 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeijie Wu
Evaluating the Factuality of Large Language Models using Large-Scale Knowledge Graphs
Apr 01, 2024
The advent of Large Language Models (LLMs) has significantly transformed the AI landscape, enhancing machine learning and AI capabilities. Factuality issue is a critical concern for LLMs, as they may generate factually incorrect responses. In this paper, we propose GraphEval to evaluate an LLM's performance using a substantially large test dataset. Specifically, the test dataset is retrieved from a large knowledge graph with more than 10 million facts without expensive human efforts. Unlike conventional methods that evaluate LLMs based on generated responses, GraphEval streamlines the evaluation process by creating a judge model to estimate the correctness of the answers given by the LLM. Our experiments demonstrate that the judge model's factuality assessment aligns closely with the correctness of the LLM's generated outputs, while also substantially reducing evaluation costs. Besides, our findings offer valuable insights into LLM performance across different metrics and highlight the potential for future improvements in ensuring the factual integrity of LLM outputs. The code is publicly available at https://github.com/xz-liu/GraphEval.
Towards Poisoning Fair Representations
Sep 28, 2023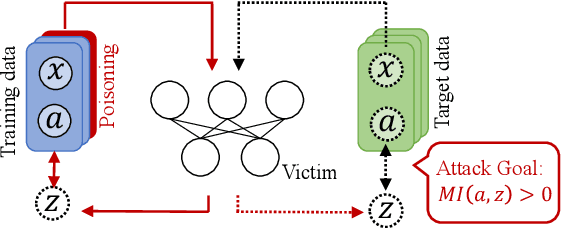
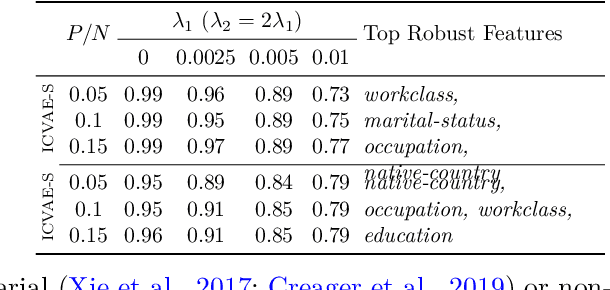
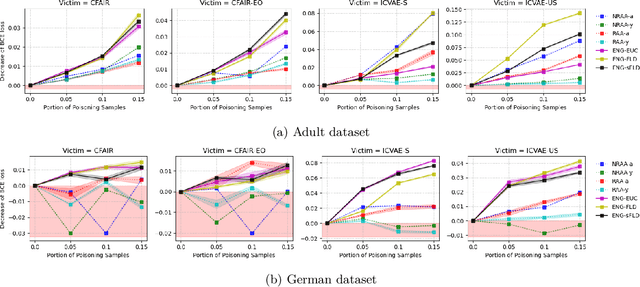
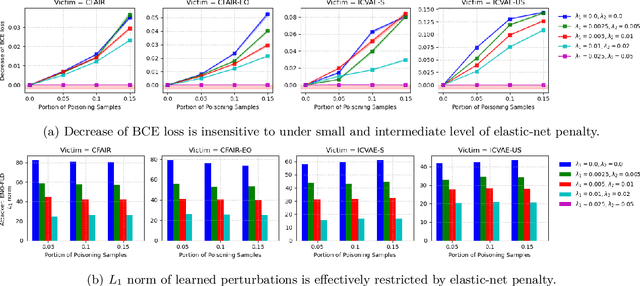
Fair machine learning seeks to mitigate model prediction bias against certain demographic subgroups such as elder and female. Recently, fair representation learning (FRL) trained by deep neural networks has demonstrated superior performance, whereby representations containing no demographic information are inferred from the data and then used as the input to classification or other downstream tasks. Despite the development of FRL methods, their vulnerability under data poisoning attack, a popular protocol to benchmark model robustness under adversarial scenarios, is under-explored. Data poisoning attacks have been developed for classical fair machine learning methods which incorporate fairness constraints into shallow-model classifiers. Nonetheless, these attacks fall short in FRL due to notably different fairness goals and model architectures. This work proposes the first data poisoning framework attacking FRL. We induce the model to output unfair representations that contain as much demographic information as possible by injecting carefully crafted poisoning samples into the training data. This attack entails a prohibitive bilevel optimization, wherefore an effective approximated solution is proposed. A theoretical analysis on the needed number of poisoning samples is derived and sheds light on defending against the attack. Experiments on benchmark fairness datasets and state-of-the-art fair representation learning models demonstrate the superiority of our attack.
