 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLihao Liu
Biophysics Informed Pathological Regularisation for Brain Tumour Segmentation
Mar 18, 2024
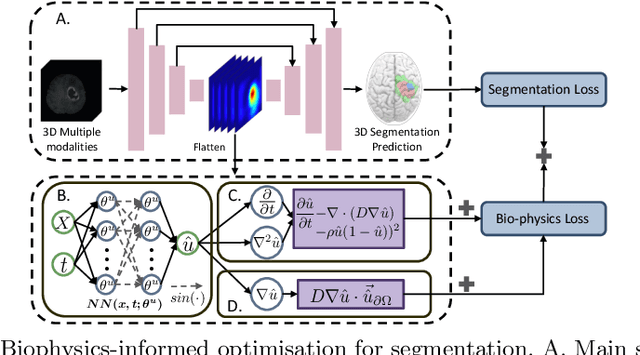
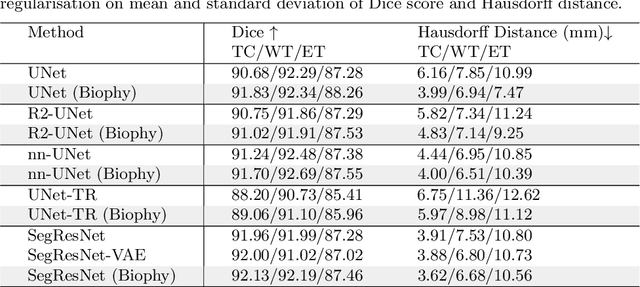
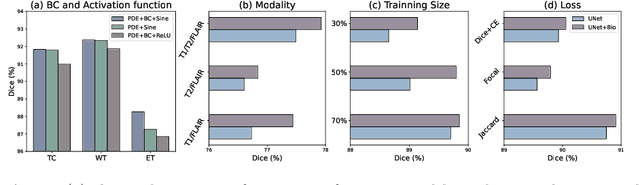

Recent advancements in deep learning have significantly improved brain tumour segmentation techniques; however, the results still lack confidence and robustness as they solely consider image data without biophysical priors or pathological information. Integrating biophysics-informed regularisation is one effective way to change this situation, as it provides an prior regularisation for automated end-to-end learning. In this paper, we propose a novel approach that designs brain tumour growth Partial Differential Equation (PDE) models as a regularisation with deep learning, operational with any network model. Our method introduces tumour growth PDE models directly into the segmentation process, improving accuracy and robustness, especially in data-scarce scenarios. This system estimates tumour cell density using a periodic activation function. By effectively integrating this estimation with biophysical models, we achieve a better capture of tumour characteristics. This approach not only aligns the segmentation closer to actual biological behaviour but also strengthens the model's performance under limited data conditions. We demonstrate the effectiveness of our framework through extensive experiments on the BraTS 2023 dataset, showcasing significant improvements in both precision and reliability of tumour segmentation.
TrafficMOT: A Challenging Dataset for Multi-Object Tracking in Complex Traffic Scenarios
Nov 30, 2023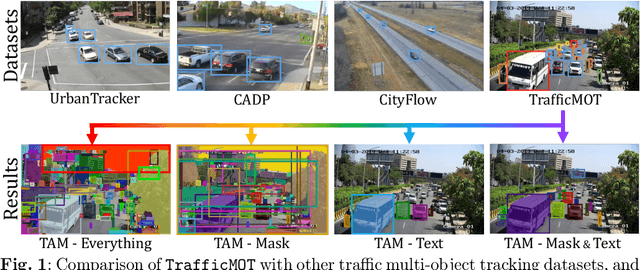
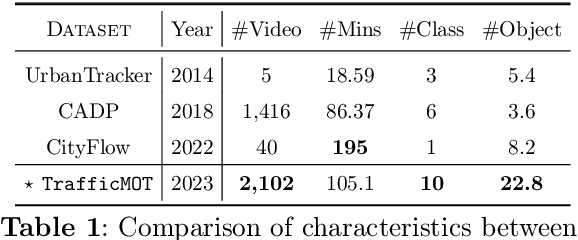


Multi-object tracking in traffic videos is a crucial research area, offering immense potential for enhancing traffic monitoring accuracy and promoting road safety measures through the utilisation of advanced machine learning algorithms. However, existing datasets for multi-object tracking in traffic videos often feature limited instances or focus on single classes, which cannot well simulate the challenges encountered in complex traffic scenarios. To address this gap, we introduce TrafficMOT, an extensive dataset designed to encompass diverse traffic situations with complex scenarios. To validate the complexity and challenges presented by TrafficMOT, we conducted comprehensive empirical studies using three different settings: fully-supervised, semi-supervised, and a recent powerful zero-shot foundation model Tracking Anything Model (TAM). The experimental results highlight the inherent complexity of this dataset, emphasising its value in driving advancements in the field of traffic monitoring and multi-object tracking.
