 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEli Chien
Stochastic Gradient Langevin Unlearning
Mar 25, 2024
``The right to be forgotten'' ensured by laws for user data privacy becomes increasingly important. Machine unlearning aims to efficiently remove the effect of certain data points on the trained model parameters so that it can be approximately the same as if one retrains the model from scratch. This work proposes stochastic gradient Langevin unlearning, the first unlearning framework based on noisy stochastic gradient descent (SGD) with privacy guarantees for approximate unlearning problems under convexity assumption. Our results show that mini-batch gradient updates provide a superior privacy-complexity trade-off compared to the full-batch counterpart. There are numerous algorithmic benefits of our unlearning approach, including complexity saving compared to retraining, and supporting sequential and batch unlearning. To examine the privacy-utility-complexity trade-off of our method, we conduct experiments on benchmark datasets compared against prior works. Our approach achieves a similar utility under the same privacy constraint while using $2\%$ and $10\%$ of the gradient computations compared with the state-of-the-art gradient-based approximate unlearning methods for mini-batch and full-batch settings, respectively.
Machine Unlearning of Pre-trained Large Language Models
Feb 27, 2024This study investigates the concept of the `right to be forgotten' within the context of large language models (LLMs). We explore machine unlearning as a pivotal solution, with a focus on pre-trained models--a notably under-researched area. Our research delineates a comprehensive framework for machine unlearning in pre-trained LLMs, encompassing a critical analysis of seven diverse unlearning methods. Through rigorous evaluation using curated datasets from arXiv, books, and GitHub, we establish a robust benchmark for unlearning performance, demonstrating that these methods are over $10^5$ times more computationally efficient than retraining. Our results show that integrating gradient ascent with gradient descent on in-distribution data improves hyperparameter robustness. We also provide detailed guidelines for efficient hyperparameter tuning in the unlearning process. Our findings advance the discourse on ethical AI practices, offering substantive insights into the mechanics of machine unlearning for pre-trained LLMs and underscoring the potential for responsible AI development.
Langevin Unlearning: A New Perspective of Noisy Gradient Descent for Machine Unlearning
Feb 01, 2024Machine unlearning has raised significant interest with the adoption of laws ensuring the ``right to be forgotten''. Researchers have provided a probabilistic notion of approximate unlearning under a similar definition of Differential Privacy (DP), where privacy is defined as statistical indistinguishability to retraining from scratch. We propose Langevin unlearning, an unlearning framework based on noisy gradient descent with privacy guarantees for approximate unlearning problems. Langevin unlearning unifies the DP learning process and the privacy-certified unlearning process with many algorithmic benefits. These include approximate certified unlearning for non-convex problems, complexity saving compared to retraining, sequential and batch unlearning for multiple unlearning requests. We verify the practicality of Langevin unlearning by studying its privacy-utility-complexity trade-off via experiments on benchmark datasets, and also demonstrate its superiority against gradient-decent-plus-output-perturbation based approximate unlearning.
Breaking the Trilemma of Privacy, Utility, Efficiency via Controllable Machine Unlearning
Oct 28, 2023Machine Unlearning (MU) algorithms have become increasingly critical due to the imperative adherence to data privacy regulations. The primary objective of MU is to erase the influence of specific data samples on a given model without the need to retrain it from scratch. Accordingly, existing methods focus on maximizing user privacy protection. However, there are different degrees of privacy regulations for each real-world web-based application. Exploring the full spectrum of trade-offs between privacy, model utility, and runtime efficiency is critical for practical unlearning scenarios. Furthermore, designing the MU algorithm with simple control of the aforementioned trade-off is desirable but challenging due to the inherent complex interaction. To address the challenges, we present Controllable Machine Unlearning (ConMU), a novel framework designed to facilitate the calibration of MU. The ConMU framework contains three integral modules: an important data selection module that reconciles the runtime efficiency and model generalization, a progressive Gaussian mechanism module that balances privacy and model generalization, and an unlearning proxy that controls the trade-offs between privacy and runtime efficiency. Comprehensive experiments on various benchmark datasets have demonstrated the robust adaptability of our control mechanism and its superiority over established unlearning methods. ConMU explores the full spectrum of the Privacy-Utility-Efficiency trade-off and allows practitioners to account for different real-world regulations. Source code available at: https://github.com/guangyaodou/ConMU.
