 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYi Jiang
Groma: Localized Visual Tokenization for Grounding Multimodal Large Language Models
Apr 19, 2024
We introduce Groma, a Multimodal Large Language Model (MLLM) with grounded and fine-grained visual perception ability. Beyond holistic image understanding, Groma is adept at region-level tasks such as region captioning and visual grounding. Such capabilities are built upon a localized visual tokenization mechanism, where an image input is decomposed into regions of interest and subsequently encoded into region tokens. By integrating region tokens into user instructions and model responses, we seamlessly enable Groma to understand user-specified region inputs and ground its textual output to images. Besides, to enhance the grounded chat ability of Groma, we curate a visually grounded instruction dataset by leveraging the powerful GPT-4V and visual prompting techniques. Compared with MLLMs that rely on the language model or external module for localization, Groma consistently demonstrates superior performances in standard referring and grounding benchmarks, highlighting the advantages of embedding localization into image tokenization. Project page: https://groma-mllm.github.io/.
Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
Apr 03, 2024We present Visual AutoRegressive modeling (VAR), a new generation paradigm that redefines the autoregressive learning on images as coarse-to-fine "next-scale prediction" or "next-resolution prediction", diverging from the standard raster-scan "next-token prediction". This simple, intuitive methodology allows autoregressive (AR) transformers to learn visual distributions fast and generalize well: VAR, for the first time, makes AR models surpass diffusion transformers in image generation. On ImageNet 256x256 benchmark, VAR significantly improve AR baseline by improving Frechet inception distance (FID) from 18.65 to 1.80, inception score (IS) from 80.4 to 356.4, with around 20x faster inference speed. It is also empirically verified that VAR outperforms the Diffusion Transformer (DiT) in multiple dimensions including image quality, inference speed, data efficiency, and scalability. Scaling up VAR models exhibits clear power-law scaling laws similar to those observed in LLMs, with linear correlation coefficients near -0.998 as solid evidence. VAR further showcases zero-shot generalization ability in downstream tasks including image in-painting, out-painting, and editing. These results suggest VAR has initially emulated the two important properties of LLMs: Scaling Laws and zero-shot task generalization. We have released all models and codes to promote the exploration of AR/VAR models for visual generation and unified learning.
Generative Region-Language Pretraining for Open-Ended Object Detection
Mar 15, 2024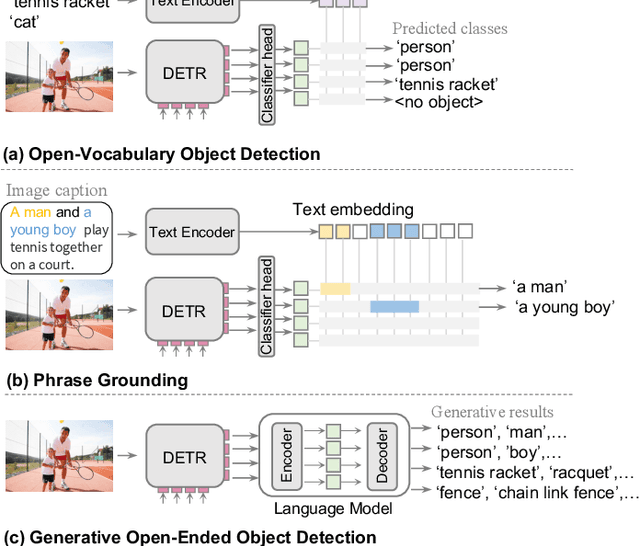


In recent research, significant attention has been devoted to the open-vocabulary object detection task, aiming to generalize beyond the limited number of classes labeled during training and detect objects described by arbitrary category names at inference. Compared with conventional object detection, open vocabulary object detection largely extends the object detection categories. However, it relies on calculating the similarity between image regions and a set of arbitrary category names with a pretrained vision-and-language model. This implies that, despite its open-set nature, the task still needs the predefined object categories during the inference stage. This raises the question: What if we do not have exact knowledge of object categories during inference? In this paper, we call such a new setting as generative open-ended object detection, which is a more general and practical problem. To address it, we formulate object detection as a generative problem and propose a simple framework named GenerateU, which can detect dense objects and generate their names in a free-form way. Particularly, we employ Deformable DETR as a region proposal generator with a language model translating visual regions to object names. To assess the free-form object detection task, we introduce an evaluation method designed to quantitatively measure the performance of generative outcomes. Extensive experiments demonstrate strong zero-shot detection performance of our GenerateU. For example, on the LVIS dataset, our GenerateU achieves comparable results to the open-vocabulary object detection method GLIP, even though the category names are not seen by GenerateU during inference. Code is available at: https:// github.com/FoundationVision/GenerateU .
