 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTali Dekel
DINO-Tracker: Taming DINO for Self-Supervised Point Tracking in a Single Video
Mar 21, 2024
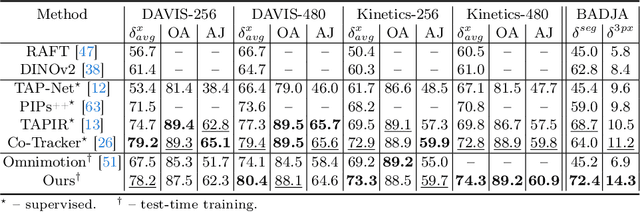
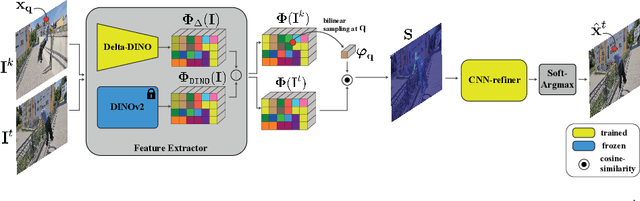
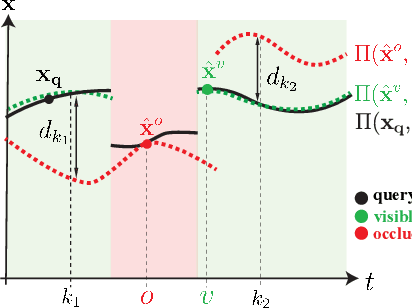

We present DINO-Tracker -- a new framework for long-term dense tracking in video. The pillar of our approach is combining test-time training on a single video, with the powerful localized semantic features learned by a pre-trained DINO-ViT model. Specifically, our framework simultaneously adopts DINO's features to fit to the motion observations of the test video, while training a tracker that directly leverages the refined features. The entire framework is trained end-to-end using a combination of self-supervised losses, and regularization that allows us to retain and benefit from DINO's semantic prior. Extensive evaluation demonstrates that our method achieves state-of-the-art results on known benchmarks. DINO-tracker significantly outperforms self-supervised methods and is competitive with state-of-the-art supervised trackers, while outperforming them in challenging cases of tracking under long-term occlusions.
Lumiere: A Space-Time Diffusion Model for Video Generation
Feb 05, 2024We introduce Lumiere -- a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse and coherent motion -- a pivotal challenge in video synthesis. To this end, we introduce a Space-Time U-Net architecture that generates the entire temporal duration of the video at once, through a single pass in the model. This is in contrast to existing video models which synthesize distant keyframes followed by temporal super-resolution -- an approach that inherently makes global temporal consistency difficult to achieve. By deploying both spatial and (importantly) temporal down- and up-sampling and leveraging a pre-trained text-to-image diffusion model, our model learns to directly generate a full-frame-rate, low-resolution video by processing it in multiple space-time scales. We demonstrate state-of-the-art text-to-video generation results, and show that our design easily facilitates a wide range of content creation tasks and video editing applications, including image-to-video, video inpainting, and stylized generation.
Space-Time Diffusion Features for Zero-Shot Text-Driven Motion Transfer
Dec 03, 2023We present a new method for text-driven motion transfer - synthesizing a video that complies with an input text prompt describing the target objects and scene while maintaining an input video's motion and scene layout. Prior methods are confined to transferring motion across two subjects within the same or closely related object categories and are applicable for limited domains (e.g., humans). In this work, we consider a significantly more challenging setting in which the target and source objects differ drastically in shape and fine-grained motion characteristics (e.g., translating a jumping dog into a dolphin). To this end, we leverage a pre-trained and fixed text-to-video diffusion model, which provides us with generative and motion priors. The pillar of our method is a new space-time feature loss derived directly from the model. This loss guides the generation process to preserve the overall motion of the input video while complying with the target object in terms of shape and fine-grained motion traits.
