 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaoyu Zhao
MoreStyle: Relax Low-frequency Constraint of Fourier-based Image Reconstruction in Generalizable Medical Image Segmentation
Mar 19, 2024
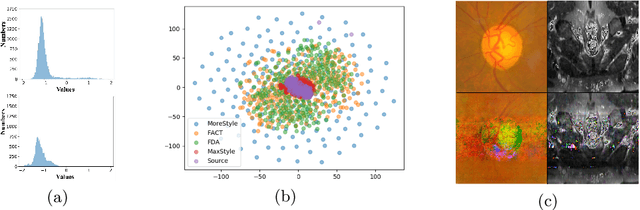
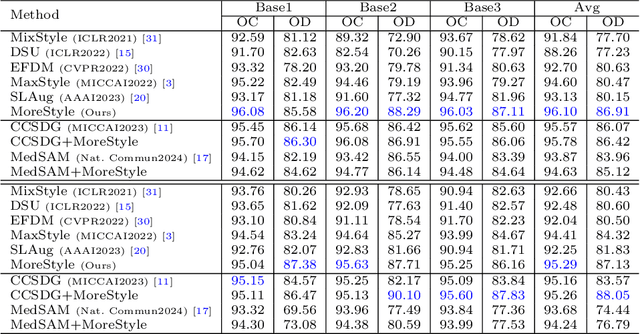
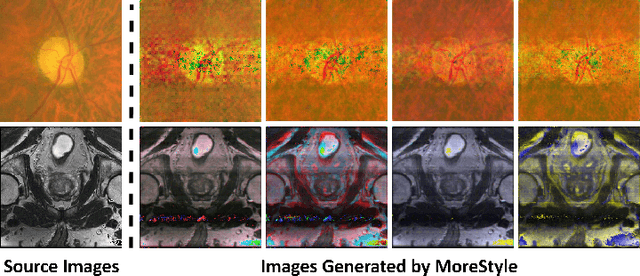
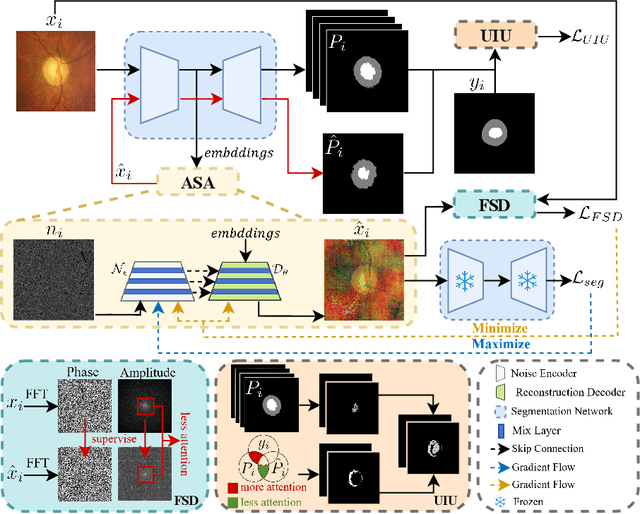
The task of single-source domain generalization (SDG) in medical image segmentation is crucial due to frequent domain shifts in clinical image datasets. To address the challenge of poor generalization across different domains, we introduce a Plug-and-Play module for data augmentation called MoreStyle. MoreStyle diversifies image styles by relaxing low-frequency constraints in Fourier space, guiding the image reconstruction network. With the help of adversarial learning, MoreStyle further expands the style range and pinpoints the most intricate style combinations within latent features. To handle significant style variations, we introduce an uncertainty-weighted loss. This loss emphasizes hard-to-classify pixels resulting only from style shifts while mitigating true hard-to-classify pixels in both MoreStyle-generated and original images. Extensive experiments on two widely used benchmarks demonstrate that the proposed MoreStyle effectively helps to achieve good domain generalization ability, and has the potential to further boost the performance of some state-of-the-art SDG methods.
