 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEli Shechtman
VideoGigaGAN: Towards Detail-rich Video Super-Resolution
Apr 18, 2024
Video super-resolution (VSR) approaches have shown impressive temporal consistency in upsampled videos. However, these approaches tend to generate blurrier results than their image counterparts as they are limited in their generative capability. This raises a fundamental question: can we extend the success of a generative image upsampler to the VSR task while preserving the temporal consistency? We introduce VideoGigaGAN, a new generative VSR model that can produce videos with high-frequency details and temporal consistency. VideoGigaGAN builds upon a large-scale image upsampler -- GigaGAN. Simply inflating GigaGAN to a video model by adding temporal modules produces severe temporal flickering. We identify several key issues and propose techniques that significantly improve the temporal consistency of upsampled videos. Our experiments show that, unlike previous VSR methods, VideoGigaGAN generates temporally consistent videos with more fine-grained appearance details. We validate the effectiveness of VideoGigaGAN by comparing it with state-of-the-art VSR models on public datasets and showcasing video results with $8\times$ super-resolution.
Lazy Diffusion Transformer for Interactive Image Editing
Apr 18, 2024We introduce a novel diffusion transformer, LazyDiffusion, that generates partial image updates efficiently. Our approach targets interactive image editing applications in which, starting from a blank canvas or an image, a user specifies a sequence of localized image modifications using binary masks and text prompts. Our generator operates in two phases. First, a context encoder processes the current canvas and user mask to produce a compact global context tailored to the region to generate. Second, conditioned on this context, a diffusion-based transformer decoder synthesizes the masked pixels in a "lazy" fashion, i.e., it only generates the masked region. This contrasts with previous works that either regenerate the full canvas, wasting time and computation, or confine processing to a tight rectangular crop around the mask, ignoring the global image context altogether. Our decoder's runtime scales with the mask size, which is typically small, while our encoder introduces negligible overhead. We demonstrate that our approach is competitive with state-of-the-art inpainting methods in terms of quality and fidelity while providing a 10x speedup for typical user interactions, where the editing mask represents 10% of the image.
Customizing Text-to-Image Diffusion with Camera Viewpoint Control
Apr 18, 2024Model customization introduces new concepts to existing text-to-image models, enabling the generation of the new concept in novel contexts. However, such methods lack accurate camera view control w.r.t the object, and users must resort to prompt engineering (e.g., adding "top-view") to achieve coarse view control. In this work, we introduce a new task -- enabling explicit control of camera viewpoint for model customization. This allows us to modify object properties amongst various background scenes via text prompts, all while incorporating the target camera pose as additional control. This new task presents significant challenges in merging a 3D representation from the multi-view images of the new concept with a general, 2D text-to-image model. To bridge this gap, we propose to condition the 2D diffusion process on rendered, view-dependent features of the new object. During training, we jointly adapt the 2D diffusion modules and 3D feature predictions to reconstruct the object's appearance and geometry while reducing overfitting to the input multi-view images. Our method outperforms existing image editing and model personalization baselines in preserving the custom object's identity while following the input text prompt and the object's camera pose.
Magic Fixup: Streamlining Photo Editing by Watching Dynamic Videos
Mar 19, 2024
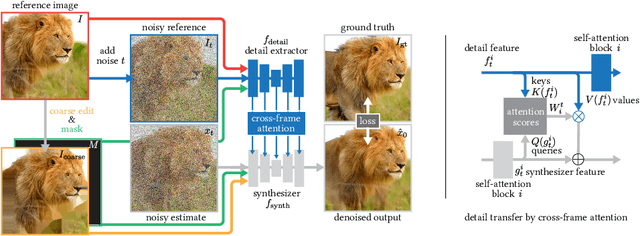


