 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDandan Tu
DocStormer: Revitalizing Multi-Degraded Colored Document Images to Pristine PDF
Oct 27, 2023
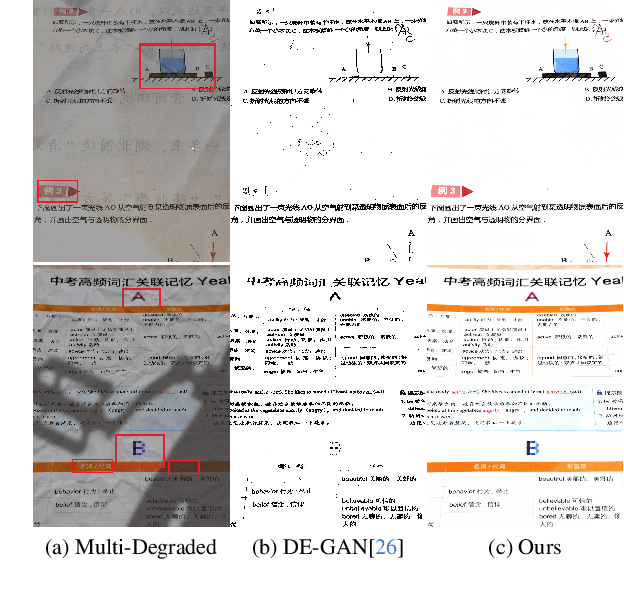

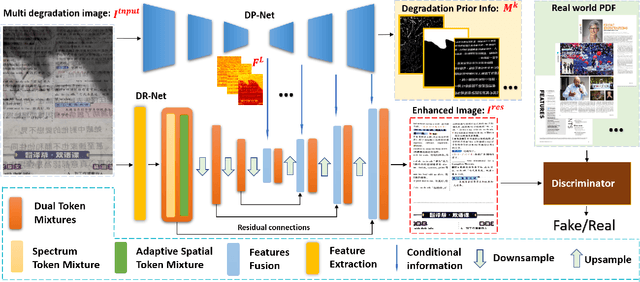
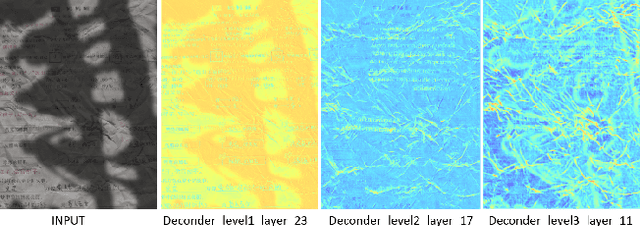
For capturing colored document images, e.g. posters and magazines, it is common that multiple degradations such as shadows, wrinkles, etc., are simultaneously introduced due to external factors. Restoring multi-degraded colored document images is a great challenge, yet overlooked, as most existing algorithms focus on enhancing color-ignored document images via binarization. Thus, we propose DocStormer, a novel algorithm designed to restore multi-degraded colored documents to their potential pristine PDF. The contributions are: firstly, we propose a "Perceive-then-Restore" paradigm with a reinforced transformer block, which more effectively encodes and utilizes the distribution of degradations. Secondly, we are the first to utilize GAN and pristine PDF magazine images to narrow the distribution gap between the enhanced results and PDF images, in pursuit of less degradation and better visual quality. Thirdly, we propose a non-parametric strategy, PFILI, which enables a smaller training scale and larger testing resolutions with acceptable detail trade-off, while saving memory and inference time. Fourthly, we are the first to propose a novel Multi-Degraded Colored Document image Enhancing dataset, named MD-CDE, for both training and evaluation. Experimental results show that the DocStormer exhibits superior performance, capable of revitalizing multi-degraded colored documents into their potential pristine digital versions, which fills the current academic gap from the perspective of method, data, and task.
Style Miner: Find Significant and Stable Explanatory Factors in Time Series with Constrained Reinforcement Learning
Mar 21, 2023



In high-dimensional time-series analysis, it is essential to have a set of key factors (namely, the style factors) that explain the change of the observed variable. For example, volatility modeling in finance relies on a set of risk factors, and climate change studies in climatology rely on a set of causal factors. The ideal low-dimensional style factors should balance significance (with high explanatory power) and stability (consistent, no significant fluctuations). However, previous supervised and unsupervised feature extraction methods can hardly address the tradeoff. In this paper, we propose Style Miner, a reinforcement learning method to generate style factors. We first formulate the problem as a Constrained Markov Decision Process with explanatory power as the return and stability as the constraint. Then, we design fine-grained immediate rewards and costs and use a Lagrangian heuristic to balance them adaptively. Experiments on real-world financial data sets show that Style Miner outperforms existing learning-based methods by a large margin and achieves a relatively 10% gain in R-squared explanatory power compared to the industry-renowned factors proposed by human experts.
Stable Attribute Group Editing for Reliable Few-shot Image Generation
Feb 01, 2023



