 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRui Yu
MoreStyle: Relax Low-frequency Constraint of Fourier-based Image Reconstruction in Generalizable Medical Image Segmentation
Mar 19, 2024
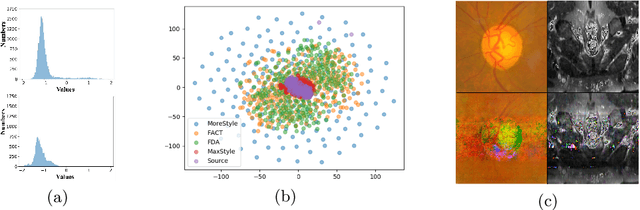
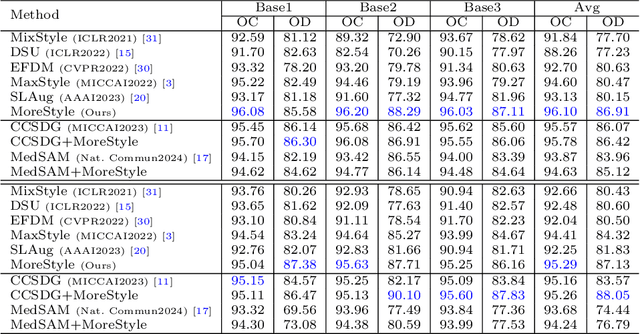
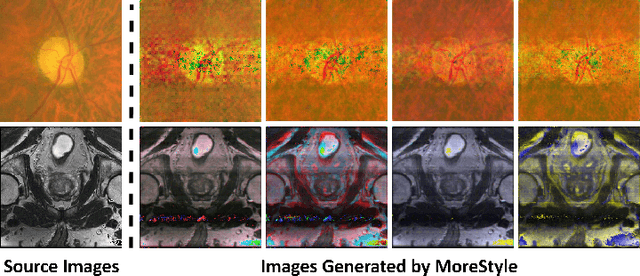
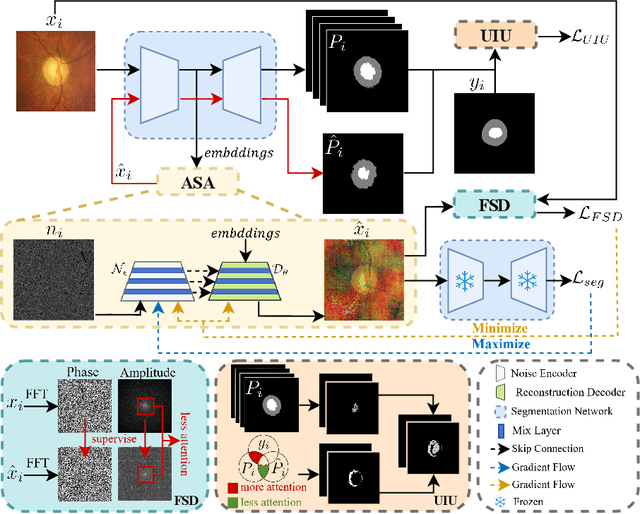
The task of single-source domain generalization (SDG) in medical image segmentation is crucial due to frequent domain shifts in clinical image datasets. To address the challenge of poor generalization across different domains, we introduce a Plug-and-Play module for data augmentation called MoreStyle. MoreStyle diversifies image styles by relaxing low-frequency constraints in Fourier space, guiding the image reconstruction network. With the help of adversarial learning, MoreStyle further expands the style range and pinpoints the most intricate style combinations within latent features. To handle significant style variations, we introduce an uncertainty-weighted loss. This loss emphasizes hard-to-classify pixels resulting only from style shifts while mitigating true hard-to-classify pixels in both MoreStyle-generated and original images. Extensive experiments on two widely used benchmarks demonstrate that the proposed MoreStyle effectively helps to achieve good domain generalization ability, and has the potential to further boost the performance of some state-of-the-art SDG methods.
