 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYanfang Ye
Graph Inference Acceleration by Learning MLPs on Graphs without Supervision
Feb 14, 2024
Graph Neural Networks (GNNs) have demonstrated effectiveness in various graph learning tasks, yet their reliance on message-passing constraints their deployment in latency-sensitive applications such as financial fraud detection. Recent works have explored distilling knowledge from GNNs to Multi-Layer Perceptrons (MLPs) to accelerate inference. However, this task-specific supervised distillation limits generalization to unseen nodes, which are prevalent in latency-sensitive applications. To this end, we present \textbf{\textsc{SimMLP}}, a \textbf{\textsc{Sim}}ple yet effective framework for learning \textbf{\textsc{MLP}}s on graphs without supervision, to enhance generalization. \textsc{SimMLP} employs self-supervised alignment between GNNs and MLPs to capture the fine-grained and generalizable correlation between node features and graph structures, and proposes two strategies to alleviate the risk of trivial solutions. Theoretically, we comprehensively analyze \textsc{SimMLP} to demonstrate its equivalence to GNNs in the optimal case and its generalization capability. Empirically, \textsc{SimMLP} outperforms state-of-the-art baselines, especially in settings with unseen nodes. In particular, it obtains significant performance gains {\bf (7$\sim$26\%)} over MLPs and inference acceleration over GNNs {\bf (90$\sim$126$\times$)} on large-scale graph datasets. Our codes are available at: \url{https://github.com/Zehong-Wang/SimMLP}.
Tackling Negative Transfer on Graphs
Feb 14, 2024Transfer learning aims to boost the learning on the target task leveraging knowledge learned from other relevant tasks. However, when the source and target are not closely related, the learning performance may be adversely affected, a phenomenon known as negative transfer. In this paper, we investigate the negative transfer in graph transfer learning, which is important yet underexplored. We reveal that, unlike image or text, negative transfer commonly occurs in graph-structured data, even when source and target graphs share semantic similarities. Specifically, we identify that structural differences significantly amplify the dissimilarities in the node embeddings across graphs. To mitigate this, we bring a new insight: for semantically similar graphs, although structural differences lead to significant distribution shift in node embeddings, their impact on subgraph embeddings could be marginal. Building on this insight, we introduce two effective yet elegant methods, Subgraph Pooling (SP) and Subgraph Pooling++ (SP++), that transfer subgraph-level knowledge across graphs. We theoretically analyze the role of SP in reducing graph discrepancy and conduct extensive experiments to evaluate its superiority under various settings. Our code and datasets are available at: https://github.com/Zehong-Wang/Subgraph-Pooling.
TrustLLM: Trustworthiness in Large Language Models
Jan 25, 2024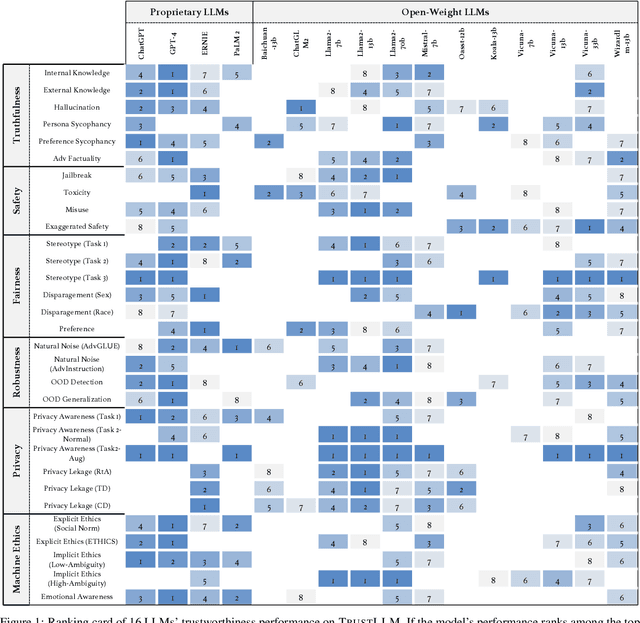


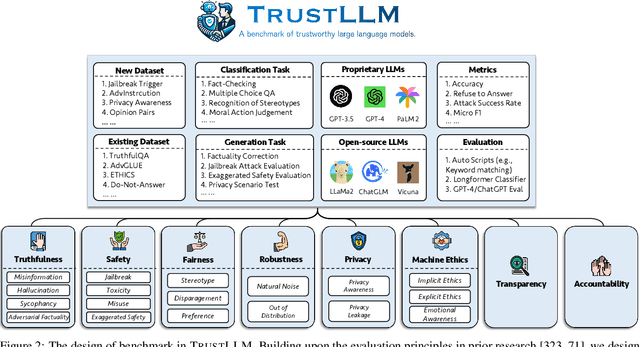
Large language models (LLMs), exemplified by ChatGPT, have gained considerable attention for their excellent natural language processing capabilities. Nonetheless, these LLMs present many challenges, particularly in the realm of trustworthiness. Therefore, ensuring the trustworthiness of LLMs emerges as an important topic. This paper introduces TrustLLM, a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. Our findings firstly show that in general trustworthiness and utility (i.e., functional effectiveness) are positively related. Secondly, our observations reveal that proprietary LLMs generally outperform most open-source counterparts in terms of trustworthiness, raising concerns about the potential risks of widely accessible open-source LLMs. However, a few open-source LLMs come very close to proprietary ones. Thirdly, it is important to note that some LLMs may be overly calibrated towards exhibiting trustworthiness, to the extent that they compromise their utility by mistakenly treating benign prompts as harmful and consequently not responding. Finally, we emphasize the importance of ensuring transparency not only in the models themselves but also in the technologies that underpin trustworthiness. Knowing the specific trustworthy technologies that have been employed is crucial for analyzing their effectiveness.
