 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChunhui Zhang
Study on the static detection of ICF target based on muonic X-ray sphere encoded imaging
Apr 18, 2024
Muon Induced X-ray Emission (MIXE) was discovered by Chinese physicist Zhang Wenyu as early as 1947, and it can conduct non-destructive elemental analysis inside samples. Research has shown that MIXE can retain the high efficiency of direct imaging while benefiting from the low noise of pinhole imaging through encoding holes. The related technology significantly improves the counting rate while maintaining imaging quality. The sphere encoding technology effectively solves the imaging blurring caused by the tilting of the encoding system, and successfully images micrometer sized X-ray sources. This paper will combine MIXE and X-ray sphere coding imaging techniques, including ball coding and zone plates, to study the method of non-destructive deep structure imaging of ICF targets and obtaining sub element distribution. This method aims to develop a new method for ICF target detection, which is particularly important for inertial confinement fusion. At the same time, this method can be used to detect and analyze materials that are difficult to penetrate or sensitive, and is expected to solve the problem of element resolution and imaging that traditional technologies cannot overcome. It will provide new methods for the future development of multiple fields such as particle physics, material science, and X-ray optics.
When Emotional Stimuli meet Prompt Designing: An Auto-Prompt Graphical Paradigm
Apr 16, 2024With the development of Large Language Models (LLM), numerous prompts have been proposed, each with a rich set of features and their own merits. This paper summarizes the prompt words for large language models (LLMs), categorizing them into stimulating and framework types, and proposes an Auto-Prompt Graphical Paradigm(APGP) that combines both stimulating and framework prompts to enhance the problem-solving capabilities of LLMs across multiple domains, then exemplifies it with a framework that adheres to this paradigm. The framework involves automated prompt generation and consideration of emotion-stimulus factors, guiding LLMs in problem abstraction, diversified solutions generation, comprehensive optimization, and self-verification after providing answers, ensuring solution accuracy. Compared to traditional stimuli and framework prompts, this framework integrates the advantages of both by adopting automated approaches inspired by APE work, overcoming the limitations of manually designed prompts. Test results on the ruozhiba and BBH datasets demonstrate that this framework can effectively improve the efficiency and accuracy of LLMs in problem-solving, paving the way for new applications of LLMs.
Breaking the Trilemma of Privacy, Utility, Efficiency via Controllable Machine Unlearning
Oct 28, 2023Machine Unlearning (MU) algorithms have become increasingly critical due to the imperative adherence to data privacy regulations. The primary objective of MU is to erase the influence of specific data samples on a given model without the need to retrain it from scratch. Accordingly, existing methods focus on maximizing user privacy protection. However, there are different degrees of privacy regulations for each real-world web-based application. Exploring the full spectrum of trade-offs between privacy, model utility, and runtime efficiency is critical for practical unlearning scenarios. Furthermore, designing the MU algorithm with simple control of the aforementioned trade-off is desirable but challenging due to the inherent complex interaction. To address the challenges, we present Controllable Machine Unlearning (ConMU), a novel framework designed to facilitate the calibration of MU. The ConMU framework contains three integral modules: an important data selection module that reconciles the runtime efficiency and model generalization, a progressive Gaussian mechanism module that balances privacy and model generalization, and an unlearning proxy that controls the trade-offs between privacy and runtime efficiency. Comprehensive experiments on various benchmark datasets have demonstrated the robust adaptability of our control mechanism and its superiority over established unlearning methods. ConMU explores the full spectrum of the Privacy-Utility-Efficiency trade-off and allows practitioners to account for different real-world regulations. Source code available at: https://github.com/guangyaodou/ConMU.
