 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYongchao Xu
WIA-LD2ND: Wavelet-based Image Alignment for Self-supervised Low-Dose CT Denoising
Mar 19, 2024
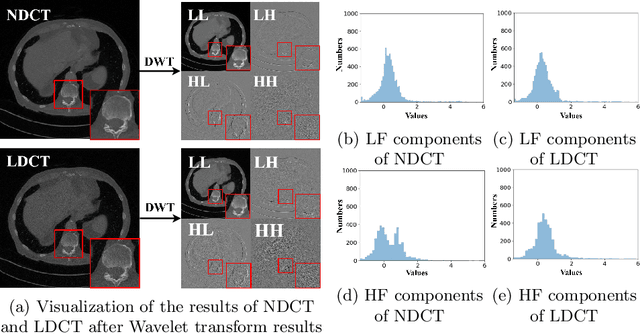


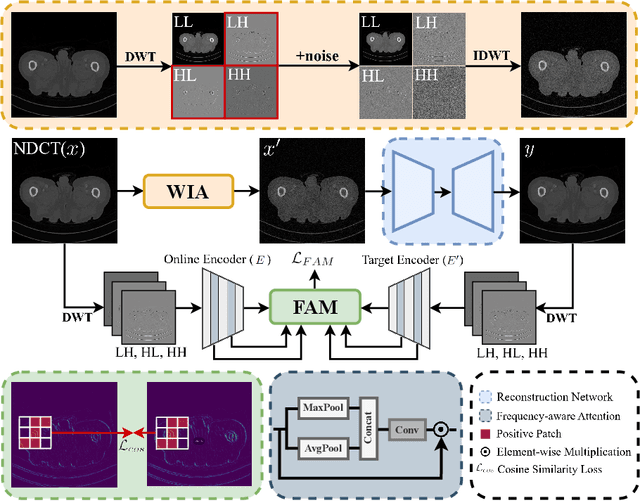
In clinical examinations and diagnoses, low-dose computed tomography (LDCT) is crucial for minimizing health risks compared with normal-dose computed tomography (NDCT). However, reducing the radiation dose compromises the signal-to-noise ratio, leading to degraded quality of CT images. To address this, we analyze LDCT denoising task based on experimental results from the frequency perspective, and then introduce a novel self-supervised CT image denoising method called WIA-LD2ND, only using NDCT data. The proposed WIA-LD2ND comprises two modules: Wavelet-based Image Alignment (WIA) and Frequency-Aware Multi-scale Loss (FAM). First, WIA is introduced to align NDCT with LDCT by mainly adding noise to the high-frequency components, which is the main difference between LDCT and NDCT. Second, to better capture high-frequency components and detailed information, Frequency-Aware Multi-scale Loss (FAM) is proposed by effectively utilizing multi-scale feature space. Extensive experiments on two public LDCT denoising datasets demonstrate that our WIA-LD2ND, only uses NDCT, outperforms existing several state-of-the-art weakly-supervised and self-supervised methods.
