 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarola-Bibiane Schönlieb
Continuous Learned Primal Dual
May 03, 2024
Neural ordinary differential equations (Neural ODEs) propose the idea that a sequence of layers in a neural network is just a discretisation of an ODE, and thus can instead be directly modelled by a parameterised ODE. This idea has had resounding success in the deep learning literature, with direct or indirect influence in many state of the art ideas, such as diffusion models or time dependant models. Recently, a continuous version of the U-net architecture has been proposed, showing increased performance over its discrete counterpart in many imaging applications and wrapped with theoretical guarantees around its performance and robustness. In this work, we explore the use of Neural ODEs for learned inverse problems, in particular with the well-known Learned Primal Dual algorithm, and apply it to computed tomography (CT) reconstruction.
Tackling Graph Oversquashing by Global and Local Non-Dissipativity
May 02, 2024A common problem in Message-Passing Neural Networks is oversquashing -- the limited ability to facilitate effective information flow between distant nodes. Oversquashing is attributed to the exponential decay in information transmission as node distances increase. This paper introduces a novel perspective to address oversquashing, leveraging properties of global and local non-dissipativity, that enable the maintenance of a constant information flow rate. Namely, we present SWAN, a uniquely parameterized model GNN with antisymmetry both in space and weight domains, as a means to obtain non-dissipativity. Our theoretical analysis asserts that by achieving these properties, SWAN offers an enhanced ability to transmit information over extended distances. Empirical evaluations on synthetic and real-world benchmarks that emphasize long-range interactions validate the theoretical understanding of SWAN, and its ability to mitigate oversquashing.
GRANOLA: Adaptive Normalization for Graph Neural Networks
Apr 20, 2024In recent years, significant efforts have been made to refine the design of Graph Neural Network (GNN) layers, aiming to overcome diverse challenges, such as limited expressive power and oversmoothing. Despite their widespread adoption, the incorporation of off-the-shelf normalization layers like BatchNorm or InstanceNorm within a GNN architecture may not effectively capture the unique characteristics of graph-structured data, potentially reducing the expressive power of the overall architecture. Moreover, existing graph-specific normalization layers often struggle to offer substantial and consistent benefits. In this paper, we propose GRANOLA, a novel graph-adaptive normalization layer. Unlike existing normalization layers, GRANOLA normalizes node features by adapting to the specific characteristics of the graph, particularly by generating expressive representations of its neighborhood structure, obtained by leveraging the propagation of Random Node Features (RNF) in the graph. We present theoretical results that support our design choices. Our extensive empirical evaluation of various graph benchmarks underscores the superior performance of GRANOLA over existing normalization techniques. Furthermore, GRANOLA emerges as the top-performing method among all baselines within the same time complexity of Message Passing Neural Networks (MPNNs).
Unsupervised Training of Convex Regularizers using Maximum Likelihood Estimation
Apr 08, 2024Unsupervised learning is a training approach in the situation where ground truth data is unavailable, such as inverse imaging problems. We present an unsupervised Bayesian training approach to learning convex neural network regularizers using a fixed noisy dataset, based on a dual Markov chain estimation method. Compared to classical supervised adversarial regularization methods, where there is access to both clean images as well as unlimited to noisy copies, we demonstrate close performance on natural image Gaussian deconvolution and Poisson denoising tasks.
