 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAimin Zhou
Inductive Cognitive Diagnosis for Fast Student Learning in Web-Based Online Intelligent Education Systems
Apr 17, 2024
Cognitive diagnosis aims to gauge students' mastery levels based on their response logs. Serving as a pivotal module in web-based online intelligent education systems (WOIESs), it plays an upstream and fundamental role in downstream tasks like learning item recommendation and computerized adaptive testing. WOIESs are open learning environment where numerous new students constantly register and complete exercises. In WOIESs, efficient cognitive diagnosis is crucial to fast feedback and accelerating student learning. However, the existing cognitive diagnosis methods always employ intrinsically transductive student-specific embeddings, which become slow and costly due to retraining when dealing with new students who are unseen during training. To this end, this paper proposes an inductive cognitive diagnosis model (ICDM) for fast new students' mastery levels inference in WOIESs. Specifically, in ICDM, we propose a novel student-centered graph (SCG). Rather than inferring mastery levels through updating student-specific embedding, we derive the inductive mastery levels as the aggregated outcomes of students' neighbors in SCG. Namely, SCG enables to shift the task from finding the most suitable student-specific embedding that fits the response logs to finding the most suitable representations for different node types in SCG, and the latter is more efficient since it no longer requires retraining. To obtain this representation, ICDM consists of a construction-aggregation-generation-transformation process to learn the final representation of students, exercises and concepts. Extensive experiments across real-world datasets show that, compared with the existing cognitive diagnosis methods that are always transductive, ICDM is much more faster while maintains the competitive inference performance for new students.
Emotion Neural Transducer for Fine-Grained Speech Emotion Recognition
Mar 28, 2024