MoreStyle: Relax Low-frequency Constraint of Fourier-based Image Reconstruction in Generalizable Medical Image Segmentation
Mar 19, 2024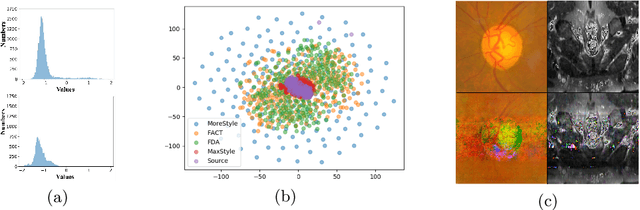
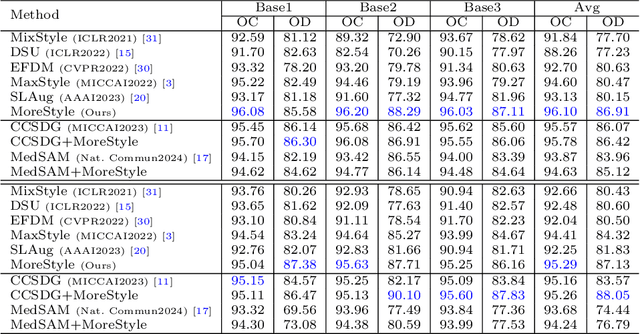
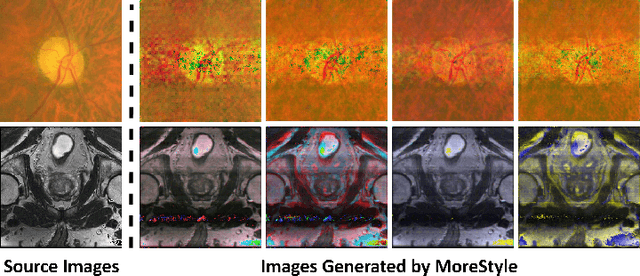
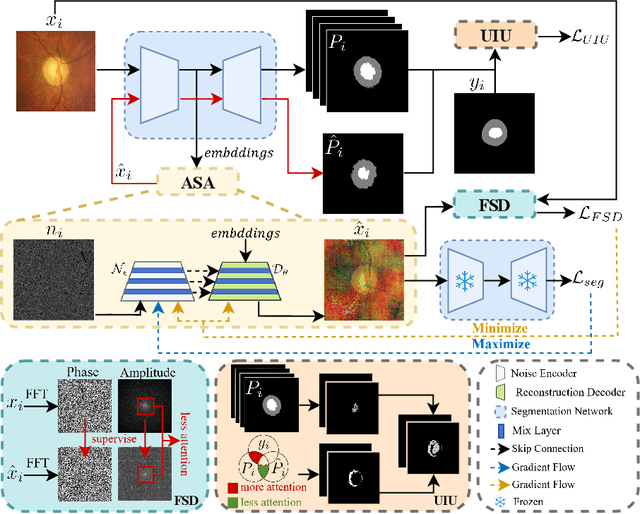
The task of single-source domain generalization (SDG) in medical image segmentation is crucial due to frequent domain shifts in clinical image datasets. To address the challenge of poor generalization across different domains, we introduce a Plug-and-Play module for data augmentation called MoreStyle. MoreStyle diversifies image styles by relaxing low-frequency constraints in Fourier space, guiding the image reconstruction network. With the help of adversarial learning, MoreStyle further expands the style range and pinpoints the most intricate style combinations within latent features. To handle significant style variations, we introduce an uncertainty-weighted loss. This loss emphasizes hard-to-classify pixels resulting only from style shifts while mitigating true hard-to-classify pixels in both MoreStyle-generated and original images. Extensive experiments on two widely used benchmarks demonstrate that the proposed MoreStyle effectively helps to achieve good domain generalization ability, and has the potential to further boost the performance of some state-of-the-art SDG methods.
Dual Structure-Preserving Image Filterings for Semi-supervised Medical Image Segmentation
Dec 12, 2023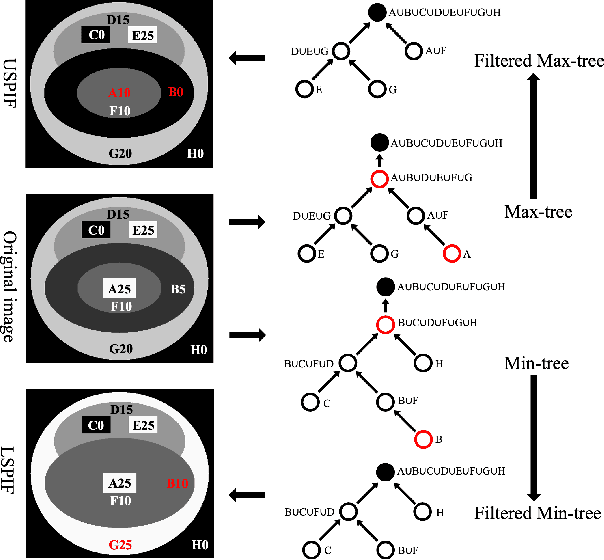