On the Inherent Privacy Properties of Discrete Denoising Diffusion Models
Oct 24, 2023Privacy concerns have led to a surge in the creation of synthetic datasets, with diffusion models emerging as a promising avenue. Although prior studies have performed empirical evaluations on these models, there has been a gap in providing a mathematical characterization of their privacy-preserving capabilities. To address this, we present the pioneering theoretical exploration of the privacy preservation inherent in discrete diffusion models (DDMs) for discrete dataset generation. Focusing on per-instance differential privacy (pDP), our framework elucidates the potential privacy leakage for each data point in a given training dataset, offering insights into data preprocessing to reduce privacy risks of the synthetic dataset generation via DDMs. Our bounds also show that training with $s$-sized data points leads to a surge in privacy leakage from $(\epsilon, \mathcal{O}(\frac{1}{s^2\epsilon}))$-pDP to $(\epsilon, \mathcal{O}(\frac{1}{s\epsilon}))$-pDP during the transition from the pure noise to the synthetic clean data phase, and a faster decay in diffusion coefficients amplifies the privacy guarantee. Finally, we empirically verify our theoretical findings on both synthetic and real-world datasets.
Federated Classification in Hyperbolic Spaces via Secure Aggregation of Convex Hulls
Aug 14, 2023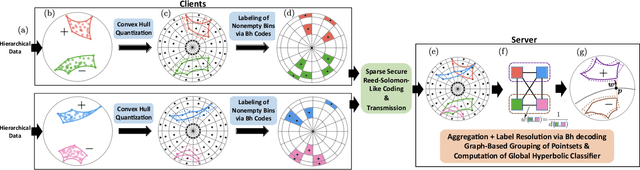
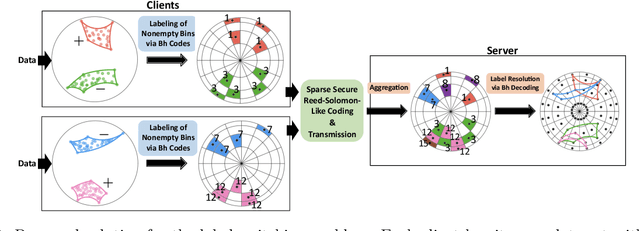

Hierarchical and tree-like data sets arise in many applications, including language processing, graph data mining, phylogeny and genomics. It is known that tree-like data cannot be embedded into Euclidean spaces of finite dimension with small distortion. This problem can be mitigated through the use of hyperbolic spaces. When such data also has to be processed in a distributed and privatized setting, it becomes necessary to work with new federated learning methods tailored to hyperbolic spaces. As an initial step towards the development of the field of federated learning in hyperbolic spaces, we propose the first known approach to federated classification in hyperbolic spaces. Our contributions are as follows. First, we develop distributed versions of convex SVM classifiers for Poincar\'e discs. In this setting, the information conveyed from clients to the global classifier are convex hulls of clusters present in individual client data. Second, to avoid label switching issues, we introduce a number-theoretic approach for label recovery based on the so-called integer $B_h$ sequences. Third, we compute the complexity of the convex hulls in hyperbolic spaces to assess the extent of data leakage; at the same time, in order to limit the communication cost for the hulls, we propose a new quantization method for the Poincar\'e disc coupled with Reed-Solomon-like encoding. Fourth, at server level, we introduce a new approach for aggregating convex hulls of the clients based on balanced graph partitioning. We test our method on a collection of diverse data sets, including hierarchical single-cell RNA-seq data from different patients distributed across different repositories that have stringent privacy constraints. The classification accuracy of our method is up to $\sim 11\%$ better than its Euclidean counterpart, demonstrating the importance of privacy-preserving learning in hyperbolic spaces.
