 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWilliam K. Cheung
DrFuse: Learning Disentangled Representation for Clinical Multi-Modal Fusion with Missing Modality and Modal Inconsistency
Mar 10, 2024
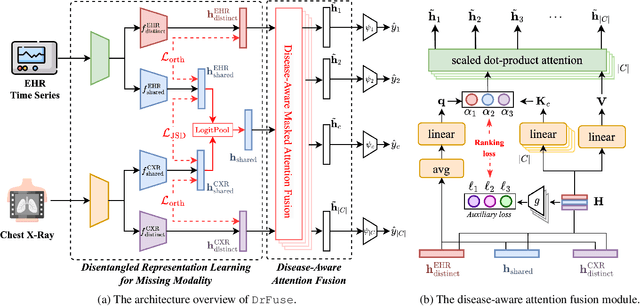
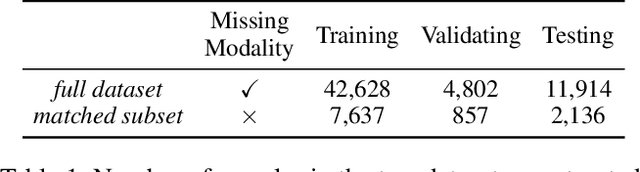
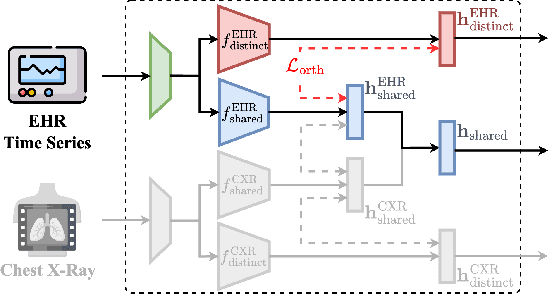
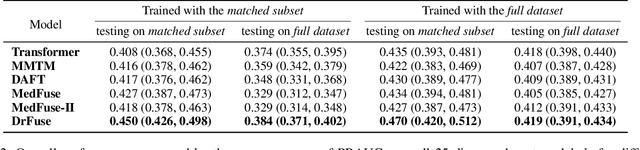
The combination of electronic health records (EHR) and medical images is crucial for clinicians in making diagnoses and forecasting prognosis. Strategically fusing these two data modalities has great potential to improve the accuracy of machine learning models in clinical prediction tasks. However, the asynchronous and complementary nature of EHR and medical images presents unique challenges. Missing modalities due to clinical and administrative factors are inevitable in practice, and the significance of each data modality varies depending on the patient and the prediction target, resulting in inconsistent predictions and suboptimal model performance. To address these challenges, we propose DrFuse to achieve effective clinical multi-modal fusion. It tackles the missing modality issue by disentangling the features shared across modalities and those unique within each modality. Furthermore, we address the modal inconsistency issue via a disease-wise attention layer that produces the patient- and disease-wise weighting for each modality to make the final prediction. We validate the proposed method using real-world large-scale datasets, MIMIC-IV and MIMIC-CXR. Experimental results show that the proposed method significantly outperforms the state-of-the-art models. Our implementation is publicly available at https://github.com/dorothy-yao/drfuse.
WL-Align: Weisfeiler-Lehman Relabeling for Aligning Users across Networks via Regularized Representation Learning
Dec 29, 2022



Aligning users across networks using graph representation learning has been found effective where the alignment is accomplished in a low-dimensional embedding space. Yet, achieving highly precise alignment is still challenging, especially when nodes with long-range connectivity to the labeled anchors are encountered. To alleviate this limitation, we purposefully designed WL-Align which adopts a regularized representation learning framework to learn distinctive node representations. It extends the Weisfeiler-Lehman Isormorphism Test and learns the alignment in alternating phases of "across-network Weisfeiler-Lehman relabeling" and "proximity-preserving representation learning". The across-network Weisfeiler-Lehman relabeling is achieved through iterating the anchor-based label propagation and a similarity-based hashing to exploit the known anchors' connectivity to different nodes in an efficient and robust manner. The representation learning module preserves the second-order proximity within individual networks and is regularized by the across-network Weisfeiler-Lehman hash labels. Extensive experiments on real-world and synthetic datasets have demonstrated that our proposed WL-Align outperforms the state-of-the-art methods, achieving significant performance improvements in the "exact matching" scenario. Data and code of WL-Align are available at https://github.com/ChenPengGang/WLAlignCode.
Attributed Abnormality Graph Embedding for Clinically Accurate X-Ray Report Generation
Jul 05, 2022



