 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaoze Liu
Evaluating the Factuality of Large Language Models using Large-Scale Knowledge Graphs
Apr 01, 2024
The advent of Large Language Models (LLMs) has significantly transformed the AI landscape, enhancing machine learning and AI capabilities. Factuality issue is a critical concern for LLMs, as they may generate factually incorrect responses. In this paper, we propose GraphEval to evaluate an LLM's performance using a substantially large test dataset. Specifically, the test dataset is retrieved from a large knowledge graph with more than 10 million facts without expensive human efforts. Unlike conventional methods that evaluate LLMs based on generated responses, GraphEval streamlines the evaluation process by creating a judge model to estimate the correctness of the answers given by the LLM. Our experiments demonstrate that the judge model's factuality assessment aligns closely with the correctness of the LLM's generated outputs, while also substantially reducing evaluation costs. Besides, our findings offer valuable insights into LLM performance across different metrics and highlight the potential for future improvements in ensuring the factual integrity of LLM outputs. The code is publicly available at https://github.com/xz-liu/GraphEval.
Knowledge Graphs Meet Multi-Modal Learning: A Comprehensive Survey
Feb 26, 2024Knowledge Graphs (KGs) play a pivotal role in advancing various AI applications, with the semantic web community's exploration into multi-modal dimensions unlocking new avenues for innovation. In this survey, we carefully review over 300 articles, focusing on KG-aware research in two principal aspects: KG-driven Multi-Modal (KG4MM) learning, where KGs support multi-modal tasks, and Multi-Modal Knowledge Graph (MM4KG), which extends KG studies into the MMKG realm. We begin by defining KGs and MMKGs, then explore their construction progress. Our review includes two primary task categories: KG-aware multi-modal learning tasks, such as Image Classification and Visual Question