 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChuanbo Hu
Can ChatGPT Detect DeepFakes? A Study of Using Multimodal Large Language Models for Media Forensics
Mar 26, 2024
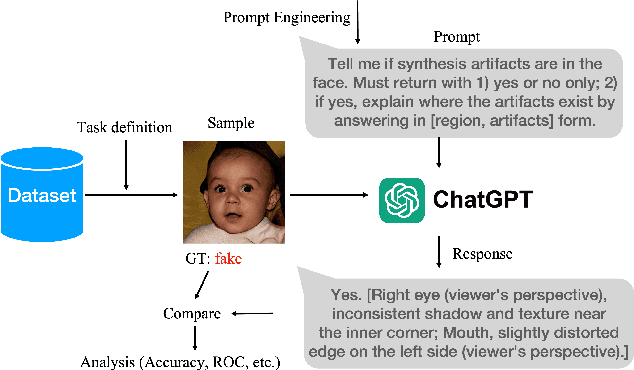

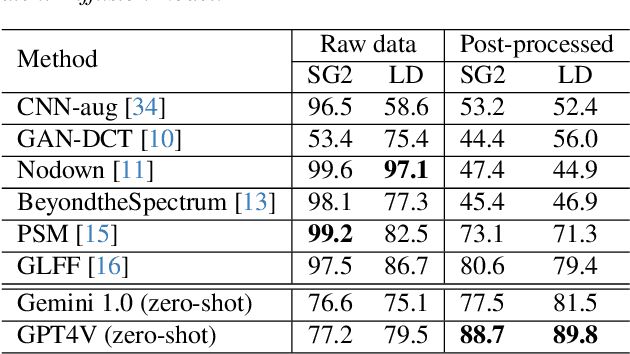
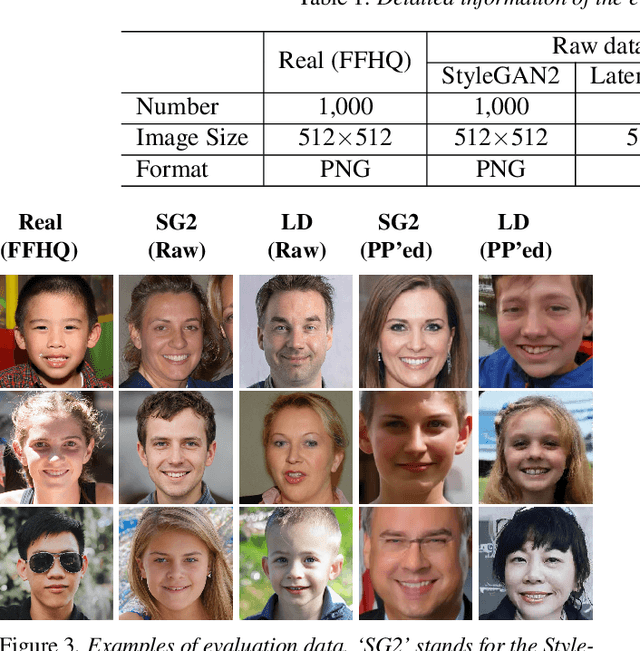
DeepFakes, which refer to AI-generated media content, have become an increasing concern due to their use as a means for disinformation. Detecting DeepFakes is currently solved with programmed machine learning algorithms. In this work, we investigate the capabilities of multimodal large language models (LLMs) in DeepFake detection. We conducted qualitative and quantitative experiments to demonstrate multimodal LLMs and show that they can expose AI-generated images through careful experimental design and prompt engineering. This is interesting, considering that LLMs are not inherently tailored for media forensic tasks, and the process does not require programming. We discuss the limitations of multimodal LLMs for these tasks and suggest possible improvements.