Disentangling Structure and Appearance in ViT Feature Space
Nov 20, 2023

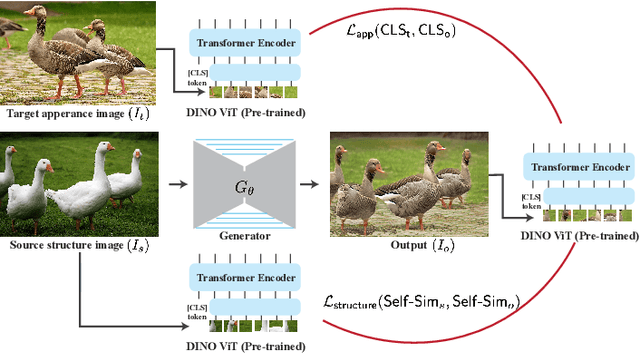

We present a method for semantically transferring the visual appearance of one natural image to another. Specifically, our goal is to generate an image in which objects in a source structure image are "painted" with the visual appearance of their semantically related objects in a target appearance image. To integrate semantic information into our framework, our key idea is to leverage a pre-trained and fixed Vision Transformer (ViT) model. Specifically, we derive novel disentangled representations of structure and appearance extracted from deep ViT features. We then establish an objective function that splices the desired structure and appearance representations, interweaving them together in the space of ViT features. Based on our objective function, we propose two frameworks of semantic appearance transfer -- "Splice", which works by training a generator on a single and arbitrary pair of structure-appearance images, and "SpliceNet", a feed-forward real-time appearance transfer model trained on a dataset of images from a specific domain. Our frameworks do not involve adversarial training, nor do they require any additional input information such as semantic segmentation or correspondences. We demonstrate high-resolution results on a variety of in-the-wild image pairs, under significant variations in the number of objects, pose, and appearance. Code and supplementary material are available in our project page: splice-vit.github.io.
State of the Art on Diffusion Models for Visual Computing
Oct 11, 2023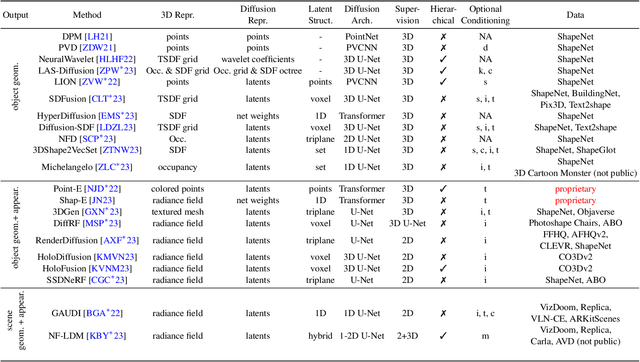

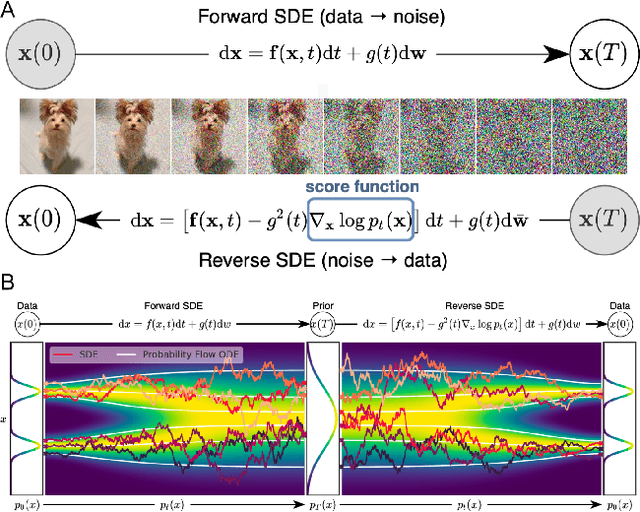
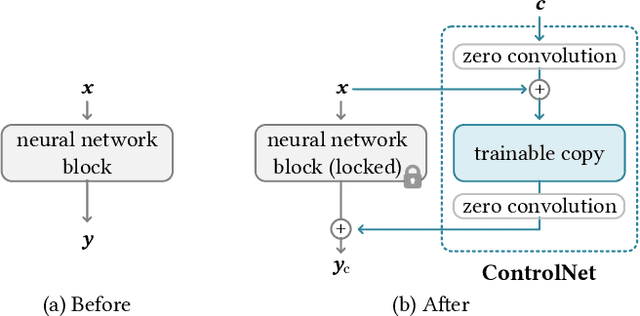
