 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJeff Z. Pan
Leveraging Intra-modal and Inter-modal Interaction for Multi-Modal Entity Alignment
Apr 19, 2024
Multi-modal entity alignment (MMEA) aims to identify equivalent entity pairs across different multi-modal knowledge graphs (MMKGs). Existing approaches focus on how to better encode and aggregate information from different modalities. However, it is not trivial to leverage multi-modal knowledge in entity alignment due to the modal heterogeneity. In this paper, we propose a Multi-Grained Interaction framework for Multi-Modal Entity Alignment (MIMEA), which effectively realizes multi-granular interaction within the same modality or between different modalities. MIMEA is composed of four modules: i) a Multi-modal Knowledge Embedding module, which extracts modality-specific representations with multiple individual encoders; ii) a Probability-guided Modal Fusion module, which employs a probability guided approach to integrate uni-modal representations into joint-modal embeddings, while considering the interaction between uni-modal representations; iii) an Optimal Transport Modal Alignment module, which introduces an optimal transport mechanism to encourage the interaction between uni-modal and joint-modal embeddings; iv) a Modal-adaptive Contrastive Learning module, which distinguishes the embeddings of equivalent entities from those of non-equivalent ones, for each modality. Extensive experiments conducted on two real-world datasets demonstrate the strong performance of MIMEA compared to the SoTA. Datasets and code have been submitted as supplementary materials.
HyperMono: A Monotonicity-aware Approach to Hyper-Relational Knowledge Representation
Apr 15, 2024In a hyper-relational knowledge graph (HKG), each fact is composed of a main triple associated with attribute-value qualifiers, which express additional factual knowledge. The hyper-relational knowledge graph completion (HKGC) task aims at inferring plausible missing links in a HKG. Most existing approaches to HKGC focus on enhancing the communication between qualifier pairs and main triples, while overlooking two important properties that emerge from the monotonicity of the hyper-relational graphs representation regime. Stage Reasoning allows for a two-step reasoning process, facilitating the integration of coarse-grained inference results derived solely from main triples and fine-grained inference results obtained from hyper-relational facts with qualifiers. In the initial stage, coarse-grained results provide an upper bound for correct predictions, which are subsequently refined in the fine-grained step. More generally, Qualifier Monotonicity implies that by attaching more qualifier pairs to a main triple, we may only narrow down the answer set, but never enlarge it. This paper proposes the HyperMono model for hyper-relational knowledge graph completion, which realizes stage reasoning and qualifier monotonicity. To implement qualifier monotonicity HyperMono resorts to cone embeddings. Experiments on three real-world datasets with three different scenario conditions demonstrate the strong performance of HyperMono when compared to the SoTA.
UniArk: Improving Generalisation and Consistency for Factual Knowledge Extraction through Debiasing
Apr 01, 2024Several recent papers have investigated the potential of language models as knowledge bases as well as the existence of severe biases when extracting factual knowledge. In this work, we focus on the factual probing performance over unseen prompts from tuning, and using a probabilistic view we show the inherent misalignment between pre-training and downstream tuning objectives in language models for probing knowledge. We hypothesize that simultaneously debiasing these objectives can be the key to generalisation over unseen prompts. We propose an adapter-based framework, UniArk, for generalised and consistent factual knowledge extraction through simple methods without introducing extra parameters. Extensive experiments show that UniArk can significantly improve the model's out-of-domain generalisation as well as consistency under various prompts. Additionally, we construct ParaTrex, a large-scale and diverse dataset for measuring the inconsistency and out-of-domain generation of models. Further, ParaTrex offers a reference method for constructing paraphrased datasets using large language models.
