 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeng Liu
VideoGigaGAN: Towards Detail-rich Video Super-Resolution
Apr 18, 2024
Video super-resolution (VSR) approaches have shown impressive temporal consistency in upsampled videos. However, these approaches tend to generate blurrier results than their image counterparts as they are limited in their generative capability. This raises a fundamental question: can we extend the success of a generative image upsampler to the VSR task while preserving the temporal consistency? We introduce VideoGigaGAN, a new generative VSR model that can produce videos with high-frequency details and temporal consistency. VideoGigaGAN builds upon a large-scale image upsampler -- GigaGAN. Simply inflating GigaGAN to a video model by adding temporal modules produces severe temporal flickering. We identify several key issues and propose techniques that significantly improve the temporal consistency of upsampled videos. Our experiments show that, unlike previous VSR methods, VideoGigaGAN generates temporally consistent videos with more fine-grained appearance details. We validate the effectiveness of VideoGigaGAN by comparing it with state-of-the-art VSR models on public datasets and showcasing video results with $8\times$ super-resolution.
Image Reconstruction with B0 Inhomogeneity using an Interpretable Deep Unrolled Network on an Open-bore MRI-Linac
Apr 15, 2024MRI-Linac systems require fast image reconstruction with high geometric fidelity to localize and track tumours for radiotherapy treatments. However, B0 field inhomogeneity distortions and slow MR acquisition potentially limit the quality of the image guidance and tumour treatments. In this study, we develop an interpretable unrolled network, referred to as RebinNet, to reconstruct distortion-free images from B0 inhomogeneity-corrupted k-space for fast MRI-guided radiotherapy applications. RebinNet includes convolutional neural network (CNN) blocks to perform image regularizations and nonuniform fast Fourier Transform (NUFFT) modules to incorporate B0 inhomogeneity information. The RebinNet was trained on a publicly available MR dataset from eleven healthy volunteers for both fully sampled and subsampled acquisitions. Grid phantom and human brain images acquired from an open-bore 1T MRI-Linac scanner were used to evaluate the performance of the proposed network. The RebinNet was compared with the conventional regularization algorithm and our recently developed UnUNet method in terms of root mean squared error (RMSE), structural similarity (SSIM), residual distortions, and computation time. Imaging results demonstrated that the RebinNet reconstructed images with lowest RMSE (<0.05) and highest SSIM (>0.92) at four-time acceleration for simulated brain images. The RebinNet could better preserve structural details and substantially improve the computational efficiency (ten-fold faster) compared to the conventional regularization methods, and had better generalization ability than the UnUNet method. The proposed RebinNet can achieve rapid image reconstruction and overcome the B0 inhomogeneity distortions simultaneously, which would facilitate accurate and fast image guidance in radiotherapy treatments.
On the Learnability of Out-of-distribution Detection
Apr 07, 2024Supervised learning aims to train a classifier under the assumption that training and test data are from the same distribution. To ease the above assumption, researchers have studied a more realistic setting: out-of-distribution (OOD) detection, where test data may come from classes that are unknown during training (i.e., OOD data). Due to the unavailability and diversity of OOD data, good generalization ability is crucial for effective OOD detection algorithms, and corresponding learning theory is still an open problem. To study the generalization of OOD detection, this paper investigates the probably approximately correct (PAC) learning theory of OOD detection that fits the commonly used evaluation metrics in the literature. First, we find a necessary condition for the learnability of OOD detection. Then, using this condition, we prove several impossibility theorems for the learnability of OOD detection under some scenarios. Although the impossibility theorems are frustrating, we find that some conditions of these impossibility theorems may not hold in some practical scenarios. Based on this observation, we next give several necessary and sufficient conditions to characterize the learnability of OOD detection in some practical scenarios. Lastly, we offer theoretical support for representative OOD detection works based on our OOD theory.
Learn to Disguise: Avoid Refusal Responses in LLM's Defense via a Multi-agent Attacker-Disguiser Game
Apr 03, 2024With the enhanced performance of large models on natural language processing tasks, potential moral and ethical issues of large models arise. There exist malicious attackers who induce large models to jailbreak and generate information containing illegal, privacy-invasive information through techniques such as prompt engineering. As a result, large models counter malicious attackers' attacks using techniques such as safety alignment. However, the strong defense mechanism of the large model through rejection replies is easily identified by attackers and used to strengthen attackers' capabilities. In this paper, we propose a multi-agent attacker-disguiser game approach to achieve a weak defense mechanism that allows the large model to both safely reply to the attacker and hide the defense intent. First, we construct a multi-agent framework to simulate attack and defense scenarios, playing different roles to be responsible for attack, disguise, safety evaluation, and disguise evaluation tasks. After that, we design attack and disguise game algorithms to optimize the game strategies of the attacker and the disguiser and use the curriculum learning process to strengthen the capabilities of the agents. The experiments verify that the method in this paper is more effective in strengthening the model's ability to disguise the defense intent compared with other methods. Moreover, our approach can adapt any black-box large model to assist the model in defense and does not suffer from model version iterations.