Promoting Fairness in GNNs: A Characterization of Stability
Sep 19, 2023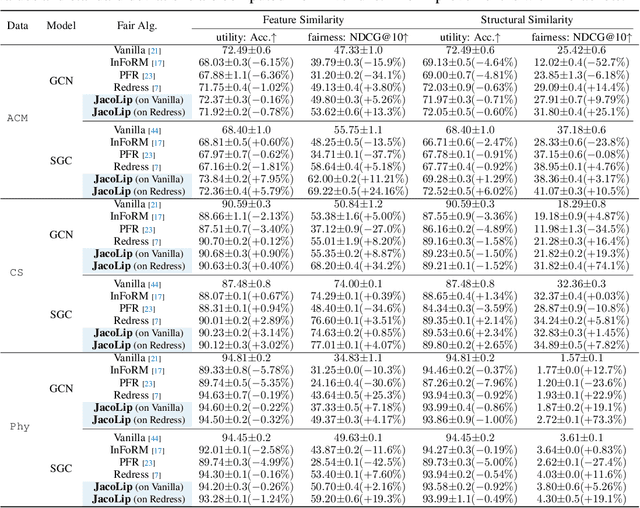
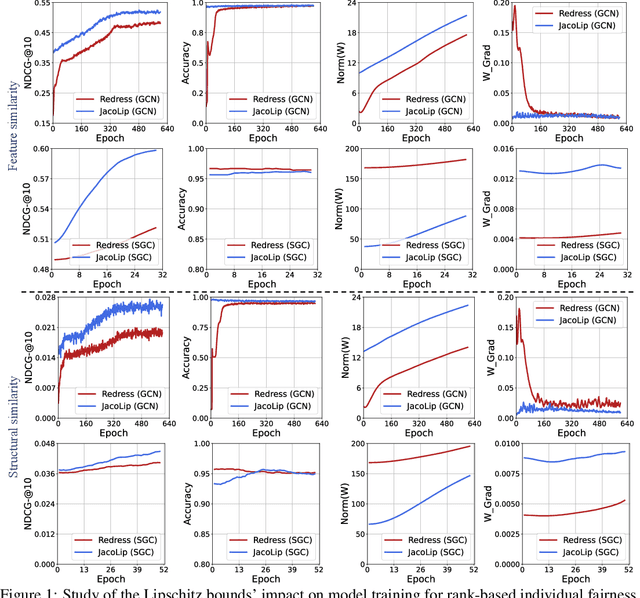
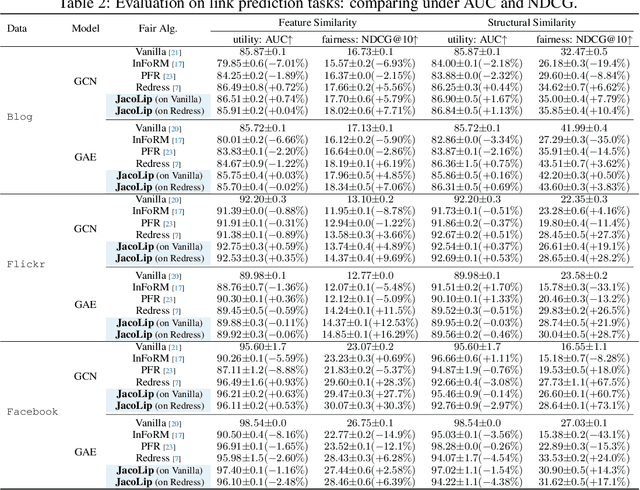
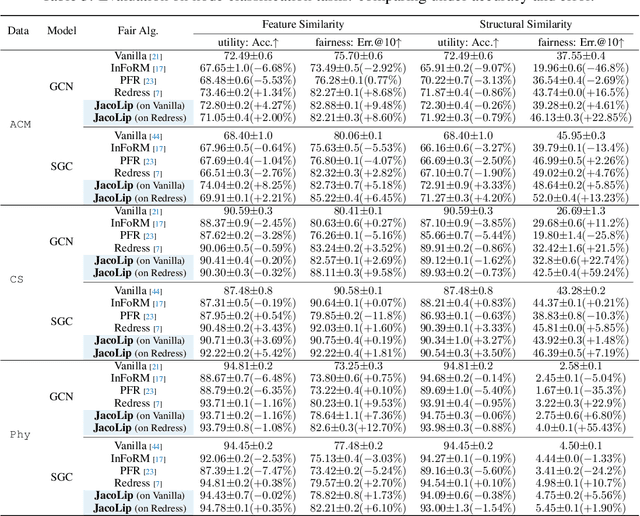
The Lipschitz bound, a technique from robust statistics, can limit the maximum changes in the output concerning the input, taking into account associated irrelevant biased factors. It is an efficient and provable method for examining the output stability of machine learning models without incurring additional computation costs. Recently, Graph Neural Networks (GNNs), which operate on non-Euclidean data, have gained significant attention. However, no previous research has investigated the GNN Lipschitz bounds to shed light on stabilizing model outputs, especially when working on non-Euclidean data with inherent biases. Given the inherent biases in common graph data used for GNN training, it poses a serious challenge to constraining the GNN output perturbations induced by input biases, thereby safeguarding fairness during training. Recently, despite the Lipschitz constant's use in controlling the stability of Euclideanneural networks, the calculation of the precise Lipschitz constant remains elusive for non-Euclidean neural networks like GNNs, especially within fairness contexts. To narrow this gap, we begin with the general GNNs operating on an attributed graph, and formulate a Lipschitz bound to limit the changes in the output regarding biases associated with the input. Additionally, we theoretically analyze how the Lipschitz constant of a GNN model could constrain the output perturbations induced by biases learned from data for fairness training. We experimentally validate the Lipschitz bound's effectiveness in limiting biases of the model output. Finally, from a training dynamics perspective, we demonstrate why the theoretical Lipschitz bound can effectively guide the GNN training to better trade-off between accuracy and fairness.
