 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharles Herrmann
DreamWalk: Style Space Exploration using Diffusion Guidance
Apr 04, 2024
Text-conditioned diffusion models can generate impressive images, but fall short when it comes to fine-grained control. Unlike direct-editing tools like Photoshop, text conditioned models require the artist to perform "prompt engineering," constructing special text sentences to control the style or amount of a particular subject present in the output image. Our goal is to provide fine-grained control over the style and substance specified by the prompt, for example to adjust the intensity of styles in different regions of the image (Figure 1). Our approach is to decompose the text prompt into conceptual elements, and apply a separate guidance term for each element in a single diffusion process. We introduce guidance scale functions to control when in the diffusion process and \emph{where} in the image to intervene. Since the method is based solely on adjusting diffusion guidance, it does not require fine-tuning or manipulating the internal layers of the diffusion model's neural network, and can be used in conjunction with LoRA- or DreamBooth-trained models (Figure2). Project page: https://mshu1.github.io/dreamwalk.github.io/
Lumiere: A Space-Time Diffusion Model for Video Generation
Feb 05, 2024We introduce Lumiere -- a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse and coherent motion -- a pivotal challenge in video synthesis. To this end, we introduce a Space-Time U-Net architecture that generates the entire temporal duration of the video at once, through a single pass in the model. This is in contrast to existing video models which synthesize distant keyframes followed by temporal super-resolution -- an approach that inherently makes global temporal consistency difficult to achieve. By deploying both spatial and (importantly) temporal down- and up-sampling and leveraging a pre-trained text-to-image diffusion model, our model learns to directly generate a full-frame-rate, low-resolution video by processing it in multiple space-time scales. We demonstrate state-of-the-art text-to-video generation results, and show that our design easily facilitates a wide range of content creation tasks and video editing applications, including image-to-video, video inpainting, and stylized generation.
Efficient Hybrid Zoom using Camera Fusion on Mobile Phones
Jan 02, 2024DSLR cameras can achieve multiple zoom levels via shifting lens distances or swapping lens types. However, these techniques are not possible on smartphone devices due to space constraints. Most smartphone manufacturers adopt a hybrid zoom system: commonly a Wide (W) camera at a low zoom level and a Telephoto (T) camera at a high zoom level. To simulate zoom levels between W and T, these systems crop and digitally upsample images from W, leading to significant detail loss. In this paper, we propose an efficient system for hybrid zoom super-resolution on mobile devices, which captures a synchronous pair of W and T shots and leverages machine learning models to align and transfer details from T to W. We further develop an adaptive blending method that accounts for depth-of-field mismatches, scene occlusion, flow uncertainty, and alignment errors. To minimize the domain gap, we design a dual-phone camera rig to capture real-world inputs and ground-truths for supervised training. Our method generates a 12-megapixel image in 500ms on a mobile platform and compares favorably against state-of-the-art methods under extensive evaluation on real-world scenarios.
Boundary Attention: Learning to Find Faint Boundaries at Any Resolution
Jan 01, 2024We present a differentiable model that explicitly models boundaries -- including contours, corners and junctions -- using a new mechanism that we call boundary attention. We show that our model provides accurate results even when the boundary signal is very weak or is swamped by noise. Compared to previous classical methods for finding faint boundaries, our model has the advantages of being differentiable; being scalable to larger images; and automatically adapting to an appropriate level of geometric detail in each part of an image. Compared to previous deep methods for finding boundaries via end-to-end training, it has the advantages of providing sub-pixel precision, being more resilient to noise, and being able to process any image at its native resolution and aspect ratio.
Zero-Shot Metric Depth with a Field-of-View Conditioned Diffusion Model
Dec 20, 2023While methods for monocular depth estimation have made significant strides on standard benchmarks, zero-shot metric depth estimation remains unsolved. Challenges include the joint modeling of indoor and outdoor scenes, which often exhibit significantly different distributions of RGB and depth, and the depth-scale ambiguity due to unknown camera intrinsics. Recent work has proposed specialized multi-head architectures for jointly modeling indoor and outdoor scenes. In contrast, we advocate a generic, task-agnostic diffusion model, with several advancements such as log-scale depth parameterization to enable joint modeling of indoor and outdoor scenes, conditioning on the field-of-view (FOV) to handle scale ambiguity and synthetically augmenting FOV during training to generalize beyond the limited camera intrinsics in training datasets. Furthermore, by employing a more diverse training mixture than is common, and an efficient diffusion parameterization, our method, DMD (Diffusion for Metric Depth) achieves a 25\% reduction in relative error (REL) on zero-shot indoor and 33\% reduction on zero-shot outdoor datasets over the current SOTA using only a small number of denoising steps. For an overview see https://diffusion-vision.github.io/dmd
WonderJourney: Going from Anywhere to Everywhere
Dec 06, 2023We introduce WonderJourney, a modularized framework for perpetual 3D scene generation. Unlike prior work on view generation that focuses on a single type of scenes, we start at any user-provided location (by a text description or an image) and generate a journey through a long sequence of diverse yet coherently connected 3D scenes. We leverage an LLM to generate textual descriptions of the scenes in this journey, a text-driven point cloud generation pipeline to make a compelling and coherent sequence of 3D scenes, and a large VLM to verify the generated scenes. We show compelling, diverse visual results across various scene types and styles, forming imaginary "wonderjourneys". Project website: https://kovenyu.com/WonderJourney/
DreamSync: Aligning Text-to-Image Generation with Image Understanding Feedback
Nov 29, 2023Despite their wide-spread success, Text-to-Image models (T2I) still struggle to produce images that are both aesthetically pleasing and faithful to the user's input text. We introduce DreamSync, a model-agnostic training algorithm by design that improves T2I models to be faithful to the text input. DreamSync builds off a recent insight from TIFA's evaluation framework -- that large vision-language models (VLMs) can effectively identify the fine-grained discrepancies between generated images and the text inputs. DreamSync uses this insight to train T2I models without any labeled data; it improves T2I models using its own generations. First, it prompts the model to generate several candidate images for a given input text. Then, it uses two VLMs to select the best generation: a Visual Question Answering model that measures the alignment of generated images to the text, and another that measures the generation's aesthetic quality. After selection, we use LoRA to iteratively finetune the T2I model to guide its generation towards the selected best generations. DreamSync does not need any additional human annotation. model architecture changes, or reinforcement learning. Despite its simplicity, DreamSync improves both the semantic alignment and aesthetic appeal of two diffusion-based T2I models, evidenced by multiple benchmarks (+1.7% on TIFA, +2.9% on DSG1K, +3.4% on VILA aesthetic) and human evaluation.