PRSA: Prompt Reverse Stealing Attacks against Large Language Models
Feb 29, 2024Prompt, recognized as crucial intellectual property, enables large language models (LLMs) to perform specific tasks without the need of fine-tuning, underscoring their escalating importance. With the rise of prompt-based services, such as prompt marketplaces and LLM applications, providers often display prompts' capabilities through input-output examples to attract users. However, this paradigm raises a pivotal security concern: does the exposure of input-output pairs pose the risk of potential prompt leakage, infringing on the intellectual property rights of the developers? To our knowledge, this problem still has not been comprehensively explored yet. To remedy this gap, in this paper, we perform the first in depth exploration and propose a novel attack framework for reverse-stealing prompts against commercial LLMs, namely PRSA. The main idea of PRSA is that by analyzing the critical features of the input-output pairs, we mimic and gradually infer (steal) the target prompts. In detail, PRSA mainly consists of two key phases: prompt mutation and prompt pruning. In the mutation phase, we propose a prompt attention algorithm based on differential feedback to capture these critical features for effectively inferring the target prompts. In the prompt pruning phase, we identify and mask the words dependent on specific inputs, enabling the prompts to accommodate diverse inputs for generalization. Through extensive evaluation, we verify that PRSA poses a severe threat in real world scenarios. We have reported these findings to prompt service providers and actively collaborate with them to take protective measures for prompt copyright.
Unsupervised Learning Method for the Wave Equation Based on Finite Difference Residual Constraints Loss
Jan 23, 2024The wave equation is an important physical partial differential equation, and in recent years, deep learning has shown promise in accelerating or replacing traditional numerical methods for solving it. However, existing deep learning methods suffer from high data acquisition costs, low training efficiency, and insufficient generalization capability for boundary conditions. To address these issues, this paper proposes an unsupervised learning method for the wave equation based on finite difference residual constraints. We construct a novel finite difference residual constraint based on structured grids and finite difference methods, as well as an unsupervised training strategy, enabling convolutional neural networks to train without data and predict the forward propagation process of waves. Experimental results show that finite difference residual constraints have advantages over physics-informed neural networks (PINNs) type physical information constraints, such as easier fitting, lower computational costs, and stronger source term generalization capability, making our method more efficient in training and potent in application.
UniRef++: Segment Every Reference Object in Spatial and Temporal Spaces
Dec 25, 2023The reference-based object segmentation tasks, namely referring image segmentation (RIS), few-shot image segmentation (FSS), referring video object segmentation (RVOS), and video object segmentation (VOS), aim to segment a specific object by utilizing either language or annotated masks as references. Despite significant progress in each respective field, current methods are task-specifically designed and developed in different directions, which hinders the activation of multi-task capabilities for these tasks. In this work, we end the current fragmented situation and propose UniRef++ to unify the four reference-based object segmentation tasks with a single architecture. At the heart of our approach is the proposed UniFusion module which performs multiway-fusion for handling different tasks with respect to their specified references. And a unified Transformer architecture is then adopted for achieving instance-level segmentation. With the unified designs, UniRef++ can be jointly trained on a broad range of benchmarks and can flexibly complete multiple tasks at run-time by specifying the corresponding references. We evaluate our unified models on various benchmarks. Extensive experimental results indicate that our proposed UniRef++ achieves state-of-the-art performance on RIS and RVOS, and performs competitively on FSS and VOS with a parameter-shared network. Moreover, we showcase that the proposed UniFusion module could be easily incorporated into the current advanced foundation model SAM and obtain satisfactory results with parameter-efficient finetuning. Codes and models are available at \url{https://github.com/FoundationVision/UniRef}.