Knowledge Graphs Meet Multi-Modal Learning: A Comprehensive Survey
Feb 26, 2024



Knowledge Graphs (KGs) play a pivotal role in advancing various AI applications, with the semantic web community's exploration into multi-modal dimensions unlocking new avenues for innovation. In this survey, we carefully review over 300 articles, focusing on KG-aware research in two principal aspects: KG-driven Multi-Modal (KG4MM) learning, where KGs support multi-modal tasks, and Multi-Modal Knowledge Graph (MM4KG), which extends KG studies into the MMKG realm. We begin by defining KGs and MMKGs, then explore their construction progress. Our review includes two primary task categories: KG-aware multi-modal learning tasks, such as Image Classification and Visual Question Answering, and intrinsic MMKG tasks like Multi-modal Knowledge Graph Completion and Entity Alignment, highlighting specific research trajectories. For most of these tasks, we provide definitions, evaluation benchmarks, and additionally outline essential insights for conducting relevant research. Finally, we discuss current challenges and identify emerging trends, such as progress in Large Language Modeling and Multi-modal Pre-training strategies. This survey aims to serve as a comprehensive reference for researchers already involved in or considering delving into KG and multi-modal learning research, offering insights into the evolving landscape of MMKG research and supporting future work.
Archer: A Human-Labeled Text-to-SQL Dataset with Arithmetic, Commonsense and Hypothetical Reasoning
Feb 25, 2024We present Archer, a challenging bilingual text-to-SQL dataset specific to complex reasoning, including arithmetic, commonsense and hypothetical reasoning. It contains 1,042 English questions and 1,042 Chinese questions, along with 521 unique SQL queries, covering 20 English databases across 20 domains. Notably, this dataset demonstrates a significantly higher level of complexity compared to existing publicly available datasets. Our evaluation shows that Archer challenges the capabilities of current state-of-the-art models, with a high-ranked model on the Spider leaderboard achieving only 6.73% execution accuracy on Archer test set. Thus, Archer presents a significant challenge for future research in this field.
A Usage-centric Take on Intent Understanding in E-Commerce
Feb 22, 2024Identifying and understanding user intents is a pivotal task for E-Commerce. Despite its popularity, intent understanding has not been consistently defined or accurately benchmarked. In this paper, we focus on predicative user intents as "how a customer uses a product", and pose intent understanding as a natural language reasoning task, independent of product ontologies. We identify two weaknesses of FolkScope, the SOTA E-Commerce Intent Knowledge Graph, that limit its capacity to reason about user intents and to recommend diverse useful products. Following these observations, we introduce a Product Recovery Benchmark including a novel evaluation framework and an example dataset. We further validate the above FolkScope weaknesses on this benchmark.
TrustScore: Reference-Free Evaluation of LLM Response Trustworthiness
Feb 19, 2024Large Language Models (LLMs) have demonstrated impressive capabilities across various domains, prompting a surge in their practical applications. However, concerns have arisen regarding the trustworthiness of LLMs outputs, particularly in closed-book question-answering tasks, where non-experts may struggle to identify inaccuracies due to the absence of contextual or ground truth information. This paper introduces TrustScore, a framework based on the concept of Behavioral Consistency, which evaluates whether an LLMs response aligns with its intrinsic knowledge. Additionally, TrustScore can seamlessly integrate with fact-checking methods, which assesses alignment with external knowledge sources. The experimental results show that TrustScore achieves strong correlations with human judgments, surpassing existing reference-free metrics, and achieving results on par with reference-based metrics.