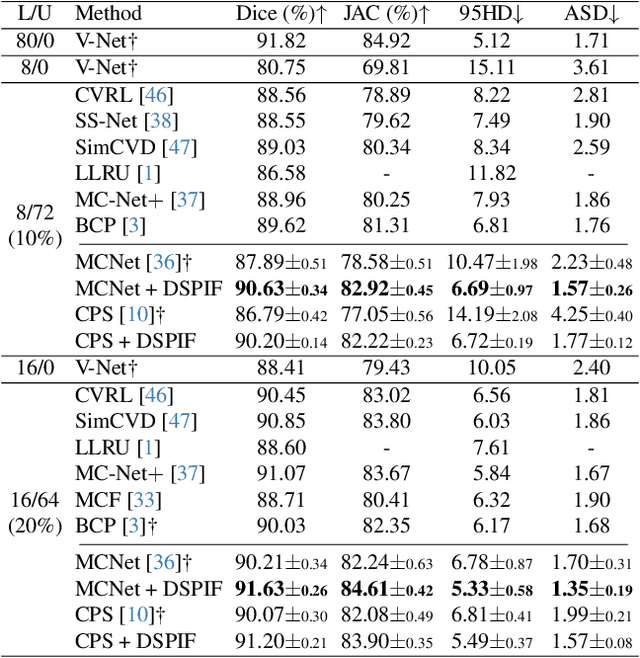
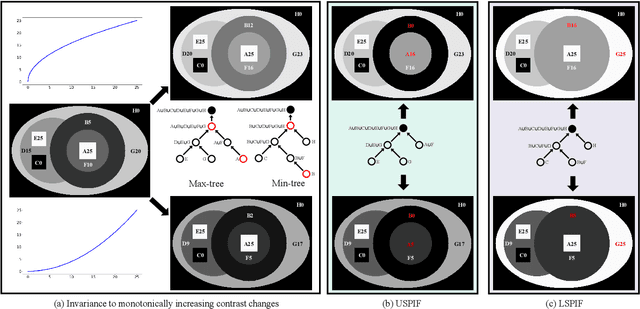
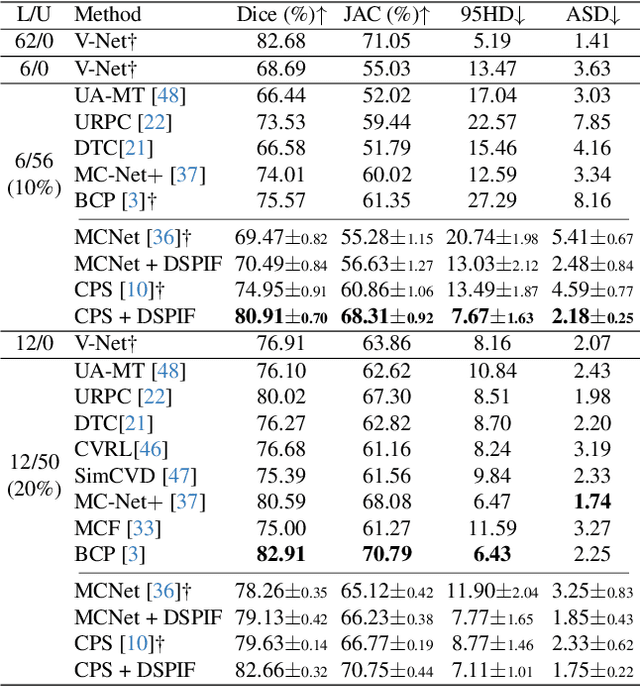
Semi-supervised image segmentation has attracted great attention recently. The key is how to leverage unlabeled images in the training process. Most methods maintain consistent predictions of the unlabeled images under variations (e.g., adding noise/perturbations, or creating alternative versions) in the image and/or model level. In most image-level variation, medical images often have prior structure information, which has not been well explored. In this paper, we propose novel dual structure-preserving image filterings (DSPIF) as the image-level variations for semi-supervised medical image segmentation. Motivated by connected filtering that simplifies image via filtering in structure-aware tree-based image representation, we resort to the dual contrast invariant Max-tree and Min-tree representation. Specifically, we propose a novel connected filtering that removes topologically equivalent nodes (i.e. connected components) having no siblings in the Max/Min-tree. This results in two filtered images preserving topologically critical structure. Applying such dual structure-preserving image filterings in mutual supervision is beneficial for semi-supervised medical image segmentation. Extensive experimental results on three benchmark datasets demonstrate that the proposed method significantly/consistently outperforms some state-of-the-art methods. The source codes will be publicly available.
