 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJing Qin
The state-of-the-art in Cardiac MRI Reconstruction: Results of the CMRxRecon Challenge in MICCAI 2023
Apr 16, 2024
Cardiac MRI, crucial for evaluating heart structure and function, faces limitations like slow imaging and motion artifacts. Undersampling reconstruction, especially data-driven algorithms, has emerged as a promising solution to accelerate scans and enhance imaging performance using highly under-sampled data. Nevertheless, the scarcity of publicly available cardiac k-space datasets and evaluation platform hinder the development of data-driven reconstruction algorithms. To address this issue, we organized the Cardiac MRI Reconstruction Challenge (CMRxRecon) in 2023, in collaboration with the 26th International Conference on MICCAI. CMRxRecon presented an extensive k-space dataset comprising cine and mapping raw data, accompanied by detailed annotations of cardiac anatomical structures. With overwhelming participation, the challenge attracted more than 285 teams and over 600 participants. Among them, 22 teams successfully submitted Docker containers for the testing phase, with 7 teams submitted for both cine and mapping tasks. All teams use deep learning based approaches, indicating that deep learning has predominately become a promising solution for the problem. The first-place winner of both tasks utilizes the E2E-VarNet architecture as backbones. In contrast, U-Net is still the most popular backbone for both multi-coil and single-coil reconstructions. This paper provides a comprehensive overview of the challenge design, presents a summary of the submitted results, reviews the employed methods, and offers an in-depth discussion that aims to inspire future advancements in cardiac MRI reconstruction models. The summary emphasizes the effective strategies observed in Cardiac MRI reconstruction, including backbone architecture, loss function, pre-processing techniques, physical modeling, and model complexity, thereby providing valuable insights for further developments in this field.
Genuine Knowledge from Practice: Diffusion Test-Time Adaptation for Video Adverse Weather Removal
Mar 12, 2024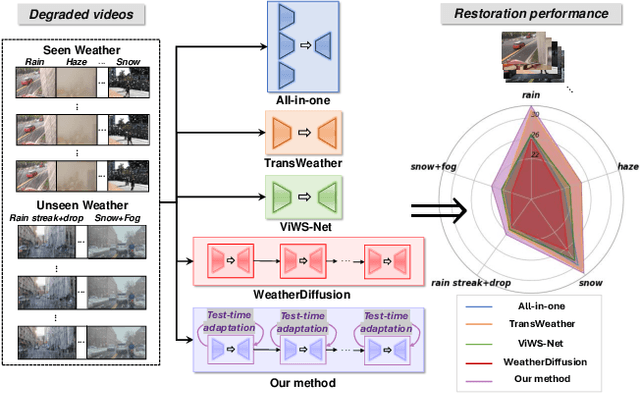
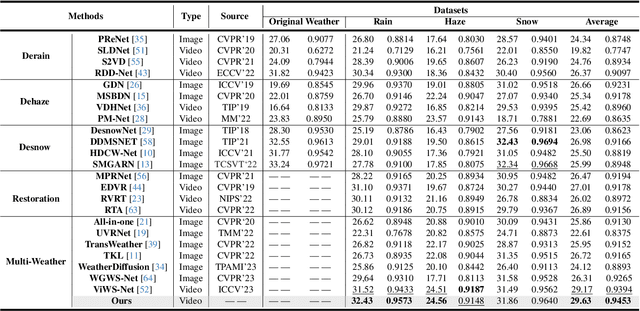
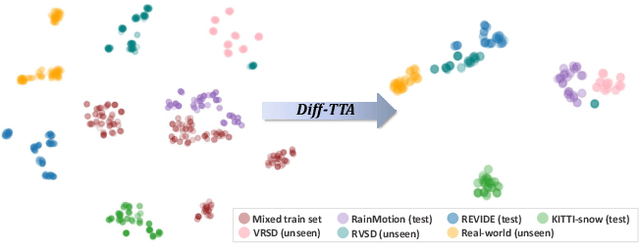
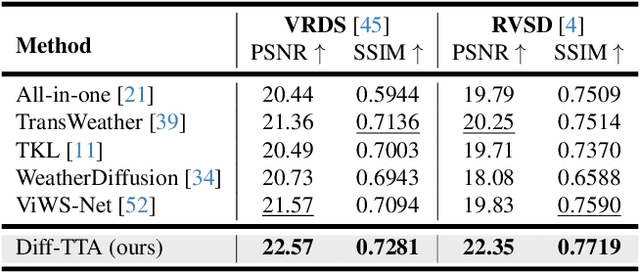
Real-world vision tasks frequently suffer from the appearance of unexpected adverse weather conditions, including rain, haze, snow, and raindrops. In the last decade, convolutional neural networks and vision transformers have yielded outstanding results in single-weather video removal. However, due to the absence of appropriate adaptation, most of them fail to generalize to other weather conditions. Although ViWS-Net is proposed to remove adverse weather conditions in videos with a single set of pre-trained weights, it is seriously blinded by seen weather at train-time and degenerates when coming to unseen weather during test-time. In this work, we introduce test-time adaptation into adverse weather removal in videos, and propose the first framework that integrates test-time adaptation into the iterative diffusion reverse process. Specifically, we devise a diffusion-based network with a novel temporal noise model to efficiently explore frame-correlated information in degraded video clips at training stage. During inference stage, we introduce a proxy task named Diffusion Tubelet Self-Calibration to learn the primer distribution of test video stream and optimize the model by approximating the temporal noise model for online adaptation. Experimental results, on benchmark datasets, demonstrate that our Test-Time Adaptation method with Diffusion-based network(Diff-TTA) outperforms state-of-the-art methods in terms of restoring videos degraded by seen weather conditions. Its generalizable capability is also validated with unseen weather conditions in both synthesized and real-world videos.