Bilevel Hypergraph Networks for Multi-Modal Alzheimer's Diagnosis
Mar 19, 2024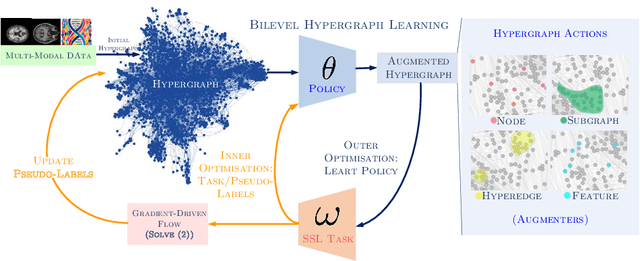

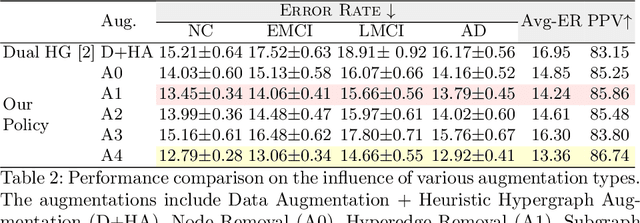
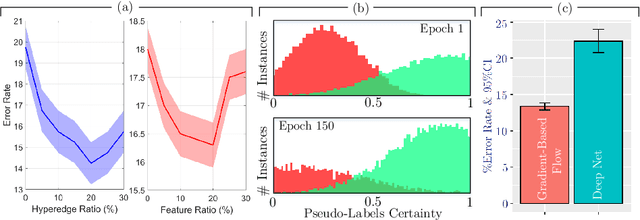
Early detection of Alzheimer's disease's precursor stages is imperative for significantly enhancing patient outcomes and quality of life. This challenge is tackled through a semi-supervised multi-modal diagnosis framework. In particular, we introduce a new hypergraph framework that enables higher-order relations between multi-modal data, while utilising minimal labels. We first introduce a bilevel hypergraph optimisation framework that jointly learns a graph augmentation policy and a semi-supervised classifier. This dual learning strategy is hypothesised to enhance the robustness and generalisation capabilities of the model by fostering new pathways for information propagation. Secondly, we introduce a novel strategy for generating pseudo-labels more effectively via a gradient-driven flow. Our experimental results demonstrate the superior performance of our framework over current techniques in diagnosing Alzheimer's disease.
Biophysics Informed Pathological Regularisation for Brain Tumour Segmentation
Mar 18, 2024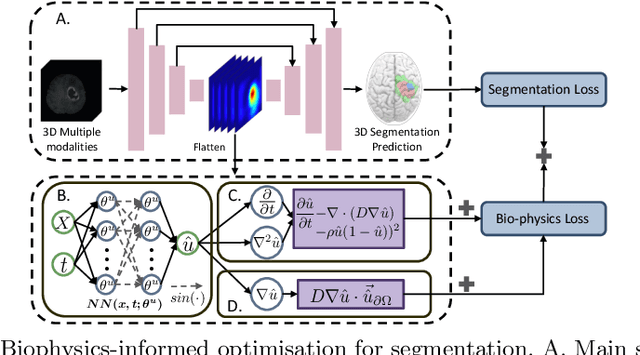
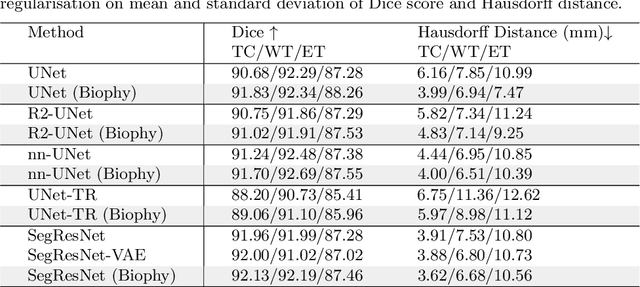
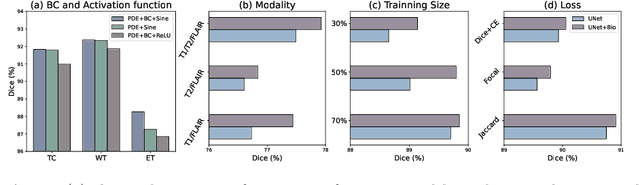

Recent advancements in deep learning have significantly improved brain tumour segmentation techniques; however, the results still lack confidence and robustness as they solely consider image data without biophysical priors or pathological information. Integrating biophysics-informed regularisation is one effective way to change this situation, as it provides an prior regularisation for automated end-to-end learning. In this paper, we propose a novel approach that designs brain tumour growth Partial Differential Equation (PDE) models as a regularisation with deep learning, operational with any network model. Our method introduces tumour growth PDE models directly into the segmentation process, improving accuracy and robustness, especially in data-scarce scenarios. This system estimates tumour cell density using a periodic activation function. By effectively integrating this estimation with biophysical models, we achieve a better capture of tumour characteristics. This approach not only aligns the segmentation closer to actual biological behaviour but also strengthens the model's performance under limited data conditions. We demonstrate the effectiveness of our framework through extensive experiments on the BraTS 2023 dataset, showcasing significant improvements in both precision and reliability of tumour segmentation.