WIA-LD2ND: Wavelet-based Image Alignment for Self-supervised Low-Dose CT Denoising
Mar 19, 2024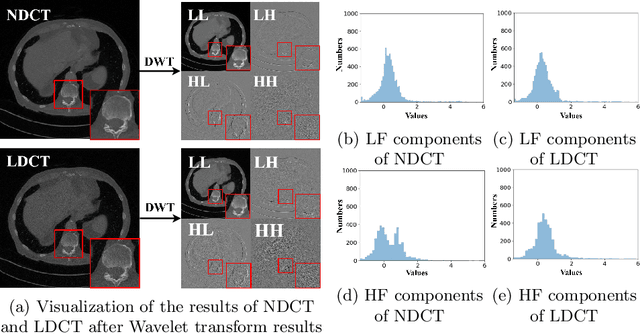


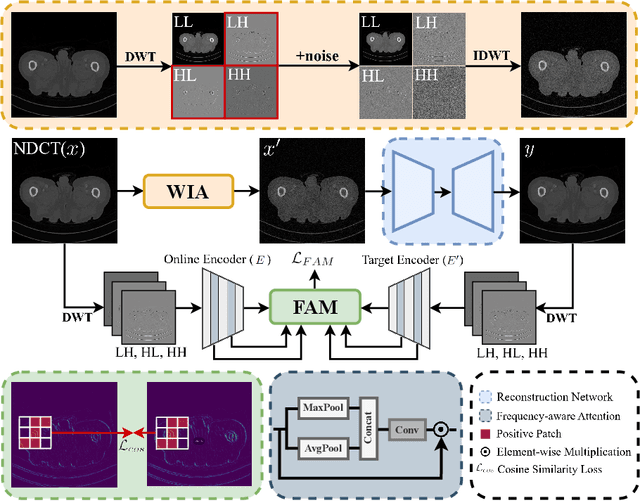
In clinical examinations and diagnoses, low-dose computed tomography (LDCT) is crucial for minimizing health risks compared with normal-dose computed tomography (NDCT). However, reducing the radiation dose compromises the signal-to-noise ratio, leading to degraded quality of CT images. To address this, we analyze LDCT denoising task based on experimental results from the frequency perspective, and then introduce a novel self-supervised CT image denoising method called WIA-LD2ND, only using NDCT data. The proposed WIA-LD2ND comprises two modules: Wavelet-based Image Alignment (WIA) and Frequency-Aware Multi-scale Loss (FAM). First, WIA is introduced to align NDCT with LDCT by mainly adding noise to the high-frequency components, which is the main difference between LDCT and NDCT. Second, to better capture high-frequency components and detailed information, Frequency-Aware Multi-scale Loss (FAM) is proposed by effectively utilizing multi-scale feature space. Extensive experiments on two public LDCT denoising datasets demonstrate that our WIA-LD2ND, only uses NDCT, outperforms existing several state-of-the-art weakly-supervised and self-supervised methods.
Progressive Feature Fusion Network for Enhancing Image Quality Assessment
Jan 13, 2024Image compression has been applied in the fields of image storage and video broadcasting. However, it's formidably tough to distinguish the subtle quality differences between those distorted images generated by different algorithms. In this paper, we propose a new image quality assessment framework to decide which image is better in an image group. To capture the subtle differences, a fine-grained network is adopted to acquire multi-scale features. Subsequently, we design a cross subtract block for separating and gathering the information within positive and negative image pairs. Enabling image comparison in feature space. After that, a progressive feature fusion block is designed, which fuses multi-scale features in a novel progressive way. Hierarchical spatial 2D features can thus be processed gradually. Experimental results show that compared with the current mainstream image quality assessment methods, the proposed network can achieve more accurate image quality assessment and ranks second in the benchmark of CLIC in the image perceptual model track.
NeRF-Enhanced Outpainting for Faithful Field-of-View Extrapolation
Sep 23, 2023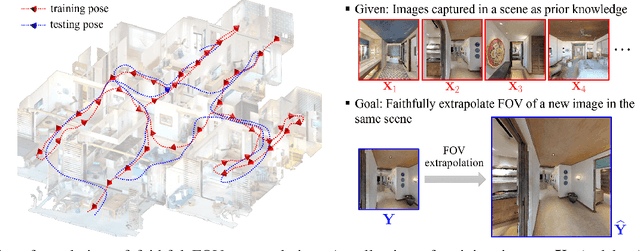



In various applications, such as robotic navigation and remote visual assistance, expanding the field of view (FOV) of the camera proves beneficial for enhancing environmental perception. Unlike image outpainting techniques aimed solely at generating aesthetically pleasing visuals, these applications demand an extended view that faithfully represents the scene. To achieve this, we formulate a new problem of faithful FOV extrapolation that utilizes a set of pre-captured images as prior knowledge of the scene. To address this problem, we present a simple yet effective solution called NeRF-Enhanced Outpainting (NEO) that uses extended-FOV images generated through NeRF to train a scene-specific image outpainting model. To assess the performance of NEO, we conduct comprehensive evaluations on three photorealistic datasets and one real-world dataset. Extensive experiments on the benchmark datasets showcase the robustness and potential of our method in addressing this challenge. We believe our work lays a strong foundation for future exploration within the research community.