Automatic generation of medical reports from X-ray images can assist radiologists to perform the time-consuming and yet important reporting task. Yet, achieving clinically accurate generated reports remains challenging. Modeling the underlying abnormalities using the knowledge graph approach has been found promising in enhancing the clinical accuracy. In this paper, we introduce a novel fined-grained knowledge graph structure called an attributed abnormality graph (ATAG). The ATAG consists of interconnected abnormality nodes and attribute nodes, allowing it to better capture the abnormality details. In contrast to the existing methods where the abnormality graph was constructed manually, we propose a methodology to automatically construct the fine-grained graph structure based on annotations, medical reports in X-ray datasets, and the RadLex radiology lexicon. We then learn the ATAG embedding using a deep model with an encoder-decoder architecture for the report generation. In particular, graph attention networks are explored to encode the relationships among the abnormalities and their attributes. A gating mechanism is adopted and integrated with various decoders for the generation. We carry out extensive experiments based on the benchmark datasets, and show that the proposed ATAG-based deep model outperforms the SOTA methods by a large margin and can improve the clinical accuracy of the generated reports.
Towards Improving Embedding Based Models of Social Network Alignment via Pseudo Anchors
Nov 22, 2021



Social network alignment aims at aligning person identities across social networks. Embedding based models have been shown effective for the alignment where the structural proximity preserving objective is typically adopted for the model training. With the observation that ``overly-close'' user embeddings are unavoidable for such models causing alignment inaccuracy, we propose a novel learning framework which tries to enforce the resulting embeddings to be more widely apart among the users via the introduction of carefully implanted pseudo anchors. We further proposed a meta-learning algorithm to guide the updating of the pseudo anchor embeddings during the learning process. The proposed intervention via the use of pseudo anchors and meta-learning allows the learning framework to be applicable to a wide spectrum of network alignment methods. We have incorporated the proposed learning framework into several state-of-the-art models. Our experimental results demonstrate its efficacy where the methods with the pseudo anchors implanted can outperform their counterparts without pseudo anchors by a fairly large margin, especially when there only exist very few labeled anchors.
TOHAN: A One-step Approach towards Few-shot Hypothesis Adaptation
Jun 11, 2021



In few-shot domain adaptation (FDA), classifiers for the target domain are trained with accessible labeled data in the source domain (SD) and few labeled data in the target domain (TD). However, data usually contain private information in the current era, e.g., data distributed on personal phones. Thus, the private information will be leaked if we directly access data in SD to train a target-domain classifier (required by FDA methods). In this paper, to thoroughly prevent the privacy leakage in SD, we consider a very challenging problem setting, where the classifier for the TD has to be trained using few labeled target data and a well-trained SD classifier, named few-shot hypothesis adaptation (FHA). In FHA, we cannot access data in SD, as a result, the private information in SD will be protected well. To this end, we propose a target orientated hypothesis adaptation network (TOHAN) to solve the FHA problem, where we generate highly-compatible unlabeled data (i.e., an intermediate domain) to help train a target-domain classifier. TOHAN maintains two deep networks simultaneously, where one focuses on learning an intermediate domain and the other takes care of the intermediate-to-target distributional adaptation and the target-risk minimization. Experimental results show that TOHAN outperforms competitive baselines significantly.
Learning Inter-Modal Correspondence and Phenotypes from Multi-Modal Electronic Health Records
Nov 12, 2020



Non-negative tensor factorization has been shown a practical solution to automatically discover phenotypes from the electronic health records (EHR) with minimal human supervision. Such methods generally require an input tensor describing the inter-modal interactions to be pre-established; however, the correspondence between different modalities (e.g., correspondence between medications and diagnoses) can often be missing in practice. Although heuristic methods can be applied to estimate them, they inevitably introduce errors, and leads to sub-optimal phenotype quality. This is particularly important for patients with complex health conditions (e.g., in critical care) as multiple diagnoses and medications are simultaneously present in the records. To alleviate this problem and discover phenotypes from EHR with unobserved inter-modal correspondence, we propose the collective hidden interaction tensor factorization (cHITF) to infer the correspondence between multiple modalities jointly with the phenotype discovery. We assume that the observed matrix for each modality is marginalization of the unobserved inter-modal correspondence, which are reconstructed by maximizing the likelihood of the observed matrices. Extensive experiments conducted on the real-world MIMIC-III dataset demonstrate that cHITF effectively infers clinically meaningful inter-modal correspondence, discovers phenotypes that are more clinically relevant and diverse, and achieves better predictive performance compared with a number of state-of-the-art computational phenotyping models.
Towards well-specified semi-supervised model-based classifiers via structural adaptation
May 01, 2017



