 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmit H. Bermano
LCM-Lookahead for Encoder-based Text-to-Image Personalization
Apr 04, 2024
Recent advancements in diffusion models have introduced fast sampling methods that can effectively produce high-quality images in just one or a few denoising steps. Interestingly, when these are distilled from existing diffusion models, they often maintain alignment with the original model, retaining similar outputs for similar prompts and seeds. These properties present opportunities to leverage fast sampling methods as a shortcut-mechanism, using them to create a preview of denoised outputs through which we can backpropagate image-space losses. In this work, we explore the potential of using such shortcut-mechanisms to guide the personalization of text-to-image models to specific facial identities. We focus on encoder-based personalization approaches, and demonstrate that by tuning them with a lookahead identity loss, we can achieve higher identity fidelity, without sacrificing layout diversity or prompt alignment. We further explore the use of attention sharing mechanisms and consistent data generation for the task of personalization, and find that encoder training can benefit from both.
Breathing Life Into Sketches Using Text-to-Video Priors
Nov 21, 2023A sketch is one of the most intuitive and versatile tools humans use to convey their ideas visually. An animated sketch opens another dimension to the expression of ideas and is widely used by designers for a variety of purposes. Animating sketches is a laborious process, requiring extensive experience and professional design skills. In this work, we present a method that automatically adds motion to a single-subject sketch (hence, "breathing life into it"), merely by providing a text prompt indicating the desired motion. The output is a short animation provided in vector representation, which can be easily edited. Our method does not require extensive training, but instead leverages the motion prior of a large pretrained text-to-video diffusion model using a score-distillation loss to guide the placement of strokes. To promote natural and smooth motion and to better preserve the sketch's appearance, we model the learned motion through two components. The first governs small local deformations and the second controls global affine transformations. Surprisingly, we find that even models that struggle to generate sketch videos on their own can still serve as a useful backbone for animating abstract representations.
MAS: Multi-view Ancestral Sampling for 3D motion generation using 2D diffusion
Oct 23, 2023



We introduce Multi-view Ancestral Sampling (MAS), a method for generating consistent multi-view 2D samples of a motion sequence, enabling the creation of its 3D counterpart. MAS leverages a diffusion model trained solely on 2D data, opening opportunities to exciting and diverse fields of motion previously under-explored as 3D data is scarce and hard to collect. MAS works by simultaneously denoising multiple 2D motion sequences representing the same motion from different angles. Our consistency block ensures consistency across all views at each diffusion step by combining the individual generations into a unified 3D sequence, and projecting it back to the original views for the next iteration. We demonstrate MAS on 2D pose data acquired