MambaMIR: An Arbitrary-Masked Mamba for Joint Medical Image Reconstruction and Uncertainty Estimation
Feb 28, 2024The recent Mamba model has shown remarkable adaptability for visual representation learning, including in medical imaging tasks. This study introduces MambaMIR, a Mamba-based model for medical image reconstruction, as well as its Generative Adversarial Network-based variant, MambaMIR-GAN. Our proposed MambaMIR inherits several advantages, such as linear complexity, global receptive fields, and dynamic weights, from the original Mamba model. The innovated arbitrary-mask mechanism effectively adapt Mamba to our image reconstruction task, providing randomness for subsequent Monte Carlo-based uncertainty estimation. Experiments conducted on various medical image reconstruction tasks, including fast MRI and SVCT, which cover anatomical regions such as the knee, chest, and abdomen, have demonstrated that MambaMIR and MambaMIR-GAN achieve comparable or superior reconstruction results relative to state-of-the-art methods. Additionally, the estimated uncertainty maps offer further insights into the reliability of the reconstruction quality. The code is publicly available at https://github.com/ayanglab/MambaMIR.
HAMLET: Graph Transformer Neural Operator for Partial Differential Equations
Feb 05, 2024We present a novel graph transformer framework, HAMLET, designed to address the challenges in solving partial differential equations (PDEs) using neural networks. The framework uses graph transformers with modular input encoders to directly incorporate differential equation information into the solution process. This modularity enhances parameter correspondence control, making HAMLET adaptable to PDEs of arbitrary geometries and varied input formats. Notably, HAMLET scales effectively with increasing data complexity and noise, showcasing its robustness. HAMLET is not just tailored to a single type of physical simulation, but can be applied across various domains. Moreover, it boosts model resilience and performance, especially in scenarios with limited data. We demonstrate, through extensive experiments, that our framework is capable of outperforming current techniques for PDEs.
Weakly Convex Regularisers for Inverse Problems: Convergence of Critical Points and Primal-Dual Optimisation
Feb 01, 2024Variational regularisation is the primary method for solving inverse problems, and recently there has been considerable work leveraging deeply learned regularisation for enhanced performance. However, few results exist addressing the convergence of such regularisation, particularly within the context of critical points as opposed to global minima. In this paper, we present a generalised formulation of convergent regularisation in terms of critical points, and show that this is achieved by a class of weakly convex regularisers. We prove convergence of the primal-dual hybrid gradient method for the associated variational problem, and, given a Kurdyka-Lojasiewicz condition, an $\mathcal{O}(\log{k}/k)$ ergodic convergence rate. Finally, applying this theory to learned regularisation, we prove universal approximation for input weakly convex neural networks (IWCNN), and show empirically that IWCNNs can lead to improved performance of learned adversarial regularisers for computed tomography (CT) reconstruction.
On The Temporal Domain of Differential Equation Inspired Graph Neural Networks
Jan 20, 2024Graph Neural Networks (GNNs) have demonstrated remarkable success in modeling complex relationships in graph-structured data. A recent innovation in this field is the family of Differential Equation-Inspired Graph Neural Networks (DE-GNNs), which leverage principles from continuous dynamical systems to model information flow on graphs with built-in properties such as feature smoothing or preservation. However, existing DE-GNNs rely on first or second-order temporal dependencies. In this paper, we propose a neural extension to those pre-defined temporal dependencies. We show that our model, called TDE-GNN, can capture a wide range of temporal dynamics that go beyond typical first or second-order methods, and provide use cases where existing temporal models are challenged. We demonstrate the benefit of learning the temporal dependencies using our method rather than using pre-defined temporal dynamics on several graph benchmarks.