Semi-supervised learning plays an important role in large-scale machine learning. Properly using additional unlabeled data (largely available nowadays) often can improve the machine learning accuracy. However, if the machine learning model is misspecified for the underlying true data distribution, the model performance could be seriously jeopardized. This issue is known as model misspecification. To address this issue, we focus on generative models and propose a criterion to detect the onset of model misspecification by measuring the performance difference between models obtained using supervised and semi-supervised learning. Then, we propose to automatically modify the generative models during model training to achieve an unbiased generative model. Rigorous experiments were carried out to evaluate the proposed method using two image classification data sets PASCAL VOC'07 and MIR Flickr. Our proposed method has been demonstrated to outperform a number of state-of-the-art semi-supervised learning approaches for the classification task.
Learning Stylometric Representations for Authorship Analysis
Jun 03, 2016



Authorship analysis (AA) is the study of unveiling the hidden properties of authors from a body of exponentially exploding textual data. It extracts an author's identity and sociolinguistic characteristics based on the reflected writing styles in the text. It is an essential process for various areas, such as cybercrime investigation, psycholinguistics, political socialization, etc. However, most of the previous techniques critically depend on the manual feature engineering process. Consequently, the choice of feature set has been shown to be scenario- or dataset-dependent. In this paper, to mimic the human sentence composition process using a neural network approach, we propose to incorporate different categories of linguistic features into distributed representation of words in order to learn simultaneously the writing style representations based on unlabeled texts for authorship analysis. In particular, the proposed models allow topical, lexical, syntactical, and character-level feature vectors of each document to be extracted as stylometrics. We evaluate the performance of our approach on the problems of authorship characterization and authorship verification with the Twitter, novel, and essay datasets. The experiments suggest that our proposed text representation outperforms the bag-of-lexical-n-grams, Latent Dirichlet Allocation, Latent Semantic Analysis, PVDM, PVDBOW, and word2vec representations.
Learning Topic Models by Belief Propagation
Mar 24, 2012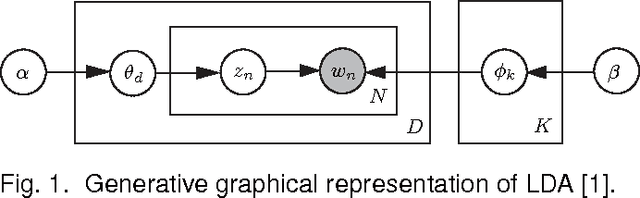
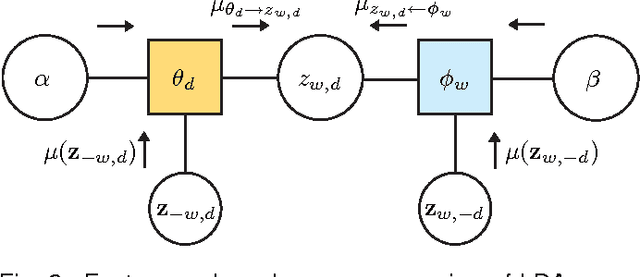
Latent Dirichlet allocation (LDA) is an important hierarchical Bayesian model for probabilistic topic modeling, which attracts worldwide interests and touches on many important applications in text mining, computer vision and computational biology. This paper represents LDA as a factor graph within the Markov random field (MRF) framework, which enables the classic loopy belief propagation (BP) algorithm for approximate inference and parameter estimation. Although two commonly-used approximate inference methods, such as variational Bayes (VB) and collapsed Gibbs sampling (GS), have gained great successes in learning LDA, the proposed BP is competitive in both speed and accuracy as validated by encouraging experimental results on four large-scale document data sets. Furthermore, the BP algorithm has the potential to become a generic learning scheme for variants of LDA-based topic models. To this end, we show how to learn two typical variants of LDA-based topic models, such as author-topic models (ATM) and relational topic models (RTM), using BP based on the factor graph representation.
* 14 pages, 17 figures
Higher-Order Markov Tag-Topic Models for Tagged Documents and Images
Sep 25, 2011



This paper studies the topic modeling problem of tagged documents and images. Higher-order relations among tagged documents and images are major and ubiquitous characteristics, and play positive roles in extracting reliable and interpretable topics. In this paper, we propose the tag-topic models (TTM) to depict such higher-order topic structural dependencies within the Markov random field (MRF) framework. First, we use the novel factor graph representation of latent Dirichlet allocation (LDA)-based topic models from the MRF perspective, and present an efficient loopy belief propagation (BP) algorithm for approximate inference and parameter estimation. Second, we propose the factor hypergraph representation of TTM, and focus on both pairwise and higher-order relation modeling among tagged documents and images. Efficient loopy BP algorithm is developed to learn TTM, which encourages the topic labeling smoothness among tagged documents and images. Extensive experimental results confirm the incorporation of higher-order relations to be effective in enhancing the overall topic modeling performance, when compared with current state-of-the-art topic models, in many text and image mining tasks of broad interests such as word and link prediction, document classification, and tag recommendation.