Tri-Attention: Explicit Context-Aware Attention Mechanism for Natural Language Processing
Nov 05, 2022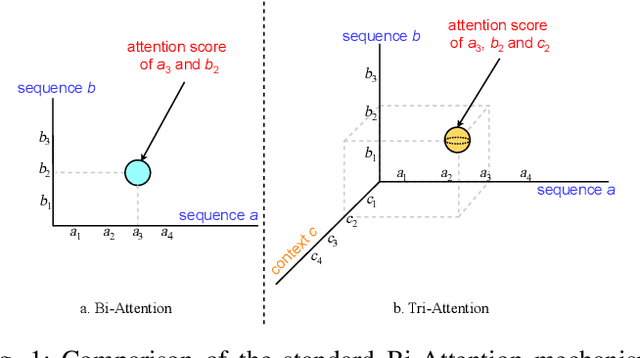
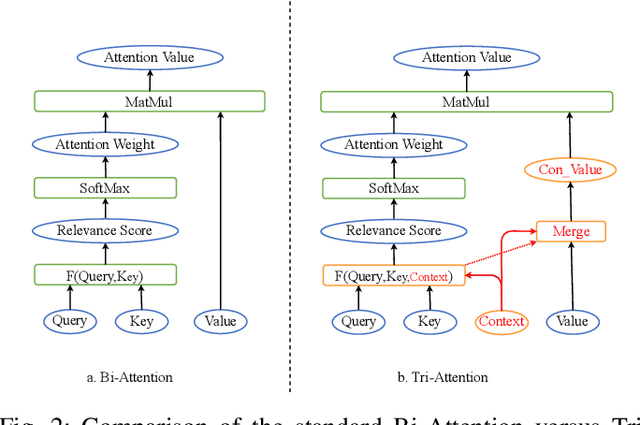
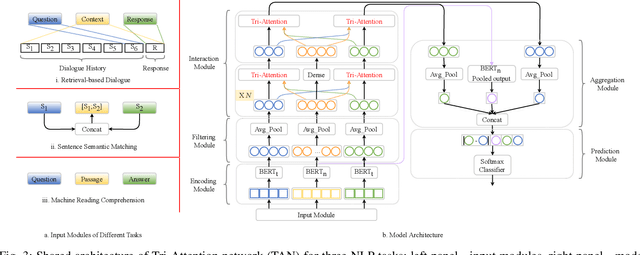

In natural language processing (NLP), the context of a word or sentence plays an essential role. Contextual information such as the semantic representation of a passage or historical dialogue forms an essential part of a conversation and a precise understanding of the present phrase or sentence. However, the standard attention mechanisms typically generate weights using query and key but ignore context, forming a Bi-Attention framework, despite their great success in modeling sequence alignment. This Bi-Attention mechanism does not explicitly model the interactions between the contexts, queries and keys of target sequences, missing important contextual information and resulting in poor attention performance. Accordingly, a novel and general triple-attention (Tri-Attention) framework expands the standard Bi-Attention mechanism and explicitly interacts query, key, and context by incorporating context as the third dimension in calculating relevance scores. Four variants of Tri-Attention are generated by expanding the two-dimensional vector-based additive, dot-product, scaled dot-product, and bilinear operations in Bi-Attention to the tensor operations for Tri-Attention. Extensive experiments on three NLP tasks demonstrate that Tri-Attention outperforms about 30 state-of-the-art non-attention, standard Bi-Attention, contextual Bi-Attention approaches and pretrained neural language models1.
