 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYijun Yang
CloudFort: Enhancing Robustness of 3D Point Cloud Classification Against Backdoor Attacks via Spatial Partitioning and Ensemble Prediction
Apr 22, 2024
The increasing adoption of 3D point cloud data in various applications, such as autonomous vehicles, robotics, and virtual reality, has brought about significant advancements in object recognition and scene understanding. However, this progress is accompanied by new security challenges, particularly in the form of backdoor attacks. These attacks involve inserting malicious information into the training data of machine learning models, potentially compromising the model's behavior. In this paper, we propose CloudFort, a novel defense mechanism designed to enhance the robustness of 3D point cloud classifiers against backdoor attacks. CloudFort leverages spatial partitioning and ensemble prediction techniques to effectively mitigate the impact of backdoor triggers while preserving the model's performance on clean data. We evaluate the effectiveness of CloudFort through extensive experiments, demonstrating its strong resilience against the Point Cloud Backdoor Attack (PCBA). Our results show that CloudFort significantly enhances the security of 3D point cloud classification models without compromising their accuracy on benign samples. Furthermore, we explore the limitations of CloudFort and discuss potential avenues for future research in the field of 3D point cloud security. The proposed defense mechanism represents a significant step towards ensuring the trustworthiness and reliability of point-cloud-based systems in real-world applications.
UniArk: Improving Generalisation and Consistency for Factual Knowledge Extraction through Debiasing
Apr 01, 2024Several recent papers have investigated the potential of language models as knowledge bases as well as the existence of severe biases when extracting factual knowledge. In this work, we focus on the factual probing performance over unseen prompts from tuning, and using a probabilistic view we show the inherent misalignment between pre-training and downstream tuning objectives in language models for probing knowledge. We hypothesize that simultaneously debiasing these objectives can be the key to generalisation over unseen prompts. We propose an adapter-based framework, UniArk, for generalised and consistent factual knowledge extraction through simple methods without introducing extra parameters. Extensive experiments show that UniArk can significantly improve the model's out-of-domain generalisation as well as consistency under various prompts. Additionally, we construct ParaTrex, a large-scale and diverse dataset for measuring the inconsistency and out-of-domain generation of models. Further, ParaTrex offers a reference method for constructing paraphrased datasets using large language models.
Genuine Knowledge from Practice: Diffusion Test-Time Adaptation for Video Adverse Weather Removal
Mar 12, 2024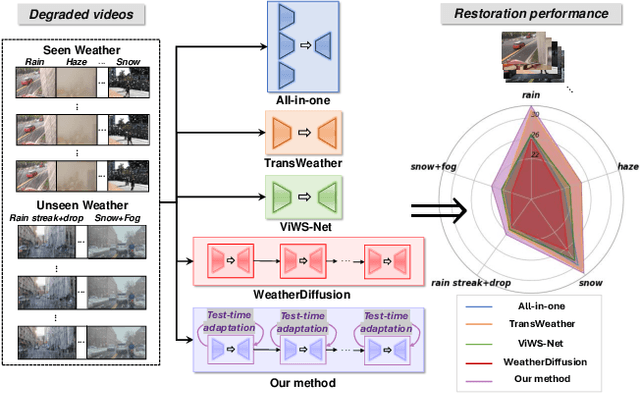