The mainstream paradigm of speech emotion recognition (SER) is identifying the single emotion label of the entire utterance. This line of works neglect the emotion dynamics at fine temporal granularity and mostly fail to leverage linguistic information of speech signal explicitly. In this paper, we propose Emotion Neural Transducer for fine-grained speech emotion recognition with automatic speech recognition (ASR) joint training. We first extend typical neural transducer with emotion joint network to construct emotion lattice for fine-grained SER. Then we propose lattice max pooling on the alignment lattice to facilitate distinguishing emotional and non-emotional frames. To adapt fine-grained SER to transducer inference manner, we further make blank, the special symbol of ASR, serve as underlying emotion indicator as well, yielding Factorized Emotion Neural Transducer. For typical utterance-level SER, our ENT models outperform state-of-the-art methods on IEMOCAP in low word error rate. Experiments on IEMOCAP and the latest speech emotion diarization dataset ZED also demonstrate the superiority of fine-grained emotion modeling. Our code is available at https://github.com/ECNU-Cross-Innovation-Lab/ENT.
Model Uncertainty in Evolutionary Optimization and Bayesian Optimization: A Comparative Analysis
Mar 22, 2024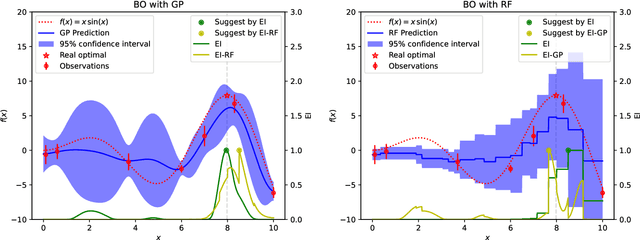
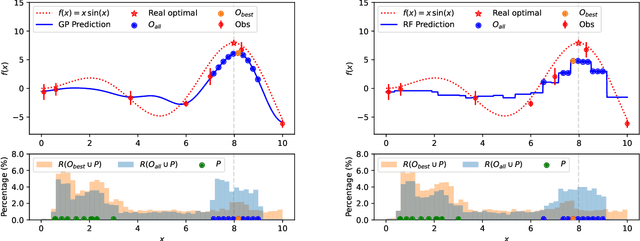
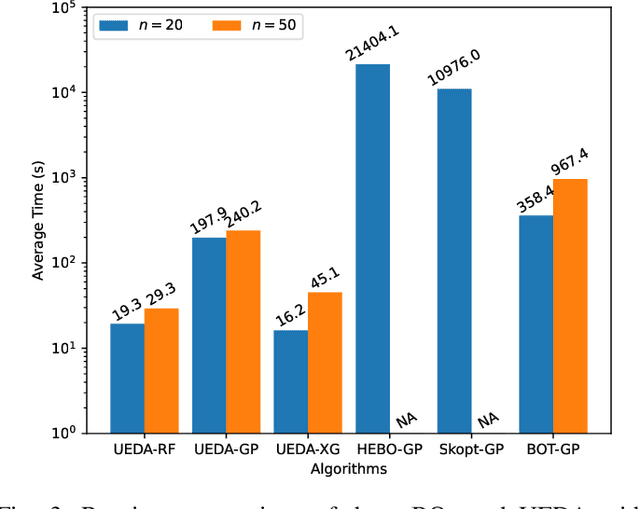
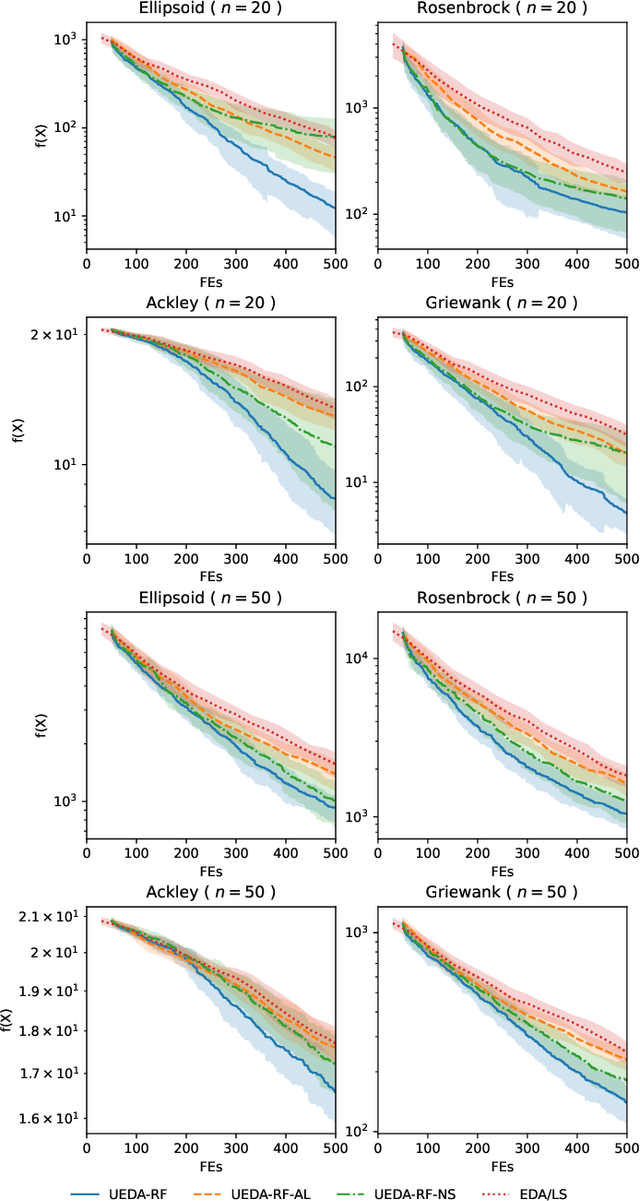
Black-box optimization problems, which are common in many real-world applications, require optimization through input-output interactions without access to internal workings. This often leads to significant computational resources being consumed for simulations. Bayesian Optimization (BO) and Surrogate-Assisted Evolutionary Algorithm (SAEA) are two widely used gradient-free optimization techniques employed to address such challenges. Both approaches follow a similar iterative procedure that relies on surrogate models to guide the search process. This paper aims to elucidate the similarities and differences in the utilization of model uncertainty between these two methods, as well as the impact of model inaccuracies on algorithmic performance. A novel model-assisted strategy is introduced, which utilizes unevaluated solutions to generate offspring, leveraging the population-based search capabilities of evolutionary algorithm to enhance the effectiveness of model-assisted optimization. Experimental results demonstrate that the proposed approach outperforms mainstream Bayesian optimization algorithms in terms of accuracy and efficiency.
