 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhen Fang
On the Learnability of Out-of-distribution Detection
Apr 07, 2024


Supervised learning aims to train a classifier under the assumption that training and test data are from the same distribution. To ease the above assumption, researchers have studied a more realistic setting: out-of-distribution (OOD) detection, where test data may come from classes that are unknown during training (i.e., OOD data). Due to the unavailability and diversity of OOD data, good generalization ability is crucial for effective OOD detection algorithms, and corresponding learning theory is still an open problem. To study the generalization of OOD detection, this paper investigates the probably approximately correct (PAC) learning theory of OOD detection that fits the commonly used evaluation metrics in the literature. First, we find a necessary condition for the learnability of OOD detection. Then, using this condition, we prove several impossibility theorems for the learnability of OOD detection under some scenarios. Although the impossibility theorems are frustrating, we find that some conditions of these impossibility theorems may not hold in some practical scenarios. Based on this observation, we next give several necessary and sufficient conditions to characterize the learnability of OOD detection in some practical scenarios. Lastly, we offer theoretical support for representative OOD detection works based on our OOD theory.
Negative Label Guided OOD Detection with Pretrained Vision-Language Models
Mar 29, 2024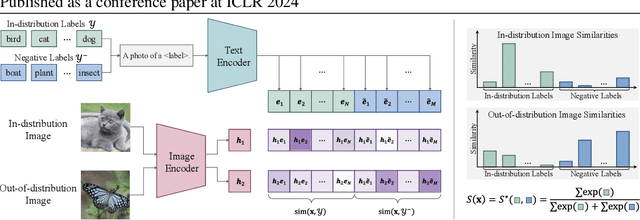
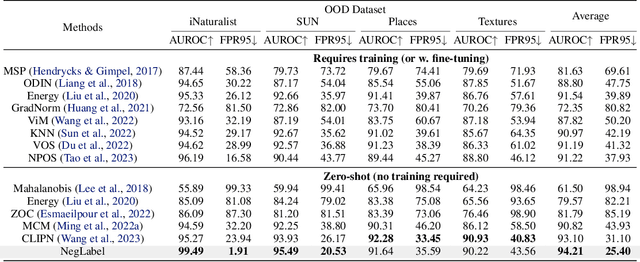

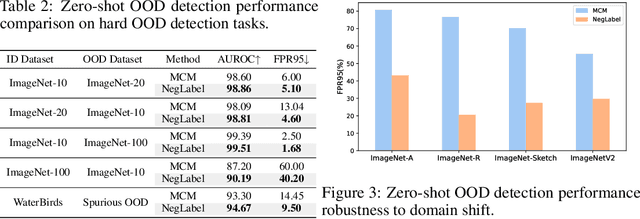
Out-of-distribution (OOD) detection aims at identifying samples from unknown classes, playing a crucial role in trustworthy models against errors on unexpected inputs. Extensive research has been dedicated to exploring OOD detection in the vision modality. Vision-language models (VLMs) can leverage both textual and visual information for various multi-modal applications, whereas few OOD detection methods take into account information from the text modality. In this paper, we propose a novel post hoc OOD detection method, called NegLabel, which takes a vast number of negative labels from extensive corpus databases. We design a novel scheme for the OOD score collaborated with negative labels. Theoretical analysis helps to understand the mechanism of negative labels. Extensive experiments demonstrate that our method NegLabel achieves state-of-the-art performance on various OOD detection benchmarks and generalizes well on multiple VLM architectures. Furthermore, our method NegLabel exhibits remarkable robustness against diverse domain shifts. The codes are available at https://github.com/tmlr-group/NegLabel.
NoiseDiffusion: Correcting Noise for Image Interpolation with Diffusion Models beyond Spherical Linear Interpolation
Mar 13, 2024
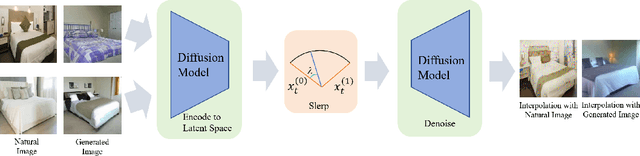


Image interpolation based on diffusion models is promising in creating fresh and interesting images. Advanced interpolation methods mainly focus on spherical linear interpolation, where images are encoded into the noise space and then interpolated for denoising to images. However, existing methods face challenges in effectively interpolating natural images (not generated by diffusion models), thereby restricting their practical applicability. Our experimental investigations reveal that these challenges stem from the invalidity of the encoding noise, which may no longer obey the expected noise distribution, e.g., a normal distribution. To address these challenges, we propose a novel approach to correct noise for image interpolation, NoiseDiffusion. Specifically, NoiseDiffusion approaches the invalid noise to the expected distribution by introducing subtle Gaussian noise and introduces a constraint to suppress noise with extreme values. In this context, promoting noise validity contributes to mitigating image artifacts, but the constraint and introduced exogenous noise typically lead to a reduction in signal-to-noise ratio, i.e., loss of original image information. Hence, NoiseDiffusion performs interpolation within the noisy image space and injects raw images into these noisy counterparts to address the challenge of information loss. Consequently, NoiseDiffusion enables us to interpolate natural images without causing artifacts or information loss, thus achieving the best interpolation results.