GlueFL: Reconciling Client Sampling and Model Masking for Bandwidth Efficient Federated Learning
Dec 03, 2022

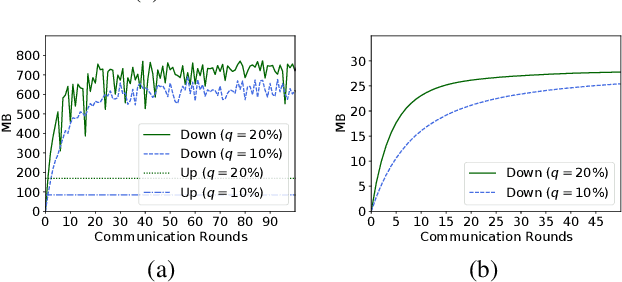
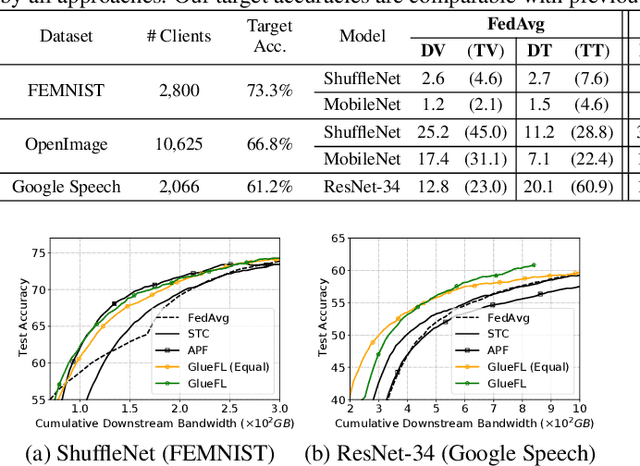
Federated learning (FL) is an effective technique to directly involve edge devices in machine learning training while preserving client privacy. However, the substantial communication overhead of FL makes training challenging when edge devices have limited network bandwidth. Existing work to optimize FL bandwidth overlooks downstream transmission and does not account for FL client sampling. In this paper we propose GlueFL, a framework that incorporates new client sampling and model compression algorithms to mitigate low download bandwidths of FL clients. GlueFL prioritizes recently used clients and bounds the number of changed positions in compression masks in each round. Across three popular FL datasets and three state-of-the-art strategies, GlueFL reduces downstream client bandwidth by 27% on average and reduces training time by 29% on average.
Accelerating Federated Learning via Sampling Anchor Clients with Large Batches
Jun 13, 2022
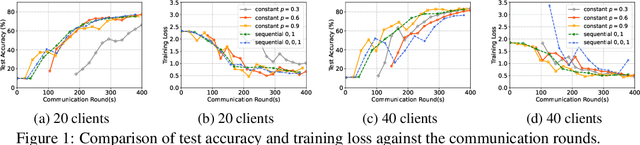
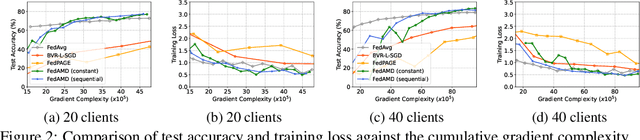
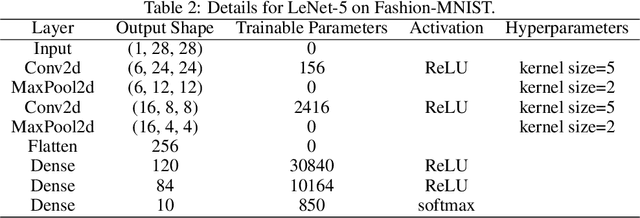
Using large batches in recent federated learning studies has improved convergence rates, but it requires additional computation overhead compared to using small batches. To overcome this limitation, we propose a unified framework FedAMD, which disjoints the participants into anchor and miner groups based on time-varying probabilities. Each client in the anchor group computes the gradient using a large batch, which is regarded as its bullseye. Clients in the miner group perform multiple local updates using serial mini-batches, and each local update is also indirectly regulated by the global target derived from the average of clients' bullseyes. As a result, the miner group follows a near-optimal update towards the global minimizer, adapted to update the global model. Measured by $\epsilon$-approximation, FedAMD achieves a convergence rate of $O(1/\epsilon)$ under non-convex objectives by sampling an anchor with a constant probability. The theoretical result considerably surpasses the state-of-the-art algorithm BVR-L-SGD at $O(1/\epsilon^{3/2})$, while FedAMD reduces at least $O(1/\epsilon)$ communication overhead. Empirical studies on real-world datasets validate the effectiveness of FedAMD and demonstrate the superiority of our proposed algorithm.