Noised Autoencoders for Point Annotation Restoration in Object Counting
Dec 12, 2023Object counting is a field of growing importance in domains such as security surveillance, urban planning, and biology. The annotation is usually provided in terms of 2D points. However, the complexity of object shapes and subjective of annotators may lead to annotation inconsistency, potentially confusing the model during training. To alleviate this issue, we introduce the Noised Autoencoders (NAE) methodology, which extracts general positional knowledge from all annotations. The method involves adding random offsets to initial point annotations, followed by a UNet to restore them to their original positions. Similar to MAE, NAE faces challenges in restoring non-generic points, necessitating reliance on the most common positions inferred from general knowledge. This reliance forms the cornerstone of our method's effectiveness. Different from existing noise-resistance methods, our approach focus on directly improving initial point annotations. Extensive experiments show that NAE yields more consistent annotations compared to the original ones, steadily enhancing the performance of advanced models trained with these revised annotations. \textbf{Remarkably, the proposed approach helps to set new records in nine datasets}. We will make the NAE codes and refined point annotations available.
Scale-aware Test-time Click Adaptation for Pulmonary Nodule and Mass Segmentation
Jul 28, 2023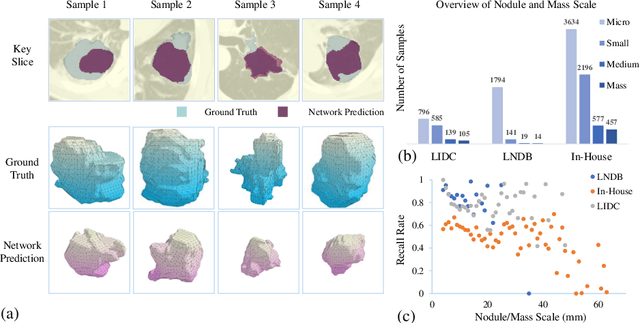


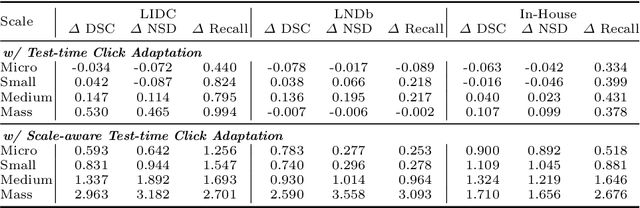
Pulmonary nodules and masses are crucial imaging features in lung cancer screening that require careful management in clinical diagnosis. Despite the success of deep learning-based medical image segmentation, the robust performance on various sizes of lesions of nodule and mass is still challenging. In this paper, we propose a multi-scale neural network with scale-aware test-time adaptation to address this challenge. Specifically, we introduce an adaptive Scale-aware Test-time Click Adaptation method based on effortlessly obtainable lesion clicks as test-time cues to enhance segmentation performance, particularly for large lesions. The proposed method can be seamlessly integrated into existing networks. Extensive experiments on both open-source and in-house datasets consistently demonstrate the effectiveness of the proposed method over some CNN and Transformer-based segmentation methods. Our code is available at https://github.com/SplinterLi/SaTTCA
Not All Pixels Are Equal: Learning Pixel Hardness for Semantic Segmentation
May 15, 2023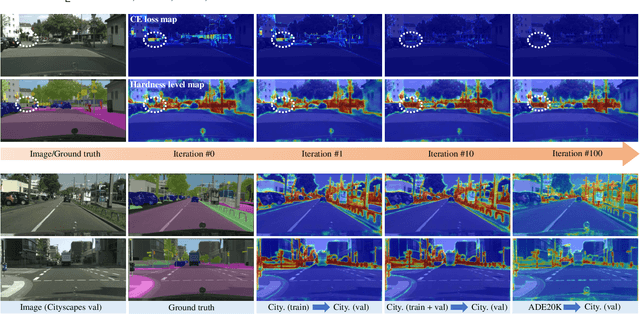

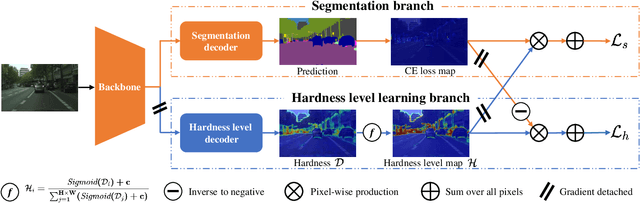
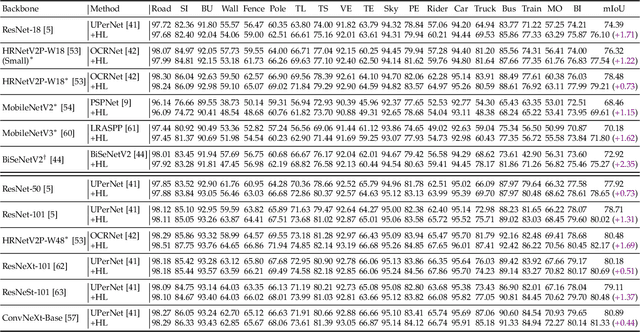