Incomplete Contrastive Multi-View Clustering with High-Confidence Guiding
Dec 14, 2023
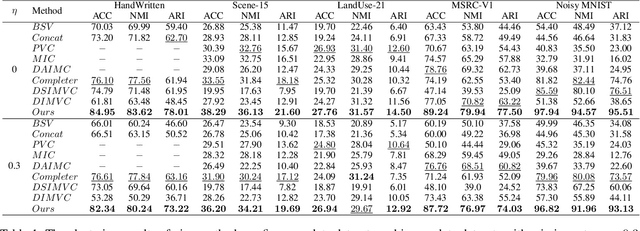

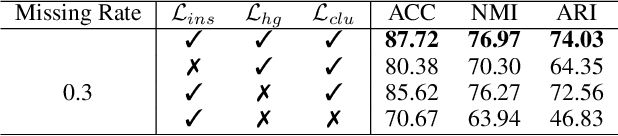
Incomplete multi-view clustering becomes an important research problem, since multi-view data with missing values are ubiquitous in real-world applications. Although great efforts have been made for incomplete multi-view clustering, there are still some challenges: 1) most existing methods didn't make full use of multi-view information to deal with missing values; 2) most methods just employ the consistent information within multi-view data but ignore the complementary information; 3) For the existing incomplete multi-view clustering methods, incomplete multi-view representation learning and clustering are treated as independent processes, which leads to performance gap. In this work, we proposed a novel Incomplete Contrastive Multi-View Clustering method with high-confidence guiding (ICMVC). Firstly, we proposed a multi-view consistency relation transfer plus graph convolutional network to tackle missing values problem. Secondly, instance-level attention fusion and high-confidence guiding are proposed to exploit the complementary information while instance-level contrastive learning for latent representation is designed to employ the consistent information. Thirdly, an end-to-end framework is proposed to integrate multi-view missing values handling, multi-view representation learning and clustering assignment for joint optimization. Experiments compared with state-of-the-art approaches demonstrated the effectiveness and superiority of our method. Our code is publicly available at https://github.com/liunian-Jay/ICMVC.
General Object Foundation Model for Images and Videos at Scale
Dec 14, 2023We present GLEE in this work, an object-level foundation model for locating and identifying objects in images and videos. Through a unified framework, GLEE accomplishes detection, segmentation, tracking, grounding, and identification of arbitrary objects in the open world scenario for various object perception tasks. Adopting a cohesive learning strategy, GLEE acquires knowledge from diverse data sources with varying supervision levels to formulate general object representations, excelling in zero-shot transfer to new data and tasks. Specifically, we employ an image encoder, text encoder, and visual prompter to handle multi-modal inputs, enabling to simultaneously solve various object-centric downstream tasks while maintaining state-of-the-art performance. Demonstrated through extensive training on over five million images from diverse benchmarks, GLEE exhibits remarkable versatility and improved generalization performance, efficiently tackling downstream tasks without the need for task-specific adaptation. By integrating large volumes of automatically labeled data, we further enhance its zero-shot generalization capabilities. Additionally, GLEE is capable of being integrated into Large Language Models, serving as a foundational model to provide universal object-level information for multi-modal tasks. We hope that the versatility and universality of our method will mark a significant step in the development of efficient visual foundation models for AGI systems. The model and code will be released at https://glee-vision.github.io .