Answering, and intrinsic MMKG tasks like Multi-modal Knowledge Graph Completion and Entity Alignment, highlighting specific research trajectories. For most of these tasks, we provide definitions, evaluation benchmarks, and additionally outline essential insights for conducting relevant research. Finally, we discuss current challenges and identify emerging trends, such as progress in Large Language Modeling and Multi-modal Pre-training strategies. This survey aims to serve as a comprehensive reference for researchers already involved in or considering delving into KG and multi-modal learning research, offering insights into the evolving landscape of MMKG research and supporting future work.
Survey on Factuality in Large Language Models: Knowledge, Retrieval and Domain-Specificity
Oct 18, 2023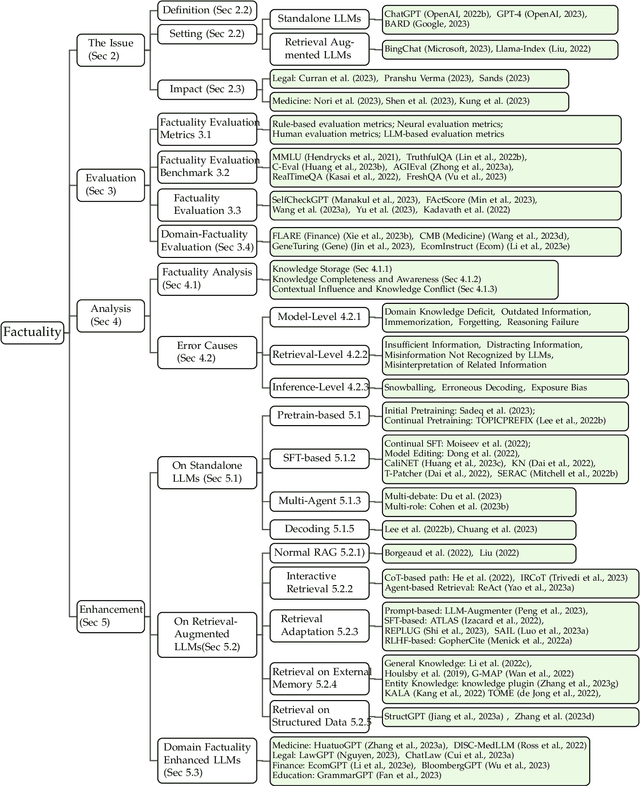
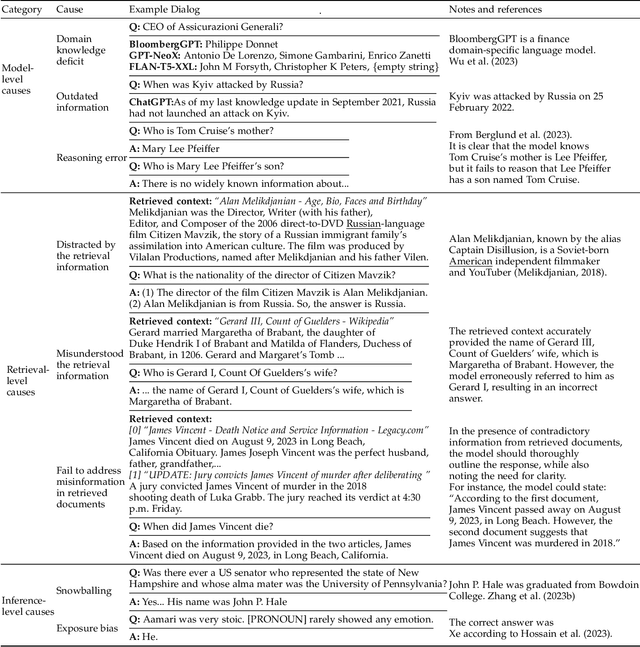
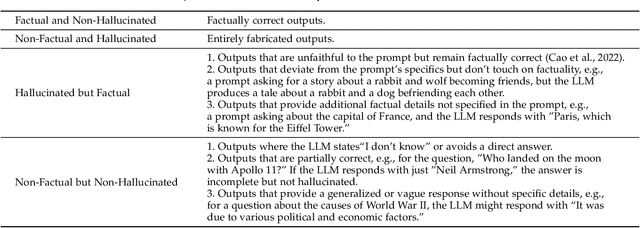
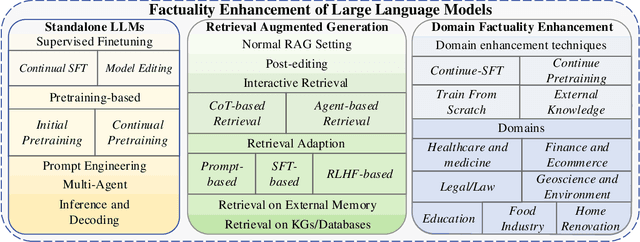
This survey addresses the crucial issue of factuality in Large Language Models (LLMs). As LLMs find applications across diverse domains, the reliability and accuracy of their outputs become vital. We define the Factuality Issue as the probability of LLMs to produce content inconsistent with established facts. We first delve into the implications of these inaccuracies, highlighting the potential consequences and challenges posed by factual errors in LLM outputs. Subsequently, we analyze the mechanisms through which LLMs store and process facts, seeking the primary causes of factual errors. Our discussion then transitions to methodologies for evaluating LLM factuality, emphasizing key metrics, benchmarks, and studies. We further explore strategies for enhancing LLM factuality, including approaches tailored for specific domains. We focus two primary LLM configurations standalone LLMs and Retrieval-Augmented LLMs that utilizes external data, we detail their unique challenges and potential enhancements. Our survey offers a structured guide for researchers aiming to fortify the factual reliability of LLMs.