The field of visual computing is rapidly advancing due to the emergence of generative artificial intelligence (AI), which unlocks unprecedented capabilities for the generation, editing, and reconstruction of images, videos, and 3D scenes. In these domains, diffusion models are the generative AI architecture of choice. Within the last year alone, the literature on diffusion-based tools and applications has seen exponential growth and relevant papers are published across the computer graphics, computer vision, and AI communities with new works appearing daily on arXiv. This rapid growth of the field makes it difficult to keep up with all recent developments. The goal of this state-of-the-art report (STAR) is to introduce the basic mathematical concepts of diffusion models, implementation details and design choices of the popular Stable Diffusion model, as well as overview important aspects of these generative AI tools, including personalization, conditioning, inversion, among others. Moreover, we give a comprehensive overview of the rapidly growing literature on diffusion-based generation and editing, categorized by the type of generated medium, including 2D images, videos, 3D objects, locomotion, and 4D scenes. Finally, we discuss available datasets, metrics, open challenges, and social implications. This STAR provides an intuitive starting point to explore this exciting topic for researchers, artists, and practitioners alike.
TokenFlow: Consistent Diffusion Features for Consistent Video Editing
Jul 23, 2023
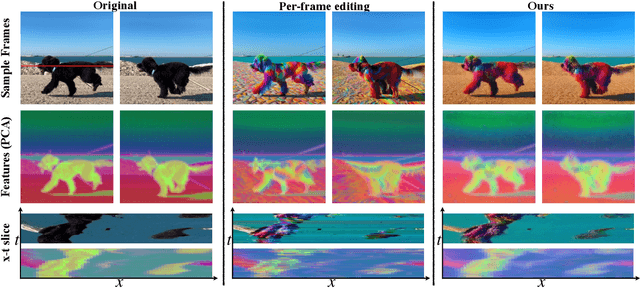

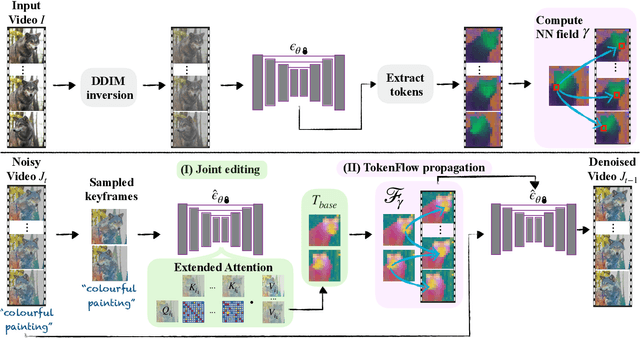
The generative AI revolution has recently expanded to videos. Nevertheless, current state-of-the-art video models are still lagging behind image models in terms of visual quality and user control over the generated content. In this work, we present a framework that harnesses the power of a text-to-image diffusion model for the task of text-driven video editing. Specifically, given a source video and a target text-prompt, our method generates a high-quality video that adheres to the target text, while preserving the spatial layout and motion of the input video. Our method is based on a key observation that consistency in the edited video can be obtained by enforcing