GraphPatcher: Mitigating Degree Bias for Graph Neural Networks via Test-time Augmentation
Oct 01, 2023Recent studies have shown that graph neural networks (GNNs) exhibit strong biases towards the node degree: they usually perform satisfactorily on high-degree nodes with rich neighbor information but struggle with low-degree nodes. Existing works tackle this problem by deriving either designated GNN architectures or training strategies specifically for low-degree nodes. Though effective, these approaches unintentionally create an artificial out-of-distribution scenario, where models mainly or even only observe low-degree nodes during the training, leading to a downgraded performance for high-degree nodes that GNNs originally perform well at. In light of this, we propose a test-time augmentation framework, namely GraphPatcher, to enhance test-time generalization of any GNNs on low-degree nodes. Specifically, GraphPatcher iteratively generates virtual nodes to patch artificially created low-degree nodes via corruptions, aiming at progressively reconstructing target GNN's predictions over a sequence of increasingly corrupted nodes. Through this scheme, GraphPatcher not only learns how to enhance low-degree nodes (when the neighborhoods are heavily corrupted) but also preserves the original superior performance of GNNs on high-degree nodes (when lightly corrupted). Additionally, GraphPatcher is model-agnostic and can also mitigate the degree bias for either self-supervised or supervised GNNs. Comprehensive experiments are conducted over seven benchmark datasets and GraphPatcher consistently enhances common GNNs' overall performance by up to 3.6% and low-degree performance by up to 6.5%, significantly outperforming state-of-the-art baselines. The source code is publicly available at https://github.com/jumxglhf/GraphPatcher.
Unveiling the Potential of Knowledge-Prompted ChatGPT for Enhancing Drug Trafficking Detection on Social Media
Jul 07, 2023

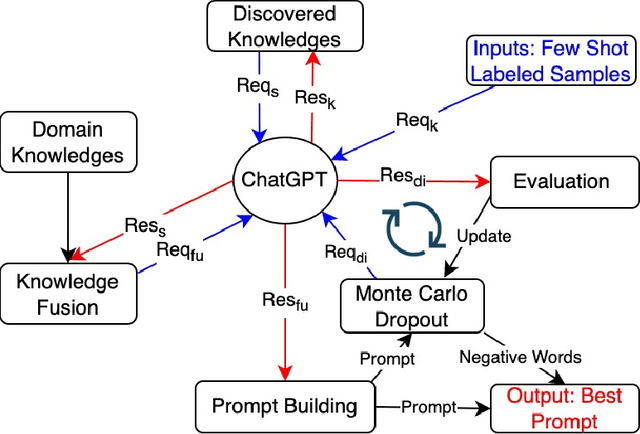

Social media platforms such as Instagram and Twitter have emerged as critical channels for drug marketing and illegal sale. Detecting and labeling online illicit drug trafficking activities becomes important in addressing this issue. However, the effectiveness of conventional supervised learning methods in detecting drug trafficking heavily relies on having access to substantial amounts of labeled data, while data annotation is time-consuming and resource-intensive. Furthermore, these models often face challenges in accurately identifying trafficking activities when drug dealers use deceptive language and euphemisms to avoid detection. To overcome this limitation, we conduct the first systematic study on leveraging large language models (LLMs), such as ChatGPT, to detect illicit drug trafficking activities on social media. We propose an analytical framework to compose \emph{knowledge-informed prompts}, which serve as the interface that humans can interact with and use LLMs to perform the detection task. Additionally, we design a Monte Carlo dropout based prompt optimization method to further to improve performance and interpretability. Our experimental findings demonstrate that the proposed framework outperforms other baseline language models in terms of drug trafficking detection accuracy, showing a remarkable improvement of nearly 12\%. By integrating prior knowledge and the proposed prompts, ChatGPT can effectively identify and label drug trafficking activities on social networks, even in the presence of deceptive language and euphemisms used by drug dealers to evade detection. The implications of our research extend to social networks, emphasizing the importance of incorporating prior knowledge and scenario-based prompts into analytical tools to improve online security and public safety.