WIA-LD2ND: Wavelet-based Image Alignment for Self-supervised Low-Dose CT Denoising
Mar 19, 2024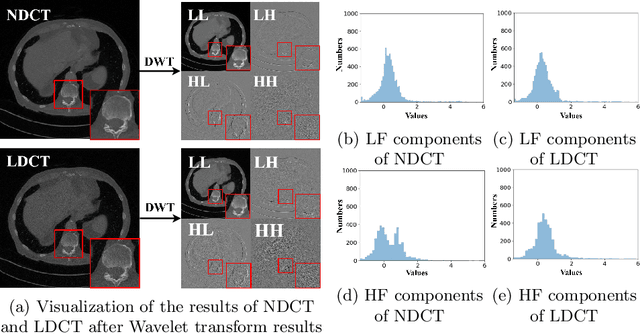


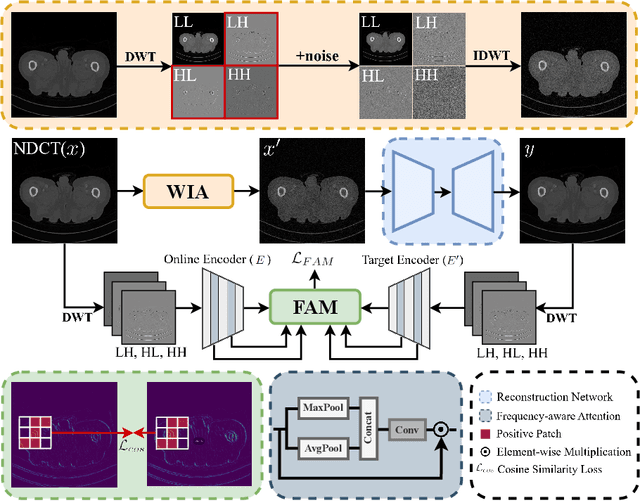
In clinical examinations and diagnoses, low-dose computed tomography (LDCT) is crucial for minimizing health risks compared with normal-dose computed tomography (NDCT). However, reducing the radiation dose compromises the signal-to-noise ratio, leading to degraded quality of CT images. To address this, we analyze LDCT denoising task based on experimental results from the frequency perspective, and then introduce a novel self-supervised CT image denoising method called WIA-LD2ND, only using NDCT data. The proposed WIA-LD2ND comprises two modules: Wavelet-based Image Alignment (WIA) and Frequency-Aware Multi-scale Loss (FAM). First, WIA is introduced to align NDCT with LDCT by mainly adding noise to the high-frequency components, which is the main difference between LDCT and NDCT. Second, to better capture high-frequency components and detailed information, Frequency-Aware Multi-scale Loss (FAM) is proposed by effectively utilizing multi-scale feature space. Extensive experiments on two public LDCT denoising datasets demonstrate that our WIA-LD2ND, only uses NDCT, outperforms existing several state-of-the-art weakly-supervised and self-supervised methods.
Keeping LLMs Aligned After Fine-tuning: The Crucial Role of Prompt Templates
Feb 28, 2024Public LLMs such as the Llama 2-Chat have driven huge activity in LLM research. These models underwent alignment training and were considered safe. Recently Qi et al. (2023) reported that even benign fine-tuning (e.g., on seemingly safe datasets) can give rise to unsafe behaviors in the models. The current paper is about methods and best practices to mitigate such loss of alignment. Through extensive experiments on several chat models (Meta's Llama 2-Chat, Mistral AI's Mistral 7B Instruct v0.2, and OpenAI's GPT-3.5 Turbo), this paper uncovers that the prompt templates used during fine-tuning and inference play a crucial role in preserving safety alignment, and proposes the "Pure Tuning, Safe Testing" (PTST) principle -- fine-tune models without a safety prompt, but include it at test time. Fine-tuning experiments on GSM8K, ChatDoctor, and OpenOrca show that PTST significantly reduces the rise of unsafe behaviors, and even almost eliminates them in some cases.