ConjNorm: Tractable Density Estimation for Out-of-Distribution Detection
Feb 27, 2024Post-hoc out-of-distribution (OOD) detection has garnered intensive attention in reliable machine learning. Many efforts have been dedicated to deriving score functions based on logits, distances, or rigorous data distribution assumptions to identify low-scoring OOD samples. Nevertheless, these estimate scores may fail to accurately reflect the true data density or impose impractical constraints. To provide a unified perspective on density-based score design, we propose a novel theoretical framework grounded in Bregman divergence, which extends distribution considerations to encompass an exponential family of distributions. Leveraging the conjugation constraint revealed in our theorem, we introduce a \textsc{ConjNorm} method, reframing density function design as a search for the optimal norm coefficient $p$ against the given dataset. In light of the computational challenges of normalization, we devise an unbiased and analytically tractable estimator of the partition function using the Monte Carlo-based importance sampling technique. Extensive experiments across OOD detection benchmarks empirically demonstrate that our proposed \textsc{ConjNorm} has established a new state-of-the-art in a variety of OOD detection setups, outperforming the current best method by up to 13.25$\%$ and 28.19$\%$ (FPR95) on CIFAR-100 and ImageNet-1K, respectively.
How Does Unlabeled Data Provably Help Out-of-Distribution Detection?
Feb 05, 2024Using unlabeled data to regularize the machine learning models has demonstrated promise for improving safety and reliability in detecting out-of-distribution (OOD) data. Harnessing the power of unlabeled in-the-wild data is non-trivial due to the heterogeneity of both in-distribution (ID) and OOD data. This lack of a clean set of OOD samples poses significant challenges in learning an optimal OOD classifier. Currently, there is a lack of research on formally understanding how unlabeled data helps OOD detection. This paper bridges the gap by introducing a new learning framework SAL (Separate And Learn) that offers both strong theoretical guarantees and empirical effectiveness. The framework separates candidate outliers from the unlabeled data and then trains an OOD classifier using the candidate outliers and the labeled ID data. Theoretically, we provide rigorous error bounds from the lens of separability and learnability, formally justifying the two components in our algorithm. Our theory shows that SAL can separate the candidate outliers with small error rates, which leads to a generalization guarantee for the learned OOD classifier. Empirically, SAL achieves state-of-the-art performance on common benchmarks, reinforcing our theoretical insights. Code is publicly available at https://github.com/deeplearning-wisc/sal.
MAG-Edit: Localized Image Editing in Complex Scenarios via Mask-Based Attention-Adjusted Guidance
Dec 21, 2023Recent diffusion-based image editing approaches have exhibited impressive editing capabilities in images with simple compositions. However, localized editing in complex scenarios has not been well-studied in the literature, despite its growing real-world demands. Existing mask-based inpainting methods fall short of retaining the underlying structure within the edit region. Meanwhile, mask-free attention-based methods often exhibit editing leakage and misalignment in more complex compositions. In this work, we develop MAG-Edit, a training-free, inference-stage optimization method, which enables localized image editing in complex scenarios. In particular, MAG-Edit optimizes the noise latent feature in diffusion models by maximizing two mask-based cross-attention constraints of the edit token, which in turn gradually enhances the local alignment with the desired prompt. Extensive quantitative and qualitative experiments demonstrate the effectiveness of our method in achieving both text alignment and structure preservation for localized editing within complex scenarios.