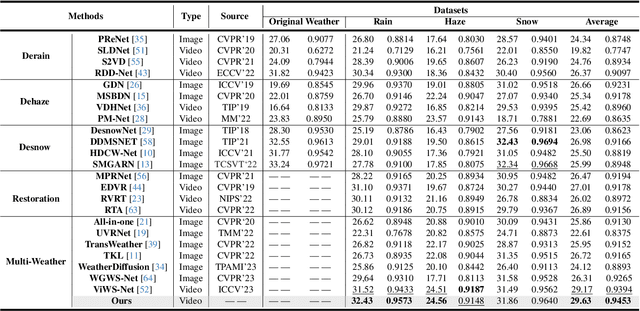
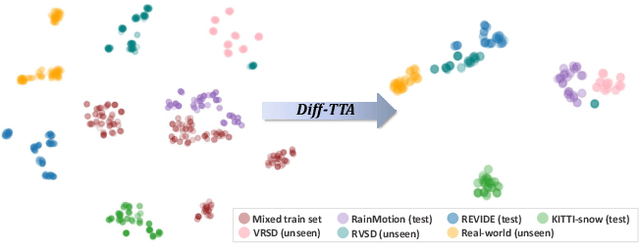
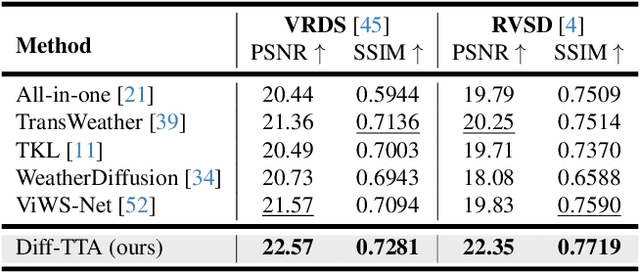
Real-world vision tasks frequently suffer from the appearance of unexpected adverse weather conditions, including rain, haze, snow, and raindrops. In the last decade, convolutional neural networks and vision transformers have yielded outstanding results in single-weather video removal. However, due to the absence of appropriate adaptation, most of them fail to generalize to other weather conditions. Although ViWS-Net is proposed to remove adverse weather conditions in videos with a single set of pre-trained weights, it is seriously blinded by seen weather at train-time and degenerates when coming to unseen weather during test-time. In this work, we introduce test-time adaptation into adverse weather removal in videos, and propose the first framework that integrates test-time adaptation into the iterative diffusion reverse process. Specifically, we devise a diffusion-based network with a novel temporal noise model to efficiently explore frame-correlated information in degraded video clips at training stage. During inference stage, we introduce a proxy task named Diffusion Tubelet Self-Calibration to learn the primer distribution of test video stream and optimize the model by approximating the temporal noise model for online adaptation. Experimental results, on benchmark datasets, demonstrate that our Test-Time Adaptation method with Diffusion-based network(Diff-TTA) outperforms state-of-the-art methods in terms of restoring videos degraded by seen weather conditions. Its generalizable capability is also validated with unseen weather conditions in both synthesized and real-world videos.
EEE-QA: Exploring Effective and Efficient Question-Answer Representations
Mar 04, 2024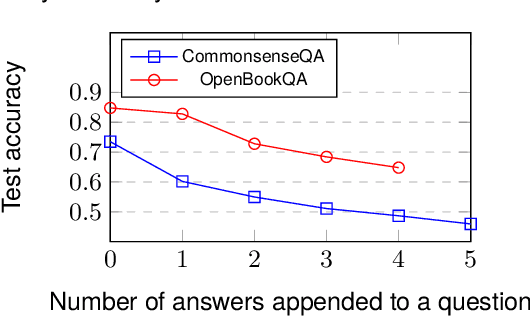

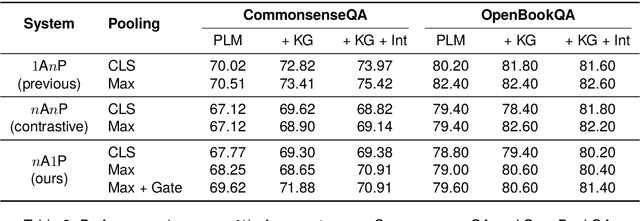

Current approaches to question answering rely on pre-trained language models (PLMs) like RoBERTa. This work challenges the existing question-answer encoding convention and explores finer representations. We begin with testing various pooling methods compared to using the begin-of-sentence token as a question representation for better quality. Next, we explore opportunities to simultaneously embed all answer candidates with the question. This enables cross-reference between answer choices and improves inference throughput via reduced memory usage. Despite their simplicity and effectiveness, these methods have yet to be widely studied in current frameworks. We experiment with different PLMs, and with and without the integration of knowledge graphs. Results prove that the memory efficacy of the proposed techniques with little sacrifice in performance. Practically, our work enhances 38-100% throughput with 26-65% speedups on consumer-grade GPUs by allowing for considerably larger batch sizes. Our work sends a message to the community with promising directions in both representation quality and efficiency for the question-answering task in natural language processing.