Unveiling the Potential of Knowledge-Prompted ChatGPT for Enhancing Drug Trafficking Detection on Social Media
Jul 07, 2023

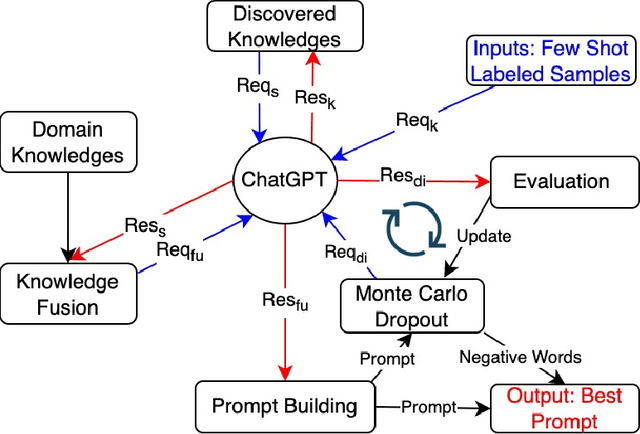

Social media platforms such as Instagram and Twitter have emerged as critical channels for drug marketing and illegal sale. Detecting and labeling online illicit drug trafficking activities becomes important in addressing this issue. However, the effectiveness of conventional supervised learning methods in detecting drug trafficking heavily relies on having access to substantial amounts of labeled data, while data annotation is time-consuming and resource-intensive. Furthermore, these models often face challenges in accurately identifying trafficking activities when drug dealers use deceptive language and euphemisms to avoid detection. To overcome this limitation, we conduct the first systematic study on leveraging large language models (LLMs), such as ChatGPT, to detect illicit drug trafficking activities on social media. We propose an analytical framework to compose \emph{knowledge-informed prompts}, which serve as the interface that humans can interact with and use LLMs to perform the detection task. Additionally, we design a Monte Carlo dropout based prompt optimization method to further to improve performance and interpretability. Our experimental findings demonstrate that the proposed framework outperforms other baseline language models in terms of drug trafficking detection accuracy, showing a remarkable improvement of nearly 12\%. By integrating prior knowledge and the proposed prompts, ChatGPT can effectively identify and label drug trafficking activities on social networks, even in the presence of deceptive language and euphemisms used by drug dealers to evade detection. The implications of our research extend to social networks, emphasizing the importance of incorporating prior knowledge and scenario-based prompts into analytical tools to improve online security and public safety.
UPDExplainer: an Interpretable Transformer-based Framework for Urban Physical Disorder Detection Using Street View Imagery
May 04, 2023

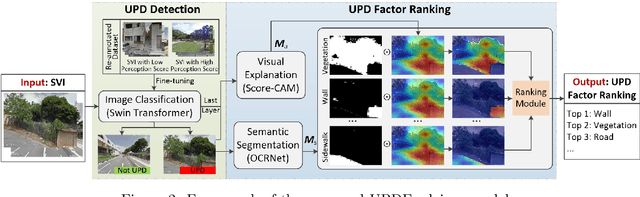
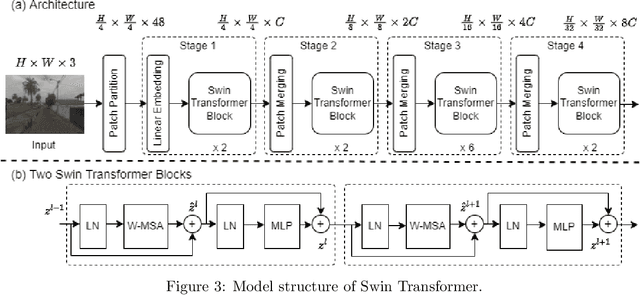
Urban Physical Disorder (UPD), such as old or abandoned buildings, broken sidewalks, litter, and graffiti, has a negative impact on residents' quality of life. They can also increase crime rates, cause social disorder, and pose a public health risk. Currently, there is a lack of efficient and reliable methods for detecting and understanding UPD. To bridge this gap, we propose UPDExplainer, an interpretable transformer-based framework for UPD detection. We first develop a UPD detection model based on the Swin Transformer architecture, which leverages readily accessible street view images to learn discriminative representations. In order to provide clear and comprehensible evidence and analysis, we subsequently introduce a UPD factor identification and ranking module that combines visual explanation maps with semantic segmentation maps. This novel integrated approach enables us to identify the exact objects within street view images that are responsible for physical disorders and gain insights into the underlying causes. Experimental results on the re-annotated Place Pulse 2.0 dataset demonstrate promising detection performance of the proposed method, with an accuracy of 79.9%. For a comprehensive evaluation of the method's ranking performance, we report the mean Average Precision (mAP), R-Precision (RPrec), and Normalized Discounted Cumulative Gain (NDCG), with success rates of 75.51%, 80.61%, and 82.58%, respectively. We also present a case study of detecting and ranking physical disorders in the southern region of downtown Los Angeles, California, to demonstrate the practicality and effectiveness of our framework.