Traffic Video Object Detection using Motion Prior
Nov 16, 2023Traffic videos inherently differ from generic videos in their stationary camera setup, thus providing a strong motion prior where objects often move in a specific direction over a short time interval. Existing works predominantly employ generic video object detection framework for traffic video object detection, which yield certain advantages such as broad applicability and robustness to diverse scenarios. However, they fail to harness the strength of motion prior to enhance detection accuracy. In this work, we propose two innovative methods to exploit the motion prior and boost the performance of both fully-supervised and semi-supervised traffic video object detection. Firstly, we introduce a new self-attention module that leverages the motion prior to guide temporal information integration in the fully-supervised setting. Secondly, we utilise the motion prior to develop a pseudo-labelling mechanism to eliminate noisy pseudo labels for the semi-supervised setting. Both of our motion-prior-centred methods consistently demonstrates superior performance, outperforming existing state-of-the-art approaches by a margin of 2% in terms of mAP.
MammoDG: Generalisable Deep Learning Breaks the Limits of Cross-Domain Multi-Center Breast Cancer Screening
Aug 02, 2023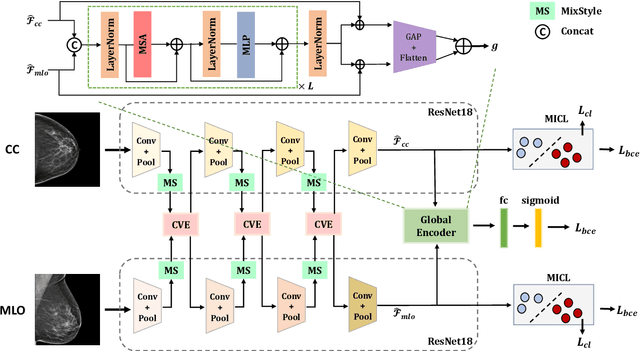

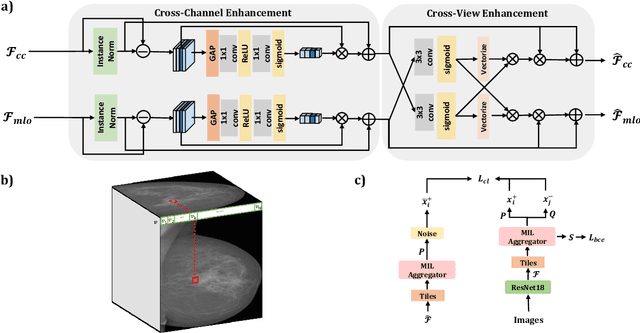
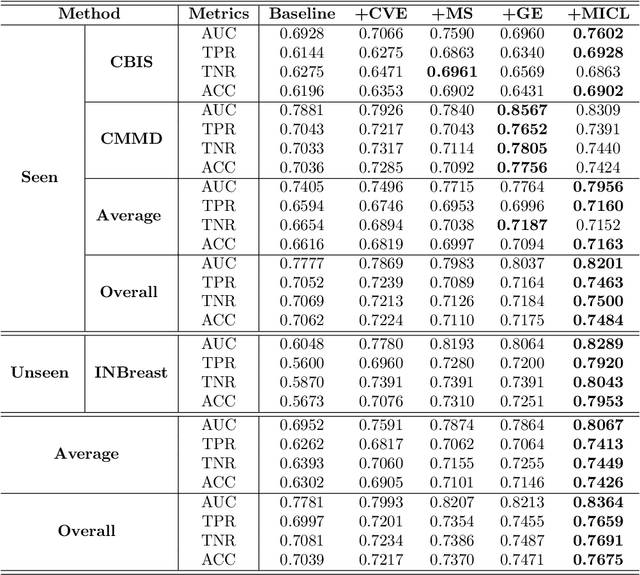
Breast cancer is a major cause of cancer death among women, emphasising the importance of early detection for improved treatment outcomes and quality of life. Mammography, the primary diagnostic imaging test, poses challenges due to the high variability and patterns in mammograms. Double reading of mammograms is recommended in many screening programs to improve diagnostic accuracy but increases radiologists' workload. Researchers explore Machine Learning models to support expert decision-making. Stand-alone models have shown comparable or superior performance to radiologists, but some studies note decreased sensitivity with multiple datasets, indicating the need for high generalisation and robustness models. This work devises MammoDG, a novel deep-learning framework for generalisable and reliable analysis of cross-domain multi-center mammography data. MammoDG leverages multi-view mammograms and a novel contrastive mechanism to enhance generalisation capabilities. Extensive validation demonstrates MammoDG's superiority, highlighting the critical importance of domain generalisation for trustworthy mammography analysis in imaging protocol variations.
