 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoyi Rassin
DreamSync: Aligning Text-to-Image Generation with Image Understanding Feedback
Nov 29, 2023
Despite their wide-spread success, Text-to-Image models (T2I) still struggle to produce images that are both aesthetically pleasing and faithful to the user's input text. We introduce DreamSync, a model-agnostic training algorithm by design that improves T2I models to be faithful to the text input. DreamSync builds off a recent insight from TIFA's evaluation framework -- that large vision-language models (VLMs) can effectively identify the fine-grained discrepancies between generated images and the text inputs. DreamSync uses this insight to train T2I models without any labeled data; it improves T2I models using its own generations. First, it prompts the model to generate several candidate images for a given input text. Then, it uses two VLMs to select the best generation: a Visual Question Answering model that measures the alignment of generated images to the text, and another that measures the generation's aesthetic quality. After selection, we use LoRA to iteratively finetune the T2I model to guide its generation towards the selected best generations. DreamSync does not need any additional human annotation. model architecture changes, or reinforcement learning. Despite its simplicity, DreamSync improves both the semantic alignment and aesthetic appeal of two diffusion-based T2I models, evidenced by multiple benchmarks (+1.7% on TIFA, +2.9% on DSG1K, +3.4% on VILA aesthetic) and human evaluation.
Linguistic Binding in Diffusion Models: Enhancing Attribute Correspondence through Attention Map Alignment
Jun 15, 2023
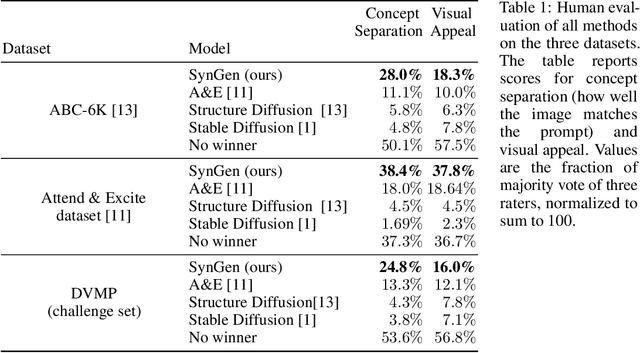
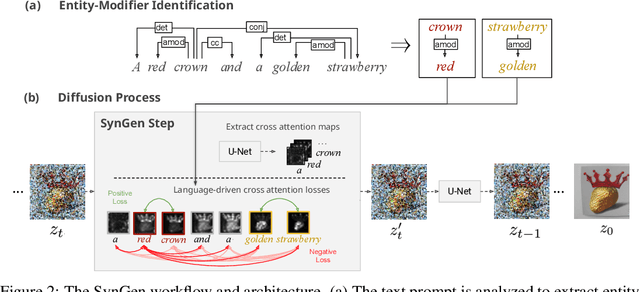
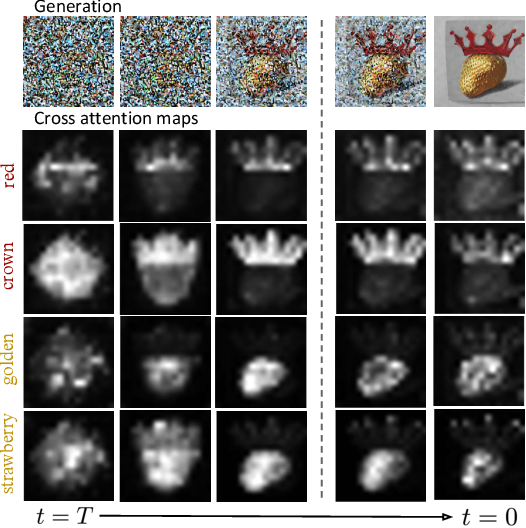
Text-conditioned image generation models often generate incorrect associations between entities and their visual attributes. This reflects an impaired mapping between linguistic binding of entities and modifiers in the prompt and visual binding of the corresponding elements in the generated image. As one notable example, a query like ``a pink sunflower and a yellow flamingo'' may incorrectly produce an image of a yellow sunflower and a pink flamingo. To remedy this issue, we propose SynGen, an approach which first syntactically analyses the prompt to identify entities and their modifiers, and then uses a novel loss function that encourages the cross-attention maps to agree with the linguistic binding reflected by the syntax. Specifically, we encourage large overlap between attention maps of entities and their modifiers, and small overlap with other entities and modifier words. The loss is optimized during inference, without retraining or fine-tuning the model. Human evaluation on three datasets, including one new and challenging set, demonstrate significant improvements of SynGen compared with current state of the art methods. This work highlights how making use of sentence structure during inference can efficiently and substantially improve the faithfulness of text-to-image generation.