All in One: Exploring Unified Vision-Language Tracking with Multi-Modal Alignment
Jul 07, 2023
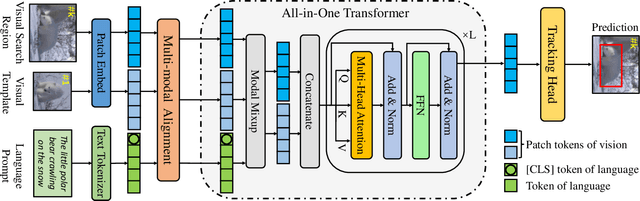
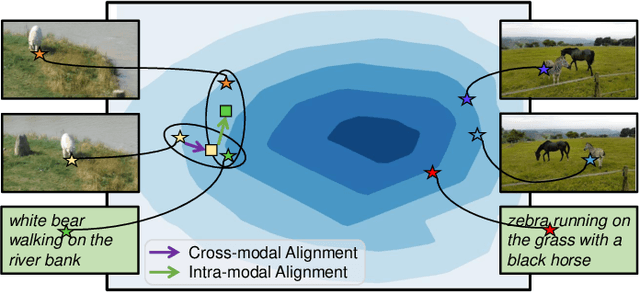
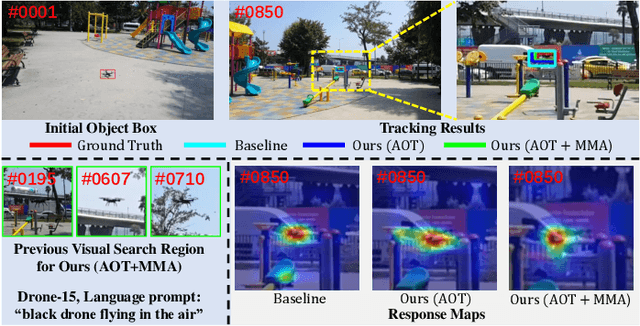
Current mainstream vision-language (VL) tracking framework consists of three parts, \ie a visual feature extractor, a language feature extractor, and a fusion model. To pursue better performance, a natural modus operandi for VL tracking is employing customized and heavier unimodal encoders, and multi-modal fusion models. Albeit effective, existing VL trackers separate feature extraction and feature integration, resulting in extracted features that lack semantic guidance and have limited target-aware capability in complex scenarios, \eg similar distractors and extreme illumination. In this work, inspired by the recent success of exploring foundation models with unified architecture for both natural language and computer vision tasks, we propose an All-in-One framework, which learns joint feature extraction and interaction by adopting a unified transformer backbone. Specifically, we mix raw vision and language signals to generate language-injected vision tokens, which we then concatenate before feeding into the unified backbone architecture. This approach achieves feature integration in a unified backbone, removing the need for carefully-designed fusion modules and resulting in a more effective and efficient VL tracking framework. To further improve the learning efficiency, we introduce a multi-modal alignment module based on cross-modal and intra-modal contrastive objectives, providing more reasonable representations for the unified All-in-One transformer backbone. Extensive experiments on five benchmarks, \ie OTB99-L, TNL2K, LaSOT, LaSOT$_{\rm Ext}$ and WebUAV-3M, demonstrate the superiority of the proposed tracker against existing state-of-the-arts on VL tracking. Codes will be made publicly available.