Sign Bit is Enough: A Learning Synchronization Framework for Multi-hop All-reduce with Ultimate Compression
Apr 14, 2022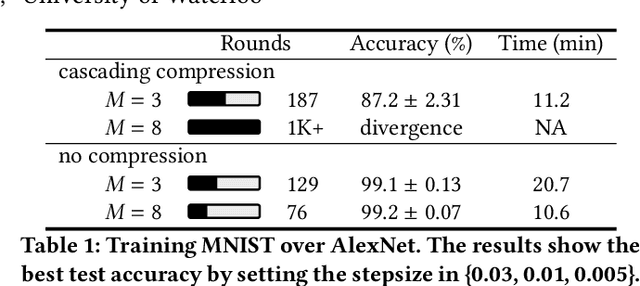
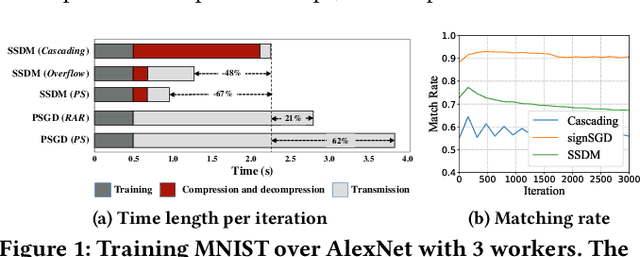


Traditional one-bit compressed stochastic gradient descent can not be directly employed in multi-hop all-reduce, a widely adopted distributed training paradigm in network-intensive high-performance computing systems such as public clouds. According to our theoretical findings, due to the cascading compression, the training process has considerable deterioration on the convergence performance. To overcome this limitation, we implement a sign-bit compression-based learning synchronization framework, Marsit. It prevents cascading compression via an elaborate bit-wise operation for unbiased sign aggregation and its specific global compensation mechanism for mitigating compression deviation. The proposed framework retains the same theoretical convergence rate as non-compression mechanisms. Experimental results demonstrate that Marsit reduces up to 35% training time while preserving the same accuracy as training without compression.
From Deterioration to Acceleration: A Calibration Approach to Rehabilitating Step Asynchronism in Federated Optimization
Dec 17, 2021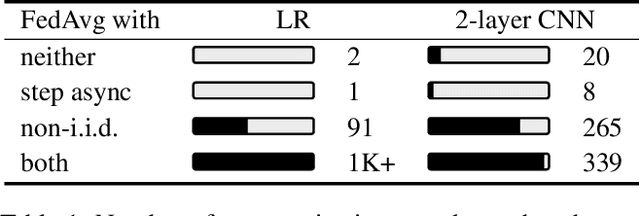


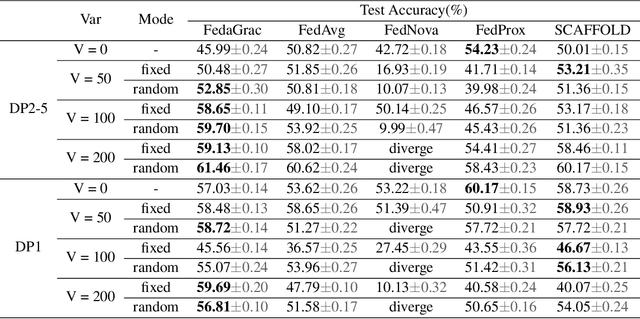
In the setting of federated optimization, where a global model is aggregated periodically, step asynchronism occurs when participants conduct model training with fully utilizing their computational resources. It is well acknowledged that step asynchronism leads to objective inconsistency under non-i.i.d. data, which degrades the model accuracy. To address this issue, we propose a new algorithm \texttt{FedaGrac}, which calibrates the local direction to a predictive global orientation. Taking the advantage of estimated orientation, we guarantee that the aggregated model does not excessively deviate from the expected orientation while fully utilizing the local updates of faster nodes. We theoretically prove that \texttt{FedaGrac} holds an improved order of convergence rate than the state-of-the-art approaches and eliminates the negative effect of step asynchronism. Empirical results show that our algorithm accelerates the training and enhances the final accuracy.
Parameterized Knowledge Transfer for Personalized Federated Learning
Nov 04, 2021



In recent years, personalized federated learning (pFL) has attracted increasing attention for its potential in dealing with statistical heterogeneity among clients. However, the state-of-the-art pFL methods rely on model parameters aggregation at the server side, which require all models to have the same structure and size, and thus limits the application for more heterogeneous scenarios. To deal with such model constraints, we exploit the potentials of heterogeneous model settings and propose a novel training framework to employ personalized models for different clients. Specifically, we formulate the aggregation procedure in original pFL into a personalized group knowledge transfer training algorithm, namely, KT-pFL, which enables each client to maintain a personalized soft prediction at the server side to guide the others' local training. KT-pFL updates the personalized soft prediction of each client by a linear combination of all local soft predictions using a knowledge coefficient matrix, which can adaptively reinforce the collaboration among clients who own similar data distribution. Furthermore, to quantify the contributions of each client to others' personalized training, the knowledge coefficient matrix is parameterized so that it can be trained simultaneously with the models. The knowledge coefficient matrix and the model parameters are alternatively updated in each round following the gradient descent way. Extensive experiments on various datasets (EMNIST, Fashion\_MNIST, CIFAR-10) are conducted under different settings (heterogeneous models and data distributions). It is demonstrated that the proposed framework is the first federated learning paradigm that realizes personalized model training via parameterized group knowledge transfer while achieving significant performance gain comparing with state-of-the-art algorithms.