consistency in the diffusion feature space. We achieve this by explicitly propagating diffusion features based on inter-frame correspondences, readily available in the model. Thus, our framework does not require any training or fine-tuning, and can work in conjunction with any off-the-shelf text-to-image editing method. We demonstrate state-of-the-art editing results on a variety of real-world videos. Webpage: https://diffusion-tokenflow.github.io/
DreamSim: Learning New Dimensions of Human Visual Similarity using Synthetic Data
Jun 26, 2023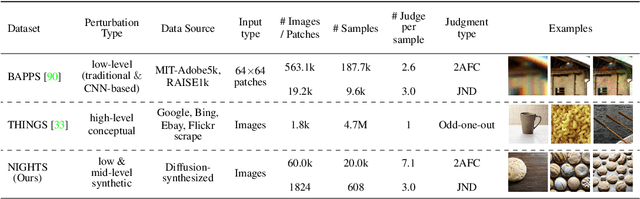
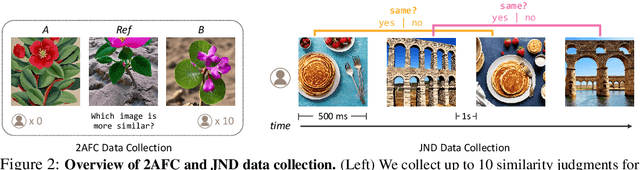
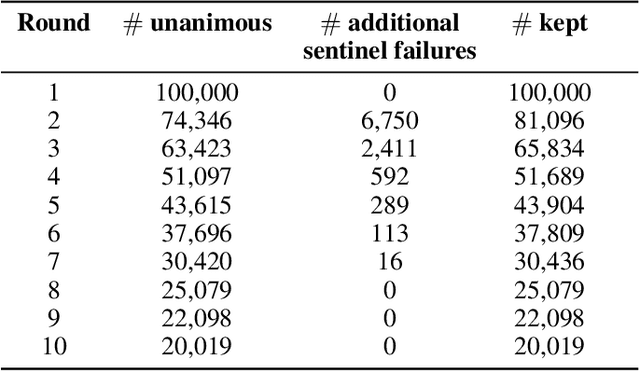
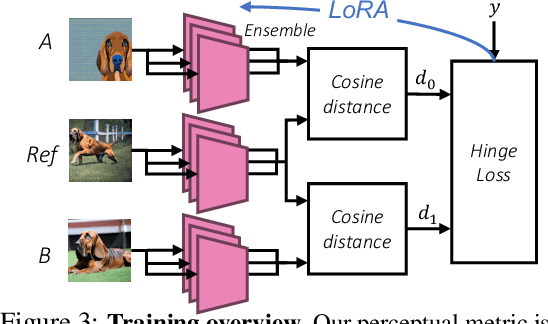
Current perceptual similarity metrics operate at the level of pixels and patches. These metrics compare images in terms of their low-level colors and textures, but fail to capture mid-level similarities and differences in image layout, object pose, and semantic content. In this paper, we develop a perceptual metric that assesses images holistically. Our first step is to collect a new dataset of human similarity judgments over image pairs that are alike in diverse ways. Critical to this dataset is that judgments are nearly automatic and shared by all observers. To achieve this we use recent text-to-image models to create synthetic pairs that are perturbed along various dimensions. We observe that popular perceptual metrics fall short of explaining our new data, and we introduce a new metric, DreamSim, tuned to better align with human perception. We analyze how our metric is affected by different visual attributes, and find that it focuses heavily on foreground objects and semantic content while also being sensitive to color and layout. Notably, despite being trained on synthetic data, our metric generalizes to real images, giving strong results on retrieval and reconstruction tasks. Furthermore, our metric outperforms both prior learned metrics and recent large vision models on these tasks.