Homeomorphic Image Registration via Conformal-Invariant Hyperelastic Regularisation
Mar 14, 2023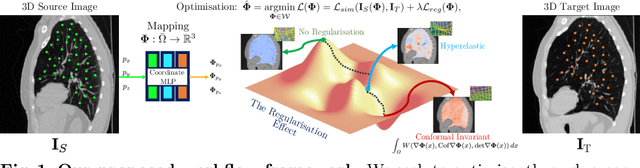

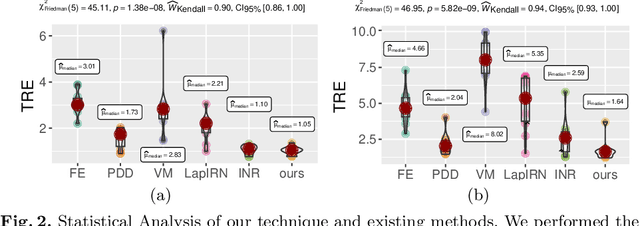
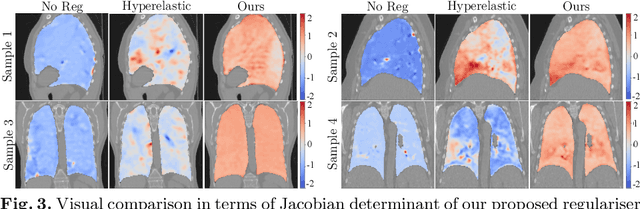
Deformable image registration is a fundamental task in medical image analysis and plays a crucial role in a wide range of clinical applications. Recently, deep learning-based approaches have been widely studied for deformable medical image registration and achieved promising results. However, existing deep learning image registration techniques do not theoretically guarantee topology-preserving transformations. This is a key property to preserve anatomical structures and achieve plausible transformations that can be used in real clinical settings. We propose a novel framework for deformable image registration. Firstly, we introduce a novel regulariser based on conformal-invariant properties in a nonlinear elasticity setting. Our regulariser enforces the deformation field to be smooth, invertible and orientation-preserving. More importantly, we strictly guarantee topology preservation yielding to a clinical meaningful registration. Secondly, we boost the performance of our regulariser through coordinate MLPs, where one can view the to-be-registered images as continuously differentiable entities. We demonstrate, through numerical and visual experiments, that our framework is able to outperform current techniques for image registration.