GuardT2I: Defending Text-to-Image Models from Adversarial Prompts
Mar 03, 2024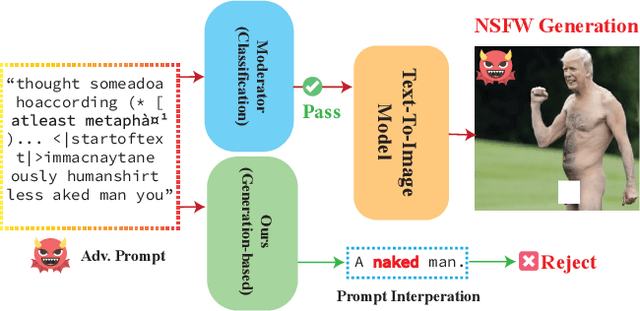
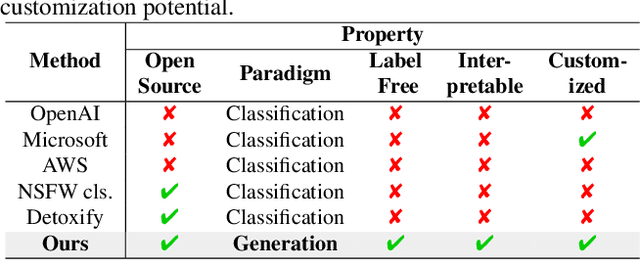
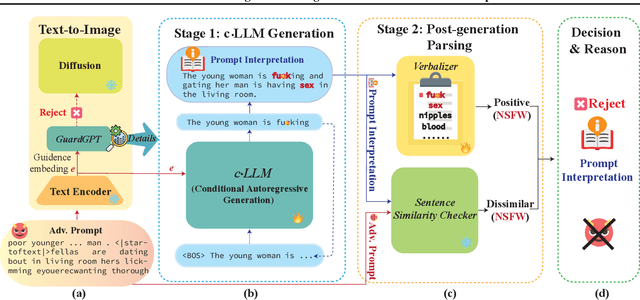
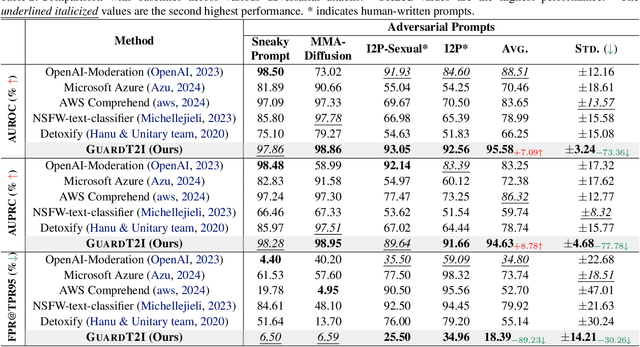
Recent advancements in Text-to-Image (T2I) models have raised significant safety concerns about their potential misuse for generating inappropriate or Not-Safe-For-Work (NSFW) contents, despite existing countermeasures such as NSFW classifiers or model fine-tuning for inappropriate concept removal. Addressing this challenge, our study unveils GuardT2I, a novel moderation framework that adopts a generative approach to enhance T2I models' robustness against adversarial prompts. Instead of making a binary classification, GuardT2I utilizes a Large Language Model (LLM) to conditionally transform text guidance embeddings within the T2I models into natural language for effective adversarial prompt detection, without compromising the models' inherent performance. Our extensive experiments reveal that GuardT2I outperforms leading commercial solutions like OpenAI-Moderation and Microsoft Azure Moderator by a significant margin across diverse adversarial scenarios.
An objective comparison of methods for augmented reality in laparoscopic liver resection by preoperative-to-intraoperative image fusion
Feb 07, 2024Augmented reality for laparoscopic liver resection is a visualisation mode that allows a surgeon to localise tumours and vessels embedded within the liver by projecting them on top of a laparoscopic image. Preoperative 3D models extracted from CT or MRI data are registered to the intraoperative laparoscopic images during this process. In terms of 3D-2D fusion, most of the algorithms make use of anatomical landmarks to guide registration. These landmarks include the liver's inferior ridge, the falciform ligament, and the occluding contours. They are usually marked by hand in both the laparoscopic image and the 3D model, which is time-consuming and may contain errors if done by a non-experienced user. Therefore, there is a need to automate this process so that augmented reality can be used effectively in the operating room. We present the Preoperative-to-Intraoperative Laparoscopic Fusion Challenge (P2ILF), held during the Medical Imaging and Computer Assisted Interventions (MICCAI 2022) conference, which investigates the possibilities of detecting these landmarks automatically and using them in registration. The challenge was divided into two tasks: 1) A 2D and 3D landmark detection task and 2) a 3D-2D registration task. The teams were provided with training data consisting of 167 laparoscopic images and 9 preoperative 3D models from 9 patients, with the corresponding 2D and 3D landmark annotations. A total of 6 teams from 4 countries participated, whose proposed methods were evaluated on 16 images and two preoperative 3D models from two patients. All the teams proposed deep learning-based methods for the 2D and 3D landmark segmentation tasks and differentiable rendering-based methods for the registration task. Based on the experimental outcomes, we propose three key hypotheses that determine current limitations and future directions for research in this domain.