Telling Left from Right: Identifying Geometry-Aware Semantic Correspondence
Nov 28, 2023While pre-trained large-scale vision models have shown significant promise for semantic correspondence, their features often struggle to grasp the geometry and orientation of instances. This paper identifies the importance of being geometry-aware for semantic correspondence and reveals a limitation of the features of current foundation models under simple post-processing. We show that incorporating this information can markedly enhance semantic correspondence performance with simple but effective solutions in both zero-shot and supervised settings. We also construct a new challenging benchmark for semantic correspondence built from an existing animal pose estimation dataset, for both pre-training validating models. Our method achieves a PCK@0.10 score of 64.2 (zero-shot) and 85.6 (supervised) on the challenging SPair-71k dataset, outperforming the state-of-the-art by 4.3p and 11.0p absolute gains, respectively. Our code and datasets will be publicly available.
ZeroNVS: Zero-Shot 360-Degree View Synthesis from a Single Real Image
Oct 27, 2023We introduce a 3D-aware diffusion model, ZeroNVS, for single-image novel view synthesis for in-the-wild scenes. While existing methods are designed for single objects with masked backgrounds, we propose new techniques to address challenges introduced by in-the-wild multi-object scenes with complex backgrounds. Specifically, we train a generative prior on a mixture of data sources that capture object-centric, indoor, and outdoor scenes. To address issues from data mixture such as depth-scale ambiguity, we propose a novel camera conditioning parameterization and normalization scheme. Further, we observe that Score Distillation Sampling (SDS) tends to truncate the distribution of complex backgrounds during distillation of 360-degree scenes, and propose "SDS anchoring" to improve the diversity of synthesized novel views. Our model sets a new state-of-the-art result in LPIPS on the DTU dataset in the zero-shot setting, even outperforming methods specifically trained on DTU. We further adapt the challenging Mip-NeRF 360 dataset as a new benchmark for single-image novel view synthesis, and demonstrate strong performance in this setting. Our code and data are at http://kylesargent.github.io/zeronvs/
Substance or Style: What Does Your Image Embedding Know?
Jul 10, 2023
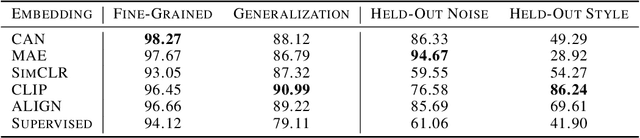

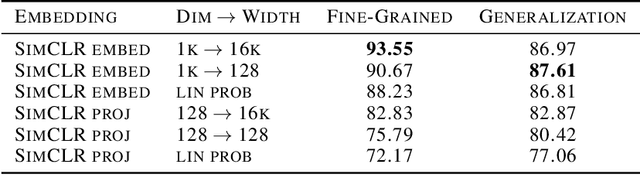
Probes are small networks that predict properties of underlying data from embeddings, and they provide a targeted, effective way to illuminate the information contained in embeddings. While analysis through the use of probes has become standard in NLP, there has been much less exploration in vision. Image foundation models have primarily been evaluated for semantic content. Better understanding the non-semantic information in popular embeddings (e.g., MAE, SimCLR, or CLIP) will shed new light both on the training algorithms and on the uses for these foundation models. We design a systematic transformation prediction task and measure the visual content of embeddings along many axes, including image style, quality, and a range of natural and artificial transformations. Surprisingly, six embeddings (including SimCLR) encode enough non-semantic information to identify dozens of transformations. We also consider a generalization task, where we group similar transformations and hold out several for testing. We find that image-text models (CLIP and ALIGN) are better at recognizing new examples of style transfer than masking-based models (CAN and MAE). Overall, our results suggest that the choice of pre-training algorithm impacts the types of information in the embedding, and certain models are better than others for non-semantic downstream tasks.