 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDaniel Cohen-Or
Lazy Diffusion Transformer for Interactive Image Editing
Apr 18, 2024
We introduce a novel diffusion transformer, LazyDiffusion, that generates partial image updates efficiently. Our approach targets interactive image editing applications in which, starting from a blank canvas or an image, a user specifies a sequence of localized image modifications using binary masks and text prompts. Our generator operates in two phases. First, a context encoder processes the current canvas and user mask to produce a compact global context tailored to the region to generate. Second, conditioned on this context, a diffusion-based transformer decoder synthesizes the masked pixels in a "lazy" fashion, i.e., it only generates the masked region. This contrasts with previous works that either regenerate the full canvas, wasting time and computation, or confine processing to a tight rectangular crop around the mask, ignoring the global image context altogether. Our decoder's runtime scales with the mask size, which is typically small, while our encoder introduces negligible overhead. We demonstrate that our approach is competitive with state-of-the-art inpainting methods in terms of quality and fidelity while providing a 10x speedup for typical user interactions, where the editing mask represents 10% of the image.
Dynamic Typography: Bringing Text to Life via Video Diffusion Prior
Apr 18, 2024Text animation serves as an expressive medium, transforming static communication into dynamic experiences by infusing words with motion to evoke emotions, emphasize meanings, and construct compelling narratives. Crafting animations that are semantically aware poses significant challenges, demanding expertise in graphic design and animation. We present an automated text animation scheme, termed "Dynamic Typography", which combines two challenging tasks. It deforms letters to convey semantic meaning and infuses them with vibrant movements based on user prompts. Our technique harnesses vector graphics representations and an end-to-end optimization-based framework. This framework employs neural displacement fields to convert letters into base shapes and applies per-frame motion, encouraging coherence with the intended textual concept. Shape preservation techniques and perceptual loss regularization are employed to maintain legibility and structural integrity throughout the animation process. We demonstrate the generalizability of our approach across various text-to-video models and highlight the superiority of our end-to-end methodology over baseline methods, which might comprise separate tasks. Through quantitative and qualitative evaluations, we demonstrate the effectiveness of our framework in generating coherent text animations that faithfully interpret user prompts while maintaining readability. Our code is available at: https://animate-your-word.github.io/demo/.
LCM-Lookahead for Encoder-based Text-to-Image Personalization
Apr 04, 2024Recent advancements in diffusion models have introduced fast sampling methods that can effectively produce high-quality images in just one or a few denoising steps. Interestingly, when these are distilled from existing diffusion models, they often maintain alignment with the original model, retaining similar outputs for similar prompts and seeds. These properties present opportunities to leverage fast sampling methods as a shortcut-mechanism, using them to create a preview of denoised outputs through which we can backpropagate image-space losses. In this work, we explore the potential of using such shortcut-mechanisms to guide the personalization of text-to-image models to specific facial identities. We focus on encoder-based personalization approaches, and demonstrate that by tuning them with a lookahead identity loss, we can achieve higher identity fidelity, without sacrificing layout diversity or prompt alignment. We further explore the use of attention sharing mechanisms and consistent data generation for the task of personalization, and find that encoder training can benefit from both.
Be Yourself: Bounded Attention for Multi-Subject Text-to-Image Generation
Mar 25, 2024Text-to-image diffusion models have an unprecedented ability to generate diverse and high-quality images. However, they often struggle to faithfully capture the intended semantics of complex input prompts that include multiple subjects. Recently, numerous layout-to-image extensions have been introduced to improve user control, aiming to localize subjects represented by specific tokens. Yet, these methods often produce semantically inaccurate images, especially when dealing with multiple semantically or visually similar subjects. In this work, we study and analyze the causes of these limitations. Our exploration reveals that the primary issue stems from inadvertent semantic leakage between subjects in the denoising process. This leakage is attributed to the diffusion model's attention layers, which tend to blend the visual features of different subjects. To address these issues, we introduce Bounded Attention, a training-free method for bounding the information flow in the sampling process. Bounded Attention prevents detrimental leakage among subjects and enables guiding the generation to promote each subject's individuality, even with complex multi-subject conditioning. Through extensive experimentation, we demonstrate that our method empowers the generation of multiple subjects that better align with given prompts and layouts.
MyVLM: Personalizing VLMs for User-Specific Queries
Mar 21, 2024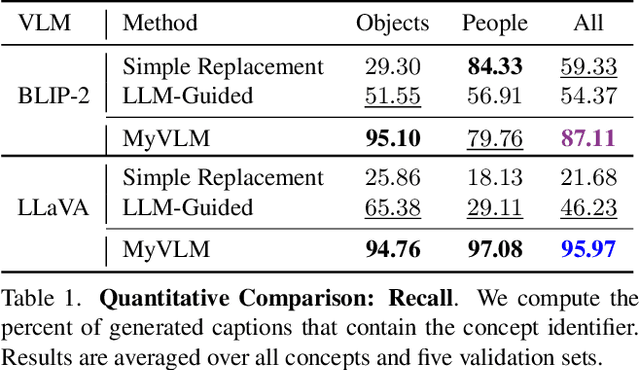
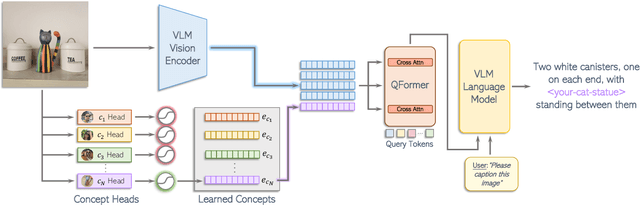
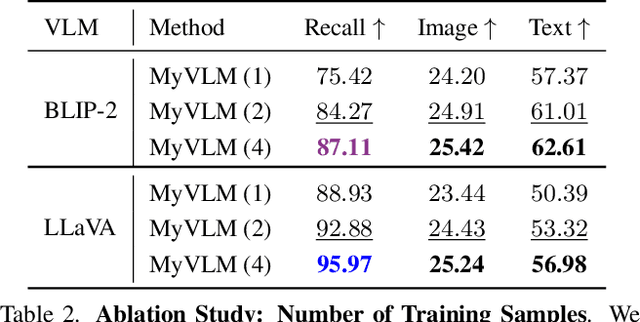