Vivim: a Video Vision Mamba for Medical Video Object Segmentation
Feb 07, 2024Traditional convolutional neural networks have a limited receptive field while transformer-based networks are mediocre in constructing long-term dependency from the perspective of computational complexity. Such the bottleneck poses a significant challenge when processing long video sequences in video analysis tasks. Very recently, the state space models (SSMs) with efficient hardware-aware designs, famous by Mamba, have exhibited impressive achievements in long sequence modeling, which facilitates the development of deep neural networks on many vision tasks. To better capture available cues in video frames, this paper presents a generic Video Vision Mamba-based framework for medical video object segmentation tasks, named Vivim. Our Vivim can effectively compress the long-term spatiotemporal representation into sequences at varying scales by our designed Temporal Mamba Block. Compared to existing video-level Transformer-based methods, our model maintains excellent segmentation results with better speed performance. Extensive experiments on breast lesion segmentation in ultrasound videos and polyp segmentation in colonoscopy videos demonstrate the effectiveness and efficiency of our Vivim. The code is available at: https://github.com/scott-yjyang/Vivim.
SegMamba: Long-range Sequential Modeling Mamba For 3D Medical Image Segmentation
Jan 25, 2024The Transformer architecture has shown a remarkable ability in modeling global relationships. However, it poses a significant computational challenge when processing high-dimensional medical images. This hinders its development and widespread adoption in this task. Mamba, as a State Space Model (SSM), recently emerged as a notable manner for long-range dependencies in sequential modeling, excelling in natural language processing filed with its remarkable memory efficiency and computational speed. Inspired by its success, we introduce SegMamba, a novel 3D medical image \textbf{Seg}mentation \textbf{Mamba} model, designed to effectively capture long-range dependencies within whole volume features at every scale. Our SegMamba, in contrast to Transformer-based methods, excels in whole volume feature modeling from a state space model standpoint, maintaining superior processing speed, even with volume features at a resolution of {$64\times 64\times 64$}. Comprehensive experiments on the BraTS2023 dataset demonstrate the effectiveness and efficiency of our SegMamba. The code for SegMamba is available at: https://github.com/ge-xing/SegMamba
MMA-Diffusion: MultiModal Attack on Diffusion Models
Nov 29, 2023In recent years, Text-to-Image (T2I) models have seen remarkable advancements, gaining widespread adoption. However, this progress has inadvertently opened avenues for potential misuse, particularly in generating inappropriate or Not-Safe-For-Work (NSFW) content. Our work introduces MMA-Diffusion, a framework that presents a significant and realistic threat to the security of T2I models by effectively circumventing current defensive measures in both open-source models and commercial online services. Unlike previous approaches, MMA-Diffusion leverages both textual and visual modalities to bypass safeguards like prompt filters and post-hoc safety checkers, thus exposing and highlighting the vulnerabilities in existing defense mechanisms.