Graph Mining for Cybersecurity: A Survey
Apr 02, 2023
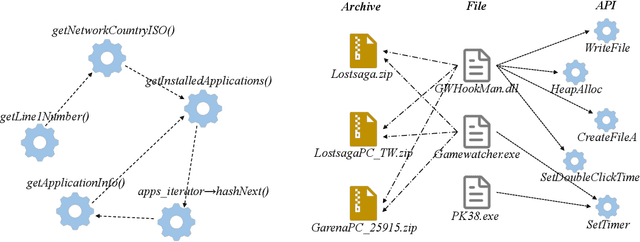

The explosive growth of cyber attacks nowadays, such as malware, spam, and intrusions, caused severe consequences on society. Securing cyberspace has become an utmost concern for organizations and governments. Traditional Machine Learning (ML) based methods are extensively used in detecting cyber threats, but they hardly model the correlations between real-world cyber entities. In recent years, with the proliferation of graph mining techniques, many researchers investigated these techniques for capturing correlations between cyber entities and achieving high performance. It is imperative to summarize existing graph-based cybersecurity solutions to provide a guide for future studies. Therefore, as a key contribution of this paper, we provide a comprehensive review of graph mining for cybersecurity, including an overview of cybersecurity tasks, the typical graph mining techniques, and the general process of applying them to cybersecurity, as well as various solutions for different cybersecurity tasks. For each task, we probe into relevant methods and highlight the graph types, graph approaches, and task levels in their modeling. Furthermore, we collect open datasets and toolkits for graph-based cybersecurity. Finally, we outlook the potential directions of this field for future research.
Let Graph be the Go Board: Gradient-free Node Injection Attack for Graph Neural Networks via Reinforcement Learning
Nov 25, 2022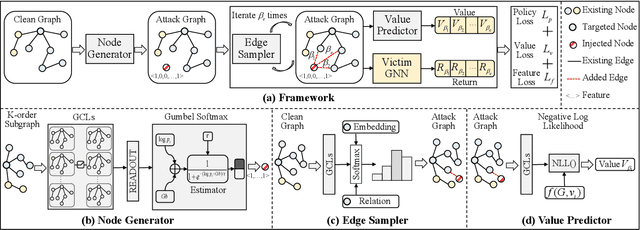
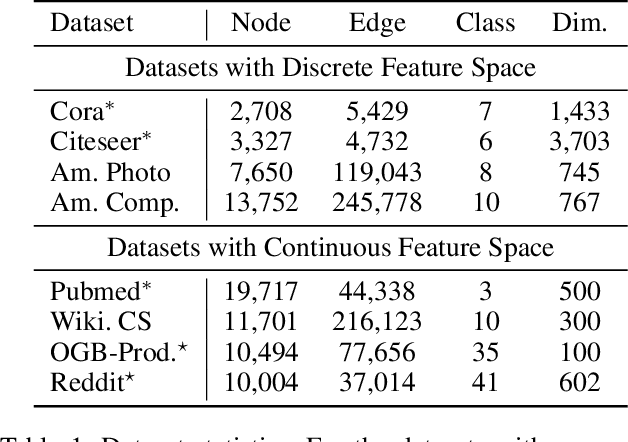
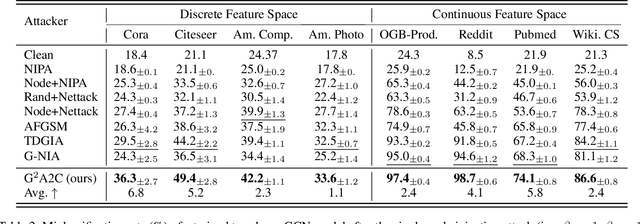
Graph Neural Networks (GNNs) have drawn significant attentions over the years and been broadly applied to essential applications requiring solid robustness or vigorous security standards, such as product recommendation and user behavior modeling. Under these scenarios, exploiting GNN's vulnerabilities and further downgrading its performance become extremely incentive for adversaries. Previous attackers mainly focus on structural perturbations or node injections to the existing graphs, guided by gradients from the surrogate models. Although they deliver promising results, several limitations still exist. For the structural perturbation attack, to launch a proposed attack, adversaries need to manipulate the existing graph topology, which is impractical in most circumstances. Whereas for the node injection attack, though being more practical, current approaches require training surrogate models to simulate a white-box setting, which results in significant performance downgrade when the surrogate architecture diverges from the actual victim model. To bridge these gaps, in this paper, we study the problem of black-box node injection attack, without training a potentially misleading surrogate model. Specifically, we model the node injection attack as a Markov decision process and propose Gradient-free Graph Advantage Actor Critic, namely G2A2C, a reinforcement learning framework in the fashion of advantage actor critic. By directly querying the victim model, G2A2C learns to inject highly malicious nodes with extremely limited attacking budgets, while maintaining a similar node feature distribution. Through our comprehensive experiments over eight acknowledged benchmark datasets with different characteristics, we demonstrate the superior performance of our proposed G2A2C over the existing state-of-the-art attackers. Source code is publicly available at: https://github.com/jumxglhf/G2A2C}.