Teaching CLIP to Count to Ten
Feb 23, 2023

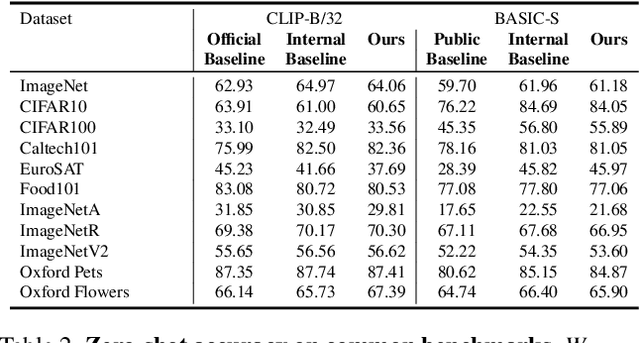

Large vision-language models (VLMs), such as CLIP, learn rich joint image-text representations, facilitating advances in numerous downstream tasks, including zero-shot classification and text-to-image generation. Nevertheless, existing VLMs exhibit a prominent well-documented limitation - they fail to encapsulate compositional concepts such as counting. We introduce a simple yet effective method to improve the quantitative understanding of VLMs, while maintaining their overall performance on common benchmarks. Specifically, we propose a new counting-contrastive loss used to finetune a pre-trained VLM in tandem with its original objective. Our counting loss is deployed over automatically-created counterfactual examples, each consisting of an image and a caption containing an incorrect object count. For example, an image depicting three dogs is paired with the caption "Six dogs playing in the yard". Our loss encourages discrimination between the correct caption and its counterfactual variant which serves as a hard negative example. To the best of our knowledge, this work is the first to extend CLIP's capabilities to object counting. Furthermore, we introduce "CountBench" - a new image-text counting benchmark for evaluating a model's understanding of object counting. We demonstrate a significant improvement over state-of-the-art baseline models on this task. Finally, we leverage our count-aware CLIP model for image retrieval and text-conditioned image generation, demonstrating that our model can produce specific counts of objects more reliably than existing ones.
MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation
Feb 16, 2023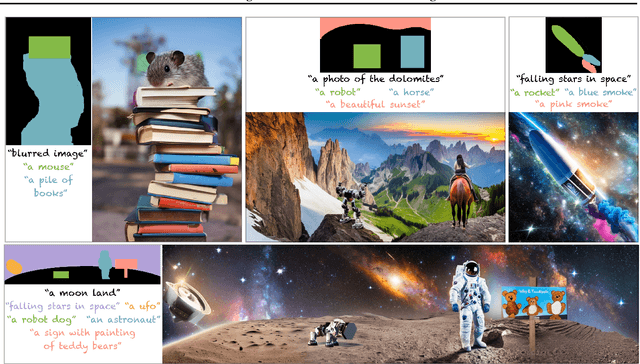
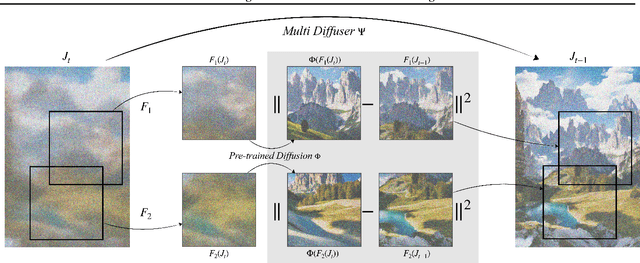


Recent advances in text-to-image generation with diffusion models present transformative capabilities in image quality. However, user controllability of the generated image, and fast adaptation to new tasks still remains an open challenge, currently mostly addressed by costly and long re-training and fine-tuning or ad-hoc adaptations to specific image generation tasks. In this work, we present MultiDiffusion, a