Universal Multi-modal Entity Alignment via Iteratively Fusing Modality Similarity Paths
Oct 13, 2023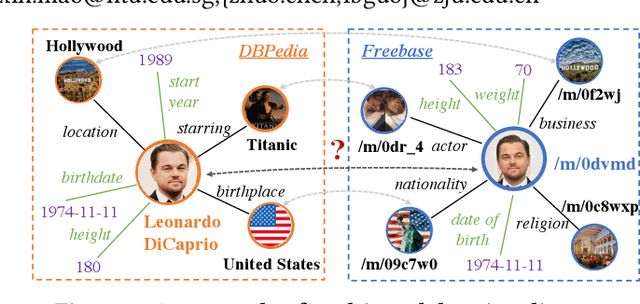
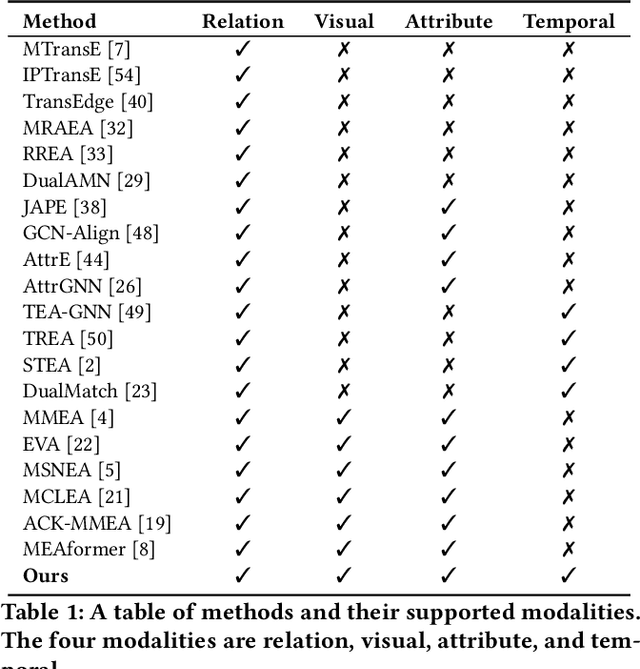

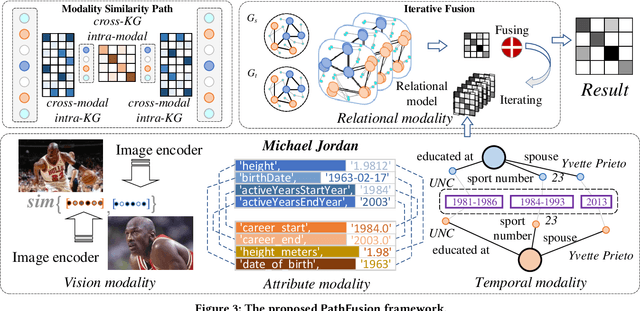
The objective of Entity Alignment (EA) is to identify equivalent entity pairs from multiple Knowledge Graphs (KGs) and create a more comprehensive and unified KG. The majority of EA methods have primarily focused on the structural modality of KGs, lacking exploration of multi-modal information. A few multi-modal EA methods have made good attempts in this field. Still, they have two shortcomings: (1) inconsistent and inefficient modality modeling that designs complex and distinct models for each modality; (2) ineffective modality fusion due to the heterogeneous nature of modalities in EA. To tackle these challenges, we propose PathFusion, consisting of two main components: (1) MSP, a unified modeling approach that simplifies the alignment process by constructing paths connecting entities and modality nodes to represent multiple modalities; (2) IRF, an iterative fusion method that effectively combines information from different modalities using the path as an information carrier. Experimental results on real-world datasets demonstrate the superiority of PathFusion over state-of-the-art methods, with 22.4%-28.9% absolute improvement on Hits@1, and 0.194-0.245 absolute improvement on MRR.