DrFuse: Learning Disentangled Representation for Clinical Multi-Modal Fusion with Missing Modality and Modal Inconsistency
Mar 10, 2024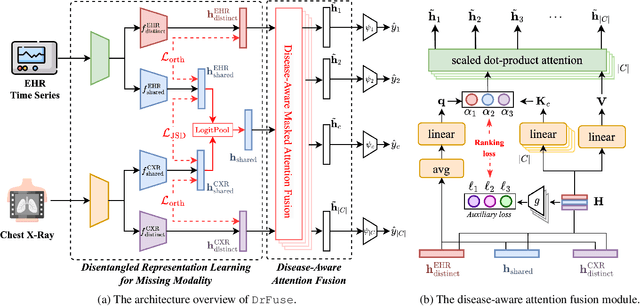
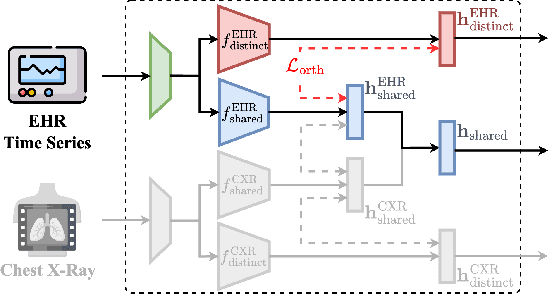
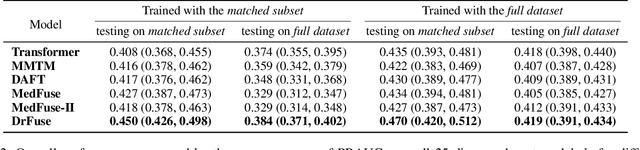
The combination of electronic health records (EHR) and medical images is crucial for clinicians in making diagnoses and forecasting prognosis. Strategically fusing these two data modalities has great potential to improve the accuracy of machine learning models in clinical prediction tasks. However, the asynchronous and complementary nature of EHR and medical images presents unique challenges. Missing modalities due to clinical and administrative factors are inevitable in practice, and the significance of each data modality varies depending on the patient and the prediction target, resulting in inconsistent predictions and suboptimal model performance. To address these challenges, we propose DrFuse to achieve effective clinical multi-modal fusion. It tackles the missing modality issue by disentangling the features shared across modalities and those unique within each modality. Furthermore, we address the modal inconsistency issue via a disease-wise attention layer that produces the patient- and disease-wise weighting for each modality to make the final prediction. We validate the proposed method using real-world large-scale datasets, MIMIC-IV and MIMIC-CXR. Experimental results show that the proposed method significantly outperforms the state-of-the-art models. Our implementation is publicly available at https://github.com/dorothy-yao/drfuse.
Revitalizing Multivariate Time Series Forecasting: Learnable Decomposition with Inter-Series Dependencies and Intra-Series Variations Modeling
Feb 20, 2024Predicting multivariate time series is crucial, demanding precise modeling of intricate patterns, including inter-series dependencies and intra-series variations. Distinctive trend characteristics in each time series pose challenges, and existing methods, relying on basic moving average kernels, may struggle with the non-linear structure and complex trends in real-world data. Given that, we introduce a learnable decomposition strategy to capture dynamic trend information more reasonably. Additionally, we propose a dual attention module tailored to capture inter-series dependencies and intra-series variations simultaneously for better time series forecasting, which is implemented by channel-wise self-attention and autoregressive self-attention. To evaluate the effectiveness of our method, we conducted experiments across eight open-source datasets and compared it with the state-of-the-art methods. Through the comparison results, our Leddam (LEarnable Decomposition and Dual Attention Module) not only demonstrates significant advancements in predictive performance, but also the proposed decomposition strategy can be plugged into other methods with a large performance-boosting, from 11.87% to 48.56% MSE error degradation.