Recent large-scale vision-language models (VLMs) have demonstrated remarkable capabilities in understanding and generating textual descriptions for visual content. However, these models lack an understanding of user-specific concepts. In this work, we take a first step toward the personalization of VLMs, enabling them to learn and reason over user-provided concepts. For example, we explore whether these models can learn to recognize you in an image and communicate what you are doing, tailoring the model to reflect your personal experiences and relationships. To effectively recognize a variety of user-specific concepts, we augment the VLM with external concept heads that function as toggles for the model, enabling the VLM to identify the presence of specific target concepts in a given image. Having recognized the concept, we learn a new concept embedding in the intermediate feature space of the VLM. This embedding is tasked with guiding the language model to naturally integrate the target concept in its generated response. We apply our technique to BLIP-2 and LLaVA for personalized image captioning and further show its applicability for personalized visual question-answering. Our experiments demonstrate our ability to generalize to unseen images of learned concepts while preserving the model behavior on unrelated inputs.
Implicit Style-Content Separation using B-LoRA
Mar 21, 2024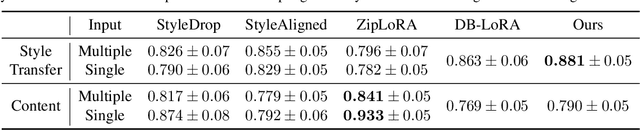

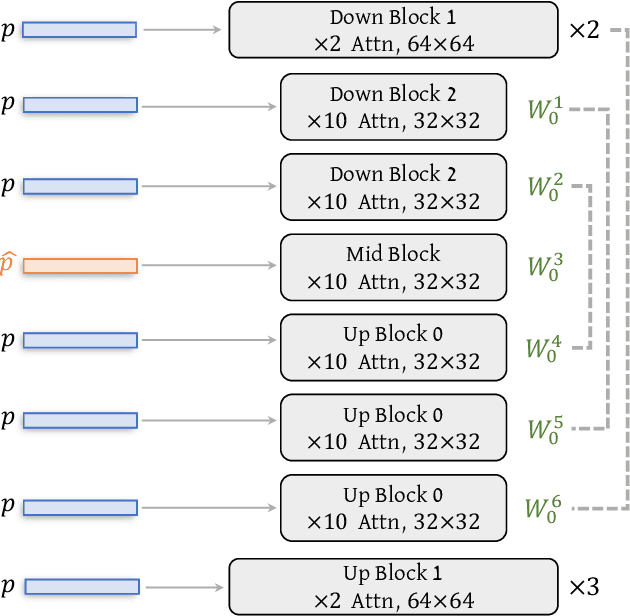

Image stylization involves manipulating the visual appearance and texture (style) of an image while preserving its underlying objects, structures, and concepts (content). The separation of style and content is essential for manipulating the image's style independently from its content, ensuring a harmonious and visually pleasing result. Achieving this separation requires a deep understanding of both the visual and semantic characteristics of images, often necessitating the training of specialized models or employing heavy optimization. In this paper, we introduce B-LoRA, a method that leverages LoRA (Low-Rank Adaptation) to implicitly separate the style and content components of a single image, facilitating various image stylization tasks. By analyzing the architecture of SDXL combined with LoRA, we find that jointly learning the LoRA weights of two specific blocks (referred to as B-LoRAs) achieves style-content separation that cannot be achieved by training each B-LoRA independently. Consolidating the training into only two blocks and separating style and content allows for significantly improving style manipulation and overcoming overfitting issues often associated with model fine-tuning. Once trained, the two B-LoRAs can be used as independent components to allow various image stylization tasks, including image style transfer, text-based image stylization, consistent style generation, and style-content mixing.
ReNoise: Real Image Inversion Through Iterative Noising
Mar 21, 2024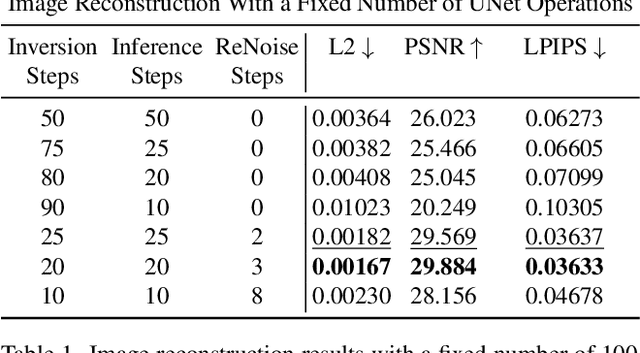