Semantic segmentation has recently witnessed great progress. Despite the impressive overall results, the segmentation performance in some hard areas (e.g., small objects or thin parts) is still not promising. A straightforward solution is hard sample mining, which is widely used in object detection. Yet, most existing hard pixel mining strategies for semantic segmentation often rely on pixel's loss value, which tends to decrease during training. Intuitively, the pixel hardness for segmentation mainly depends on image structure and is expected to be stable. In this paper, we propose to learn pixel hardness for semantic segmentation, leveraging hardness information contained in global and historical loss values. More precisely, we add a gradient-independent branch for learning a hardness level (HL) map by maximizing hardness-weighted segmentation loss, which is minimized for the segmentation head. This encourages large hardness values in difficult areas, leading to appropriate and stable HL map. Despite its simplicity, the proposed method can be applied to most segmentation methods with no and marginal extra cost during inference and training, respectively. Without bells and whistles, the proposed method achieves consistent/significant improvement (1.37% mIoU on average) over most popular semantic segmentation methods on Cityscapes dataset, and demonstrates good generalization ability across domains. The source codes are available at https://github.com/Menoly-xin/Hardness-Level-Learning .
Local Intensity Order Transformation for Robust Curvilinear Object Segmentation
Feb 25, 2022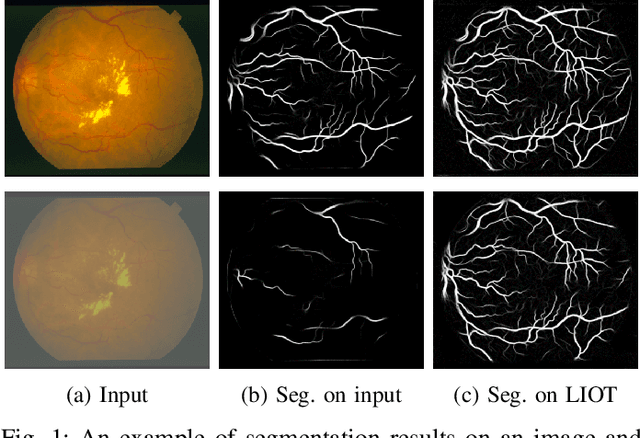


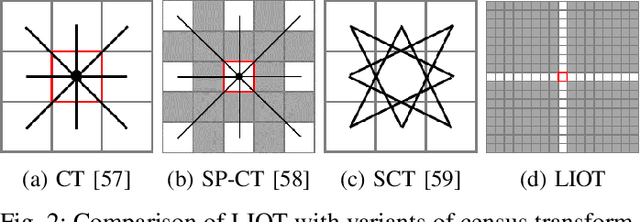
Segmentation of curvilinear structures is important in many applications, such as retinal blood vessel segmentation for early detection of vessel diseases and pavement crack segmentation for road condition evaluation and maintenance. Currently, deep learning-based methods have achieved impressive performance on these tasks. Yet, most of them mainly focus on finding powerful deep architectures but ignore capturing the inherent curvilinear structure feature (e.g., the curvilinear structure is darker than the context) for a more robust representation. In consequence, the performance usually drops a lot on cross-datasets, which poses great challenges in practice. In this paper, we aim to improve the generalizability by introducing a novel local intensity order transformation (LIOT). Specifically, we transfer a gray-scale image into a contrast-invariant four-channel image based on the intensity order between each pixel and its nearby pixels along with the four (horizontal and vertical) directions. This results in a representation that preserves the inherent characteristic of the curvilinear structure while being robust to contrast changes. Cross-dataset evaluation on three retinal blood vessel segmentation datasets demonstrates that LIOT improves the generalizability of some state-of-the-art methods. Additionally, the cross-dataset evaluation between retinal blood vessel segmentation and pavement crack segmentation shows that LIOT is able to preserve the inherent characteristic of curvilinear structure with large appearance gaps. An implementation of the proposed method is available at https://github.com/TY-Shi/LIOT.