MultiEM: Efficient and Effective Unsupervised Multi-Table Entity Matching
Aug 02, 2023
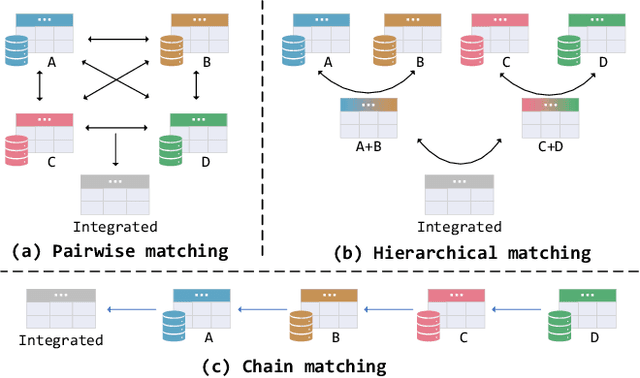
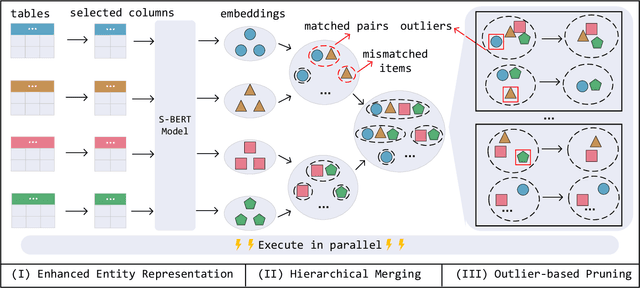

Entity Matching (EM), which aims to identify all entity pairs referring to the same real-world entity from relational tables, is one of the most important tasks in real-world data management systems. Due to the labeling process of EM being extremely labor-intensive, unsupervised EM is more applicable than supervised EM in practical scenarios. Traditional unsupervised EM assumes that all entities come from two tables; however, it is more common to match entities from multiple tables in practical applications, that is, multi-table entity matching (multi-table EM). Unfortunately, effective and efficient unsupervised multi-table EM remains under-explored. To fill this gap, this paper formally studies the problem of unsupervised multi-table entity matching and proposes an effective and efficient solution, termed as MultiEM. MultiEM is a parallelable pipeline of enhanced entity representation, table-wise hierarchical merging, and density-based pruning. Extensive experimental results on six real-world benchmark datasets demonstrate the superiority of MultiEM in terms of effectiveness and efficiency.
Real-time Workload Pattern Analysis for Large-scale Cloud Databases
Jul 05, 2023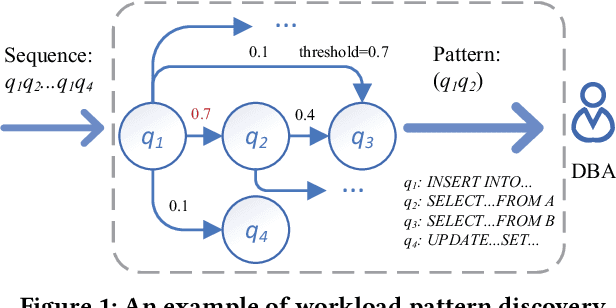
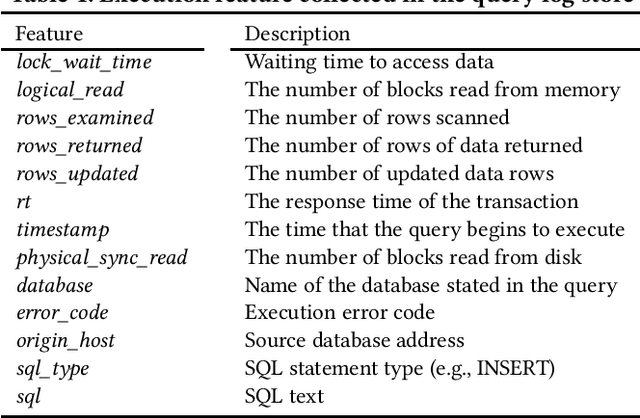
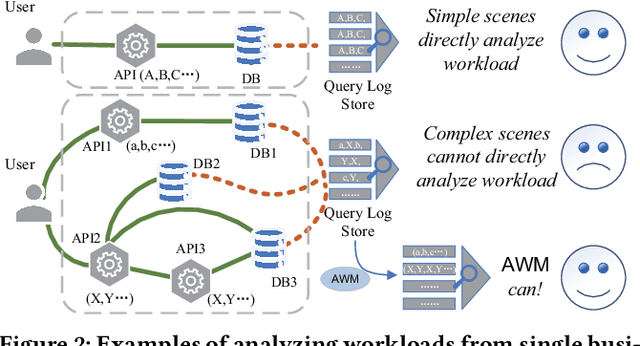
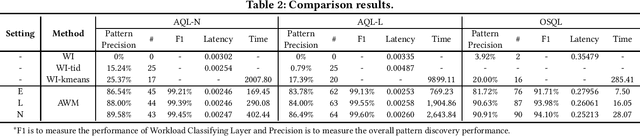
Hosting database services on cloud systems has become a common practice. This has led to the increasing volume of database workloads, which provides the opportunity for pattern analysis. Discovering workload patterns from a business logic perspective is conducive to better understanding the trends and characteristics of the database system. However, existing workload pattern discovery systems are not suitable for large-scale cloud databases which are commonly employed by the industry. This is because the workload patterns of large-scale cloud databases are generally far more complicated than those of ordinary databases. In this paper, we propose Alibaba Workload Miner (AWM), a real-time system for discovering workload