conditioned Stable Feature Generation (CCSFG). Its joint learning procedure raises concern on the stability of generative model training. Therefore, a new feature generator, $\sigma$-Regularized Conditional Variational Autoencoder ($\sigma$-Reg.~CVAE), is proposed with theoretical and experimental analysis on its robustness. Extensive experiments on two ISCS person Re-ID datasets demonstrate the superiority of our CCSFG to the competitors.
Cross-Camera Feature Prediction for Intra-Camera Supervised Person Re-identification across Distant Scenes
Jul 29, 2021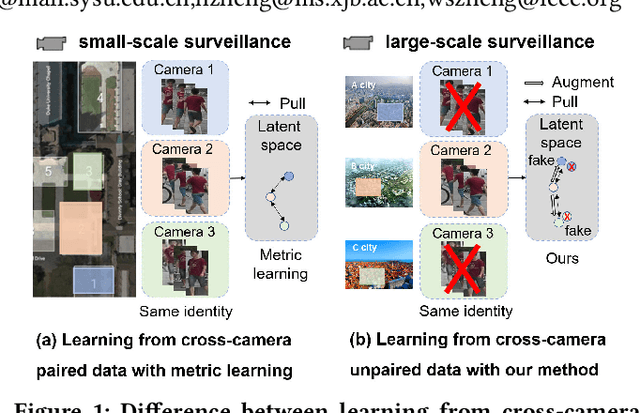
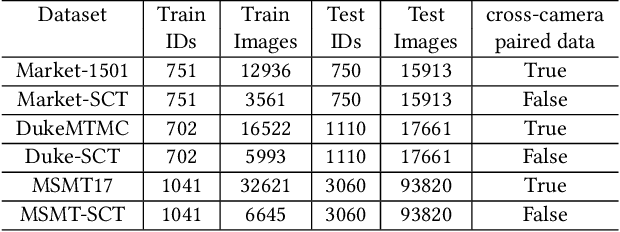
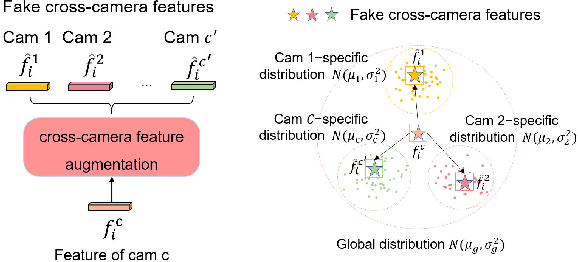
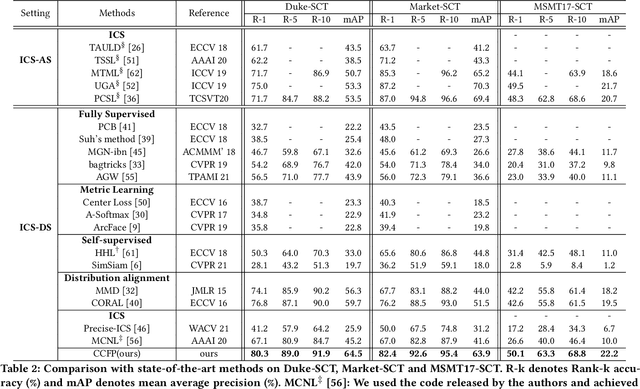
Person re-identification (Re-ID) aims to match person images across non-overlapping camera views. The majority of Re-ID methods focus on small-scale surveillance systems in which each pedestrian is captured in different camera views of adjacent scenes. However, in large-scale surveillance systems that cover larger areas, it is required to track a pedestrian of interest across distant scenes (e.g., a criminal suspect escapes from one city to another). Since most pedestrians appear in limited local areas, it is difficult to collect training data with cross-camera pairs of the same person. In this work, we study intra-camera supervised person re-identification across distant scenes (ICS-DS Re-ID), which uses cross-camera unpaired data with intra-camera identity labels for training. It is challenging as cross-camera paired data plays a crucial role for learning camera-invariant features in most existing Re-ID methods. To learn camera-invariant representation from cross-camera unpaired training data, we propose a cross-camera feature prediction method to mine cross-camera self supervision information from camera-specific feature distribution by transforming fake cross-camera positive feature pairs and minimize the distances of the fake pairs. Furthermore, we automatically localize and extract local-level feature by a transformer. Joint learning of global-level and local-level features forms a global-local cross-camera feature prediction scheme for mining fine-grained cross-camera self supervision information. Finally, cross-camera self supervision and intra-camera supervision are aggregated in a framework. The experiments are conducted in the ICS-DS setting on Market-SCT, Duke-SCT and MSMT17-SCT datasets. The evaluation results demonstrate the superiority of our method, which gains significant improvements of 15.4 Rank-1 and 22.3 mAP on Market-SCT as compared to the second best method.