Pushing The Limit of LLM Capacity for Text Classification
Feb 16, 2024The value of text classification's future research has encountered challenges and uncertainties, due to the extraordinary efficacy demonstrated by large language models (LLMs) across numerous downstream NLP tasks. In this era of open-ended language modeling, where task boundaries are gradually fading, an urgent question emerges: have we made significant advances in text classification under the full benefit of LLMs? To answer this question, we propose RGPT, an adaptive boosting framework tailored to produce a specialized text classification LLM by recurrently ensembling a pool of strong base learners. The base learners are constructed by adaptively adjusting the distribution of training samples and iteratively fine-tuning LLMs with them. Such base learners are then ensembled to be a specialized text classification LLM, by recurrently incorporating the historical predictions from the previous learners. Through a comprehensive empirical comparison, we show that RGPT significantly outperforms 8 SOTA PLMs and 7 SOTA LLMs on four benchmarks by 1.36% on average. Further evaluation experiments show a clear surpassing of RGPT over human classification.
Informed Reinforcement Learning for Situation-Aware Traffic Rule Exceptions
Feb 06, 2024Reinforcement Learning is a highly active research field with promising advancements. In the field of autonomous driving, however, often very simple scenarios are being examined. Common approaches use non-interpretable control commands as the action space and unstructured reward designs which lack structure. In this work, we introduce Informed Reinforcement Learning, where a structured rulebook is integrated as a knowledge source. We learn trajectories and asses them with a situation-aware reward design, leading to a dynamic reward which allows the agent to learn situations which require controlled traffic rule exceptions. Our method is applicable to arbitrary RL models. We successfully demonstrate high completion rates of complex scenarios with recent model-based agents.
Cross-BERT for Point Cloud Pretraining
Dec 08, 2023Introducing BERT into cross-modal settings raises difficulties in its optimization for handling multiple modalities. Both the BERT architecture and training objective need to be adapted to incorporate and model information from different modalities. In this paper, we address these challenges by exploring the implicit semantic and geometric correlations between 2D and 3D data of the same objects/scenes. We propose a new cross-modal BERT-style self-supervised learning paradigm, called Cross-BERT. To facilitate pretraining for irregular and sparse point clouds, we design two self-supervised tasks to boost cross-modal interaction. The first task, referred to as Point-Image Alignment, aims to align features between unimodal and cross-modal representations to capture the correspondences between the 2D and 3D modalities. The second task, termed Masked Cross-modal Modeling, further improves mask modeling of BERT by incorporating high-dimensional semantic information obtained by cross-modal interaction. By performing cross-modal interaction, Cross-BERT can smoothly reconstruct the masked tokens during pretraining, leading to notable performance enhancements for downstream tasks. Through empirical evaluation, we demonstrate that Cross-BERT outperforms existing state-of-the-art methods in 3D downstream applications. Our work highlights the effectiveness of leveraging cross-modal 2D knowledge to strengthen 3D point cloud representation and the transferable capability of BERT across modalities.
Feature-oriented Deep Learning Framework for Pulmonary Cone-beam CT (CBCT) Enhancement with Multi-task Customized Perceptual Loss
Nov 01, 2023Cone-beam computed tomography (CBCT) is routinely collected during image-guided radiation therapy (IGRT) to provide updated patient anatomy information for cancer treatments. However, CBCT images often suffer from streaking artifacts and noise caused by under-rate sampling projections and low-dose exposure, resulting in low clarity and information loss. While recent deep learning-based CBCT enhancement methods have shown promising results in suppressing artifacts, they have limited performance on preserving anatomical details since conventional pixel-to-pixel loss functions are incapable of describing detailed anatomy. To address this issue, we propose a novel feature-oriented deep learning framework that translates low-quality CBCT images into high-quality CT-like imaging via a multi-task customized feature-to-feature perceptual loss function. The framework comprises two main components: a multi-task learning feature-selection network(MTFS-Net) for customizing the perceptual loss function; and a CBCT-to-CT translation network guided by feature-to-feature perceptual loss, which uses advanced generative models such as U-Net, GAN and CycleGAN. Our experiments showed that the proposed framework can generate synthesized CT (sCT) images for the lung that achieved a high similarity to CT images, with an average SSIM index of 0.9869 and an average PSNR index of 39.9621. The sCT images also achieved visually pleasing performance with effective artifacts suppression, noise reduction, and distinctive anatomical details preservation. Our experiment results indicate that the proposed framework outperforms the state-of-the-art models for pulmonary CBCT enhancement. This framework holds great promise for generating high-quality anatomical imaging from CBCT that is suitable for various clinical applications.