patterns in complicated large-scale workloads. AWM encodes and discovers the SQL query patterns logged from user requests and optimizes the querying processing based on the discovered patterns. First, Data Collection & Preprocessing Module collects streaming query logs and encodes them into high-dimensional feature embeddings with rich semantic contexts and execution features. Next, Online Workload Mining Module separates encoded queries by business groups and discovers the workload patterns for each group. Meanwhile, Offline Training Module collects labels and trains the classification model using the labels. Finally, Pattern-based Optimizing Module optimizes query processing in cloud databases by exploiting discovered patterns. Extensive experimental results on one synthetic dataset and two real-life datasets (extracted from Alibaba Cloud databases) show that AWM enhances the accuracy of pattern discovery by 66% and reduce the latency of online inference by 22%, compared with the state-of-the-arts.
Quiver: Supporting GPUs for Low-Latency, High-Throughput GNN Serving with Workload Awareness
May 18, 2023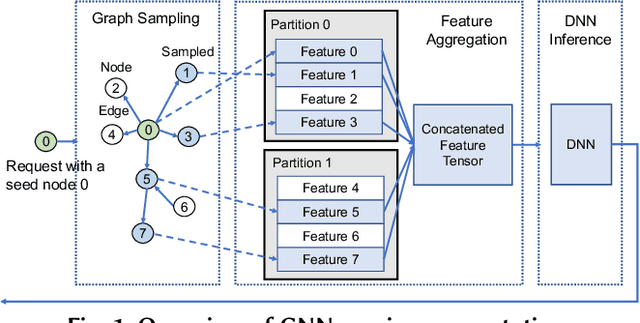
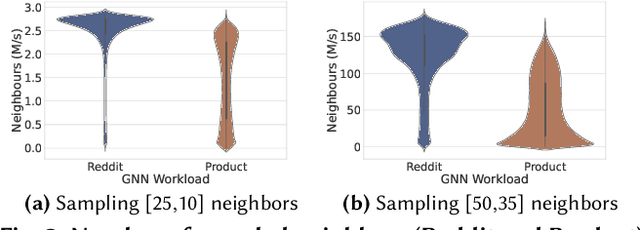
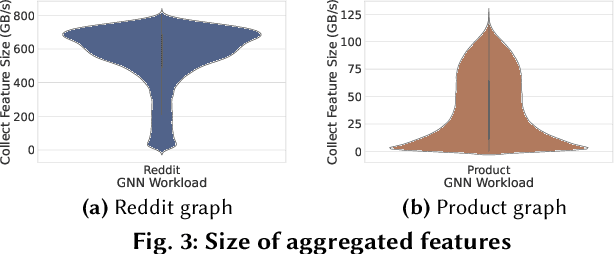
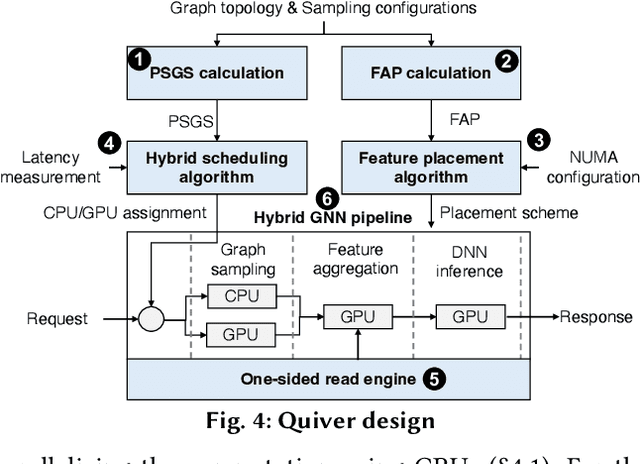
Systems for serving inference requests on graph neural networks (GNN) must combine low latency with high throughout, but they face irregular computation due to skew in the number of sampled graph nodes and aggregated GNN features. This makes it challenging to exploit GPUs effectively: using GPUs to sample only a few graph nodes yields lower performance than CPU-based sampling; and aggregating many features exhibits high data movement costs between GPUs and CPUs. Therefore, current GNN serving systems use CPUs for graph sampling and feature aggregation, limiting throughput. We describe Quiver, a distributed GPU-based GNN serving system with low-latency and high-throughput. Quiver's key idea is to exploit workload metrics for predicting the irregular computation of GNN requests, and governing the use of GPUs for graph sampling and feature aggregation: (1) for graph sampling, Quiver calculates the probabilistic sampled graph size, a metric that predicts