Cascade Transformers for End-to-End Person Search
Mar 17, 2022
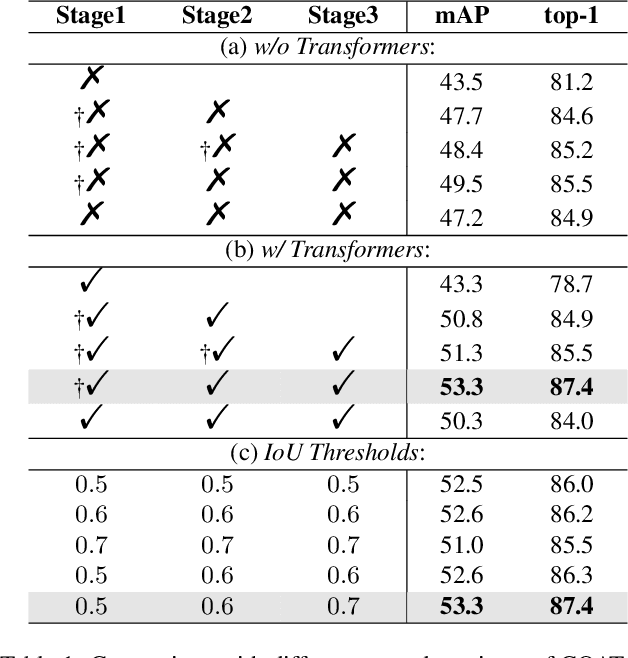
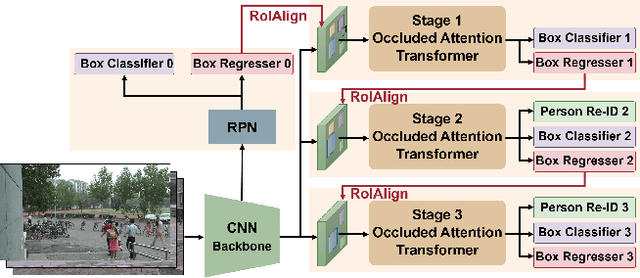
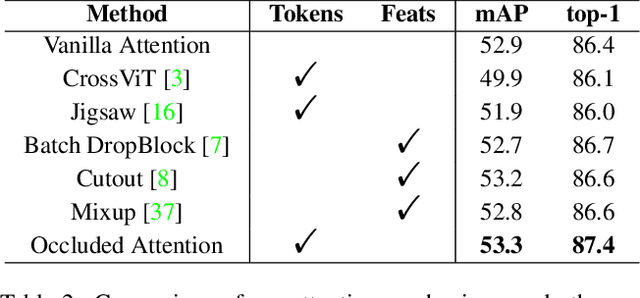
The goal of person search is to localize a target person from a gallery set of scene images, which is extremely challenging due to large scale variations, pose/viewpoint changes, and occlusions. In this paper, we propose the Cascade Occluded Attention Transformer (COAT) for end-to-end person search. Our three-stage cascade design focuses on detecting people in the first stage, while later stages simultaneously and progressively refine the representation for person detection and re-identification. At each stage the occluded attention transformer applies tighter intersection over union thresholds, forcing the network to learn coarse-to-fine pose/scale invariant features. Meanwhile, we calculate each detection's occluded attention to differentiate a person's tokens from other people or the background. In this way, we simulate the effect of other objects occluding a person of interest at the token-level. Through comprehensive experiments, we demonstrate the benefits of our method by achieving state-of-the-art performance on two benchmark datasets.
Towards Robust Human Trajectory Prediction in Raw Videos
Aug 18, 2021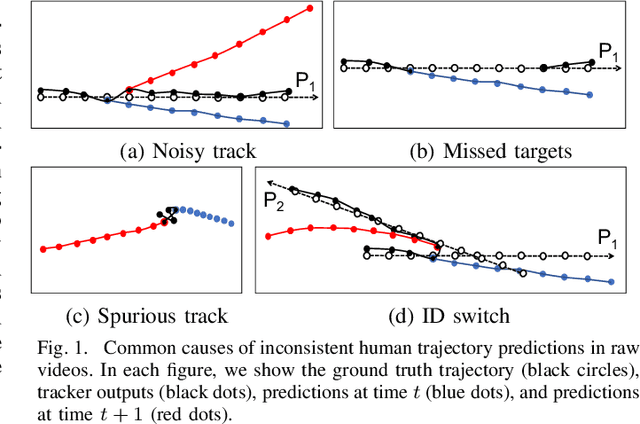

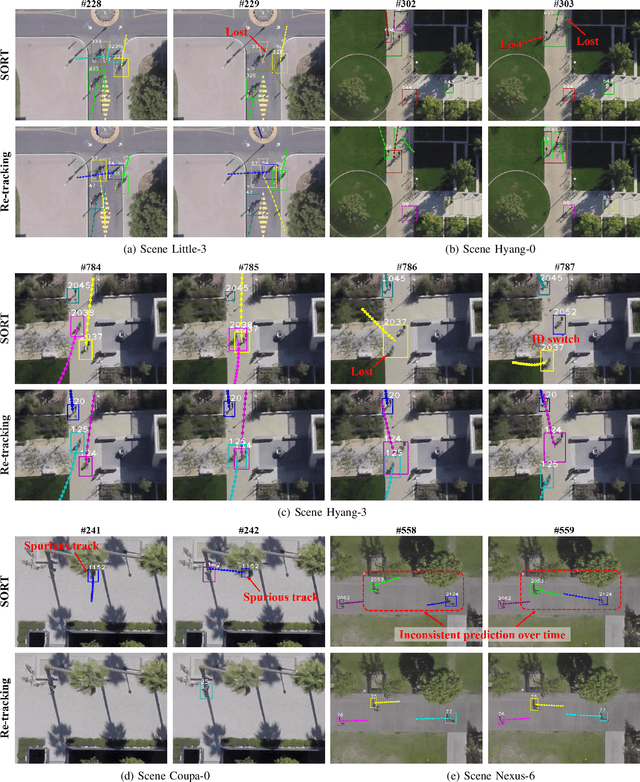
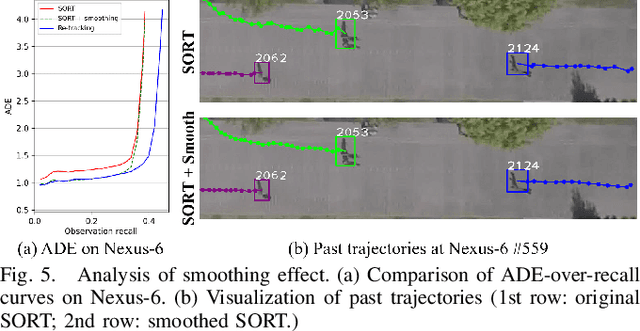
Human trajectory prediction has received increased attention lately due to its importance in applications such as autonomous vehicles and indoor robots. However, most existing methods make predictions based on human-labeled trajectories and ignore the errors and noises in detection and tracking. In this paper, we study the problem of human trajectory