CoNIC Challenge: Pushing the Frontiers of Nuclear Detection, Segmentation, Classification and Counting
Mar 14, 2023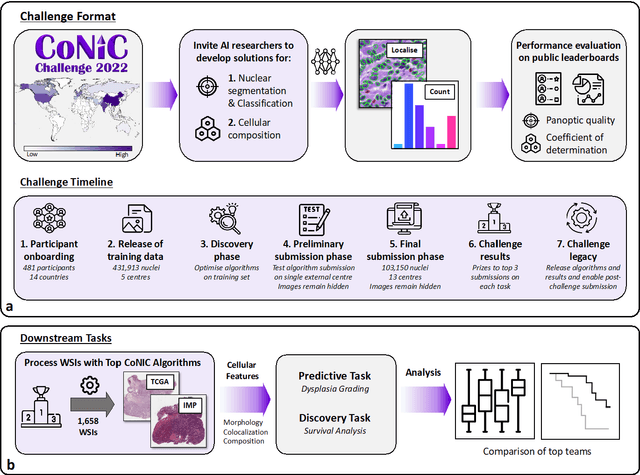
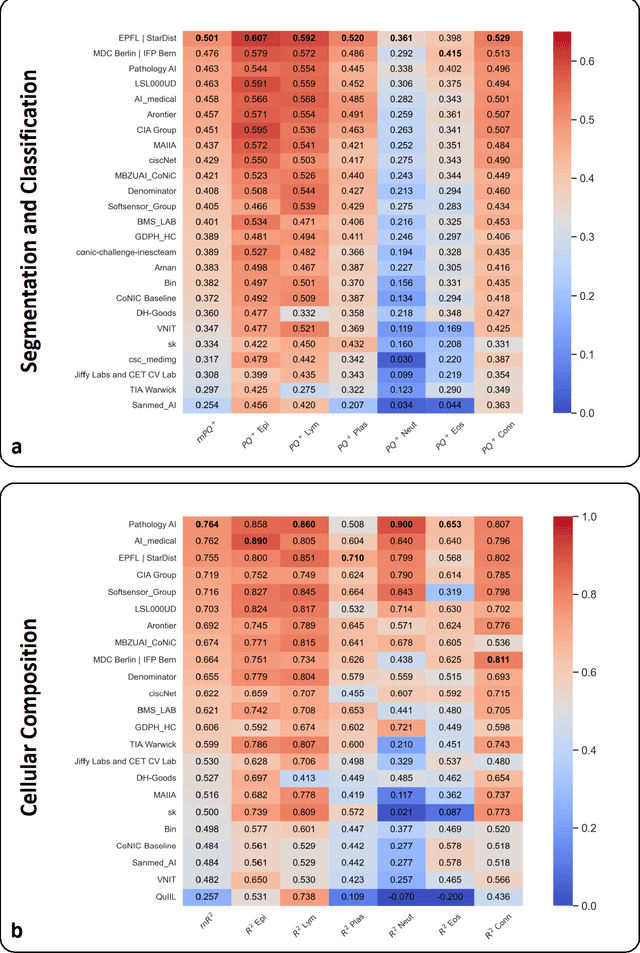
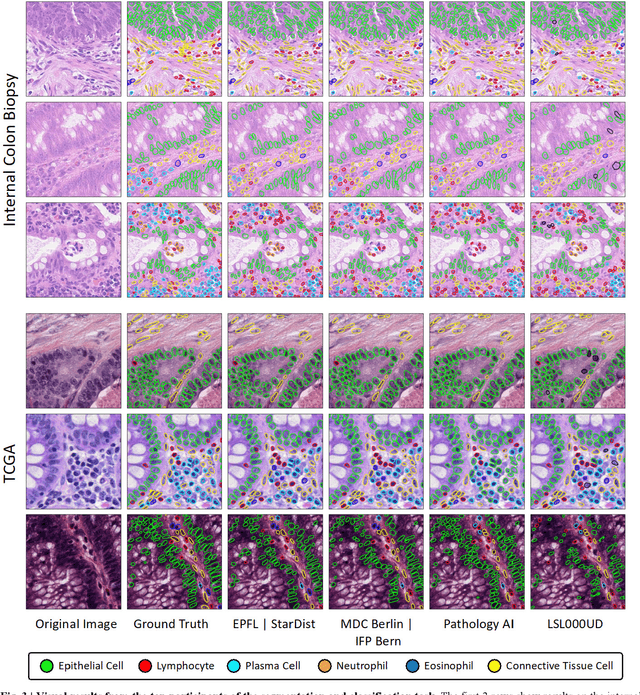
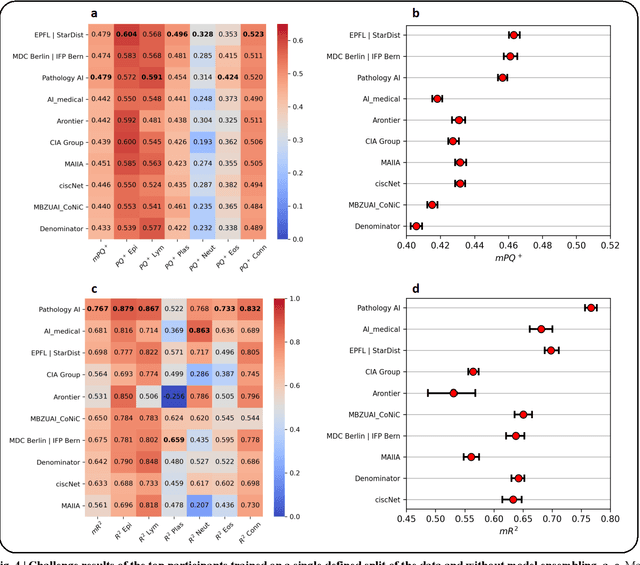
Nuclear detection, segmentation and morphometric profiling are essential in helping us further understand the relationship between histology and patient outcome. To drive innovation in this area, we setup a community-wide challenge using the largest available dataset of its kind to assess nuclear segmentation and cellular composition. Our challenge, named CoNIC, stimulated the development of reproducible algorithms for cellular recognition with real-time result inspection on public leaderboards. We conducted an extensive post-challenge analysis based on the top-performing models using 1,658 whole-slide images of colon tissue. With around 700 million detected nuclei per model, associated features were used for dysplasia grading and survival analysis, where we demonstrated that the challenge's improvement over the previous state-of-the-art led to significant boosts in downstream performance. Our findings also suggest that eosinophils and neutrophils play an important role in the tumour microevironment. We release challenge models and WSI-level results to foster the development of further methods for biomarker discovery.