We propose a generative model that, given a coarsely edited image, synthesizes a photorealistic output that follows the prescribed layout. Our method transfers fine details from the original image and preserves the identity of its parts. Yet, it adapts it to the lighting and context defined by the new layout. Our key insight is that videos are a powerful source of supervision for this task: objects and camera motions provide many observations of how the world changes with viewpoint, lighting, and physical interactions. We construct an image dataset in which each sample is a pair of source and target frames extracted from the same video at randomly chosen time intervals. We warp the source frame toward the target using two motion models that mimic the expected test-time user edits. We supervise our model to translate the warped image into the ground truth, starting from a pretrained diffusion model. Our model design explicitly enables fine detail transfer from the source frame to the generated image, while closely following the user-specified layout. We show that by using simple segmentations and coarse 2D manipulations, we can synthesize a photorealistic edit faithful to the user's input while addressing second-order effects like harmonizing the lighting and physical interactions between edited objects.
Jump Cut Smoothing for Talking Heads
Jan 11, 2024A jump cut offers an abrupt, sometimes unwanted change in the viewing experience. We present a novel framework for smoothing these jump cuts, in the context of talking head videos. We leverage the appearance of the subject from the other source frames in the video, fusing it with a mid-level representation driven by DensePose keypoints and face landmarks. To achieve motion, we interpolate the keypoints and landmarks between the end frames around the cut. We then use an image translation network from the keypoints and source frames, to synthesize pixels. Because keypoints can contain errors, we propose a cross-modal attention scheme to select and pick the most appropriate source amongst multiple options for each key point. By leveraging this mid-level representation, our method can achieve stronger results than a strong video interpolation baseline. We demonstrate our method on various jump cuts in the talking head videos, such as cutting filler words, pauses, and even random cuts. Our experiments show that we can achieve seamless transitions, even in the challenging cases where the talking head rotates or moves drastically in the jump cut.
Customizing Motion in Text-to-Video Diffusion Models
Dec 07, 2023We introduce an approach for augmenting text-to-video generation models with customized motions, extending their capabilities beyond the motions depicted in the original training data. By leveraging a few video samples demonstrating specific movements as input, our method learns and generalizes the input motion patterns for diverse, text-specified scenarios. Our contributions are threefold. First, to achieve our results, we finetune an existing text-to-video model to learn a novel mapping between the depicted motion in the input examples to a new unique token. To avoid overfitting to the new custom motion, we introduce an approach for regularization over videos. Second, by leveraging the motion priors in a pretrained model, our method can produce novel videos featuring multiple people doing the custom motion, and can invoke the motion in combination with other motions. Furthermore, our approach extends to the multimodal customization of motion and appearance of individualized subjects, enabling the generation of videos featuring unique characters and distinct motions. Third, to validate our method, we introduce an approach for quantitatively evaluating the learned custom motion and perform a systematic ablation study. We show that our method significantly outperforms prior appearance-based customization approaches when extended to the motion customization task.
One-step Diffusion with Distribution Matching Distillation
Dec 05, 2023Diffusion models generate high-quality images but require dozens of forward passes. We introduce Distribution Matching Distillation (DMD), a procedure to transform a diffusion model into a one-step image generator with minimal impact on image quality. We enforce the one-step image generator match the diffusion model at distribution level, by minimizing an approximate KL divergence whose gradient can be expressed as the difference between 2 score functions, one of the target distribution and the other of the synthetic distribution being produced by our one-step generator. The score functions are parameterized as two diffusion models trained separately on each distribution. Combined with a simple regression loss matching the large-scale structure of the multi-step diffusion outputs, our method outperforms all published few-step diffusion approaches, reaching 2.62 FID on ImageNet 64x64 and 11.49 FID on zero-shot COCO-30k, comparable to Stable Diffusion but orders of magnitude faster. Utilizing FP16 inference, our model generates images at 20 FPS on modern hardware.
Perceptual Artifacts Localization for Image Synthesis Tasks
Oct 09, 2023

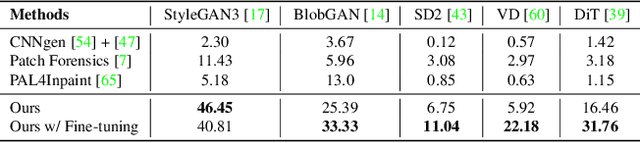
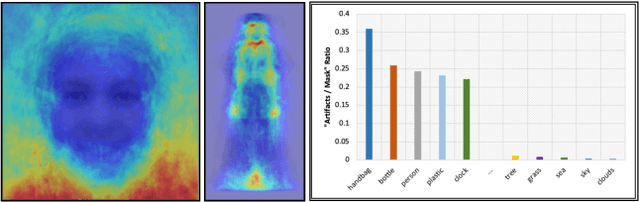
Recent advancements in deep generative models have facilitated the creation of photo-realistic images across various tasks. However, these generated images often exhibit perceptual artifacts in specific regions, necessitating manual correction. In this study, we present a comprehensive empirical examination of Perceptual Artifacts Localization (PAL) spanning diverse image synthesis endeavors. We introduce a novel dataset comprising 10,168 generated images, each annotated with per-pixel perceptual artifact labels across ten synthesis tasks. A segmentation model, trained on our proposed dataset, effectively localizes artifacts across a range of tasks. Additionally, we illustrate its proficiency in adapting to previously unseen models using minimal training samples. We further propose an innovative zoom-in inpainting pipeline that seamlessly rectifies perceptual artifacts in the generated images. Through our experimental analyses, we elucidate several practical downstream applications, such as automated artifact rectification, non-referential image quality evaluation, and abnormal region detection in images. The dataset and code are released.
DIFF-NST: Diffusion Interleaving For deFormable Neural Style Transfer
Jul 11, 2023
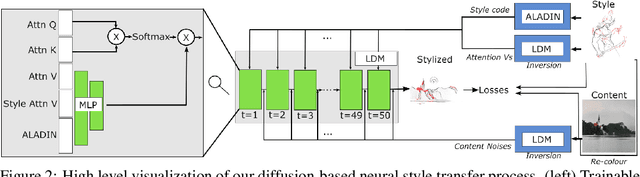


Neural Style Transfer (NST) is the field of study applying neural techniques to modify the artistic appearance of a content image to match the style of a reference style image. Traditionally, NST methods have focused on texture-based image edits, affecting mostly low level information and keeping most image structures the same. However, style-based deformation of the content is desirable for some styles, especially in cases where the style is abstract or the primary concept of the style is in its deformed rendition of some content. With the recent introduction of diffusion models, such as Stable Diffusion, we can access far more powerful image generation techniques, enabling new possibilities. In our work, we propose using this new class of models to perform style transfer while enabling deformable style transfer, an elusive capability in previous models. We show how leveraging the priors of these models can expose new artistic controls at inference time, and we document our findings in exploring this new direction for the field of style transfer.