VideoAssembler: Identity-Consistent Video Generation with Reference Entities using Diffusion Model
Dec 01, 2023Identity-consistent video generation seeks to synthesize videos that are guided by both textual prompts and reference images of entities. Current approaches typically utilize cross-attention layers to integrate the appearance of the entity, which predominantly captures semantic attributes, resulting in compromised fidelity of entities. Moreover, these methods necessitate iterative fine-tuning for each new entity encountered, thereby limiting their applicability. To address these challenges, we introduce VideoAssembler, a novel end-to-end framework for identity-consistent video generation that can conduct inference directly when encountering new entities. VideoAssembler is adept at producing videos that are not only flexible with respect to the input reference entities but also responsive to textual conditions. Additionally, by modulating the quantity of input images for the entity, VideoAssembler enables the execution of tasks ranging from image-to-video generation to sophisticated video editing. VideoAssembler comprises two principal components: the Reference Entity Pyramid (REP) encoder and the Entity-Prompt Attention Fusion (EPAF) module. The REP encoder is designed to infuse comprehensive appearance details into the denoising stages of the stable diffusion model. Concurrently, the EPAF module is utilized to integrate text-aligned features effectively. Furthermore, to mitigate the challenge of scarce data, we present a methodology for the preprocessing of training data. Our evaluation of the VideoAssembler framework on the UCF-101, MSR-VTT, and DAVIS datasets indicates that it achieves good performances in both quantitative and qualitative analyses (346.84 in FVD and 48.01 in IS on UCF-101). Our project page is at https://gulucaptain.github.io/videoassembler/.
Adversarial Attacks on Combinatorial Multi-Armed Bandits
Oct 08, 2023We study reward poisoning attacks on Combinatorial Multi-armed Bandits (CMAB). We first provide a sufficient and necessary condition for the attackability of CMAB, which depends on the intrinsic properties of the corresponding CMAB instance such as the reward distributions of super arms and outcome distributions of base arms. Additionally, we devise an attack algorithm for attackable CMAB instances. Contrary to prior understanding of multi-armed bandits, our work reveals a surprising fact that the attackability of a specific CMAB instance also depends on whether the bandit instance is known or unknown to the adversary. This finding indicates that adversarial attacks on CMAB are difficult in practice and a general attack strategy for any CMAB instance does not exist since the environment is mostly unknown to the adversary. We validate our theoretical findings via extensive experiments on real-world CMAB applications including probabilistic maximum covering problem, online minimum spanning tree, cascading bandits for online ranking, and online shortest path.
Reuse and Diffuse: Iterative Denoising for Text-to-Video Generation
Sep 07, 2023
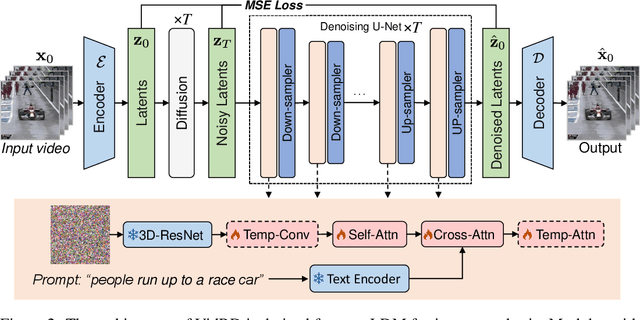
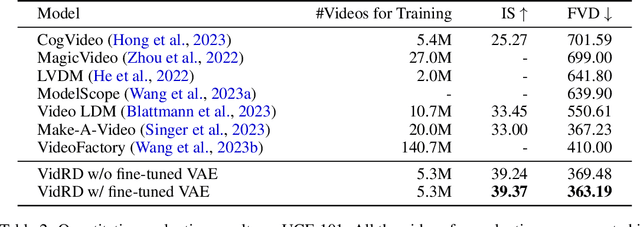
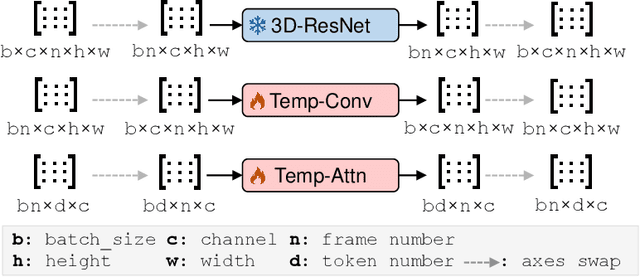
Inspired by the remarkable success of Latent Diffusion Models (LDMs) for image synthesis, we study LDM for text-to-video generation, which is a formidable challenge due to the computational and memory constraints during both model training and inference. A single LDM is usually only capable of generating a very limited number of video frames. Some existing works focus on separate prediction models for generating more video frames, which suffer from additional training cost and frame-level jittering, however. In this paper, we propose a framework called "Reuse and Diffuse" dubbed $\textit{VidRD}$ to produce more frames following the frames already generated by an LDM. Conditioned on an initial video clip with a small number of frames, additional frames are iteratively generated by reusing the original latent features and following the previous diffusion process. Besides, for the autoencoder used for translation between pixel space and latent space, we inject temporal layers into its decoder and fine-tune these layers for higher temporal consistency. We also propose a set of strategies for composing video-text data that involve diverse content from multiple existing datasets including video datasets for action recognition and image-text datasets. Extensive experiments show that our method achieves good results in both quantitative and qualitative evaluations. Our project page is available $\href{https://anonymous0x233.github.io/ReuseAndDiffuse/}{here}$.