A Comprehensive Survey on Segment Anything Model for Vision and Beyond
May 19, 2023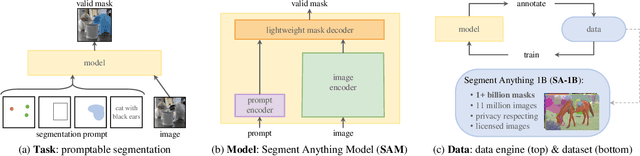

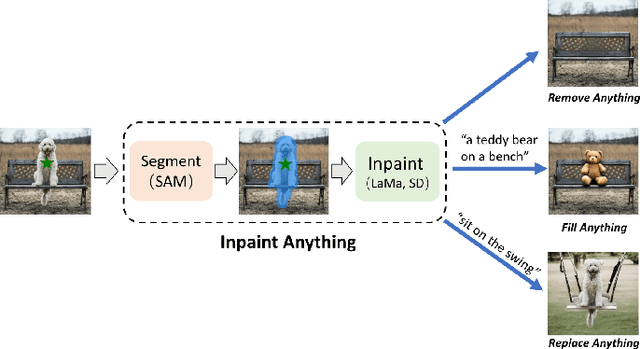
Artificial intelligence (AI) is evolving towards artificial general intelligence, which refers to the ability of an AI system to perform a wide range of tasks and exhibit a level of intelligence similar to that of a human being. This is in contrast to narrow or specialized AI, which is designed to perform specific tasks with a high degree of efficiency. Therefore, it is urgent to design a general class of models, which we term foundation models, trained on broad data that can be adapted to various downstream tasks. The recently proposed segment anything model (SAM) has made significant progress in breaking the boundaries of segmentation, greatly promoting the development of foundation models for computer vision. To fully comprehend SAM, we conduct a survey study. As the first to comprehensively review the progress of segmenting anything task for vision and beyond based on the foundation model of SAM, this work focuses on its applications to various tasks and data types by discussing its historical development, recent progress, and profound impact on broad applications. We first introduce the background and terminology for foundation models including SAM, as well as state-of-the-art methods contemporaneous with SAM that are significant for segmenting anything task. Then, we analyze and summarize the advantages and limitations of SAM across various image processing applications, including software scenes, real-world scenes, and complex scenes. Importantly, many insights are drawn to guide future research to develop more versatile foundation models and improve the architecture of SAM. We also summarize massive other amazing applications of SAM in vision and beyond. Finally, we maintain a continuously updated paper list and an open-source project summary for foundation model SAM at \href{https://github.com/liliu-avril/Awesome-Segment-Anything}{\color{magenta}{here}}.