Advancing COVID-19 Diagnosis with Privacy-Preserving Collaboration in Artificial Intelligence
Nov 18, 2021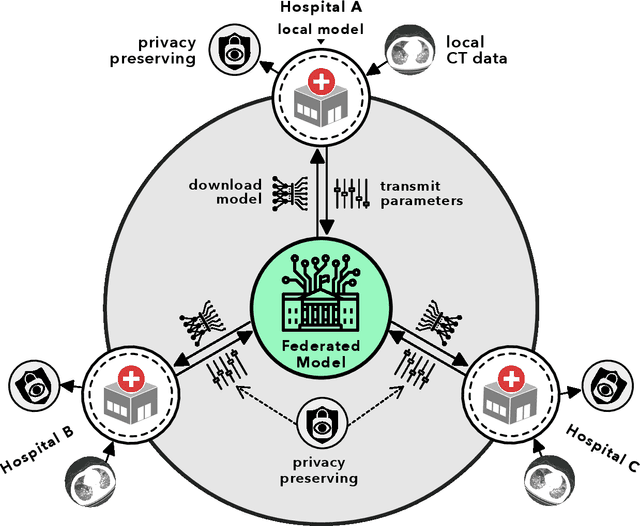
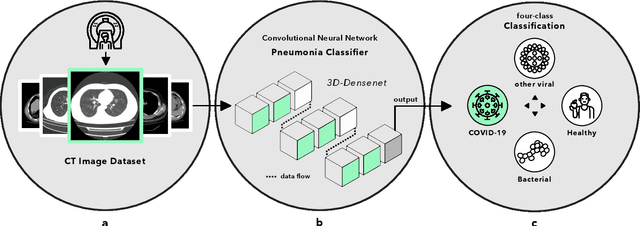
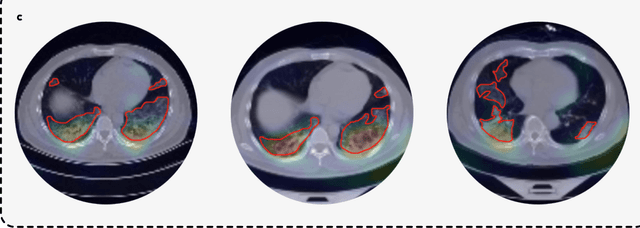
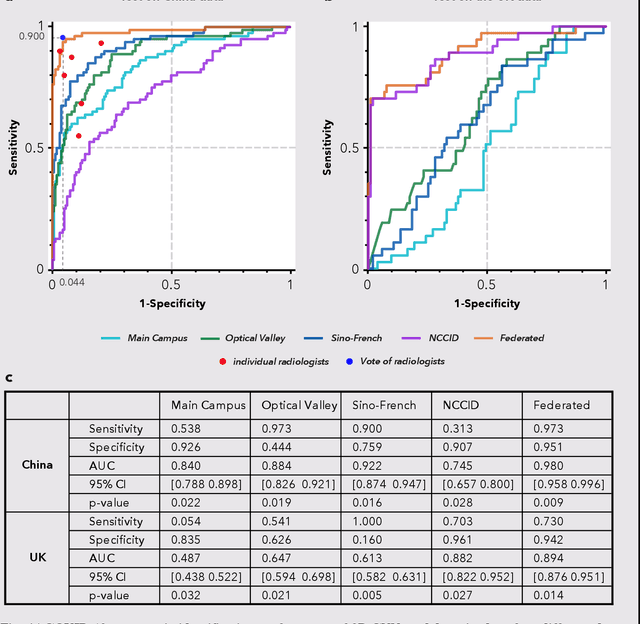
Artificial intelligence (AI) provides a promising substitution for streamlining COVID-19 diagnoses. However, concerns surrounding security and trustworthiness impede the collection of large-scale representative medical data, posing a considerable challenge for training a well-generalised model in clinical practices. To address this, we launch the Unified CT-COVID AI Diagnostic Initiative (UCADI), where the AI model can be distributedly trained and independently executed at each host institution under a federated learning framework (FL) without data sharing. Here we show that our FL model outperformed all the local models by a large yield (test sensitivity /specificity in China: 0.973/0.951, in the UK: 0.730/0.942), achieving comparable performance with a panel of professional radiologists. We further evaluated the model on the hold-out (collected from another two hospitals leaving out the FL) and heterogeneous (acquired with contrast materials) data, provided visual explanations for decisions made by the model, and analysed the trade-offs between the model performance and the communication costs in the federated training process. Our study is based on 9,573 chest