 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaoyu Wang
Glitch Tokens in Large Language Models: Categorization Taxonomy and Effective Detection
Apr 19, 2024
With the expanding application of Large Language Models (LLMs) in various domains, it becomes imperative to comprehensively investigate their unforeseen behaviors and consequent outcomes. In this study, we introduce and systematically explore the phenomenon of "glitch tokens", which are anomalous tokens produced by established tokenizers and could potentially compromise the models' quality of response. Specifically, we experiment on seven top popular LLMs utilizing three distinct tokenizers and involving a totally of 182,517 tokens. We present categorizations of the identified glitch tokens and symptoms exhibited by LLMs when interacting with glitch tokens. Based on our observation that glitch tokens tend to cluster in the embedding space, we propose GlitchHunter, a novel iterative clustering-based technique, for efficient glitch token detection. The evaluation shows that our approach notably outperforms three baseline methods on eight open-source LLMs. To the best of our knowledge, we present the first comprehensive study on glitch tokens. Our new detection further provides valuable insights into mitigating tokenization-related errors in LLMs.
BLINK: Multimodal Large Language Models Can See but Not Perceive
Apr 18, 2024We introduce Blink, a new benchmark for multimodal language models (LLMs) that focuses on core visual perception abilities not found in other evaluations. Most of the Blink tasks can be solved by humans "within a blink" (e.g., relative depth estimation, visual correspondence, forensics detection, and multi-view reasoning). However, we find these perception-demanding tasks cast significant challenges for current multimodal LLMs because they resist mediation through natural language. Blink reformats 14 classic computer vision tasks into 3,807 multiple-choice questions, paired with single or multiple images and visual prompting. While humans get 95.70% accuracy on average, Blink is surprisingly challenging for existing multimodal LLMs: even the best-performing GPT-4V and Gemini achieve accuracies of 51.26% and 45.72%, only 13.17% and 7.63% higher than random guessing, indicating that such perception abilities have not "emerged" yet in recent multimodal LLMs. Our analysis also highlights that specialist CV models could solve these problems much better, suggesting potential pathways for future improvements. We believe Blink will stimulate the community to help multimodal LLMs catch up with human-level visual perception.
Mask-ControlNet: Higher-Quality Image Generation with An Additional Mask Prompt
Apr 08, 2024Text-to-image generation has witnessed great progress, especially with the recent advancements in diffusion models. Since texts cannot provide detailed conditions like object appearance, reference images are usually leveraged for the control of objects in the generated images. However, existing methods still suffer limited accuracy when the relationship between the foreground and background is complicated. To address this issue, we develop a framework termed Mask-ControlNet by introducing an additional mask prompt. Specifically, we first employ large vision models to obtain masks to segment the objects of interest in the reference image. Then, the object images are employed as additional prompts to facilitate the diffusion model to better understand the relationship between foreground and background regions during image generation. Experiments show that the mask prompts enhance the controllability of the diffusion model to maintain higher fidelity to the reference image while achieving better image quality. Comparison with previous text-to-image generation methods demonstrates our method's superior quantitative and qualitative performance on the benchmark datasets.
Arm-Constrained Curriculum Learning for Loco-Manipulation of the Wheel-Legged Robot
Mar 28, 2024Incorporating a robotic manipulator into a wheel-legged robot enhances its agility and expands its potential for practical applications. However, the presence of potential instability and uncertainties presents additional challenges for control objectives. In this paper, we introduce an arm-constrained curriculum learning architecture to tackle the issues introduced by adding the manipulator. Firstly, we develop an arm-constrained reinforcement learning algorithm to ensure safety and stability in control performance. Additionally, to address discrepancies in reward settings between the arm and the base, we propose a reward-aware curriculum learning method. The policy is first trained in Isaac gym and transferred to the physical robot to do dynamic grasping tasks, including the door-opening task, fan-twitching task and the relay-baton-picking and following task. The results demonstrate that our proposed approach effectively controls the arm-equipped wheel-legged robot to master dynamic grasping skills, allowing it to chase and catch a moving object while in motion. Please refer to our website (https://acodedog.github.io/wheel-legged-loco-manipulation) for the code and supplemental videos.