forecasting in raw videos, and show that the prediction accuracy can be severely affected by various types of tracking errors. Accordingly, we propose a simple yet effective strategy to correct the tracking failures by enforcing prediction consistency over time. The proposed "re-tracking" algorithm can be applied to any existing tracking and prediction pipelines. Experiments on public benchmark datasets demonstrate that the proposed method can improve both tracking and prediction performance in challenging real-world scenarios. The code and data are available at https://git.io/retracking-prediction.
Data-Driven Distributed State Estimation and Behavior Modeling in Sensor Networks
Sep 24, 2020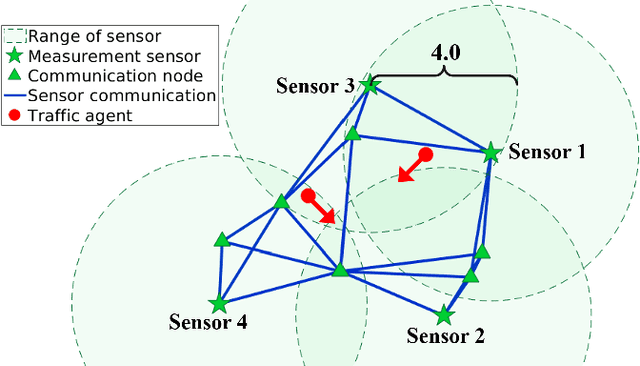


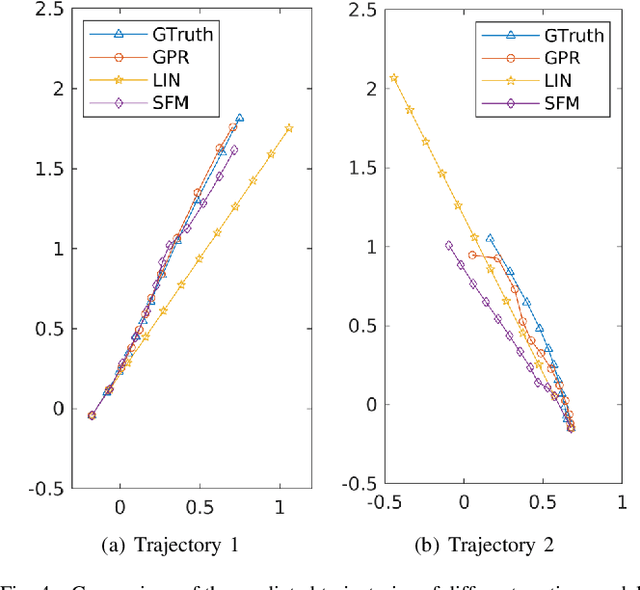
Nowadays, the prevalence of sensor networks has enabled tracking of the states of dynamic objects for a wide spectrum of applications from autonomous driving to environmental monitoring and urban planning. However, tracking real-world objects often faces two key challenges: First, due to the limitation of individual sensors, state estimation needs to be solved in a collaborative and distributed manner. Second, the objects' movement behavior is unknown, and needs to be learned using sensor observations. In this work, for the first time, we formally formulate the problem of simultaneous state estimation and behavior learning in a sensor network. We then propose a simple yet effective solution to this new problem by extending the Gaussian process-based Bayes filters (GP-BayesFilters) to an online, distributed setting. The effectiveness of the proposed method is evaluated on tracking objects with unknown movement behaviors using both synthetic data and data collected from a multi-robot platform.