Differentially Private Decoupled Graph Convolutions for Multigranular Topology Protection
Jul 12, 2023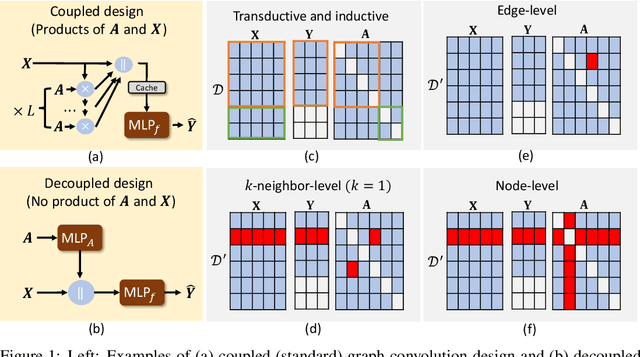

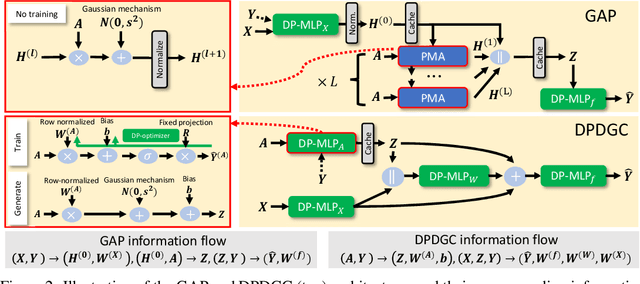
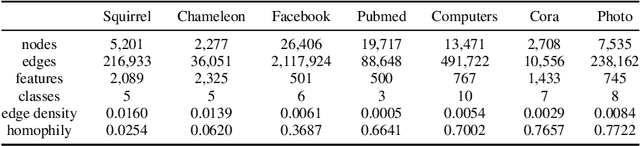
Graph learning methods, such as Graph Neural Networks (GNNs) based on graph convolutions, are highly successful in solving real-world learning problems involving graph-structured data. However, graph learning methods expose sensitive user information and interactions not only through their model parameters but also through their model predictions. Consequently, standard Differential Privacy (DP) techniques that merely offer model weight privacy are inadequate. This is especially the case for node predictions that leverage neighboring node attributes directly via graph convolutions that create additional risks of privacy leakage. To address this problem, we introduce Graph Differential Privacy (GDP), a new formal DP framework tailored to graph learning settings that ensures both provably private model parameters and predictions. Furthermore, since there may be different privacy requirements for the node attributes and graph structure, we introduce a novel notion of relaxed node-level data adjacency. This relaxation can be used for establishing guarantees for different degrees of graph topology privacy while maintaining node attribute privacy. Importantly, this relaxation reveals a useful trade-off between utility and topology privacy for graph learning methods. In addition, our analysis of GDP reveals that existing DP-GNNs fail to exploit this trade-off due to the complex interplay between graph topology and attribute data in standard graph convolution designs. To mitigate this problem, we introduce the Differentially Private Decoupled Graph Convolution (DPDGC) model, which benefits from decoupled graph convolution while providing GDP guarantees. Extensive experiments on seven node classification benchmarking datasets demonstrate the superior privacy-utility trade-off of DPDGC over existing DP-GNNs based on standard graph convolution design.