Stochastic Gradient Langevin Unlearning
Mar 25, 2024``The right to be forgotten'' ensured by laws for user data privacy becomes increasingly important. Machine unlearning aims to efficiently remove the effect of certain data points on the trained model parameters so that it can be approximately the same as if one retrains the model from scratch. This work proposes stochastic gradient Langevin unlearning, the first unlearning framework based on noisy stochastic gradient descent (SGD) with privacy guarantees for approximate unlearning problems under convexity assumption. Our results show that mini-batch gradient updates provide a superior privacy-complexity trade-off compared to the full-batch counterpart. There are numerous algorithmic benefits of our unlearning approach, including complexity saving compared to retraining, and supporting sequential and batch unlearning. To examine the privacy-utility-complexity trade-off of our method, we conduct experiments on benchmark datasets compared against prior works. Our approach achieves a similar utility under the same privacy constraint while using $2\%$ and $10\%$ of the gradient computations compared with the state-of-the-art gradient-based approximate unlearning methods for mini-batch and full-batch settings, respectively.
Subequivariant Reinforcement Learning Framework for Coordinated Motion Control
Mar 22, 2024Effective coordination is crucial for motion control with reinforcement learning, especially as the complexity of agents and their motions increases. However, many existing methods struggle to account for the intricate dependencies between joints. We introduce CoordiGraph, a novel architecture that leverages subequivariant principles from physics to enhance coordination of motion control with reinforcement learning. This method embeds the principles of equivariance as inherent patterns in the learning process under gravity influence, which aids in modeling the nuanced relationships between joints vital for motion control. Through extensive experimentation with sophisticated agents in diverse environments, we highlight the merits of our approach. Compared to current leading methods, CoordiGraph notably enhances generalization and sample efficiency.
DL2Fence: Integrating Deep Learning and Frame Fusion for Enhanced Detection and Localization of Refined Denial-of-Service in Large-Scale NoCs
Mar 20, 2024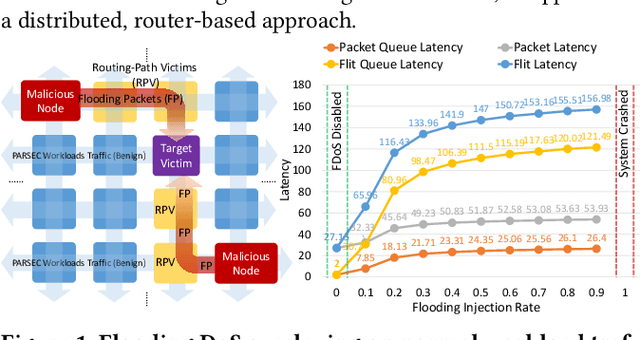
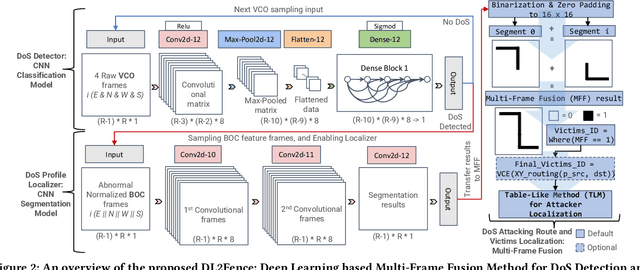
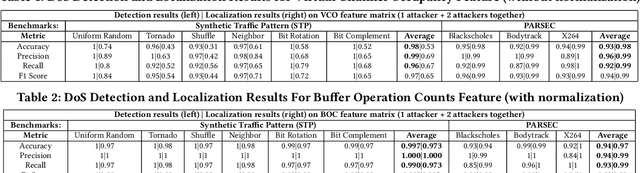

This study introduces a refined Flooding Injection Rate-adjustable Denial-of-Service (DoS) model for Network-on-Chips (NoCs) and more importantly presents DL2Fence, a novel framework utilizing Deep Learning (DL) and Frame Fusion (2F) for DoS detection and localization. Two Convolutional Neural Networks models for classification and segmentation were developed to detect and localize DoS respectively. It achieves detection and localization accuracies of 95.8\% and 91.7\%, and precision rates of 98.5\% and 99.3\% in a 16x16 mesh NoC. The framework's hardware overhead notably decreases by 76.3\% when scaling from 8x8 to 16x16 NoCs, and it requires 42.4\% less hardware compared to state-of-the-arts. This advancement demonstrates DL2Fence's effectiveness in balancing outstanding detection performance in large-scale NoCs with extremely low hardware overhead.