Generating and Weighting Semantically Consistent Sample Pairs for Ultrasound Contrastive Learning
Dec 08, 2022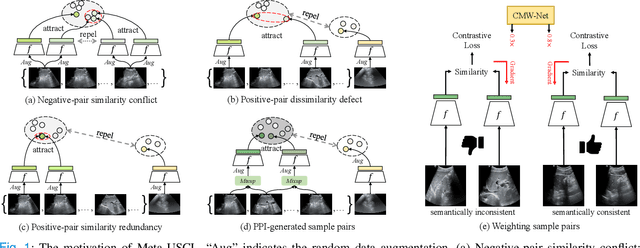
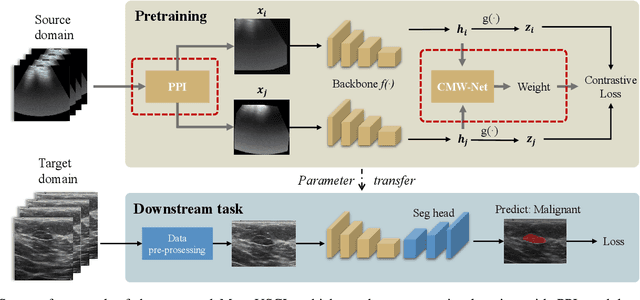
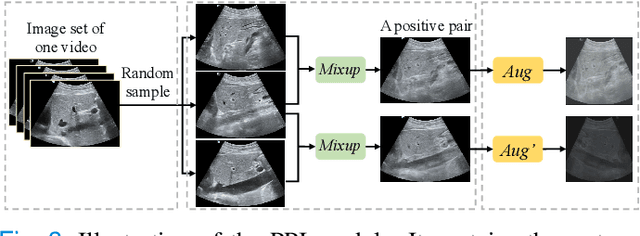
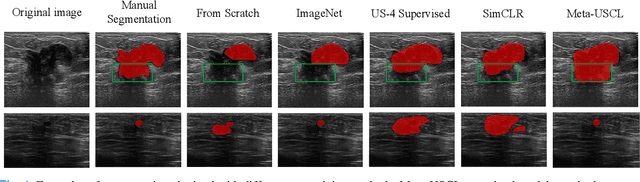
Well-annotated medical datasets enable deep neural networks (DNNs) to gain strong power in extracting lesion-related features. Building such large and well-designed medical datasets is costly due to the need for high-level expertise. Model pre-training based on ImageNet is a common practice to gain better generalization when the data amount is limited. However, it suffers from the domain gap between natural and medical images. In this work, we pre-train DNNs on ultrasound (US) domains instead of ImageNet to reduce the domain gap in medical US applications. To learn US image representations based on unlabeled US videos, we propose a novel meta-learning-based contrastive learning method, namely Meta Ultrasound Contrastive Learning (Meta-USCL). To tackle the key challenge of obtaining semantically consistent sample pairs for contrastive learning, we present a positive pair generation module along with an automatic sample weighting module based on meta-learning. Experimental results on multiple computer-aided diagnosis (CAD) problems, including pneumonia detection, breast cancer classification, and breast tumor segmentation, show that the proposed self-supervised method reaches state-of-the-art (SOTA). The codes are available at https://github.com/Schuture/Meta-USCL.
Boosting Graph Neural Networks via Adaptive Knowledge Distillation
Oct 12, 2022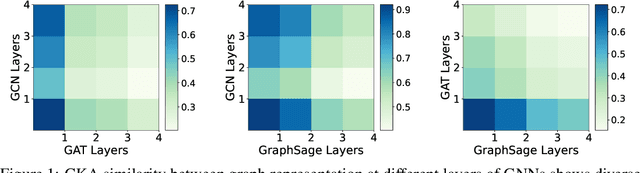
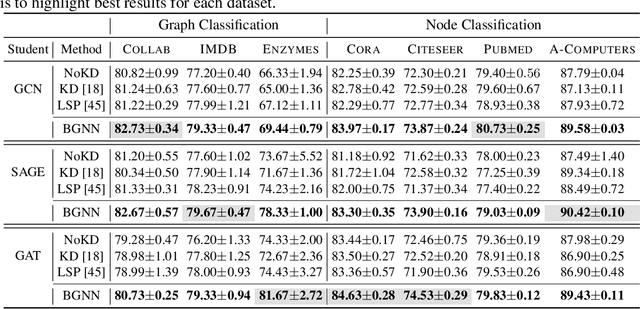
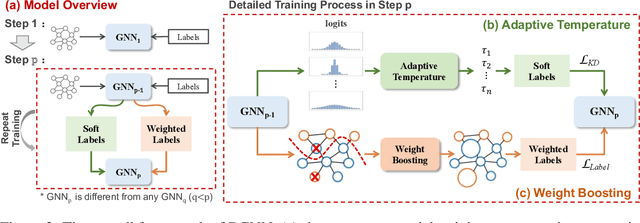
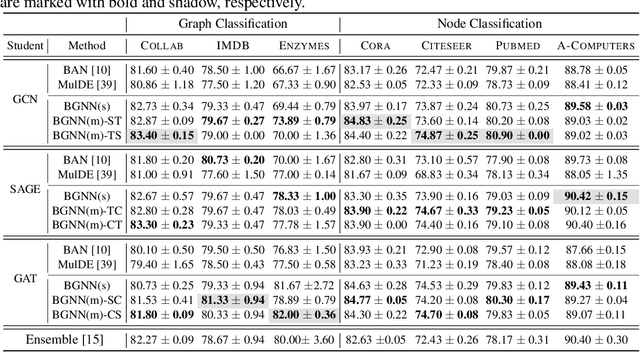
Graph neural networks (GNNs) have shown remarkable performance on diverse graph mining tasks. Although different GNNs can be unified as the same message passing framework, they learn complementary knowledge from the same graph. Knowledge distillation (KD) is developed to combine the diverse knowledge from multiple models. It transfers knowledge from high-capacity teachers to a lightweight student. However, to avoid oversmoothing, GNNs are often shallow, which deviates