Self-Supervised Graph Structure Refinement for Graph Neural Networks
Nov 12, 2022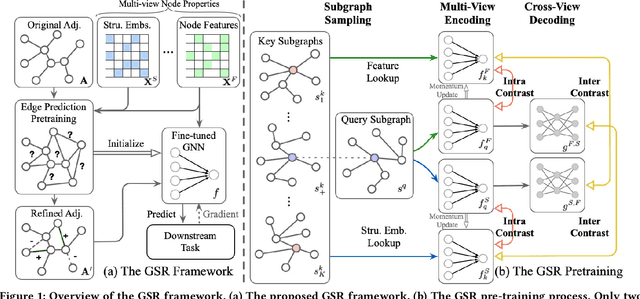
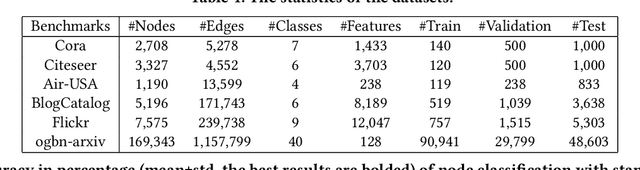
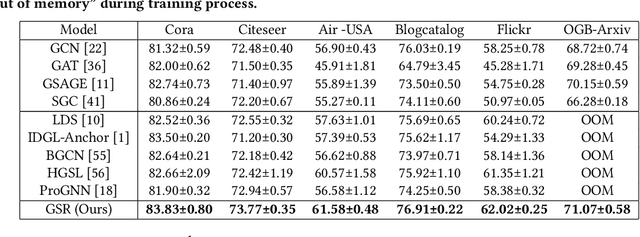

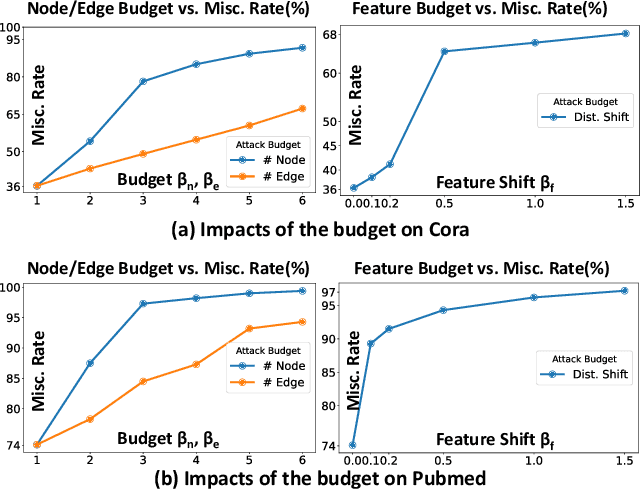
Graph structure learning (GSL), which aims to learn the adjacency matrix for graph neural networks (GNNs), has shown great potential in boosting the performance of GNNs. Most existing GSL works apply a joint learning framework where the estimated adjacency matrix and GNN parameters are optimized for downstream tasks. However, as GSL is essentially a link prediction task, whose goal may largely differ from the goal of the downstream task. The inconsistency of these two goals limits the GSL methods to learn the potential optimal graph structure. Moreover, the joint learning framework suffers from scalability issues in terms of time and space during the process of estimation and optimization of the adjacency matrix. To mitigate these issues, we propose a graph structure refinement (GSR) framework with a pretrain-finetune pipeline. Specifically, The pre-training phase aims to comprehensively estimate the underlying graph structure by a multi-view contrastive learning framework with both intra- and inter-view link prediction tasks. Then, the graph structure is refined by adding and removing edges according to the edge probabilities estimated by the pre-trained model. Finally, the fine-tuning GNN is initialized by the pre-trained model and optimized toward downstream tasks. With the refined graph structure remaining static in the fine-tuning space, GSR avoids estimating and optimizing graph structure in the fine-tuning phase which enjoys great scalability and efficiency. Moreover, the fine-tuning GNN is boosted by both migrating knowledge and refining graphs. Extensive experiments are conducted to evaluate the effectiveness (best performance on six benchmark datasets), efficiency, and scalability (13.8x faster using 32.8% GPU memory compared to the best GSL baseline on Cora) of the proposed model.