Ref-NeuS: Ambiguity-Reduced Neural Implicit Surface Learning for Multi-View Reconstruction with Reflection
Mar 20, 2023
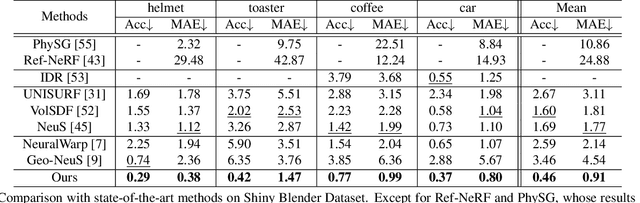
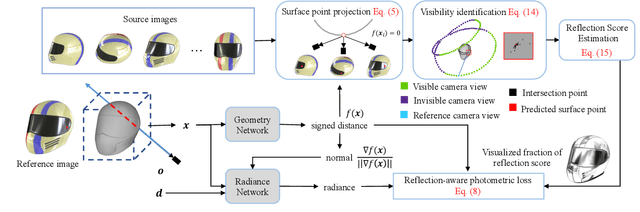
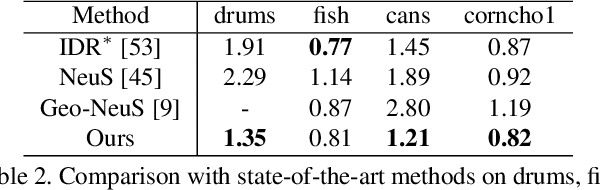
Neural implicit surface learning has shown significant progress in multi-view 3D reconstruction, where an object is represented by multilayer perceptrons that provide continuous implicit surface representation and view-dependent radiance. However, current methods often fail to accurately reconstruct reflective surfaces, leading to severe ambiguity. To overcome this issue, we propose Ref-NeuS, which aims to reduce ambiguity by attenuating the importance of reflective surfaces. Specifically, we utilize an anomaly detector to estimate an explicit reflection score with the guidance of multi-view context to localize reflective surfaces. Afterward, we design a reflection-aware photometric loss that adaptively reduces ambiguity by modeling rendered color as a Gaussian distribution, with the reflection score representing the variance. We show that together with a reflection direction-dependent radiance, our model achieves high-quality surface reconstruction on reflective surfaces and outperforms the state-of-the-arts by a large margin. Besides, our model is also comparable on general surfaces.
Do Transformers Parse while Predicting the Masked Word?