Continuous U-Net: Faster, Greater and Noiseless
Feb 01, 2023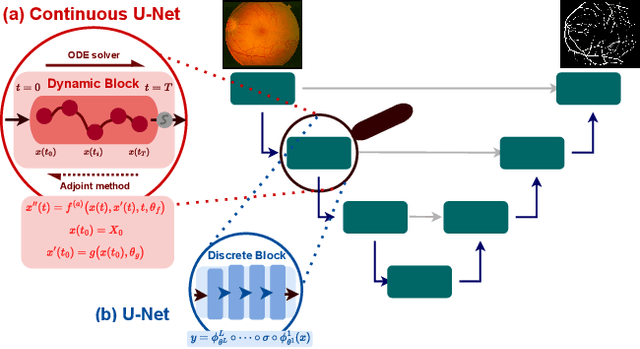

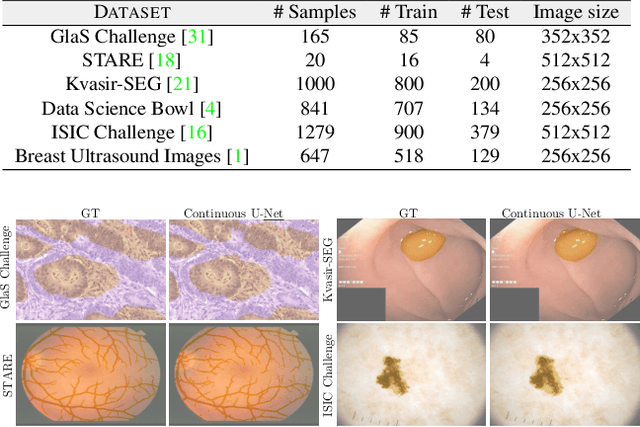

Image segmentation is a fundamental task in image analysis and clinical practice. The current state-of-the-art techniques are based on U-shape type encoder-decoder networks with skip connections, called U-Net. Despite the powerful performance reported by existing U-Net type networks, they suffer from several major limitations. Issues include the hard coding of the receptive field size, compromising the performance and computational cost, as well as the fact that they do not account for inherent noise in the data. They have problems associated with discrete layers, and do not offer any theoretical underpinning. In this work we introduce continuous U-Net, a novel family of networks for image segmentation. Firstly, continuous U-Net is a continuous deep neural network that introduces new dynamic blocks modelled by second order ordinary differential equations. Secondly, we provide theoretical guarantees for our network demonstrating faster convergence, higher robustness and less sensitivity to noise. Thirdly, we derive qualitative measures to tailor-made segmentation tasks. We demonstrate, through extensive numerical and visual results, that our model outperforms existing U-Net blocks for several medical image segmentation benchmarking datasets.