Conjunct Resolution in the Face of Verbal Omissions
May 26, 2023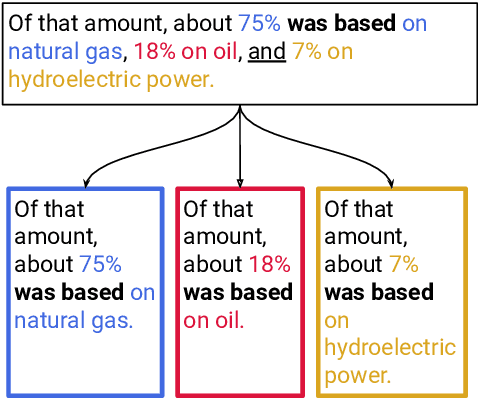
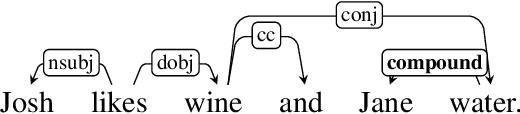

Verbal omissions are complex syntactic phenomena in VP coordination structures. They occur when verbs and (some of) their arguments are omitted from subsequent clauses after being explicitly stated in an initial clause. Recovering these omitted elements is necessary for accurate interpretation of the sentence, and while humans easily and intuitively fill in the missing information, state-of-the-art models continue to struggle with this task. Previous work is limited to small-scale datasets, synthetic data creation methods, and to resolution methods in the dependency-graph level. In this work we propose a conjunct resolution task that operates directly on the text and makes use of a split-and-rephrase paradigm in order to recover the missing elements in the coordination structure. To this end, we first formulate a pragmatic framework of verbal omissions which describes the different types of omissions, and develop an automatic scalable collection method. Based on this method, we curate a large dataset, containing over 10K examples of naturally-occurring verbal omissions with crowd-sourced annotations of the resolved conjuncts. We train various neural baselines for this task, and show that while our best method obtains decent performance, it leaves ample space for improvement. We propose our dataset, metrics and models as a starting point for future research on this topic.
DALLE-2 is Seeing Double: Flaws in Word-to-Concept Mapping in Text2Image Models
Oct 19, 2022
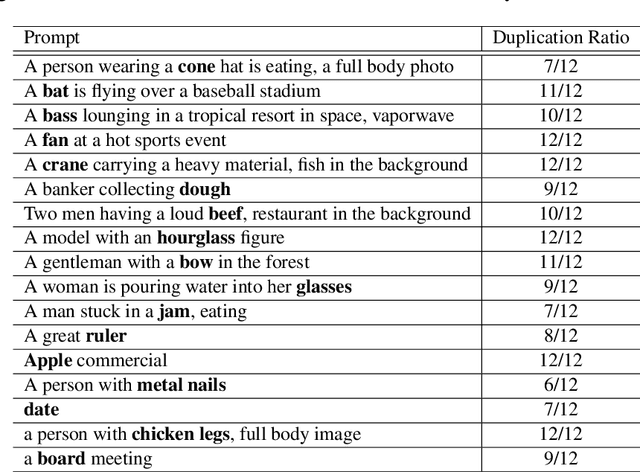

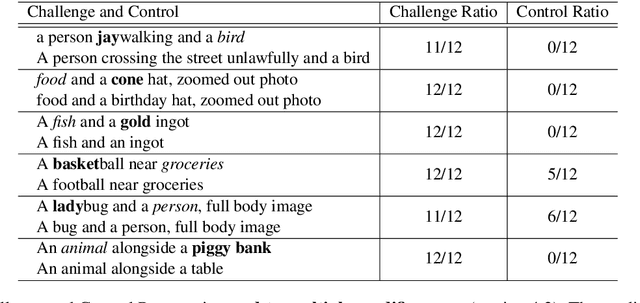
We study the way DALLE-2 maps symbols (words) in the prompt to their references (entities or properties of entities in the generated image). We show that in stark contrast to the way human process language, DALLE-2 does not follow the constraint that each word has a single role in the interpretation, and sometimes re-use the same symbol for different purposes. We collect a set of stimuli that reflect the phenomenon: we show that DALLE-2 depicts both senses of nouns with multiple senses at once; and that a given word can modify the properties of two distinct entities in the image, or can be depicted as one object and also modify the properties of another object, creating a semantic leakage of properties between entities. Taken together, our study highlights the differences between DALLE-2 and human language processing and opens an avenue for future study on the inductive biases of text-to-image models.