from the setting of KD. In this context, we revisit KD by separating its benefits from model compression and emphasizing its power of transferring knowledge. To this end, we need to tackle two challenges: how to transfer knowledge from compact teachers to a student with the same capacity; and, how to exploit student GNN's own strength to learn knowledge. In this paper, we propose a novel adaptive KD framework, called BGNN, which sequentially transfers knowledge from multiple GNNs into a student GNN. We also introduce an adaptive temperature module and a weight boosting module. These modules guide the student to the appropriate knowledge for effective learning. Extensive experiments have demonstrated the effectiveness of BGNN. In particular, we achieve up to 3.05% improvement for node classification and 7.67% improvement for graph classification over vanilla GNNs.
HiCo: Hierarchical Contrastive Learning for Ultrasound Video Model Pretraining
Oct 10, 2022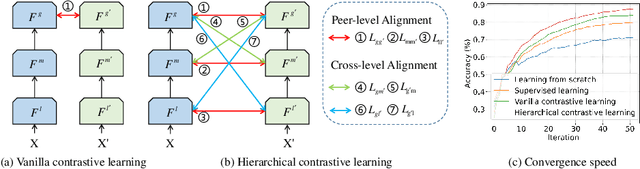
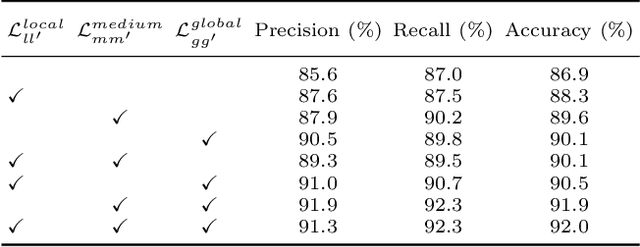
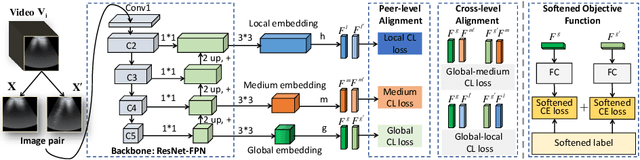
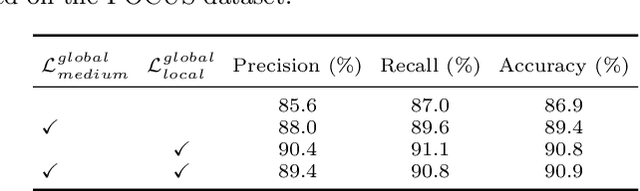
The self-supervised ultrasound (US) video model pretraining can use a small amount of labeled data to achieve one of the most promising results on US diagnosis. However, it does not take full advantage of multi-level knowledge for learning deep neural networks (DNNs), and thus is difficult to learn transferable feature representations. This work proposes a hierarchical contrastive learning (HiCo) method to improve the transferability for the US video model pretraining. HiCo introduces both peer-level semantic alignment and cross-level semantic alignment to facilitate the interaction between different semantic levels, which can effectively accelerate the convergence speed, leading to better generalization and adaptation of the learned model. Additionally, a softened objective function is implemented by smoothing the hard labels, which can alleviate the negative effect caused by local similarities of images between different classes. Experiments with HiCo on five datasets demonstrate its favorable results over state-of-the-art approaches. The source code of this work is publicly available at \url{https://github.com/983632847/HiCo}.