from videos depicting professional basketball maneuvers, rhythmic gymnastic performances featuring a ball apparatus, and horse obstacle course races. In each of these domains, 3D motion capture is arduous, and yet, MAS generates diverse and realistic 3D sequences without textual conditioning. As we demonstrate, our ancestral sampling-based approach offers a more natural integration with the diffusion framework compared to popular denoising optimization-based approaches, and avoids common issues such as out-of-domain sampling, lack of details and mode-collapse. https://guytevet.github.io/mas-page/
State of the Art on Diffusion Models for Visual Computing
Oct 11, 2023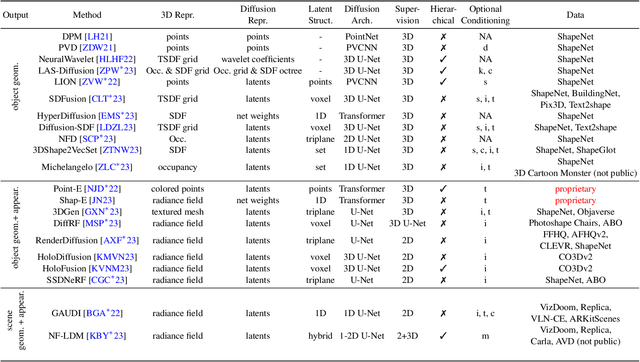

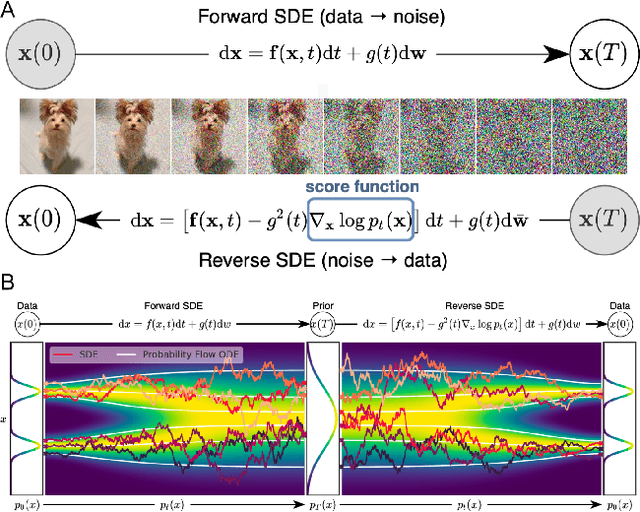
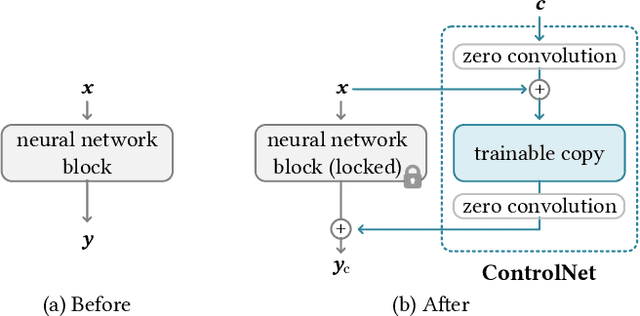
The field of visual computing is rapidly advancing due to the emergence of generative artificial intelligence (AI), which unlocks unprecedented capabilities for the generation, editing, and reconstruction of images, videos, and 3D scenes. In these domains, diffusion models are the generative AI architecture of choice. Within the last year alone, the literature on diffusion-based tools and applications has seen exponential growth and relevant papers are published across the computer graphics, computer vision, and AI communities with new works appearing daily on arXiv. This rapid growth of the field makes it difficult to keep up with all recent developments. The goal of this state-of-the-art report (STAR) is to introduce the basic mathematical concepts of diffusion models, implementation details and design choices of the popular Stable Diffusion model, as well as overview important aspects of these generative AI tools, including personalization, conditioning, inversion, among others. Moreover, we give a comprehensive overview of the rapidly growing literature on diffusion-based generation and editing, categorized by the type of generated medium, including 2D images, videos, 3D objects, locomotion, and 4D scenes. Finally, we discuss available datasets, metrics, open challenges, and social implications. This STAR provides an intuitive starting point to explore this exciting topic for researchers, artists, and practitioners alike.
OMG-ATTACK: Self-Supervised On-Manifold Generation of Transferable Evasion Attacks
Oct 05, 2023Evasion Attacks (EA) are used to test the robustness of trained neural networks by distorting input data to misguide the model into incorrect classifications. Creating these attacks is a challenging task, especially with the ever-increasing complexity of models and datasets. In this work, we introduce a self-supervised, computationally economical method for generating adversarial examples, designed for the unseen black-box setting. Adapting techniques from representation learning, our method generates on-manifold EAs that are encouraged to resemble the data distribution. These attacks are comparable in effectiveness compared to the state-of-the-art when attacking the model trained on, but are significantly more effective when attacking unseen models, as the attacks are more related to the data rather than the model itself. Our experiments consistently demonstrate the method is effective across various models, unseen data categories, and even defended models, suggesting a significant role for on-manifold EAs when targeting unseen models.