unified framework that enables versatile and controllable image generation, using a pre-trained text-to-image diffusion model, without any further training or finetuning. At the center of our approach is a new generation process, based on an optimization task that binds together multiple diffusion generation processes with a shared set of parameters or constraints. We show that MultiDiffusion can be readily applied to generate high quality and diverse images that adhere to user-provided controls, such as desired aspect ratio (e.g., panorama), and spatial guiding signals, ranging from tight segmentation masks to bounding boxes. Project webpage: https://multidiffusion.github.io
Neural Congealing: Aligning Images to a Joint Semantic Atlas
Feb 08, 2023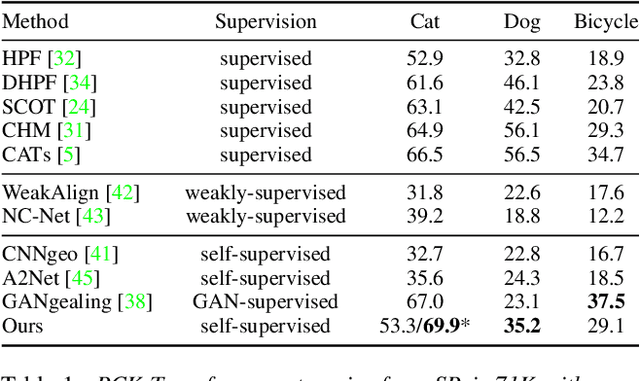
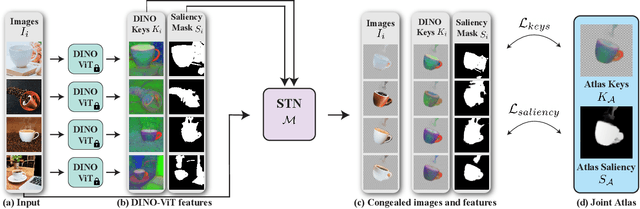

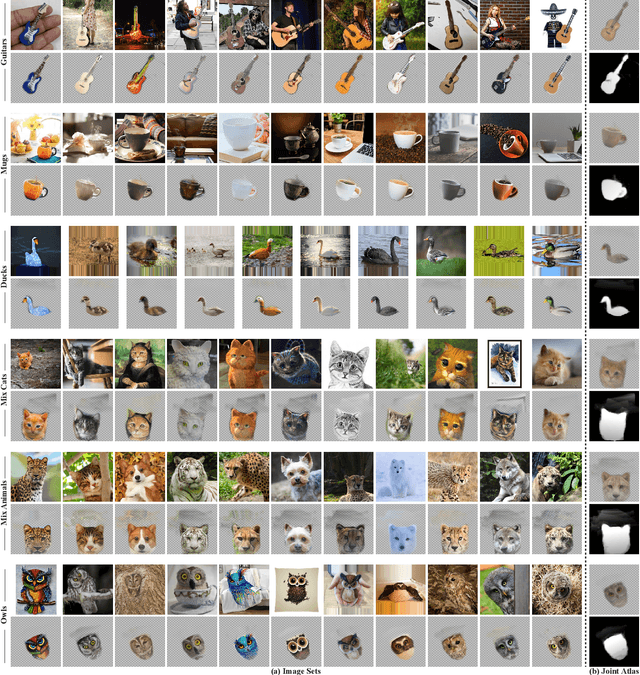
We present Neural Congealing -- a zero-shot self-supervised framework for detecting and jointly aligning semantically-common content across a given set of images. Our approach harnesses the power of pre-trained DINO-ViT features to learn: (i) a joint semantic atlas -- a 2D grid that captures the mode of DINO-ViT features in the input set, and (ii) dense mappings from the unified atlas to each of the input images. We derive a new robust self-supervised framework that optimizes the atlas representation and mappings per image set, requiring only a few real-world images as input without any additional input information (e.g., segmentation masks). Notably, we design our losses and training paradigm to account only for the shared content under severe variations in appearance, pose, background clutter or other distracting objects. We demonstrate results on a plethora of challenging image sets including sets of mixed domains (e.g., aligning images depicting sculpture and artwork of cats), sets depicting related yet different object categories (e.g., dogs and tigers), or domains for which large-scale training data is scarce (e.g., coffee mugs). We thoroughly evaluate our method and show that our test-time optimization approach performs favorably compared to a state-of-the-art method that requires extensive training on large-scale datasets.