Few-shot image generation aims to generate data of an unseen category based on only a few samples. Apart from basic content generation, a bunch of downstream applications hopefully benefit from this task, such as low-data detection and few-shot classification. To achieve this goal, the generated images should guarantee category retention for classification beyond the visual quality and diversity. In our preliminary work, we present an ``editing-based'' framework Attribute Group Editing (AGE) for reliable few-shot image generation, which largely improves the generation performance. Nevertheless, AGE's performance on downstream classification is not as satisfactory as expected. This paper investigates the class inconsistency problem and proposes Stable Attribute Group Editing (SAGE) for more stable class-relevant image generation. SAGE takes use of all given few-shot images and estimates a class center embedding based on the category-relevant attribute dictionary. Meanwhile, according to the projection weights on the category-relevant attribute dictionary, we can select category-irrelevant attributes from the similar seen categories. Consequently, SAGE injects the whole distribution of the novel class into StyleGAN's latent space, thus largely remains the category retention and stability of the generated images. Going one step further, we find that class inconsistency is a common problem in GAN-generated images for downstream classification. Even though the generated images look photo-realistic and requires no category-relevant editing, they are usually of limited help for downstream classification. We systematically discuss this issue from both the generative model and classification model perspectives, and propose to boost the downstream classification performance of SAGE by enhancing the pixel and frequency components.
Unsupervised Coherent Video Cartoonization with Perceptual Motion Consistency
Apr 02, 2022



In recent years, creative content generations like style transfer and neural photo editing have attracted more and more attention. Among these, cartoonization of real-world scenes has promising applications in entertainment and industry. Different from image translations focusing on improving the style effect of generated images, video cartoonization has additional requirements on the temporal consistency. In this paper, we propose a spatially-adaptive semantic alignment framework with perceptual motion consistency for coherent video cartoonization in an unsupervised manner. The semantic alignment module is designed to restore deformation of semantic structure caused by spatial information lost in the encoder-decoder architecture. Furthermore, we devise the spatio-temporal correlative map as a style-independent, global-aware regularization on the perceptual motion consistency. Deriving from similarity measurement of high-level features in photo and cartoon frames, it captures global semantic information beyond raw pixel-value in optical flow. Besides, the similarity measurement disentangles temporal relationships from domain-specific style properties, which helps regularize the temporal consistency without hurting style effects of cartoon images. Qualitative and quantitative experiments demonstrate our method is able to generate highly stylistic and temporal consistent cartoon videos.
Intrinsic Bias Identification on Medical Image Datasets
Mar 29, 2022
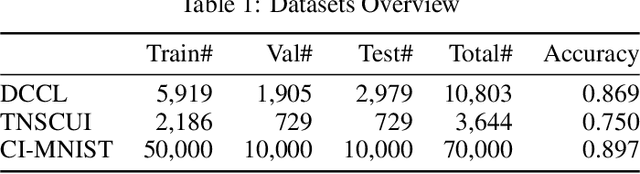
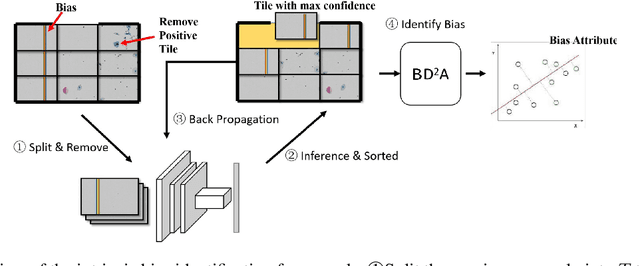
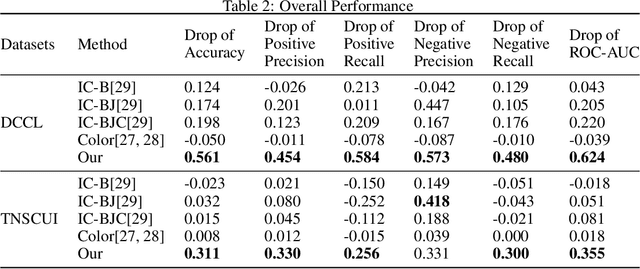
Machine learning based medical image analysis highly depends on datasets. Biases in the dataset can be learned by the model and degrade the generalizability of the applications. There are studies on debiased models. However, scientists and practitioners are difficult to identify implicit biases in the datasets, which causes lack of reliable unbias test datasets to valid models. To tackle this issue, we first define the data intrinsic bias attribute, and then propose a novel bias identification framework for medical image datasets. The framework contains two major components, KlotskiNet and Bias Discriminant Direction Analysis(bdda), where KlostkiNet is to build the mapping which makes backgrounds to distinguish positive and negative samples and bdda provides a theoretical solution on determining bias attributes. Experimental results on three datasets show the effectiveness of the bias attributes discovered by the framework.
Attribute Group Editing for Reliable Few-shot Image Generation
Mar 16, 2022