Mar 14, 2023

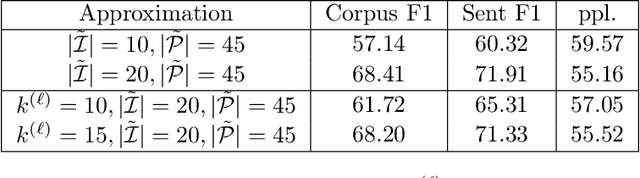
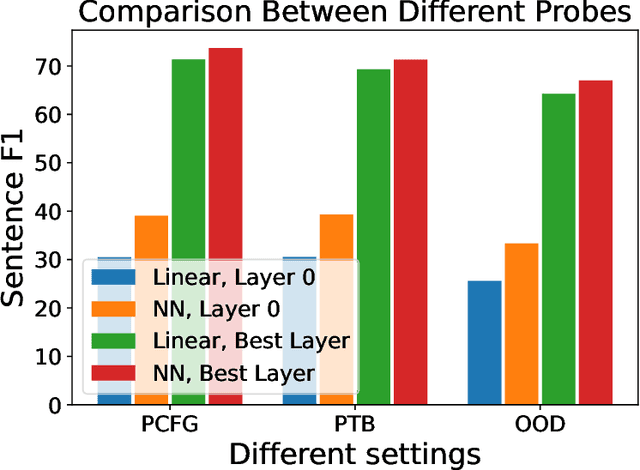
Pre-trained language models have been shown to encode linguistic structures, e.g. dependency and constituency parse trees, in their embeddings while being trained on unsupervised loss functions like masked language modeling. Some doubts have been raised whether the models actually are doing parsing or only some computation weakly correlated with it. We study questions: (a) Is it possible to explicitly describe transformers with realistic embedding dimension, number of heads, etc. that are capable of doing parsing -- or even approximate parsing? (b) Why do pre-trained models capture parsing structure? This paper takes a step toward answering these questions in the context of generative modeling with PCFGs. We show that masked language models like BERT or RoBERTa of moderate sizes can approximately execute the Inside-Outside algorithm for the English PCFG [Marcus et al, 1993]. We also show that the Inside-Outside algorithm is optimal for masked language modeling loss on the PCFG-generated data. We also give a construction of transformers with $50$ layers, $15$ attention heads, and $1275$ dimensional embeddings in average such that using its embeddings it is possible to do constituency parsing with $>70\%$ F1 score on PTB dataset. We conduct probing experiments on models pre-trained on PCFG-generated data to show that this not only allows recovery of approximate parse tree, but also recovers marginal span probabilities computed by the Inside-Outside algorithm, which suggests an implicit bias of masked language modeling towards this algorithm.
Task-Specific Skill Localization in Fine-tuned Language Models
Feb 13, 2023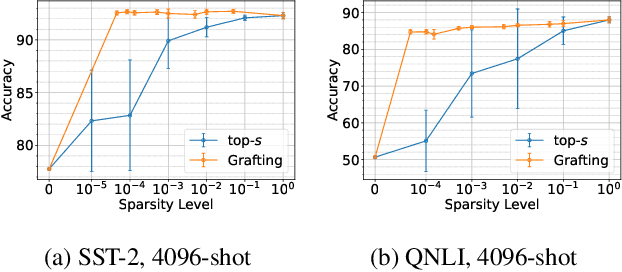
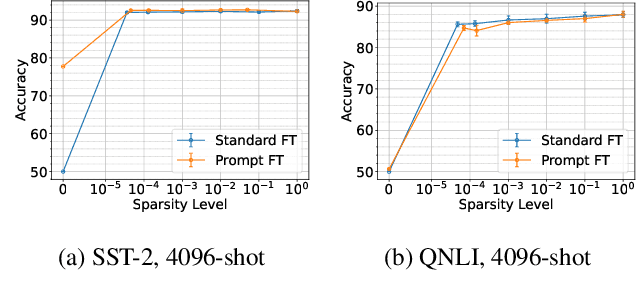
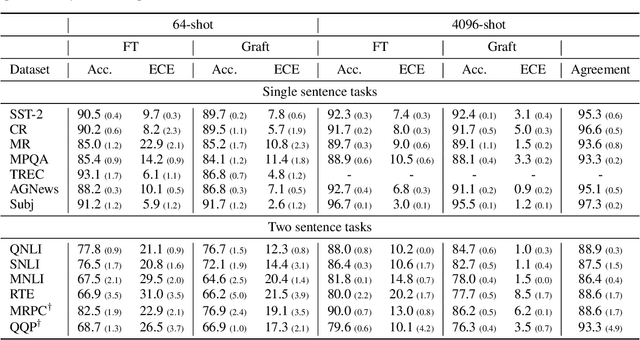
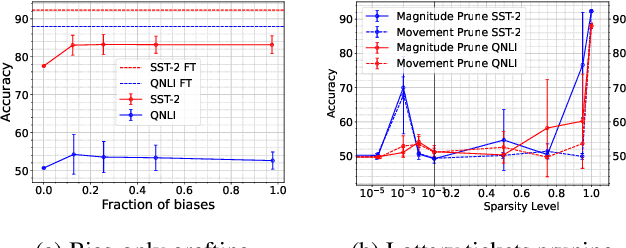