NNCTC: Physical Layer Cross-Technology Communication via Neural Networks
Mar 15, 2024
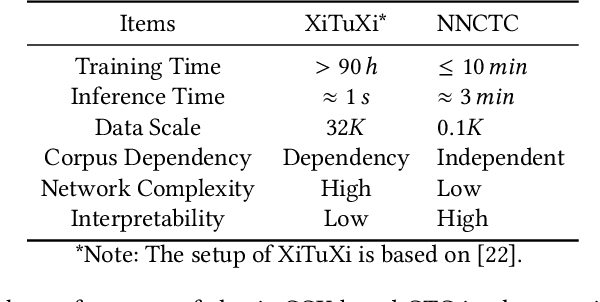
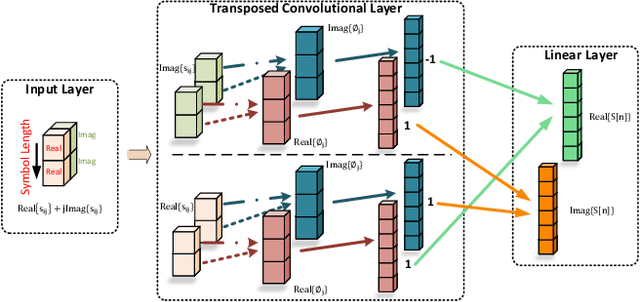
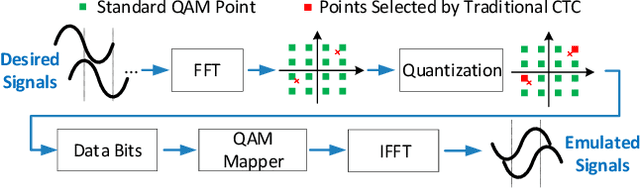
Cross-technology communication(CTC) enables seamless interactions between diverse wireless technologies. Most existing work is based on reversing the transmission path to identify the appropriate payload to generate the waveform that the target devices can recognize. However, this method suffers from many limitations, including dependency on specific technologies and the necessity for intricate algorithms to mitigate distortion. In this work, we present NNCTC, a Neural-Network-based Cross-Technology Communication framework inspired by the adaptability of trainable neural models in wireless communications. By converting signal processing components within the CTC pipeline into neural models, the NNCTC is designed for end-to-end training without requiring labeled data. This enables the NNCTC system to autonomously derive the optimal CTC payload, which significantly eases the development complexity and showcases the scalability potential for various CTC links. Particularly, we construct a CTC system from Wi-Fi to ZigBee. The NNCTC system outperforms the well-recognized WEBee and WIDE design in error performance, achieving an average packet reception rate(PRR) of 92.3% and an average symbol error rate(SER) as low as 1.3%.