Negative Label Guided OOD Detection with Pretrained Vision-Language Models
Mar 29, 2024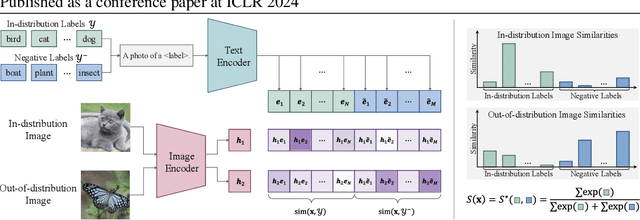
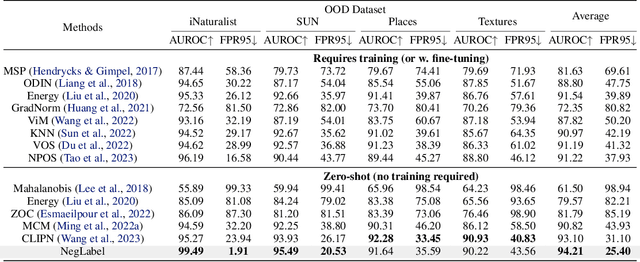

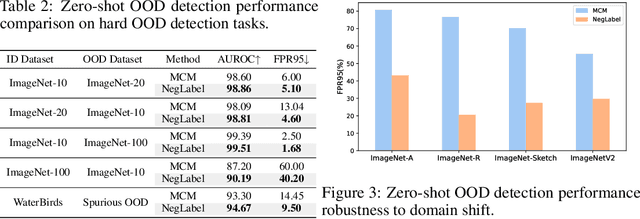
Out-of-distribution (OOD) detection aims at identifying samples from unknown classes, playing a crucial role in trustworthy models against errors on unexpected inputs. Extensive research has been dedicated to exploring OOD detection in the vision modality. Vision-language models (VLMs) can leverage both textual and visual information for various multi-modal applications, whereas few OOD detection methods take into account information from the text modality. In this paper, we propose a novel post hoc OOD detection method, called NegLabel, which takes a vast number of negative labels from extensive corpus databases. We design a novel scheme for the OOD score collaborated with negative labels. Theoretical analysis helps to understand the mechanism of negative labels. Extensive experiments demonstrate that our method NegLabel achieves state-of-the-art performance on various OOD detection benchmarks and generalizes well on multiple VLM architectures. Furthermore, our method NegLabel exhibits remarkable robustness against diverse domain shifts. The codes are available at https://github.com/tmlr-group/NegLabel.
Emotion Neural Transducer for Fine-Grained Speech Emotion Recognition
Mar 28, 2024The mainstream paradigm of speech emotion recognition (SER) is identifying the single emotion label of the entire utterance. This line of works neglect the emotion dynamics at fine temporal granularity and mostly fail to leverage linguistic information of speech signal explicitly. In this paper, we propose Emotion Neural Transducer for fine-grained speech emotion recognition with automatic speech recognition (ASR) joint training. We first extend typical neural transducer with emotion joint network to construct emotion lattice for fine-grained SER. Then we propose lattice max pooling on the alignment lattice to facilitate distinguishing emotional and non-emotional frames. To adapt fine-grained SER to transducer inference manner, we further make blank, the special symbol of ASR, serve as underlying emotion indicator as well, yielding Factorized Emotion Neural Transducer. For typical utterance-level SER, our ENT models outperform state-of-the-art methods on IEMOCAP in low word error rate. Experiments on IEMOCAP and the latest speech emotion diarization dataset ZED also demonstrate the superiority of fine-grained emotion modeling. Our code is available at https://github.com/ECNU-Cross-Innovation-Lab/ENT.
Benchmarking Video Frame Interpolation
Mar 25, 2024Video frame interpolation, the task of synthesizing new frames in between two or more given ones, is becoming an increasingly popular research target. However, the current evaluation of frame interpolation techniques is not ideal. Due to the plethora of test datasets available and inconsistent computation of error metrics, a coherent and fair comparison across papers is very challenging. Furthermore, new test sets have been proposed as part of method papers so they are unable to provide the in-depth evaluation of a dedicated benchmarking paper. Another severe downside is that these test sets violate the assumption of linearity when given two input frames, making it impossible to solve without an oracle. We hence strongly believe that the community would greatly benefit from a benchmarking paper, which is what we propose. Specifically, we present a benchmark which establishes consistent error metrics by utilizing a submission website that computes them, provides insights by analyzing the interpolation quality with respect to various per-pixel attributes such as the motion magnitude, contains a carefully designed test set adhering to the assumption of linearity by utilizing synthetic data, and evaluates the computational efficiency in a coherent manner.