Out-of-distribution Detection Learning with Unreliable Out-of-distribution Sources
Nov 06, 2023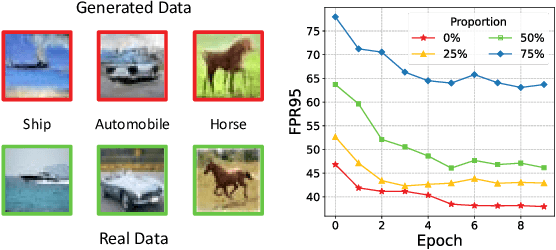
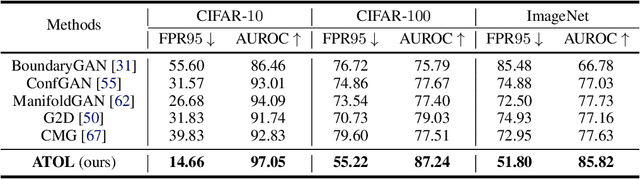
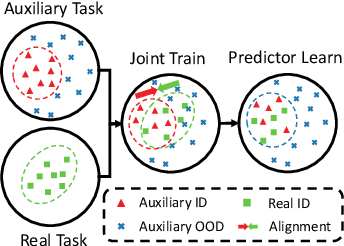

Out-of-distribution (OOD) detection discerns OOD data where the predictor cannot make valid predictions as in-distribution (ID) data, thereby increasing the reliability of open-world classification. However, it is typically hard to collect real out-of-distribution (OOD) data for training a predictor capable of discerning ID and OOD patterns. This obstacle gives rise to data generation-based learning methods, synthesizing OOD data via data generators for predictor training without requiring any real OOD data. Related methods typically pre-train a generator on ID data and adopt various selection procedures to find those data likely to be the OOD cases. However, generated data may still coincide with ID semantics, i.e., mistaken OOD generation remains, confusing the predictor between ID and OOD data. To this end, we suggest that generated data (with mistaken OOD generation) can be used to devise an auxiliary OOD detection task to facilitate real OOD detection. Specifically, we can ensure that learning from such an auxiliary task is beneficial if the ID and the OOD parts have disjoint supports, with the help of a well-designed training procedure for the predictor. Accordingly, we propose a powerful data generation-based learning method named Auxiliary Task-based OOD Learning (ATOL) that can relieve the mistaken OOD generation. We conduct extensive experiments under various OOD detection setups, demonstrating the effectiveness of our method against its advanced counterparts.
Learning to Augment Distributions for Out-of-Distribution Detection
Nov 03, 2023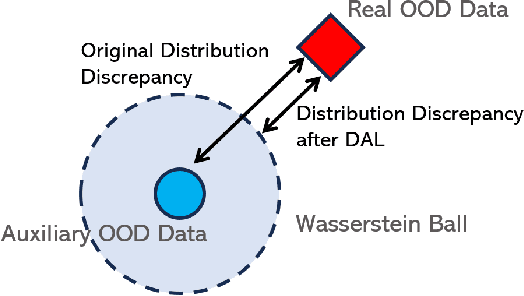
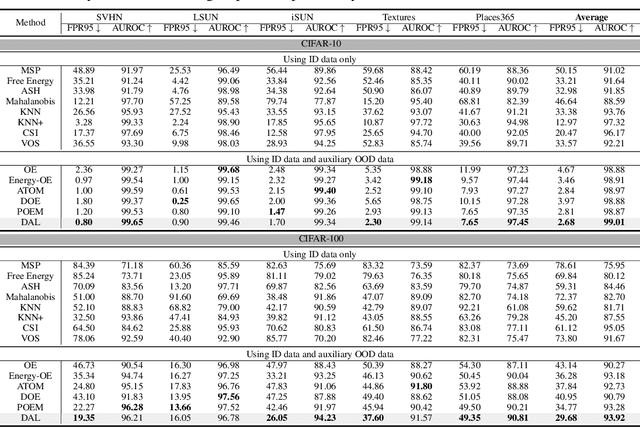
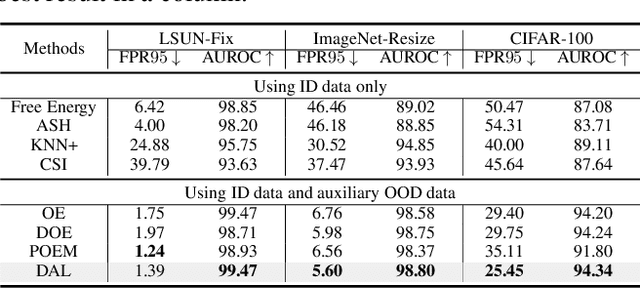

Open-world classification systems should discern out-of-distribution (OOD) data whose labels deviate from those of in-distribution (ID) cases, motivating recent studies in OOD detection. Advanced works, despite their promising progress, may still fail in the open world, owing to the lack of knowledge about unseen OOD data in advance. Although one can access auxiliary OOD data (distinct from unseen ones) for model training, it remains to analyze how such auxiliary data will work in the open world. To this end, we delve into such a problem from a learning theory perspective, finding that the distribution discrepancy between the auxiliary and the unseen real OOD data is the key to affecting the open-world detection performance. Accordingly, we propose Distributional-Augmented OOD Learning (DAL), alleviating the OOD distribution discrepancy by crafting an OOD distribution set that contains all distributions in a Wasserstein ball centered on the auxiliary OOD distribution. We justify that the predictor trained over the worst OOD data in the ball can shrink the OOD distribution discrepancy, thus improving the open-world detection performance given only the auxiliary OOD data. We conduct extensive evaluations across representative OOD detection setups, demonstrating the superiority of our DAL over its advanced counterparts.