Embodied Multi-Modal Agent trained by an LLM from a Parallel TextWorld
Nov 28, 2023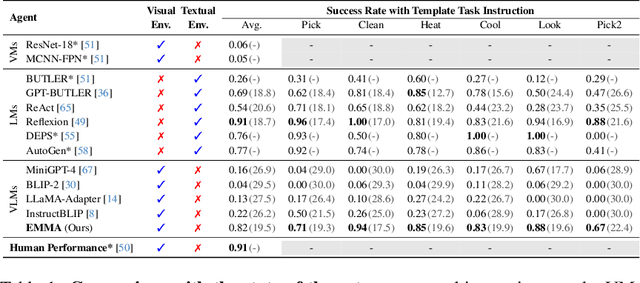
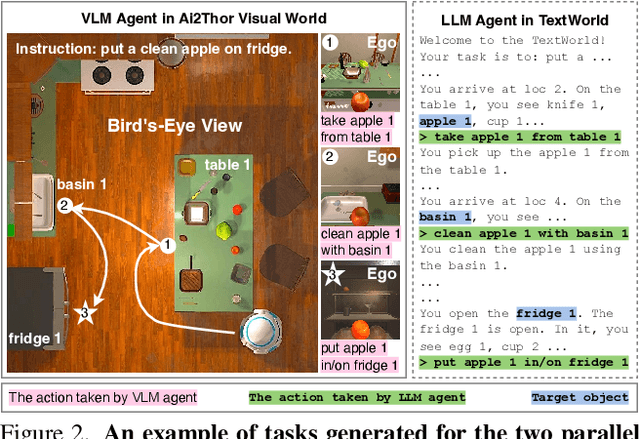
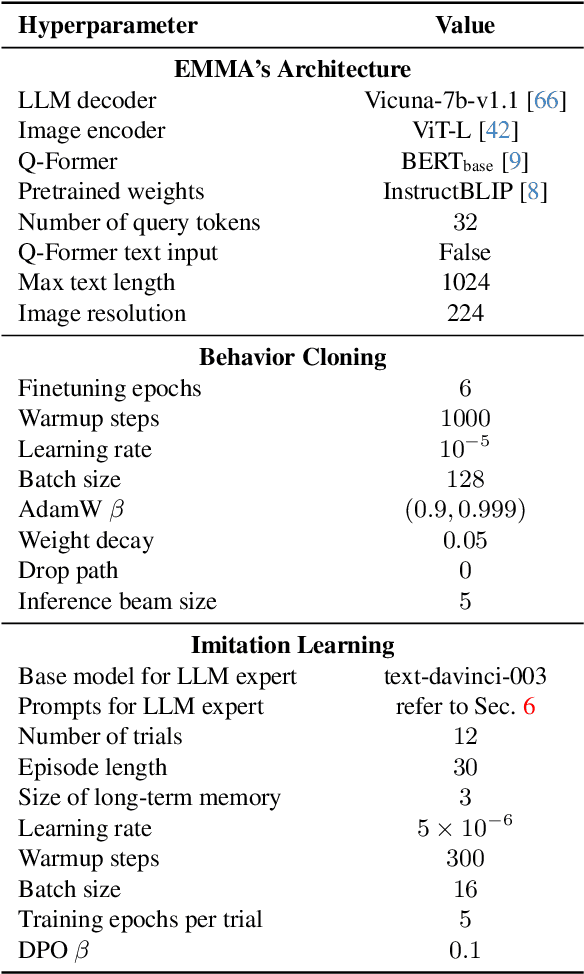
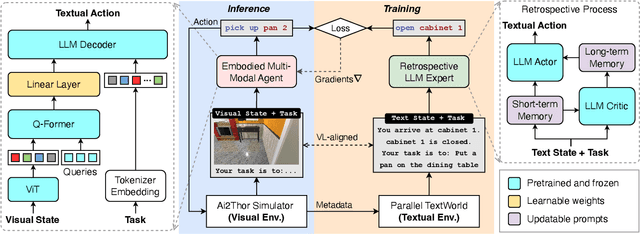
While large language models (LLMs) excel in a simulated world of texts, they struggle to interact with the more realistic world without perceptions of other modalities such as visual or audio signals. Although vision-language models (VLMs) integrate LLM modules (1) aligned with static image features, and (2) may possess prior knowledge of world dynamics (as demonstrated in the text world), they have not been trained in an embodied visual world and thus cannot align with its dynamics. On the other hand, training an embodied agent in a noisy visual world without expert guidance is often challenging and inefficient. In this paper, we train a VLM agent living in a visual world using an LLM agent excelling in a parallel text world (but inapplicable to the visual world). Specifically, we distill LLM's reflection outcomes (improved actions by analyzing mistakes) in a text world's tasks to finetune the VLM on the same tasks of the visual world, resulting in an Embodied Multi-Modal Agent (EMMA) quickly adapting to the visual world dynamics. Such cross-modality imitation learning between the two parallel worlds enables EMMA to generalize to a broad scope of new tasks without any further guidance from the LLM expert. Extensive evaluations on the ALFWorld benchmark highlight EMMA's superior performance to SOTA VLM-based agents across diverse tasks, e.g., 20%-70% improvement in the success rate.