the degree of parallelism in graph sampling. Quiver uses this metric to assign sampling tasks to GPUs only when the performance gains surpass CPU-based sampling; and (2) for feature aggregation, Quiver relies on the feature access probability to decide which features to partition and replicate across a distributed GPU NUMA topology. We show that Quiver achieves up to 35 times lower latency with an 8 times higher throughput compared to state-of-the-art GNN approaches (DGL and PyG).
Unsupervised Entity Alignment for Temporal Knowledge Graphs
Feb 08, 2023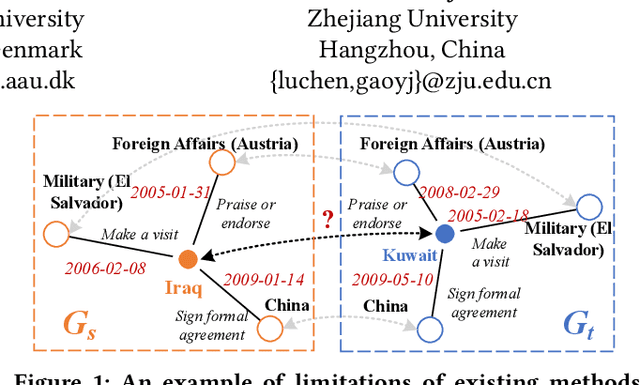
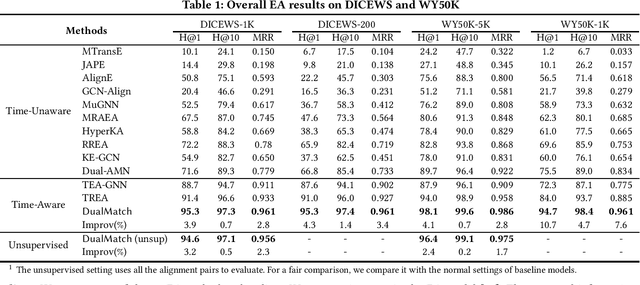
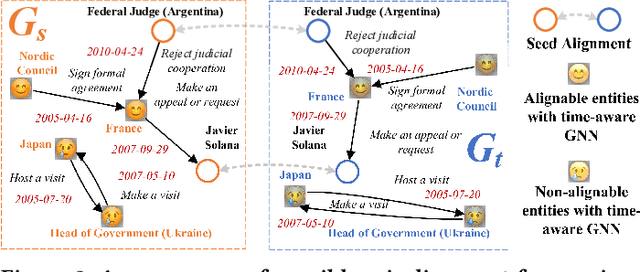
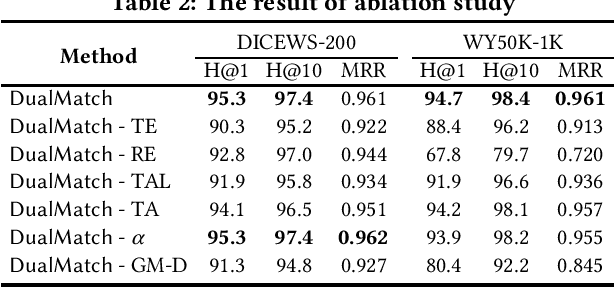
Entity alignment (EA) is a fundamental data integration task that identifies equivalent entities between different knowledge graphs (KGs). Temporal Knowledge graphs (TKGs) extend traditional knowledge graphs by introducing timestamps, which have received increasing attention. State-of-the-art time-aware EA studies have suggested that the temporal information of TKGs facilitates the performance of EA. However, existing studies have not thoroughly exploited the advantages of temporal information in TKGs. Also, they perform EA by pre-aligning entity pairs, which can be labor-intensive and thus inefficient. In this paper, we present DualMatch which effectively fuses the relational and temporal information for EA. DualMatch transfers EA on TKGs into a weighted graph matching problem. More specifically, DualMatch is equipped with an unsupervised method, which achieves EA without necessitating seed alignment. DualMatch has two steps: (i) encoding temporal and relational information into embeddings separately using a novel label-free encoder, Dual-Encoder; and (ii) fusing both information and transforming it into alignment using a novel graph-matching-based decoder, GM-Decoder. DualMatch is able to perform EA on TKGs with or without supervision, due to its capability of effectively capturing temporal information. Extensive experiments on three real-world TKG datasets offer the insight that DualMatch outperforms the state-of-the-art methods in terms of H@1 by 2.4% - 10.7% and MRR by 1.7% - 7.6%, respectively.