Towards Control-Centric Representations in Reinforcement Learning from Images
Oct 27, 2023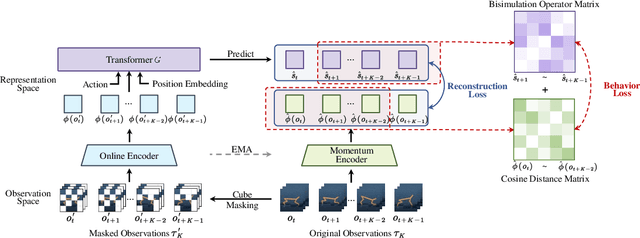
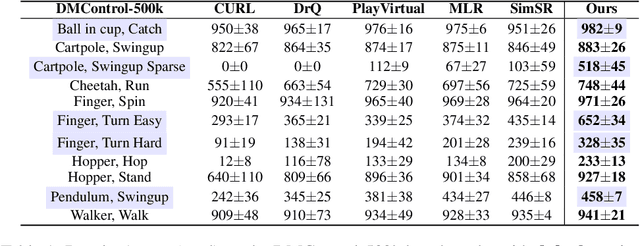

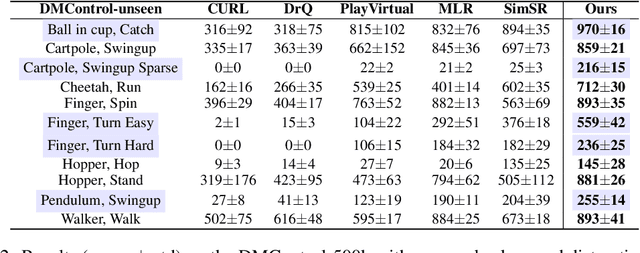
Image-based Reinforcement Learning is a practical yet challenging task. A major hurdle lies in extracting control-centric representations while disregarding irrelevant information. While approaches that follow the bisimulation principle exhibit the potential in learning state representations to address this issue, they still grapple with the limited expressive capacity of latent dynamics and the inadaptability to sparse reward environments. To address these limitations, we introduce ReBis, which aims to capture control-centric information by integrating reward-free control information alongside reward-specific knowledge. ReBis utilizes a transformer architecture to implicitly model the dynamics and incorporates block-wise masking to eliminate spatiotemporal redundancy. Moreover, ReBis combines bisimulation-based loss with asymmetric reconstruction loss to prevent feature collapse in environments with sparse rewards. Empirical studies on two large benchmarks, including Atari games and DeepMind Control Suit, demonstrate that ReBis has superior performance compared to existing methods, proving its effectiveness.
Continual Named Entity Recognition without Catastrophic Forgetting
Oct 23, 2023Continual Named Entity Recognition (CNER) is a burgeoning area, which involves updating an existing model by incorporating new entity types sequentially. Nevertheless, continual learning approaches are often severely afflicted by catastrophic forgetting. This issue is intensified in CNER due to the consolidation of old entity types from previous steps into the non-entity type at each step, leading to what is known as the semantic shift problem of the non-entity type. In this paper, we introduce a pooled feature distillation loss that skillfully navigates the trade-off between retaining knowledge of old entity types and acquiring new ones, thereby more effectively mitigating the problem of catastrophic forgetting. Additionally, we develop a confidence-based pseudo-labeling for the non-entity type, \emph{i.e.,} predicting entity types using the old model to handle the semantic shift of the non-entity type. Following the pseudo-labeling process, we suggest an adaptive re-weighting type-balanced learning strategy to handle the issue of biased type distribution. We carried out comprehensive experiments on ten CNER settings using three different datasets. The results illustrate that our method significantly outperforms prior state-of-the-art approaches, registering an average improvement of $6.3$\% and $8.0$\% in Micro and Macro F1 scores, respectively.