Representer Point Selection for Explaining Regularized High-dimensional Models
May 31, 2023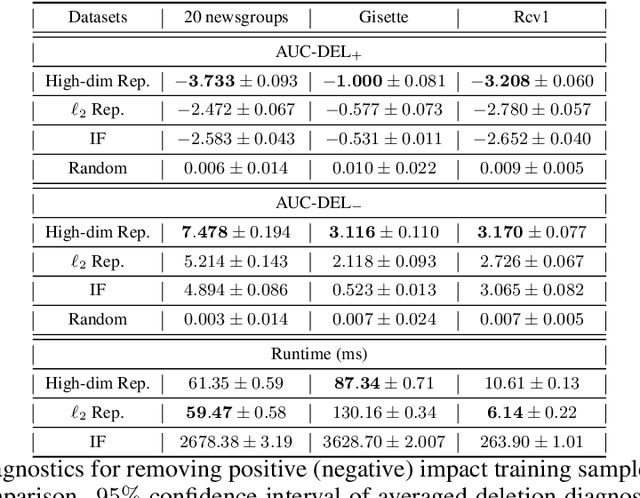
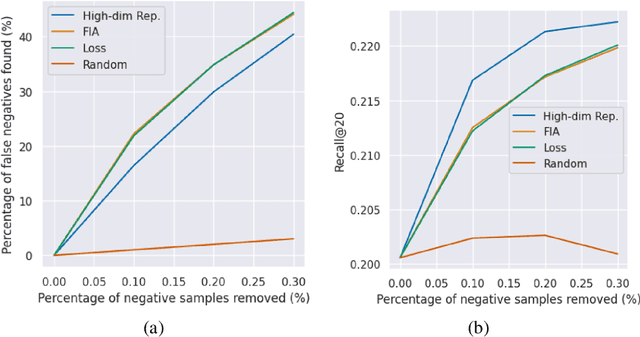
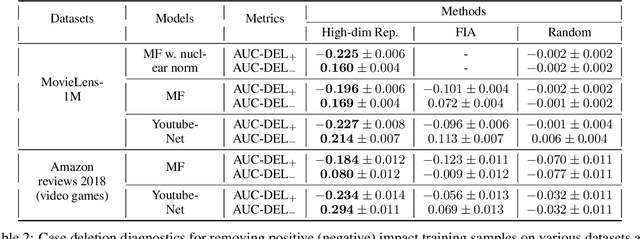
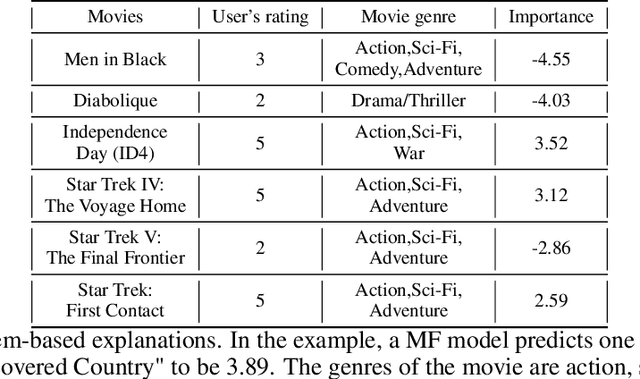
We introduce a novel class of sample-based explanations we term high-dimensional representers, that can be used to explain the predictions of a regularized high-dimensional model in terms of importance weights for each of the training samples. Our workhorse is a novel representer theorem for general regularized high-dimensional models, which decomposes the model prediction in terms of contributions from each of the training samples: with positive (negative) values corresponding to positive (negative) impact training samples to the model's prediction. We derive consequences for the canonical instances of $\ell_1$ regularized sparse models, and nuclear norm regularized low-rank models. As a case study, we further investigate the application of low-rank models in the context of collaborative filtering, where we instantiate high-dimensional representers for specific popular classes of models. Finally, we study the empirical performance of our proposed methods on three real-world binary classification datasets and two recommender system datasets. We also showcase the utility of high-dimensional representers in explaining model recommendations.
PINA: Leveraging Side Information in eXtreme Multi-label Classification via Predicted Instance Neighborhood Aggregation
May 21, 2023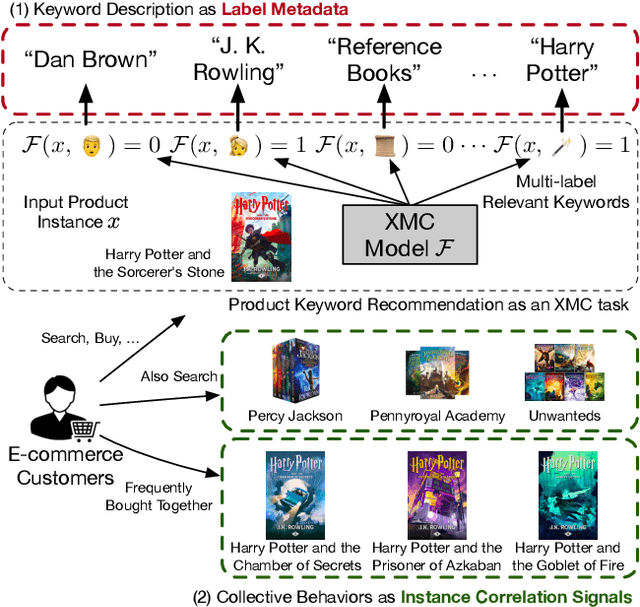
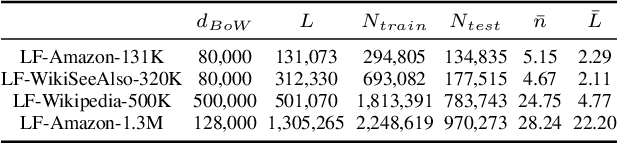
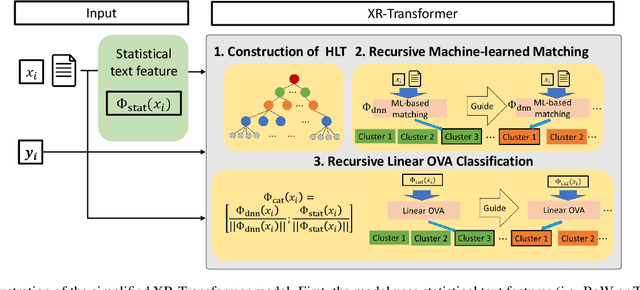
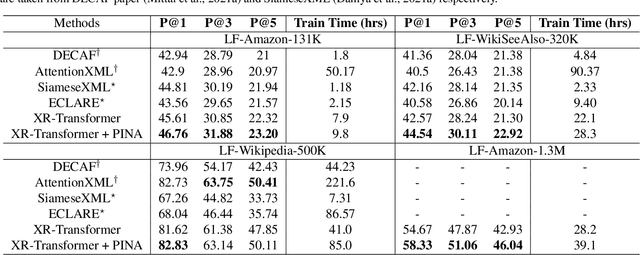
The eXtreme Multi-label Classification~(XMC) problem seeks to find relevant labels from an exceptionally large label space. Most of the existing XMC learners focus on the extraction of semantic features from input query text. However, conventional XMC studies usually neglect the side information of instances and labels, which can be of use in many real-world applications such as recommendation systems and e-commerce product search. We propose Predicted Instance Neighborhood Aggregation (PINA), a data enhancement