Few-shot image generation is a challenging task even using the state-of-the-art Generative Adversarial Networks (GANs). Due to the unstable GAN training process and the limited training data, the generated images are often of low quality and low diversity. In this work, we propose a new editing-based method, i.e., Attribute Group Editing (AGE), for few-shot image generation. The basic assumption is that any image is a collection of attributes and the editing direction for a specific attribute is shared across all categories. AGE examines the internal representation learned in GANs and identifies semantically meaningful directions. Specifically, the class embedding, i.e., the mean vector of the latent codes from a specific category, is used to represent the category-relevant attributes, and the category-irrelevant attributes are learned globally by Sparse Dictionary Learning on the difference between the sample embedding and the class embedding. Given a GAN well trained on seen categories, diverse images of unseen categories can be synthesized through editing category-irrelevant attributes while keeping category-relevant attributes unchanged. Without re-training the GAN, AGE is capable of not only producing more realistic and diverse images for downstream visual applications with limited data but achieving controllable image editing with interpretable category-irrelevant directions.
Advancing COVID-19 Diagnosis with Privacy-Preserving Collaboration in Artificial Intelligence
Nov 18, 2021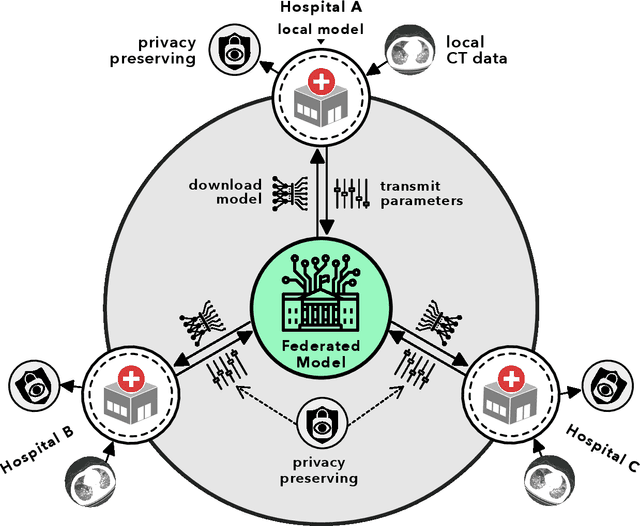
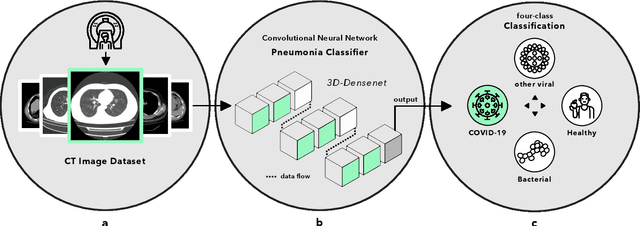
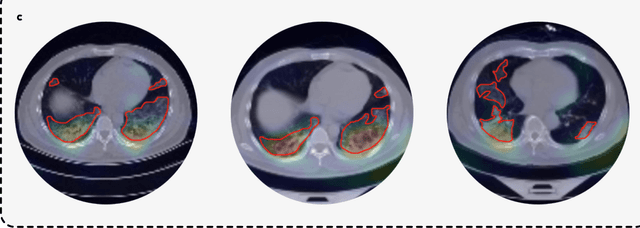
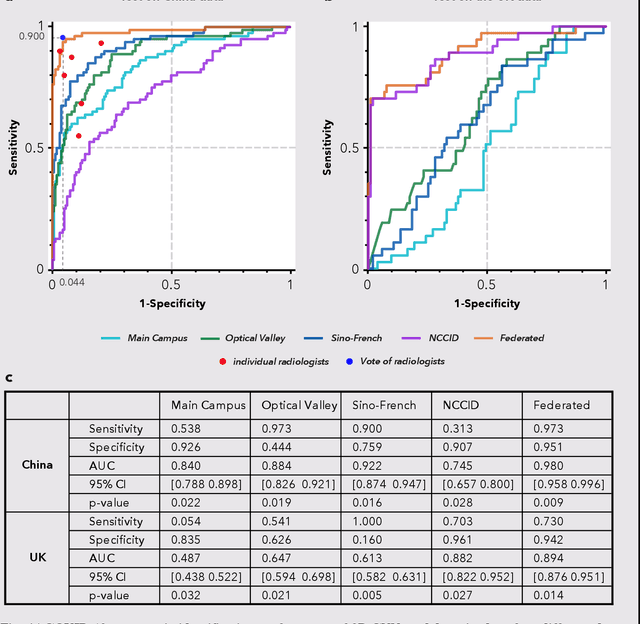
Artificial intelligence (AI) provides a promising substitution for streamlining COVID-19 diagnoses. However, concerns surrounding security and trustworthiness impede the collection of large-scale representative medical data, posing a considerable challenge for training a well-generalised model in clinical practices. To address this, we launch the Unified CT-COVID AI Diagnostic Initiative (UCADI), where the AI model can be distributedly trained and independently executed at each host institution under a federated learning framework (FL) without data sharing. Here we show that our FL model outperformed all the local models by a large yield (test sensitivity /specificity in China: 0.973/0.951, in the UK: 0.730/0.942), achieving comparable performance with a panel of professional radiologists. We further evaluated the model on the hold-out (collected from another two hospitals leaving out the FL) and heterogeneous (acquired with contrast materials) data, provided visual explanations for decisions made by the model, and analysed the trade-offs between the model performance and the communication costs in the federated training process. Our study is based on 9,573 chest computed tomography scans (CTs) from 3,336 patients collected from 23 hospitals located in China and the UK. Collectively, our work advanced the prospects of utilising federated learning for privacy-preserving AI in digital health.
DuCN: Dual-children Network for Medical Diagnosis and Similar Case Recommendation towards COVID-19
Aug 03, 2021