Logic Rules as Explanations for Legal Case Retrieval
Mar 03, 2024
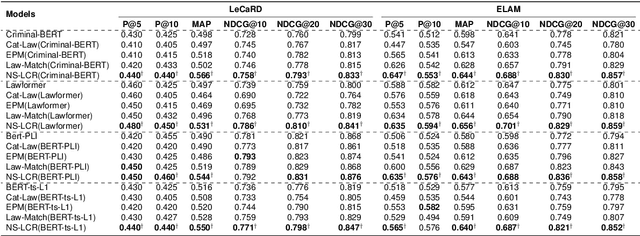
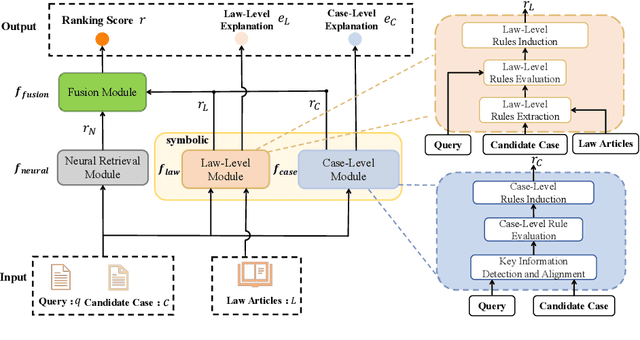
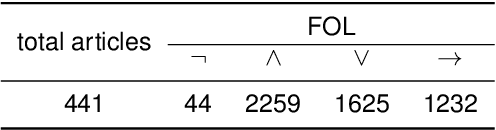
In this paper, we address the issue of using logic rules to explain the results from legal case retrieval. The task is critical to legal case retrieval because the users (e.g., lawyers or judges) are highly specialized and require the system to provide logical, faithful, and interpretable explanations before making legal decisions. Recently, research efforts have been made to learn explainable legal case retrieval models. However, these methods usually select rationales (key sentences) from the legal cases as explanations, failing to provide faithful and logically correct explanations. In this paper, we propose Neural-Symbolic enhanced Legal Case Retrieval (NS-LCR), a framework that explicitly conducts reasoning on the matching of legal cases through learning case-level and law-level logic rules. The learned rules are then integrated into the retrieval process in a neuro-symbolic manner. Benefiting from the logic and interpretable nature of the logic rules, NS-LCR is equipped with built-in faithful explainability. We also show that NS-LCR is a model-agnostic framework that can be plugged in for multiple legal retrieval models. To showcase NS-LCR's superiority, we enhance existing benchmarks by adding manually annotated logic rules and introducing a novel explainability metric using Large Language Models (LLMs). Our comprehensive experiments reveal NS-LCR's effectiveness for ranking, alongside its proficiency in delivering reliable explanations for legal case retrieval.
PRSA: Prompt Reverse Stealing Attacks against Large Language Models
Feb 29, 2024Prompt, recognized as crucial intellectual property, enables large language models (LLMs) to perform specific tasks without the need of fine-tuning, underscoring their escalating importance. With the rise of prompt-based services, such as prompt marketplaces and LLM applications, providers often display prompts' capabilities through input-output examples to attract users. However, this paradigm raises a pivotal security concern: does the exposure of input-output pairs pose the risk of potential prompt leakage, infringing on the intellectual property rights of the developers? To our knowledge, this problem still has not been comprehensively explored yet. To remedy this gap, in this paper, we perform the first in depth exploration and propose a novel attack framework for reverse-stealing prompts against commercial LLMs, namely PRSA. The main idea of PRSA is that by analyzing the critical features of the input-output pairs, we mimic and gradually infer (steal) the target prompts. In detail, PRSA mainly consists of two key phases: prompt mutation and prompt pruning. In the mutation phase, we propose a prompt attention algorithm based on differential feedback to capture these critical features for effectively inferring the target prompts. In the prompt pruning phase, we identify and mask the words dependent on specific inputs, enabling the prompts to accommodate diverse inputs for generalization. Through extensive evaluation, we verify that PRSA poses a severe threat in real world scenarios. We have reported these findings to prompt service providers and actively collaborate with them to take protective measures for prompt copyright.