Enhancing Depression-Diagnosis-Oriented Chat with Psychological State Tracking
Mar 12, 2024



Depression-diagnosis-oriented chat aims to guide patients in self-expression to collect key symptoms for depression detection. Recent work focuses on combining task-oriented dialogue and chitchat to simulate the interview-based depression diagnosis. Whereas, these methods can not well capture the changing information, feelings, or symptoms of the patient during dialogues. Moreover, no explicit framework has been explored to guide the dialogue, which results in some useless communications that affect the experience. In this paper, we propose to integrate Psychological State Tracking (POST) within the large language model (LLM) to explicitly guide depression-diagnosis-oriented chat. Specifically, the state is adapted from a psychological theoretical model, which consists of four components, namely Stage, Information, Summary and Next. We fine-tune an LLM model to generate the dynamic psychological state, which is further used to assist response generation at each turn to simulate the psychiatrist. Experimental results on the existing benchmark show that our proposed method boosts the performance of all subtasks in depression-diagnosis-oriented chat.
Wasserstein Differential Privacy
Jan 23, 2024Differential privacy (DP) has achieved remarkable results in the field of privacy-preserving machine learning. However, existing DP frameworks do not satisfy all the conditions for becoming metrics, which prevents them from deriving better basic private properties and leads to exaggerated values on privacy budgets. We propose Wasserstein differential privacy (WDP), an alternative DP framework to measure the risk of privacy leakage, which satisfies the properties of symmetry and triangle inequality. We show and prove that WDP has 13 excellent properties, which can be theoretical supports for the better performance of WDP than other DP frameworks. In addition, we derive a general privacy accounting method called Wasserstein accountant, which enables WDP to be applied in stochastic gradient descent (SGD) scenarios containing sub-sampling. Experiments on basic mechanisms, compositions and deep learning show that the privacy budgets obtained by Wasserstein accountant are relatively stable and less influenced by order. Moreover, the overestimation on privacy budgets can be effectively alleviated. The code is available at https://github.com/Hifipsysta/WDP.
Mathematical Language Models: A Survey