Pre-trained language models can be fine-tuned to solve diverse NLP tasks, including in few-shot settings. Thus fine-tuning allows the model to quickly pick up task-specific ``skills,'' but there has been limited study of where these newly-learnt skills reside inside the massive model. This paper introduces the term skill localization for this problem and proposes a solution. Given the downstream task and a model fine-tuned on that task, a simple optimization is used to identify a very small subset of parameters ($\sim0.01$% of model parameters) responsible for ($>95$%) of the model's performance, in the sense that grafting the fine-tuned values for just this tiny subset onto the pre-trained model gives performance almost as well as the fine-tuned model. While reminiscent of recent works on parameter-efficient fine-tuning, the novel aspects here are that: (i) No further re-training is needed on the subset (unlike, say, with lottery tickets). (ii) Notable improvements are seen over vanilla fine-tuning with respect to calibration of predictions in-distribution ($40$-$90$% error reduction) as well as the quality of predictions out-of-distribution (OOD). In models trained on multiple tasks, a stronger notion of skill localization is observed, where the sparse regions corresponding to different tasks are almost disjoint, and their overlap (when it happens) is a proxy for task similarity. Experiments suggest that localization via grafting can assist certain forms of continual learning.
Coresets for Vertical Federated Learning: Regularized Linear Regression and $K$-Means Clustering
Oct 26, 2022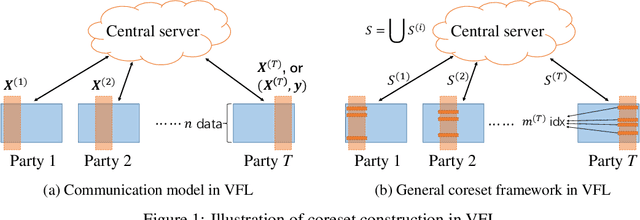
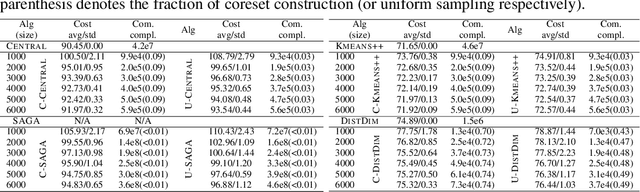
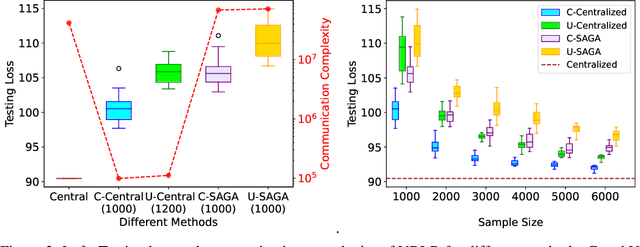
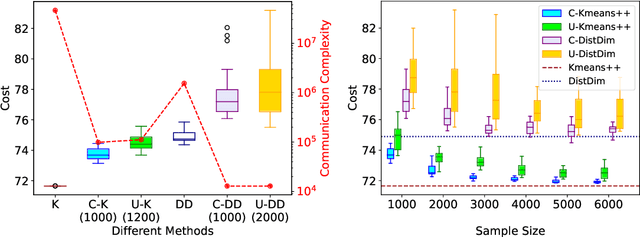
Vertical federated learning (VFL), where data features are stored in multiple parties distributively, is an important area in machine learning. However, the communication complexity for VFL is typically very high. In this paper, we propose a unified framework by constructing coresets in a distributed fashion for communication-efficient VFL. We study two important learning tasks in the VFL setting: regularized linear regression and $k$-means clustering, and apply our coreset framework to both problems. We theoretically show that using coresets can drastically alleviate the communication complexity, while nearly maintain the solution quality. Numerical experiments are conducted to corroborate our theoretical findings.