Hard-Aware Point-to-Set Deep Metric for Person Re-identification
Jul 30, 2018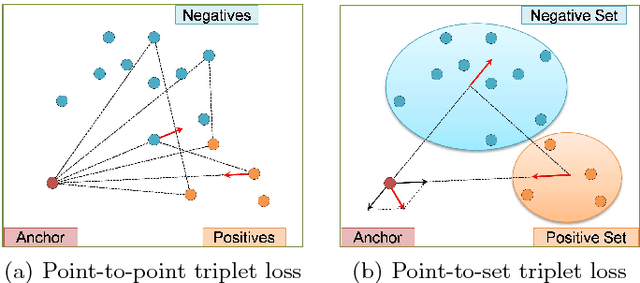
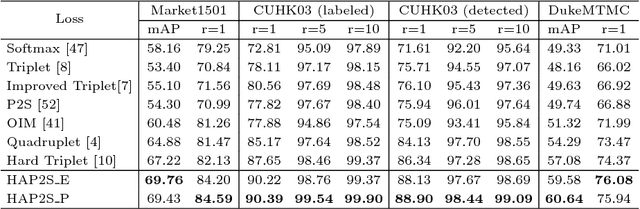
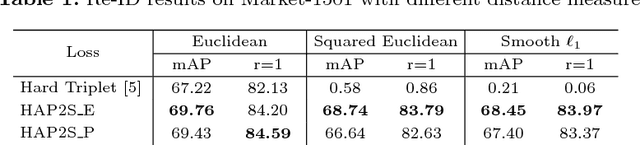
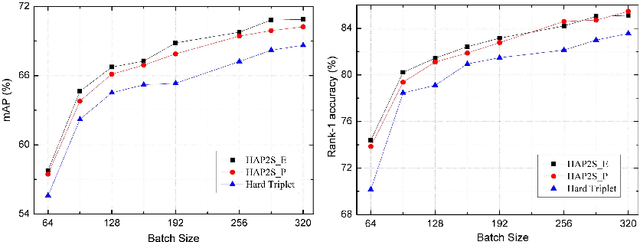
Person re-identification (re-ID) is a highly challenging task due to large variations of pose, viewpoint, illumination, and occlusion. Deep metric learning provides a satisfactory solution to person re-ID by training a deep network under supervision of metric loss, e.g., triplet loss. However, the performance of deep metric learning is greatly limited by traditional sampling methods. To solve this problem, we propose a Hard-Aware Point-to-Set (HAP2S) loss with a soft hard-mining scheme. Based on the point-to-set triplet loss framework, the HAP2S loss adaptively assigns greater weights to harder samples. Several advantageous properties are observed when compared with other state-of-the-art loss functions: 1) Accuracy: HAP2S loss consistently achieves higher re-ID accuracies than other alternatives on three large-scale benchmark datasets; 2) Robustness: HAP2S loss is more robust to outliers than other losses; 3) Flexibility: HAP2S loss does not rely on a specific weight function, i.e., different instantiations of HAP2S loss are equally effective. 4) Generality: In addition to person re-ID, we apply the proposed method to generic deep metric learning benchmarks including CUB-200-2011 and Cars196, and also achieve state-of-the-art results.