method for the general XMC problem that leverages beneficial side information. Unlike most existing XMC frameworks that treat labels and input instances as featureless indicators and independent entries, PINA extracts information from the label metadata and the correlations among training instances. Extensive experimental results demonstrate the consistent gain of PINA on various XMC tasks compared to the state-of-the-art methods: PINA offers a gain in accuracy compared to standard XR-Transformers on five public benchmark datasets. Moreover, PINA achieves a $\sim 5\%$ gain in accuracy on the largest dataset LF-AmazonTitles-1.3M. Our implementation is publicly available.
Unlearning Nonlinear Graph Classifiers in the Limited Training Data Regime
Nov 06, 2022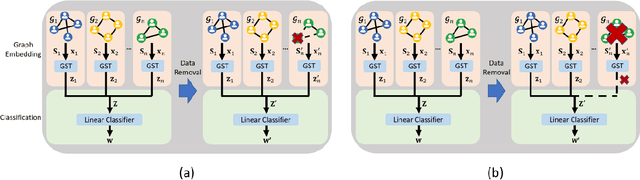



As the demand for user privacy grows, controlled data removal (machine unlearning) is becoming an important feature of machine learning models for data-sensitive Web applications such as social networks and recommender systems. Nevertheless, at this point it is still largely unknown how to perform efficient machine unlearning of graph neural networks (GNNs); this is especially the case when the number of training samples is small, in which case unlearning can seriously compromise the performance of the model. To address this issue, we initiate the study of unlearning the Graph Scattering Transform (GST), a mathematical framework that is efficient, provably stable under feature or graph topology perturbations, and offers graph classification performance comparable to that of GNNs. Our main contribution is the first known nonlinear approximate graph unlearning method based on GSTs. Our second contribution is a theoretical analysis of the computational complexity of the proposed unlearning mechanism, which is hard to replicate for deep neural networks. Our third contribution are extensive simulation results which show that, compared to complete retraining of GNNs after each removal request, the new GST-based approach offers, on average, a $10.38$x speed-up and leads to a $2.6$% increase in test accuracy during unlearning of $90$ out of $100$ training graphs from the IMDB dataset ($10$% training ratio).