Performance Conditioning for Diffusion-Based Multi-Instrument Music Synthesis
Sep 21, 2023Generating multi-instrument music from symbolic music representations is an important task in Music Information Retrieval (MIR). A central but still largely unsolved problem in this context is musically and acoustically informed control in the generation process. As the main contribution of this work, we propose enhancing control of multi-instrument synthesis by conditioning a generative model on a specific performance and recording environment, thus allowing for better guidance of timbre and style. Building on state-of-the-art diffusion-based music generative models, we introduce performance conditioning - a simple tool indicating the generative model to synthesize music with style and timbre of specific instruments taken from specific performances. Our prototype is evaluated using uncurated performances with diverse instrumentation and achieves state-of-the-art FAD realism scores while allowing novel timbre and style control. Our project page, including samples and demonstrations, is available at benadar293.github.io/midipm
Domain-Agnostic Tuning-Encoder for Fast Personalization of Text-To-Image Models
Jul 13, 2023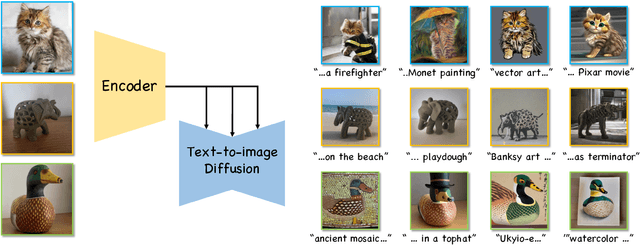
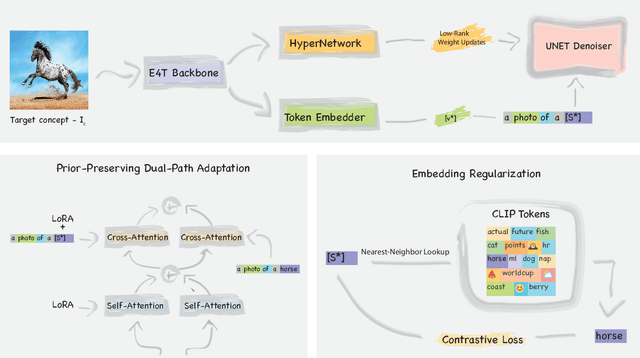


Text-to-image (T2I) personalization allows users to guide the creative image generation process by combining their own visual concepts in natural language prompts. Recently, encoder-based techniques have emerged as a new effective approach for T2I personalization, reducing the need for multiple images and long training times. However, most existing encoders are limited to a single-class domain, which hinders their ability to handle diverse concepts. In this work, we propose a domain-agnostic method that does not require any specialized dataset or prior information about the personalized concepts. We introduce a novel contrastive-based regularization technique to maintain high fidelity to the target concept characteristics while keeping the predicted embeddings close to editable regions of the latent space, by pushing the predicted tokens toward their nearest existing CLIP tokens. Our experimental results demonstrate the effectiveness of our approach and show how the learned tokens are more semantic than tokens predicted by unregularized models. This leads to a better representation that achieves state-of-the-art performance while being more flexible than previous methods.
Neural Projection Mapping Using Reflectance Fields
Jun 11, 2023
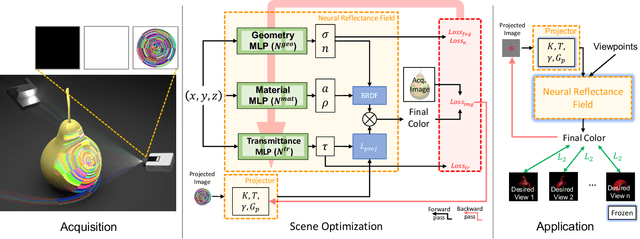
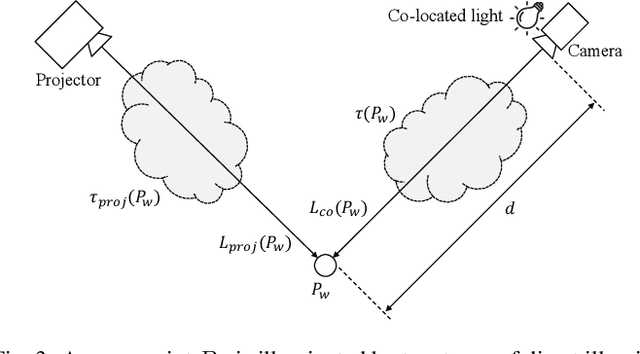
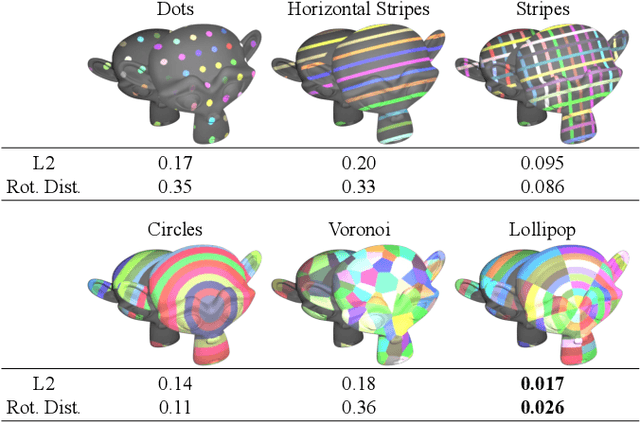