KeyPoint Relative Position Encoding for Face Recognition
Mar 21, 2024In this paper, we address the challenge of making ViT models more robust to unseen affine transformations. Such robustness becomes useful in various recognition tasks such as face recognition when image alignment failures occur. We propose a novel method called KP-RPE, which leverages key points (e.g.~facial landmarks) to make ViT more resilient to scale, translation, and pose variations. We begin with the observation that Relative Position Encoding (RPE) is a good way to bring affine transform generalization to ViTs. RPE, however, can only inject the model with prior knowledge that nearby pixels are more important than far pixels. Keypoint RPE (KP-RPE) is an extension of this principle, where the significance of pixels is not solely dictated by their proximity but also by their relative positions to specific keypoints within the image. By anchoring the significance of pixels around keypoints, the model can more effectively retain spatial relationships, even when those relationships are disrupted by affine transformations. We show the merit of KP-RPE in face and gait recognition. The experimental results demonstrate the effectiveness in improving face recognition performance from low-quality images, particularly where alignment is prone to failure. Code and pre-trained models are available.
QSMDiff: Unsupervised 3D Diffusion Models for Quantitative Susceptibility Mapping
Mar 21, 2024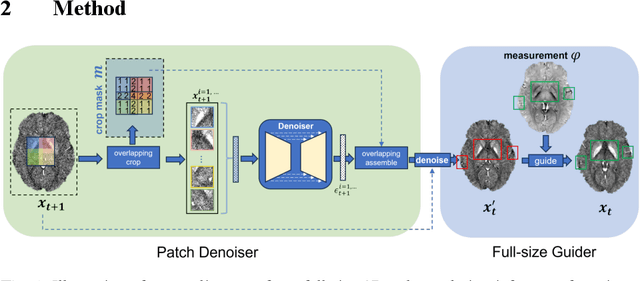
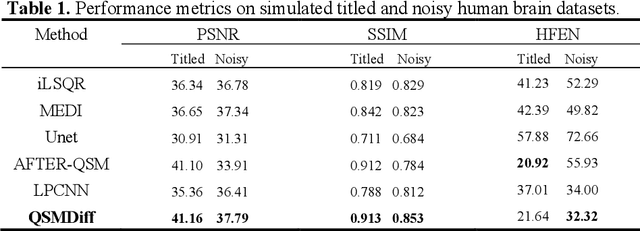
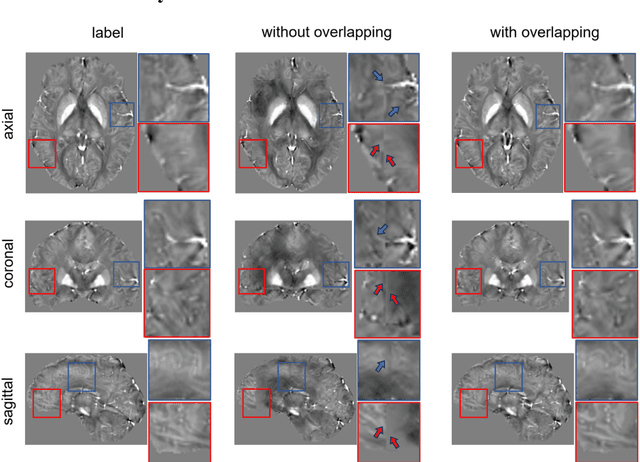
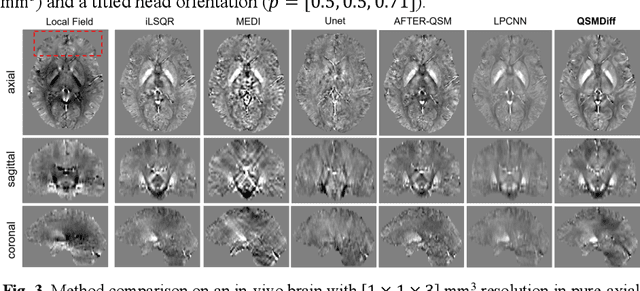
Quantitative Susceptibility Mapping (QSM) dipole inversion is an ill-posed inverse problem for quantifying magnetic susceptibility distributions from MRI tissue phases. While supervised deep learning methods have shown success in specific QSM tasks, their generalizability across different acquisition scenarios remains constrained. Recent developments in diffusion models have demonstrated potential for solving 2D medical imaging inverse problems. However, their application to 3D modalities, such as QSM, remains challenging due to high computational demands. In this work, we developed a 3D image patch-based diffusion model, namely QSMDiff, for robust QSM reconstruction across different scan parameters, alongside simultaneous super-resolution and image-denoising tasks. QSMDiff adopts unsupervised 3D image patch training and full-size measurement guidance during inference for controlled image generation. Evaluation on simulated and in-vivo human brains, using gradient-echo and echo-planar imaging sequences across different acquisition parameters, demonstrates superior performance. The method proposed in QSMDiff also holds promise for impacting other 3D medical imaging applications beyond QSM.