Recognize Any Regions
Nov 02, 2023Understanding the semantics of individual regions or patches within unconstrained images, such as in open-world object detection, represents a critical yet challenging task in computer vision. Building on the success of powerful image-level vision-language (ViL) foundation models like CLIP, recent efforts have sought to harness their capabilities by either training a contrastive model from scratch with an extensive collection of region-label pairs or aligning the outputs of a detection model with image-level representations of region proposals. Despite notable progress, these approaches are plagued by computationally intensive training requirements, susceptibility to data noise, and deficiency in contextual information. To address these limitations, we explore the synergistic potential of off-the-shelf foundation models, leveraging their respective strengths in localization and semantics. We introduce a novel, generic, and efficient region recognition architecture, named RegionSpot, designed to integrate position-aware localization knowledge from a localization foundation model (e.g., SAM) with semantic information extracted from a ViL model (e.g., CLIP). To fully exploit pretrained knowledge while minimizing training overhead, we keep both foundation models frozen, focusing optimization efforts solely on a lightweight attention-based knowledge integration module. Through extensive experiments in the context of open-world object recognition, our RegionSpot demonstrates significant performance improvements over prior alternatives, while also providing substantial computational savings. For instance, training our model with 3 million data in a single day using 8 V100 GPUs. Our model outperforms GLIP by 6.5 % in mean average precision (mAP), with an even larger margin by 14.8 % for more challenging and rare categories.
CoDet: Co-Occurrence Guided Region-Word Alignment for Open-Vocabulary Object Detection
Oct 25, 2023
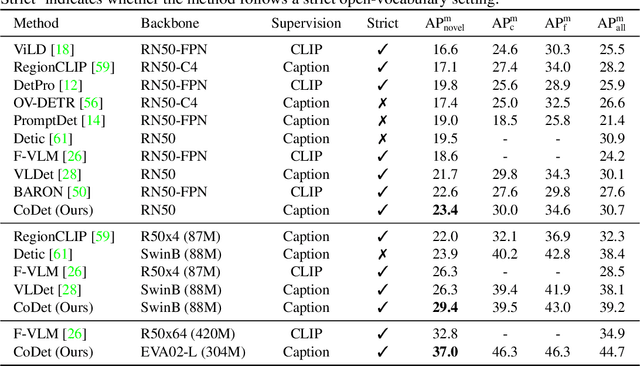
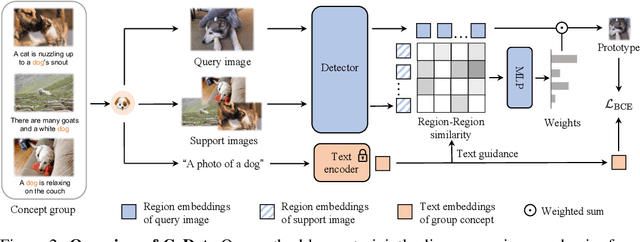
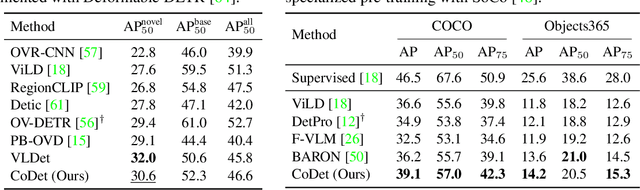
Deriving reliable region-word alignment from image-text pairs is critical to learn object-level vision-language representations for open-vocabulary object detection. Existing methods typically rely on pre-trained or self-trained vision-language models for alignment, which are prone to limitations in localization accuracy or generalization capabilities. In this paper, we propose CoDet, a novel approach that overcomes the reliance on pre-aligned vision-language space by reformulating region-word alignment as a co-occurring object discovery problem. Intuitively, by grouping images that mention a shared concept in their captions, objects corresponding to the shared concept shall exhibit high co-occurrence among the group. CoDet then leverages visual similarities to discover the co-occurring objects and align them with the shared concept. Extensive experiments demonstrate that CoDet has superior performances and compelling scalability in open-vocabulary detection, e.g., by scaling up the visual backbone, CoDet achieves 37.0 $\text{AP}^m_{novel}$ and 44.7 $\text{AP}^m_{all}$ on OV-LVIS, surpassing the previous SoTA by 4.2 $\text{AP}^m_{novel}$ and 9.8 $\text{AP}^m_{all}$. Code is available at https://github.com/CVMI-Lab/CoDet.