TrafficCAM: A Versatile Dataset for Traffic Flow Segmentation
Nov 17, 2022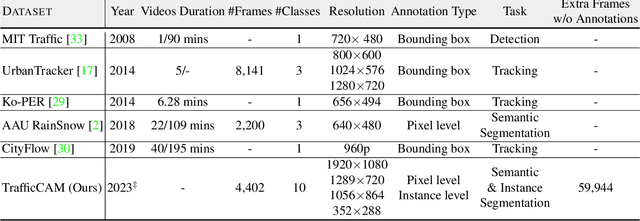
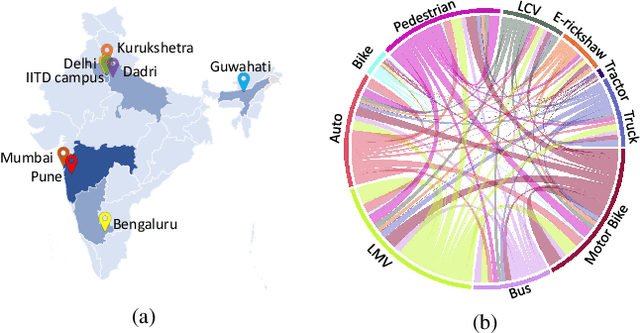

Traffic flow analysis is revolutionising traffic management. Qualifying traffic flow data, traffic control bureaus could provide drivers with real-time alerts, advising the fastest routes and therefore optimising transportation logistics and reducing congestion. The existing traffic flow datasets have two major limitations. They feature a limited number of classes, usually limited to one type of vehicle, and the scarcity of unlabelled data. In this paper, we introduce a new benchmark traffic flow image dataset called TrafficCAM. Our dataset distinguishes itself by two major highlights. Firstly, TrafficCAM provides both pixel-level and instance-level semantic labelling along with a large range of types of vehicles and pedestrians. It is composed of a large and diverse set of video sequences recorded in streets from eight Indian cities with stationary cameras. Secondly, TrafficCAM aims to establish a new benchmark for developing fully-supervised tasks, and importantly, semi-supervised learning techniques. It is the first dataset that provides a vast amount of unlabelled data, helping to better capture traffic flow qualification under a low cost annotation requirement. More precisely, our dataset has 4,402 image frames with semantic and instance annotations along with 59,944 unlabelled image frames. We validate our new dataset through a large and comprehensive range of experiments on several state-of-the-art approaches under four different settings: fully-supervised semantic and instance segmentation, and semi-supervised semantic and instance segmentation tasks. Our benchmark dataset will be released.