Dec 14, 2023In recent years, there has been remarkable progress in leveraging Language Models (LMs), encompassing Pre-trained Language Models (PLMs) and Large-scale Language Models (LLMs), within the domain of mathematics. This paper conducts a comprehensive survey of mathematical LMs, systematically categorizing pivotal research endeavors from two distinct perspectives: tasks and methodologies. The landscape reveals a large number of proposed mathematical LLMs, which are further delineated into instruction learning, tool-based methods, fundamental CoT techniques, and advanced CoT methodologies. In addition, our survey entails the compilation of over 60 mathematical datasets, including training datasets, benchmark datasets, and augmented datasets. Addressing the primary challenges and delineating future trajectories within the field of mathematical LMs, this survey is positioned as a valuable resource, poised to facilitate and inspire future innovation among researchers invested in advancing this domain.
Unlearning with Fisher Masking
Oct 09, 2023



Machine unlearning aims to revoke some training data after learning in response to requests from users, model developers, and administrators. Most previous methods are based on direct fine-tuning, which may neither remove data completely nor retain full performances on the remain data. In this work, we find that, by first masking some important parameters before fine-tuning, the performances of unlearning could be significantly improved. We propose a new masking strategy tailored to unlearning based on Fisher information. Experiments on various datasets and network structures show the effectiveness of the method: without any fine-tuning, the proposed Fisher masking could unlearn almost completely while maintaining most of the performance on the remain data. It also exhibits stronger stability compared to other unlearning baselines
Evolutionary Retrosynthetic Route Planning
Oct 08, 2023
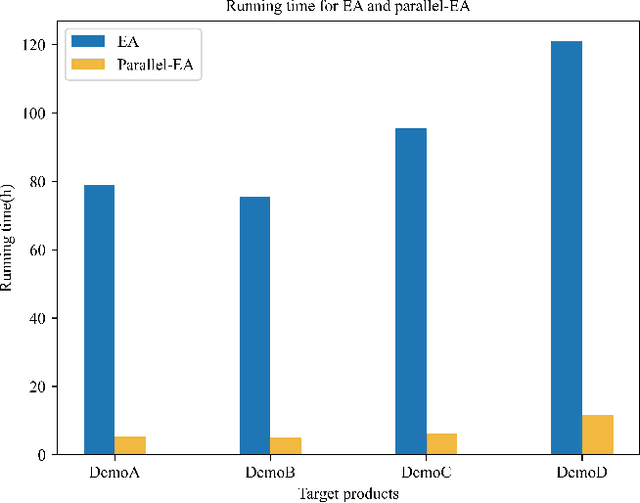
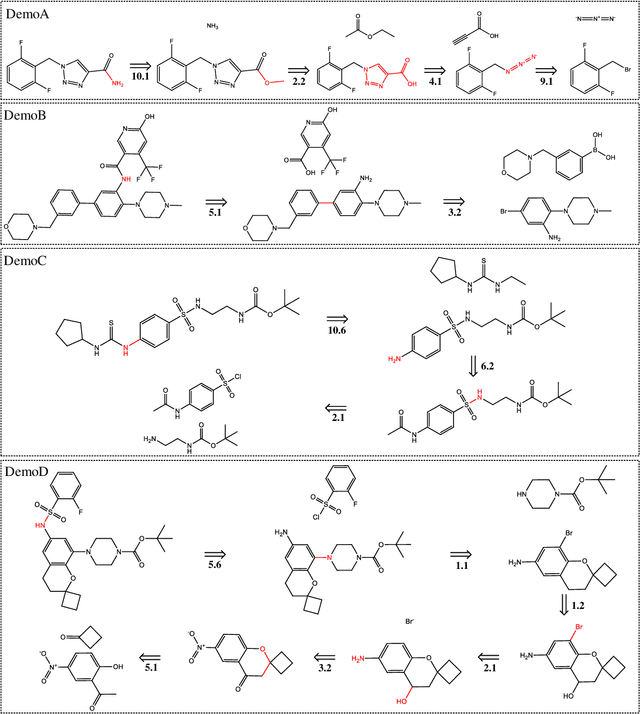

Molecular retrosynthesis is a significant and complex problem in the field of chemistry, however, traditional manual synthesis methods not only need well-trained experts but also are time-consuming. With the development of big data and machine learning, artificial intelligence (AI) based retrosynthesis is attracting more attention and is becoming a valuable tool for molecular retrosynthesis. At present, Monte Carlo tree search is a mainstream search framework employed to address this problem. Nevertheless, its search efficiency is compromised by its large search space. Therefore, we propose a novel approach for retrosynthetic route planning based on evolutionary optimization, marking the first use of Evolutionary Algorithm (EA) in the field of multi-step retrosynthesis. The proposed method involves modeling the retrosynthetic problem into an optimization problem, defining the search space and operators. Additionally, to improve the search efficiency, a parallel strategy is implemented. The new approach is applied to four case products, and is compared with Monte Carlo tree search. The experimental results show that, in comparison to the Monte Carlo tree search algorithm, EA significantly reduces the number of calling single-step model by an average of 53.9%. The time required to search three solutions decreased by an average of 83.9%, and the number of feasible search routes increases by 5 times.