Knowledge-Aware Neuron Interpretation for Scene Classification
Jan 29, 2024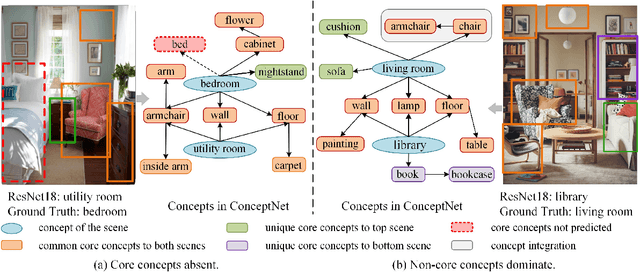
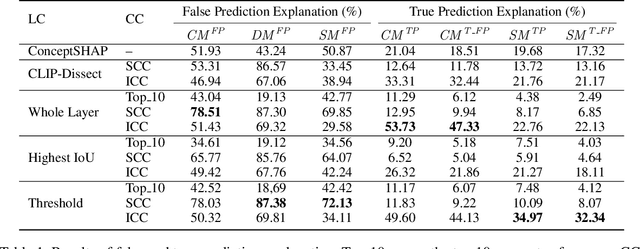


Although neural models have achieved remarkable performance, they still encounter doubts due to the intransparency. To this end, model prediction explanation is attracting more and more attentions. However, current methods rarely incorporate external knowledge and still suffer from three limitations: (1) Neglecting concept completeness. Merely selecting concepts may not sufficient for prediction. (2) Lacking concept fusion. Failure to merge semantically-equivalent concepts. (3) Difficult in manipulating model behavior. Lack of verification for explanation on original model. To address these issues, we propose a novel knowledge-aware neuron interpretation framework to explain model predictions for image scene classification. Specifically, for concept completeness, we present core concepts of a scene based on knowledge graph, ConceptNet, to gauge the completeness of concepts. Our method, incorporating complete concepts, effectively provides better prediction explanations compared to baselines. Furthermore, for concept fusion, we introduce a knowledge graph-based method known as Concept Filtering, which produces over 23% point gain on neuron behaviors for neuron interpretation. At last, we propose Model Manipulation, which aims to study whether the core concepts based on ConceptNet could be employed to manipulate model behavior. The results show that core concepts can effectively improve the performance of original model by over 26%.
Benchmarking Large Language Models in Complex Question Answering Attribution using Knowledge Graphs
Jan 26, 2024The attribution of question answering is to provide citations for supporting generated statements, and has attracted wide research attention. The current methods for automatically evaluating the attribution, which are often based on Large Language Models (LLMs), are still inadequate, particularly in recognizing subtle differences between attributions, and complex relationships between citations and statements. To compare these attribution evaluation methods and develop new ones, we introduce a set of fine-grained categories (i.e., supportive, insufficient, contradictory and irrelevant) for measuring the attribution, and develop a Complex Attributed Question Answering (CAQA) benchmark by leveraging knowledge graphs (KGs) for automatically generating attributions of different categories to question-answer pairs. Our analysis reveals that existing evaluators perform poorly under fine-grained attribution settings and exhibit weaknesses in complex citation-statement reasoning. Our CAQA benchmark, validated with human annotations, emerges as a promising tool for selecting and developing LLM attribution evaluators.
UniMS-RAG: A Unified Multi-source Retrieval-Augmented Generation for Personalized Dialogue Systems
Jan 24, 2024Large Language Models (LLMs) has shown exceptional capabilities in many natual language understanding and generation tasks. However, the personalization issue still remains a much-coveted property, especially when it comes to the multiple sources involved in the dialogue system. To better plan and incorporate the use of multiple sources in generating personalized response, we firstly decompose it into three sub-tasks: Knowledge Source Selection, Knowledge Retrieval, and Response Generation. We then propose a novel Unified Multi-Source Retrieval-Augmented Generation system (UniMS-RAG) Specifically, we unify these three sub-tasks with different formulations into the same sequence-to-sequence paradigm during the training, to adaptively retrieve evidences and evaluate the relevance on-demand using special tokens, called acting tokens and evaluation tokens. Enabling language models to generate acting tokens facilitates interaction with various knowledge sources, allowing them to adapt their behavior to diverse task requirements. Meanwhile, evaluation tokens gauge the relevance score between the dialogue context and the retrieved evidence. In addition, we carefully design a self-refinement mechanism to iteratively refine the generated response considering 1) the consistency scores between the generated response and retrieved evidence; and 2) the relevance scores. Experiments on two personalized datasets (DuLeMon and KBP) show that UniMS-RAG achieves state-of-the-art performance on the knowledge source selection and response generation task with itself as a retriever in a unified manner. Extensive analyses and discussions are provided for shedding some new perspectives for personalized dialogue systems.