computed tomography scans (CTs) from 3,336 patients collected from 23 hospitals located in China and the UK. Collectively, our work advanced the prospects of utilising federated learning for privacy-preserving AI in digital health.
VisDrone-CC2020: The Vision Meets Drone Crowd Counting Challenge Results
Jul 19, 2021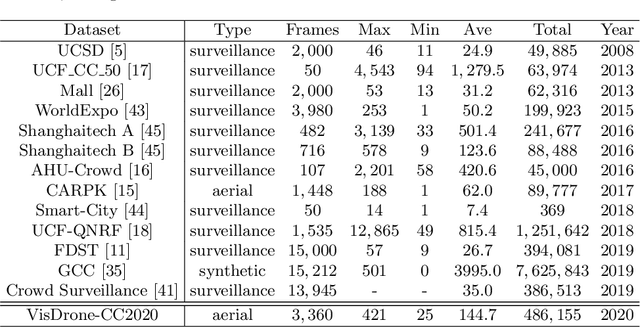

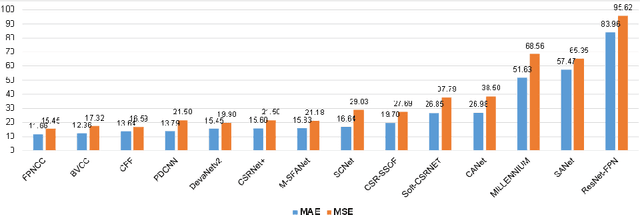
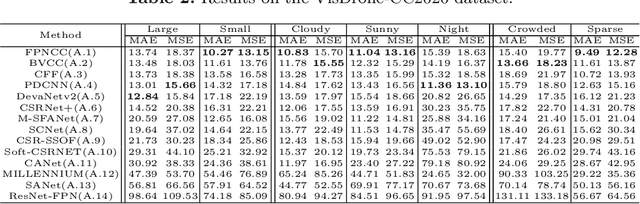
Crowd counting on the drone platform is an interesting topic in computer vision, which brings new challenges such as small object inference, background clutter and wide viewpoint. However, there are few algorithms focusing on crowd counting on the drone-captured data due to the lack of comprehensive datasets. To this end, we collect a large-scale dataset and organize the Vision Meets Drone Crowd Counting Challenge (VisDrone-CC2020) in conjunction with the 16th European Conference on Computer Vision (ECCV 2020) to promote the developments in the related fields. The collected dataset is formed by $3,360$ images, including $2,460$ images for training, and $900$ images for testing. Specifically, we manually annotate persons with points in each video frame. There are $14$ algorithms from $15$ institutes submitted to the VisDrone-CC2020 Challenge. We provide a detailed analysis of the evaluation results and conclude the challenge. More information can be found at the website: \url{http://www.aiskyeye.com/}.