We introduce a high resolution spatially adaptive light source, or a projector, into a neural reflectance field that allows to both calibrate the projector and photo realistic light editing. The projected texture is fully differentiable with respect to all scene parameters, and can be optimized to yield a desired appearance suitable for applications in augmented reality and projection mapping. Our neural field consists of three neural networks, estimating geometry, material, and transmittance. Using an analytical BRDF model and carefully selected projection patterns, our acquisition process is simple and intuitive, featuring a fixed uncalibrated projected and a handheld camera with a co-located light source. As we demonstrate, the virtual projector incorporated into the pipeline improves scene understanding and enables various projection mapping applications, alleviating the need for time consuming calibration steps performed in a traditional setting per view or projector location. In addition to enabling novel viewpoint synthesis, we demonstrate state-of-the-art performance projector compensation for novel viewpoints, improvement over the baselines in material and scene reconstruction, and three simply implemented scenarios where projection image optimization is performed, including the use of a 2D generative model to consistently dictate scene appearance from multiple viewpoints. We believe that neural projection mapping opens up the door to novel and exciting downstream tasks, through the joint optimization of the scene and projection images.
Encoder-based Domain Tuning for Fast Personalization of Text-to-Image Models
Mar 05, 2023
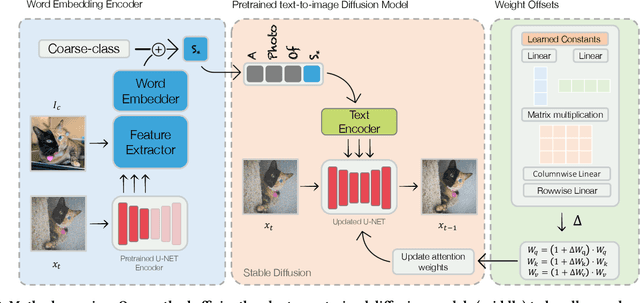

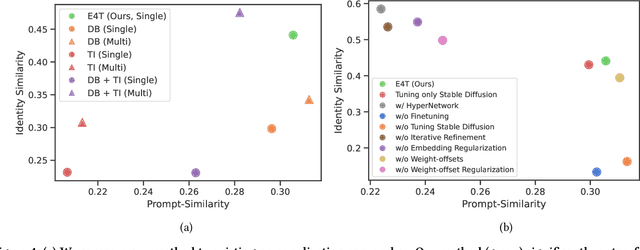
Text-to-image personalization aims to teach a pre-trained diffusion model to reason about novel, user provided concepts, embedding them into new scenes guided by natural language prompts. However, current personalization approaches struggle with lengthy training times, high storage requirements or loss of identity. To overcome these limitations, we propose an encoder-based domain-tuning approach. Our key insight is that by underfitting on a large set of concepts from a given domain, we can improve generalization and create a model that is more amenable to quickly adding novel concepts from the same domain. Specifically, we employ two components: First, an encoder that takes as an input a single image of a target concept from a given domain, e.g. a specific face, and learns to map it into a word-embedding representing the concept. Second, a set of regularized weight-offsets for the text-to-image model that learn how to effectively ingest additional concepts. Together, these components are used to guide the learning of unseen concepts, allowing us to personalize a model using only a single image and as few as 5 training steps - accelerating personalization from dozens of minutes to seconds, while preserving quality.