IIDM: Image-to-Image Diffusion Model for Semantic Image Synthesis
Mar 20, 2024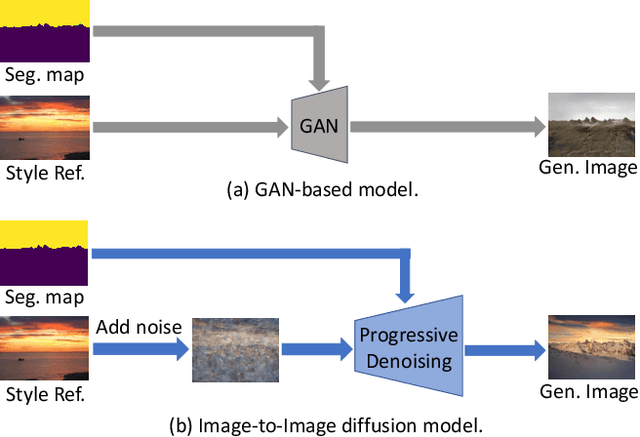
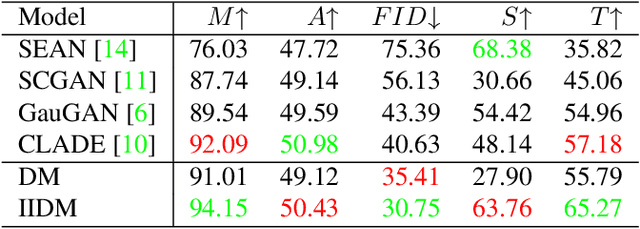
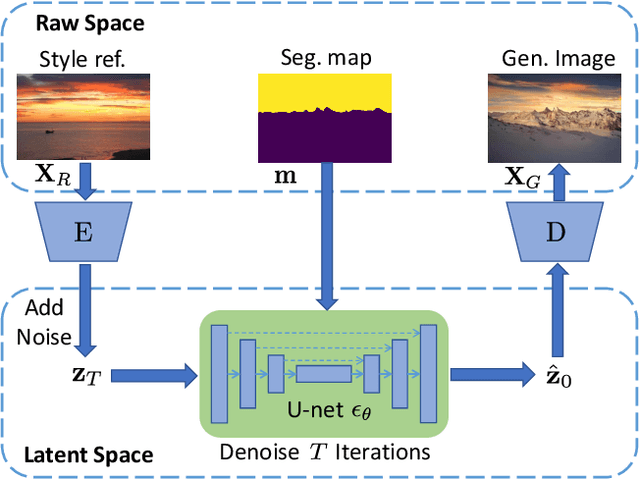
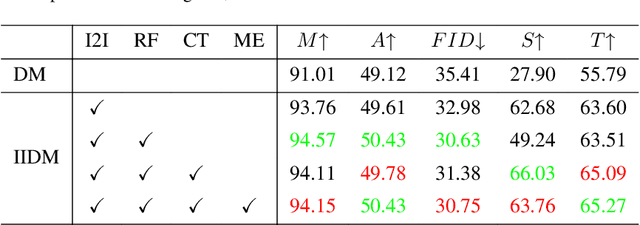
Semantic image synthesis aims to generate high-quality images given semantic conditions, i.e. segmentation masks and style reference images. Existing methods widely adopt generative adversarial networks (GANs). GANs take all conditional inputs and directly synthesize images in a single forward step. In this paper, semantic image synthesis is treated as an image denoising task and is handled with a novel image-to-image diffusion model (IIDM). Specifically, the style reference is first contaminated with random noise and then progressively denoised by IIDM, guided by segmentation masks. Moreover, three techniques, refinement, color-transfer and model ensembles, are proposed to further boost the generation quality. They are plug-in inference modules and do not require additional training. Extensive experiments show that our IIDM outperforms existing state-of-the-art methods by clear margins. Further analysis is provided via detailed demonstrations. We have implemented IIDM based on the Jittor framework; code is available at https://github.com/ader47/jittor-jieke-semantic_images_synthesis.