Diving into Unified Data-Model Sparsity for Class-Imbalanced Graph Representation Learning
Oct 01, 2022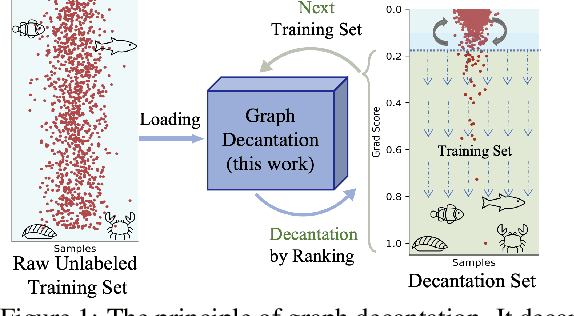

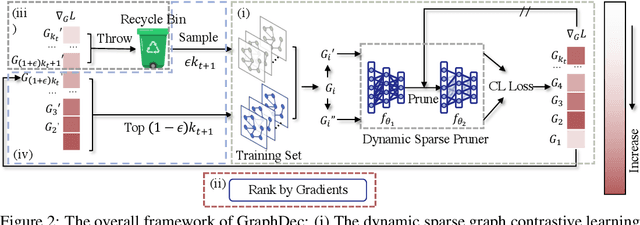
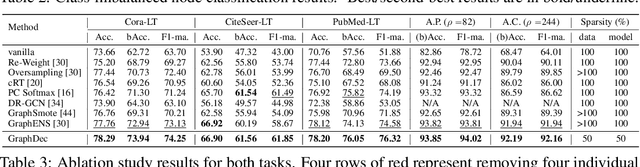
Even pruned by the state-of-the-art network compression methods, Graph Neural Networks (GNNs) training upon non-Euclidean graph data often encounters relatively higher time costs, due to its irregular and nasty density properties, compared with data in the regular Euclidean space. Another natural property concomitantly with graph is class-imbalance which cannot be alleviated by the massive graph data while hindering GNNs' generalization. To fully tackle these unpleasant properties, (i) theoretically, we introduce a hypothesis about what extent a subset of the training data can approximate the full dataset's learning effectiveness. The effectiveness is further guaranteed and proved by the gradients' distance between the subset and the full set; (ii) empirically, we discover that during the learning process of a GNN, some samples in the training dataset are informative for providing gradients to update model parameters. Moreover, the informative subset is not fixed during training process. Samples that are informative in the current training epoch may not be so in the next one. We also notice that sparse subnets pruned from a well-trained GNN sometimes forget the information provided by the informative subset, reflected in their poor performances upon the subset. Based on these findings, we develop a unified data-model dynamic sparsity framework named Graph Decantation (GraphDec) to address challenges brought by training upon a massive class-imbalanced graph data. The key idea of GraphDec is to identify the informative subset dynamically during the training process by adopting sparse graph contrastive learning. Extensive experiments on benchmark datasets demonstrate that GraphDec outperforms baselines for graph and node tasks, with respect to classification accuracy and data usage efficiency.