Early detection of the coronavirus disease 2019 (COVID-19) helps to treat patients timely and increase the cure rate, thus further suppressing the spread of the disease. In this study, we propose a novel deep learning based detection and similar case recommendation network to help control the epidemic. Our proposed network contains two stages: the first one is a lung region segmentation step and is used to exclude irrelevant factors, and the second is a detection and recommendation stage. Under this framework, in the second stage, we develop a dual-children network (DuCN) based on a pre-trained ResNet-18 to simultaneously realize the disease diagnosis and similar case recommendation. Besides, we employ triplet loss and intrapulmonary distance maps to assist the detection, which helps incorporate tiny differences between two images and is conducive to improving the diagnostic accuracy. For each confirmed COVID-19 case, we give similar cases to provide radiologists with diagnosis and treatment references. We conduct experiments on a large publicly available dataset (CC-CCII) and compare the proposed model with state-of-the-art COVID-19 detection methods. The results show that our proposed model achieves a promising clinical performance.
Trust the Model When It Is Confident: Masked Model-based Actor-Critic
Oct 10, 2020



It is a popular belief that model-based Reinforcement Learning (RL) is more sample efficient than model-free RL, but in practice, it is not always true due to overweighed model errors. In complex and noisy settings, model-based RL tends to have trouble using the model if it does not know when to trust the model. In this work, we find that better model usage can make a huge difference. We show theoretically that if the use of model-generated data is restricted to state-action pairs where the model error is small, the performance gap between model and real rollouts can be reduced. It motivates us to use model rollouts only when the model is confident about its predictions. We propose Masked Model-based Actor-Critic (M2AC), a novel policy optimization algorithm that maximizes a model-based lower-bound of the true value function. M2AC implements a masking mechanism based on the model's uncertainty to decide whether its prediction should be used or not. Consequently, the new algorithm tends to give robust policy improvements. Experiments on continuous control benchmarks demonstrate that M2AC has strong performance even when using long model rollouts in very noisy environments, and it significantly outperforms previous state-of-the-art methods.
Learning Directional Feature Maps for Cardiac MRI Segmentation
Jul 22, 2020



Cardiac MRI segmentation plays a crucial role in clinical diagnosis for evaluating personalized cardiac performance parameters. Due to the indistinct boundaries and heterogeneous intensity distributions in the cardiac MRI, most existing methods still suffer from two aspects of challenges: inter-class indistinction and intra-class inconsistency. To tackle these two problems, we propose a novel method to exploit the directional feature maps, which can simultaneously strengthen the differences between classes and the similarities within classes. Specifically, we perform cardiac segmentation and learn a direction field pointing away from the nearest cardiac tissue boundary to each pixel via a direction field (DF) module. Based on the learned direction field, we then propose a feature rectification and fusion (FRF) module to improve the original segmentation features, and obtain the final segmentation. The proposed modules are simple yet effective and can be flexibly added to any existing segmentation network without excessively increasing time and space complexity. We evaluate the proposed method on the 2017 MICCAI Automated Cardiac Diagnosis Challenge (ACDC) dataset and a large-scale self-collected dataset, showing good segmentation performance and robust generalization ability of the proposed method.