Enhancing SAEAs with Unevaluated Solutions: A Case Study of Relation Model for Expensive Optimization
Sep 21, 2023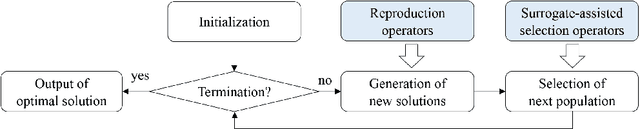

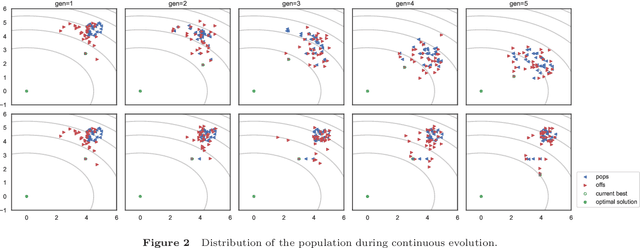
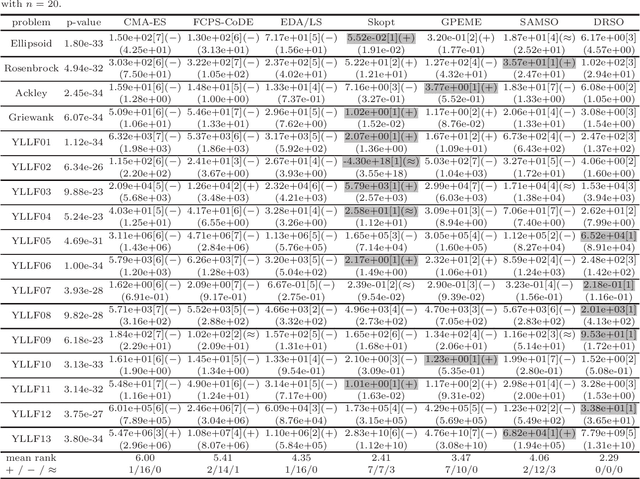
Surrogate-assisted evolutionary algorithms (SAEAs) hold significant importance in resolving expensive optimization problems~(EOPs). Extensive efforts have been devoted to improving the efficacy of SAEAs through the development of proficient model-assisted selection methods. However, generating high-quality solutions is a prerequisite for selection. The fundamental paradigm of evaluating a limited number of solutions in each generation within SAEAs reduces the variance of adjacent populations, thus impacting the quality of offspring solutions. This is a frequently encountered issue, yet it has not gained widespread attention. This paper presents a framework using unevaluated solutions to enhance the efficiency of SAEAs. The surrogate model is employed to identify high-quality solutions for direct generation of new solutions without evaluation. To ensure dependable selection, we have introduced two tailored relation models for the selection of the optimal solution and the unevaluated population. A comprehensive experimental analysis is performed on two test suites, which showcases the superiority of the relation model over regression and classification models in the selection phase. Furthermore, the surrogate-selected unevaluated solutions with high potential have been shown to significantly enhance the efficiency of the algorithm.
EduChat: A Large-Scale Language Model-based Chatbot System for Intelligent Education
Aug 05, 2023
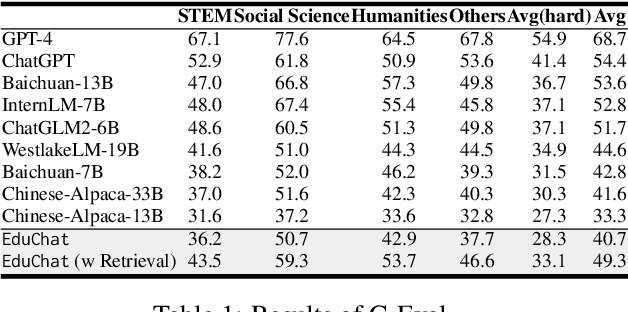
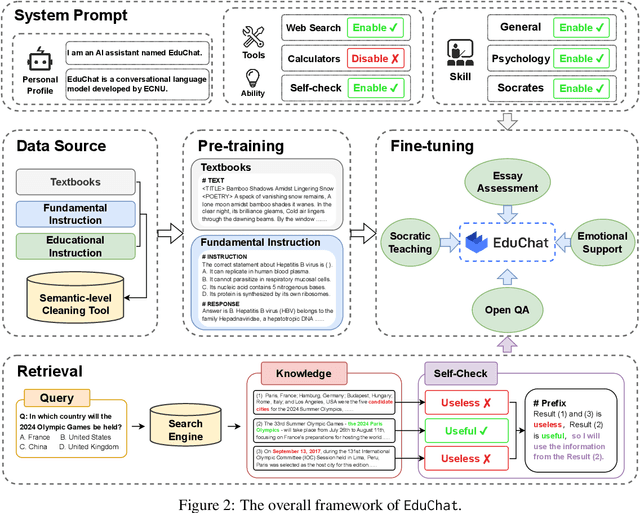

EduChat (https://www.educhat.top/) is a large-scale language model (LLM)-based chatbot system in the education domain. Its goal is to support personalized, fair, and compassionate intelligent education, serving teachers, students, and parents. Guided by theories from psychology and education, it further strengthens educational functions such as open question answering, essay assessment, Socratic teaching, and emotional support based on the existing basic LLMs. Particularly, we learn domain-specific knowledge by pre-training on the educational corpus and stimulate various skills with tool use by fine-tuning on designed system prompts and instructions. Currently, EduChat is available online as an open-source project, with its code, data, and model parameters available on platforms (e.g., GitHub https://github.com/icalk-nlp/EduChat, Hugging Face https://huggingface.co/ecnu-icalk ). We also prepare a demonstration of its capabilities online (https://vimeo.com/851004454). This initiative aims to promote research and applications of LLMs for intelligent education.