Human Motion Diffusion as a Generative Prior
Mar 02, 2023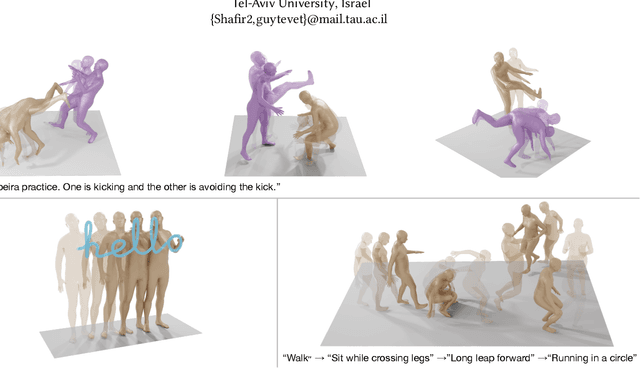

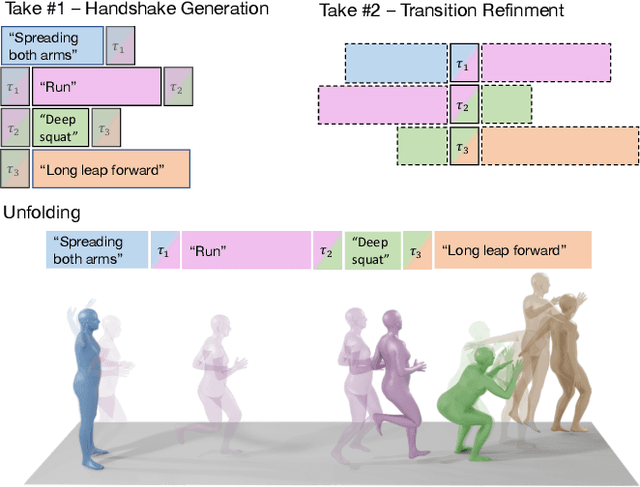
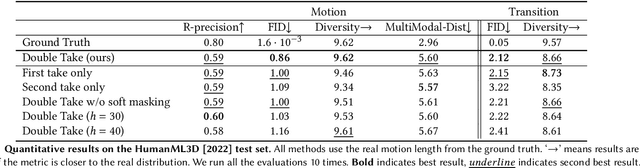
In recent months, we witness a leap forward as denoising diffusion models were introduced to Motion Generation. Yet, the main gap in this field remains the low availability of data. Furthermore, the expensive acquisition process of motion biases the already modest data towards short single-person sequences. With such a shortage, more elaborate generative tasks are left behind. In this paper, we show that this gap can be mitigated using a pre-trained diffusion-based model as a generative prior. We demonstrate the prior is effective for fine-tuning, in a few-, and even a zero-shot manner. For the zero-shot setting, we tackle the challenge of long sequence generation. We introduce DoubleTake, an inference-time method with which we demonstrate up to 10-minute long animations of prompted intervals and their meaningful and controlled transition, using the prior that was trained for 10-second generations. For the few-shot setting, we consider two-person generation. Using two fixed priors and as few as a dozen training examples, we learn a slim communication block, ComMDM, to infuse interaction between the two resulting motions. Finally, using fine-tuning, we train the prior to semantically complete motions from a single prescribed joint. Then, we use our DiffusionBlending to blend a few such models into a single one that responds well to the combination of the individual control signals, enabling fine-grained joint- and trajectory-level control and editing. Using an off-the-shelf state-of-the-art (SOTA) motion diffusion model as a prior, we evaluate our approach for the three mentioned cases and show that we consistently outperform SOTA models that were designed and trained for those tasks.