ClusterEA: Scalable Entity Alignment with Stochastic Training and Normalized Mini-batch Similarities
May 20, 2022


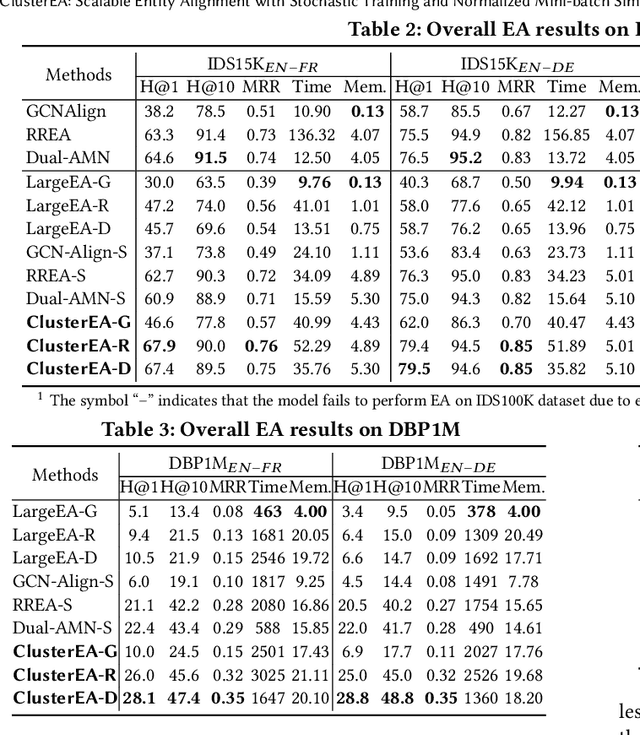
Entity alignment (EA) aims at finding equivalent entities in different knowledge graphs (KGs). Embedding-based approaches have dominated the EA task in recent years. Those methods face problems that come from the geometric properties of embedding vectors, including hubness and isolation. To solve these geometric problems, many normalization approaches have been adopted to EA. However, the increasing scale of KGs renders it is hard for EA models to adopt the normalization processes, thus limiting their usage in real-world applications. To tackle this challenge, we present ClusterEA, a general framework that is capable of scaling up EA models and enhancing their results by leveraging normalization methods on mini-batches with a high entity equivalent rate. ClusterEA contains three components to align entities between large-scale KGs, including stochastic training, ClusterSampler, and SparseFusion. It first trains a large-scale Siamese GNN for EA in a stochastic fashion to produce entity embeddings. Based on the embeddings, a novel ClusterSampler strategy is proposed for sampling highly overlapped mini-batches. Finally, ClusterEA incorporates SparseFusion, which normalizes local and global similarity and then fuses all similarity matrices to obtain the final similarity matrix. Extensive experiments with real-life datasets on EA benchmarks offer insight into the proposed framework, and suggest that it is capable of outperforming the state-of-the-art scalable EA framework by up to 8 times in terms of Hits@1.