Grape: Knowledge Graph Enhanced Passage Reader for Open-domain Question Answering
Oct 10, 2022
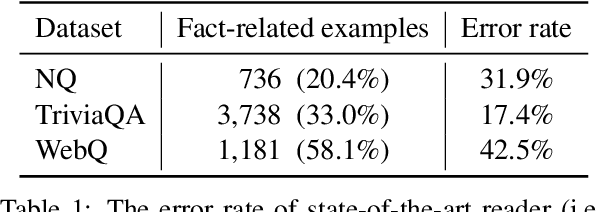


A common thread of open-domain question answering (QA) models employs a retriever-reader pipeline that first retrieves a handful of relevant passages from Wikipedia and then peruses the passages to produce an answer. However, even state-of-the-art readers fail to capture the complex relationships between entities appearing in questions and retrieved passages, leading to answers that contradict the facts. In light of this, we propose a novel knowledge Graph enhanced passage reader, namely Grape, to improve the reader performance for open-domain QA. Specifically, for each pair of question and retrieved passage, we first construct a localized bipartite graph, attributed to entity embeddings extracted from the intermediate layer of the reader model. Then, a graph neural network learns relational knowledge while fusing graph and contextual representations into the hidden states of the reader model. Experiments on three open-domain QA benchmarks show Grape can improve the state-of-the-art performance by up to 2.2 exact match score with a negligible overhead increase, with the same retriever and retrieved passages. Our code is publicly available at https://github.com/jumxglhf/GRAPE.
Multi-objective Deep Data Generation with Correlated Property Control
Oct 06, 2022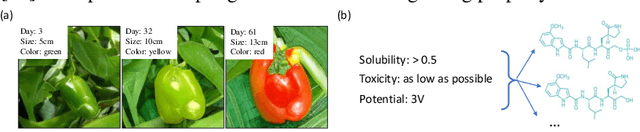
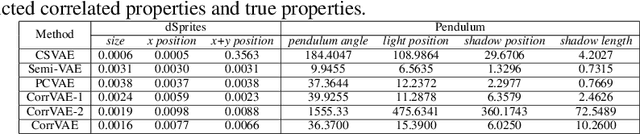

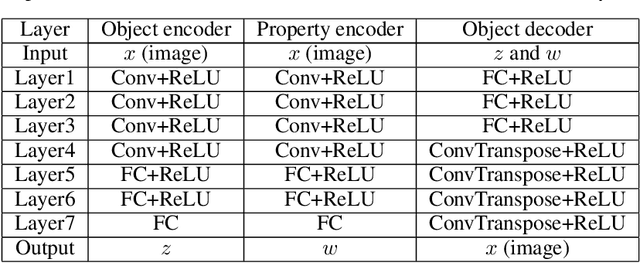
Developing deep generative models has been an emerging field due to the ability to model and generate complex data for various purposes, such as image synthesis and molecular design. However, the advancement of deep generative models is limited by challenges to generate objects that possess multiple desired properties: 1) the existence of complex correlation among real-world properties is common but hard to identify; 2) controlling individual property enforces an implicit partially control of its correlated properties, which is difficult to model; 3) controlling multiple properties under various manners simultaneously is hard and under-explored. We address these challenges by proposing a novel deep generative framework that recovers semantics and the correlation of properties through disentangled latent vectors. The correlation is handled via an explainable mask pooling layer, and properties are precisely retained by generated objects via the mutual dependence between latent vectors and properties. Our generative model preserves properties of interest while handling correlation and conflicts of properties under a multi-objective optimization framework. The experiments demonstrate our model's superior performance in generating data with desired properties.