* The method description of A7 Mutil-Scale Aware based SFANet (M-SFANet) is updated and missing references are added
Affinity Space Adaptation for Semantic Segmentation Across Domains
Sep 26, 2020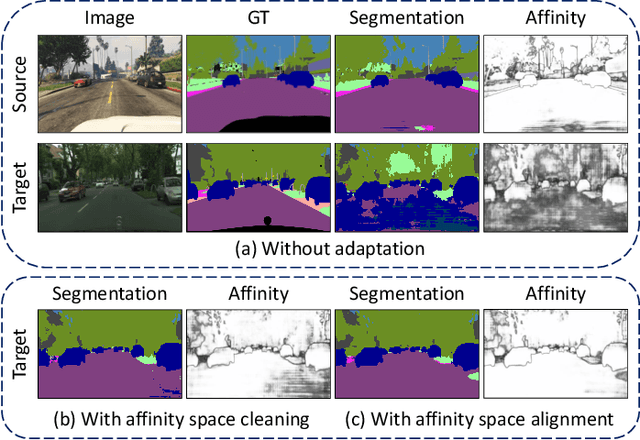
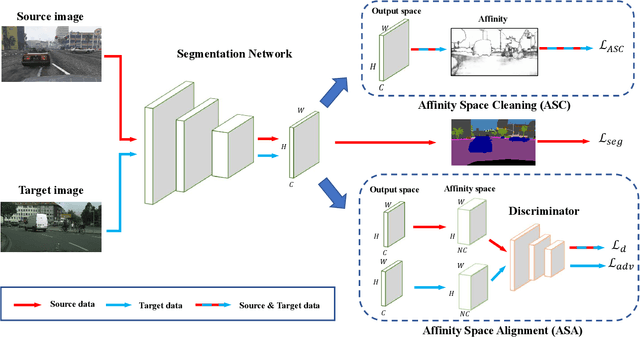

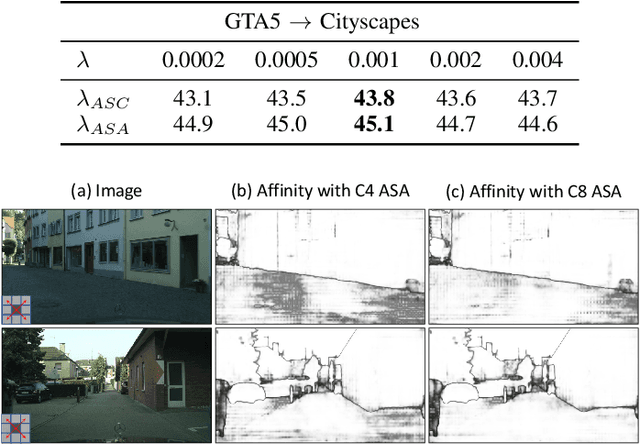
Semantic segmentation with dense pixel-wise annotation has achieved excellent performance thanks to deep learning. However, the generalization of semantic segmentation in the wild remains challenging. In this paper, we address the problem of unsupervised domain adaptation (UDA) in semantic segmentation. Motivated by the fact that source and target domain have invariant semantic structures, we propose to exploit such invariance across domains by leveraging co-occurring patterns between pairwise pixels in the output of structured semantic segmentation. This is different from most existing approaches that attempt to adapt domains based on individual pixel-wise information in image, feature, or output level. Specifically, we perform domain adaptation on the affinity relationship between adjacent pixels termed affinity space of source and target domain. To this end, we develop two affinity space adaptation strategies: affinity space cleaning and adversarial affinity space alignment. Extensive experiments demonstrate that the proposed method achieves superior performance against some state-of-the-art methods on several challenging benchmarks for semantic segmentation across domains. The code is available at https://github.com/idealwei/ASANet.