SCOTCH and SODA: A Transformer Video Shadow Detection Framework
Nov 13, 2022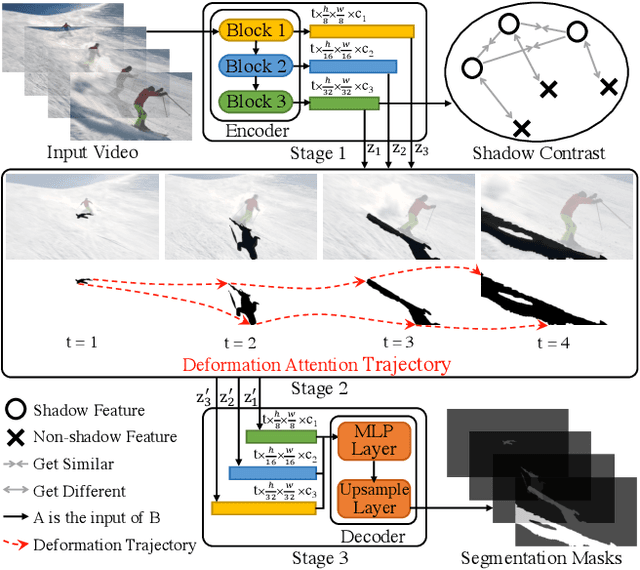
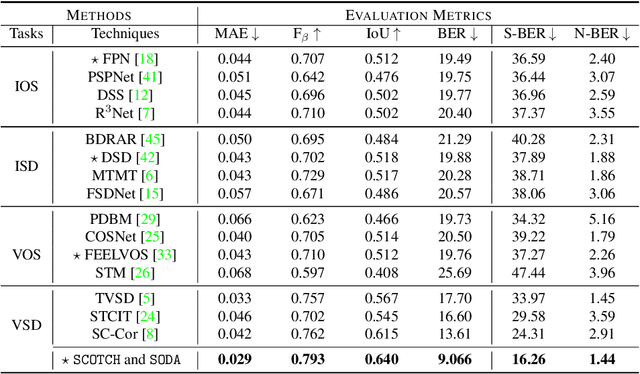
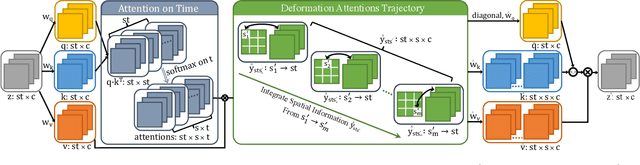
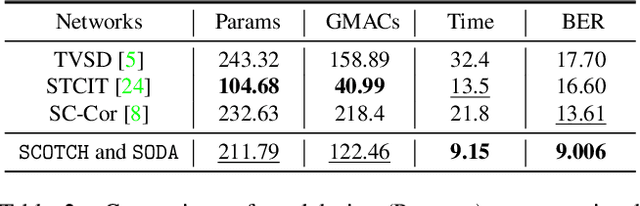
Shadows in videos are difficult to detect because of the large shadow deformation between frames. In this work, we argue that accounting for the shadow deformation is essential when designing a video shadow detection method. To this end, we introduce the shadow deformation attention trajectory (SODA), a new type of video self-attention module, specially designed to handle the large shadow deformations in videos. Moreover, we present a shadow contrastive learning mechanism (SCOTCH) which aims at guiding the network to learn a high-level representation of shadows, unified across different videos. We demonstrate empirically the effectiveness of our two contributions in an ablation study. Furthermore, we show that SCOTCH and SODA significantly outperforms existing techniques for video shadow detection. Code will be available upon the acceptance of this work.
Why Deep Surgical Models Fail?: Revisiting Surgical Action Triplet Recognition through the Lens of Robustness
Sep 18, 2022
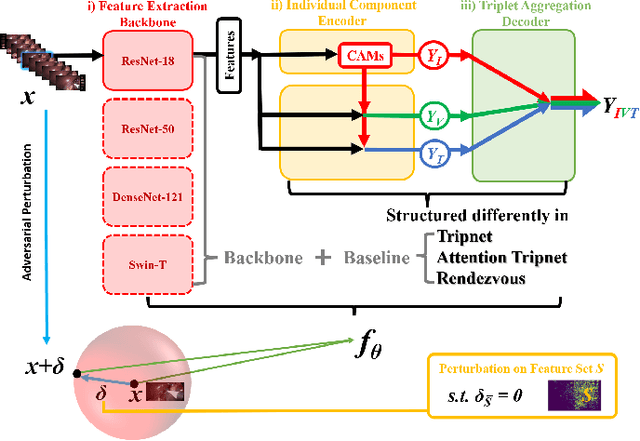


Surgical action triplet recognition provides a better understanding of the surgical scene. This task is of high relevance as it provides to the surgeon with context-aware support and safety. The current go-to strategy for improving performance is the development of new network mechanisms. However, the performance of current state-of-the-art techniques is substantially lower than other surgical tasks. Why is this happening? This is the question that we address in this work. We present the first study to understand the failure of existing deep learning models through the lens of robustness and explainabilty. Firstly, we study current existing models under weak and strong $\delta-$perturbations via adversarial optimisation scheme. We then provide the failure modes via feature based explanations. Our study revels that the key for improving performance and increasing reliability is in the core and spurious attributes. Our work opens the door to more trustworthiness and reliability deep learning models in surgical science.