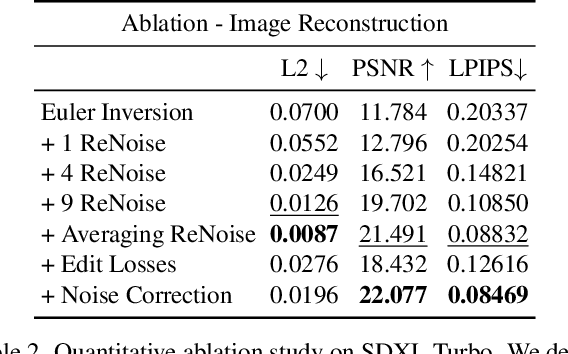

Recent advancements in text-guided diffusion models have unlocked powerful image manipulation capabilities. However, applying these methods to real images necessitates the inversion of the images into the domain of the pretrained diffusion model. Achieving faithful inversion remains a challenge, particularly for more recent models trained to generate images with a small number of denoising steps. In this work, we introduce an inversion method with a high quality-to-operation ratio, enhancing reconstruction accuracy without increasing the number of operations. Building on reversing the diffusion sampling process, our method employs an iterative renoising mechanism at each inversion sampling step. This mechanism refines the approximation of a predicted point along the forward diffusion trajectory, by iteratively applying the pretrained diffusion model, and averaging these predictions. We evaluate the performance of our ReNoise technique using various sampling algorithms and models, including recent accelerated diffusion models. Through comprehensive evaluations and comparisons, we show its effectiveness in terms of both accuracy and speed. Furthermore, we confirm that our method preserves editability by demonstrating text-driven image editing on real images.
Consolidating Attention Features for Multi-view Image Editing
Feb 22, 2024Large-scale text-to-image models enable a wide range of image editing techniques, using text prompts or even spatial controls. However, applying these editing methods to multi-view images depicting a single scene leads to 3D-inconsistent results. In this work, we focus on spatial control-based geometric manipulations and introduce a method to consolidate the editing process across various views. We build on two insights: (1) maintaining consistent features throughout the generative process helps attain consistency in multi-view editing, and (2) the queries in self-attention layers significantly influence the image structure. Hence, we propose to improve the geometric consistency of the edited images by enforcing the consistency of the queries. To do so, we introduce QNeRF, a neural radiance field trained on the internal query features of the edited images. Once trained, QNeRF can render 3D-consistent queries, which are then softly injected back into the self-attention layers during generation, greatly improving multi-view consistency. We refine the process through a progressive, iterative method that better consolidates queries across the diffusion timesteps. We compare our method to a range of existing techniques and demonstrate that it can achieve better multi-view consistency and higher fidelity to the input scene. These advantages allow us to train NeRFs with fewer visual artifacts, that are better aligned with the target geometry.
PALP: Prompt Aligned Personalization of Text-to-Image Models
Jan 11, 2024Content creators often aim to create personalized images using personal subjects that go beyond the capabilities of conventional text-to-image models. Additionally, they may want the resulting image to encompass a specific location, style, ambiance, and more. Existing personalization methods may compromise personalization ability or the alignment to complex textual prompts. This trade-off can impede the fulfillment of user prompts and subject fidelity. We propose a new approach focusing on personalization methods for a \emph{single} prompt to address this issue. We term our approach prompt-aligned personalization. While this may seem restrictive, our method excels in improving text alignment, enabling the creation of images with complex and intricate prompts, which may pose a challenge for current techniques. In particular, our method keeps the personalized model aligned with a target prompt using an additional score distillation sampling term. We demonstrate the versatility of our method in multi- and single-shot settings and further show that it can compose multiple subjects or use inspiration from reference images, such as artworks. We compare our approach quantitatively and qualitatively with existing baselines and state-of-the-art techniques.
Generating Non-Stationary Textures using Self-Rectification
Jan 05, 2024This paper addresses the challenge of example-based non-stationary texture synthesis. We introduce a novel twostep approach wherein users first modify a reference texture using standard image editing tools, yielding an initial rough target for the synthesis. Subsequently, our proposed method, termed "self-rectification", automatically refines this target into a coherent, seamless texture, while faithfully preserving the distinct visual characteristics of the reference exemplar. Our method leverages a pre-trained diffusion network, and uses self-attention mechanisms, to gradually align the synthesized texture with the reference, ensuring the retention of the structures in the provided target. Through experimental validation, our approach exhibits exceptional proficiency in handling non-stationary textures, demonstrating significant advancements in texture synthesis when compared to existing state-of-the-art techniques. Code is available at https://github.com/xiaorongjun000/Self-Rectification