Deep-Person: Learning Discriminative Deep Features for Person Re-Identification
Jul 24, 2018
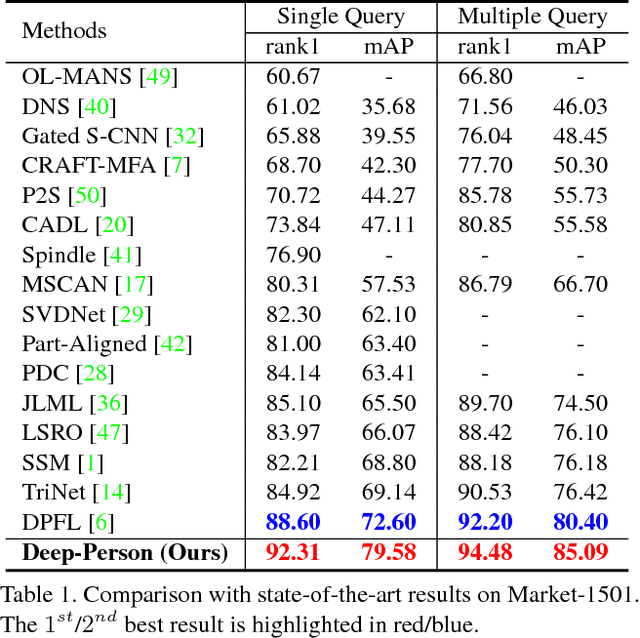
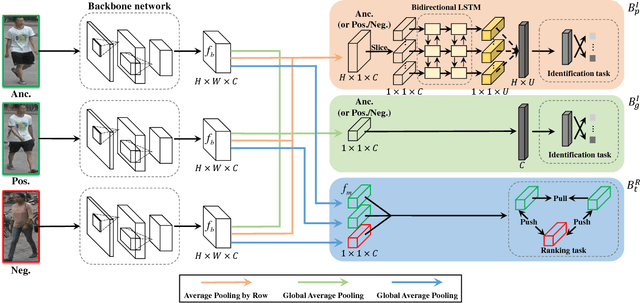
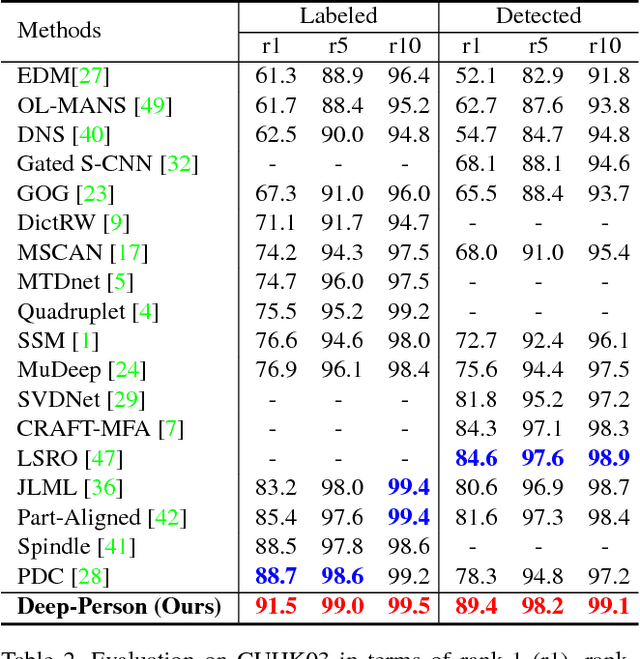
Recently, many methods of person re-identification (Re-ID) rely on part-based feature representation to learn a discriminative pedestrian descriptor. However, the spatial context between these parts is ignored for the independent extractor to each separate part. In this paper, we propose to apply Long Short-Term Memory (LSTM) in an end-to-end way to model the pedestrian, seen as a sequence of body parts from head to foot. Integrating the contextual information strengthens the discriminative ability of local representation. We also leverage the complementary information between local and global feature. Furthermore, we integrate both identification task and ranking task in one network, where a discriminative embedding and a similarity measurement are learned concurrently. This results in a novel three-branch framework named Deep-Person, which learns highly discriminative features for person Re-ID. Experimental results demonstrate that Deep-Person outperforms the state-of-the-art methods by a large margin on three challenging datasets including Market-1501, CUHK03, and DukeMTMC-reID. Specifically, combining with a re-ranking approach, we achieve a 90.84% mAP on Market-1501 under single query setting.