Video-based Contrastive Learning on Decision Trees: from Action Recognition to Autism Diagnosis
Apr 21, 2023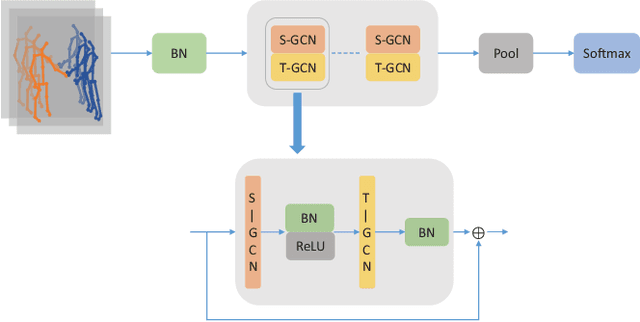
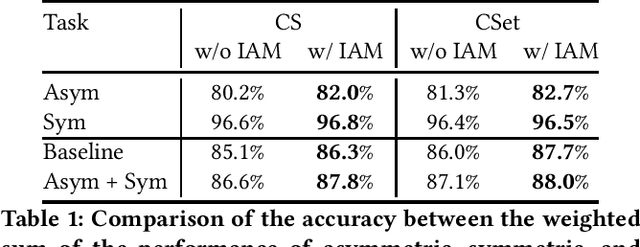
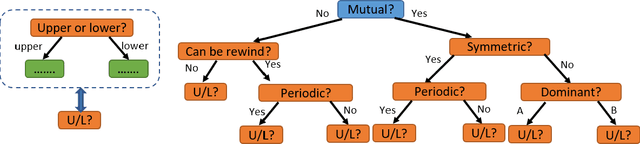
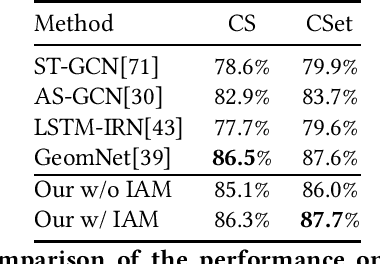
How can we teach a computer to recognize 10,000 different actions? Deep learning has evolved from supervised and unsupervised to self-supervised approaches. In this paper, we present a new contrastive learning-based framework for decision tree-based classification of actions, including human-human interactions (HHI) and human-object interactions (HOI). The key idea is to translate the original multi-class action recognition into a series of binary classification tasks on a pre-constructed decision tree. Under the new framework of contrastive learning, we present the design of an interaction adjacent matrix (IAM) with skeleton graphs as the backbone for modeling various action-related attributes such as periodicity and symmetry. Through the construction of various pretext tasks, we obtain a series of binary classification nodes on the decision tree that can be combined to support higher-level recognition tasks. Experimental justification for the potential of our approach in real-world applications ranges from interaction recognition to symmetry detection. In particular, we have demonstrated the promising performance of video-based autism spectrum disorder (ASD) diagnosis on the CalTech interview video database.
A Saliency-Guided Street View Image Inpainting Framework for Efficient Last-Meters Wayfinding
May 14, 2022
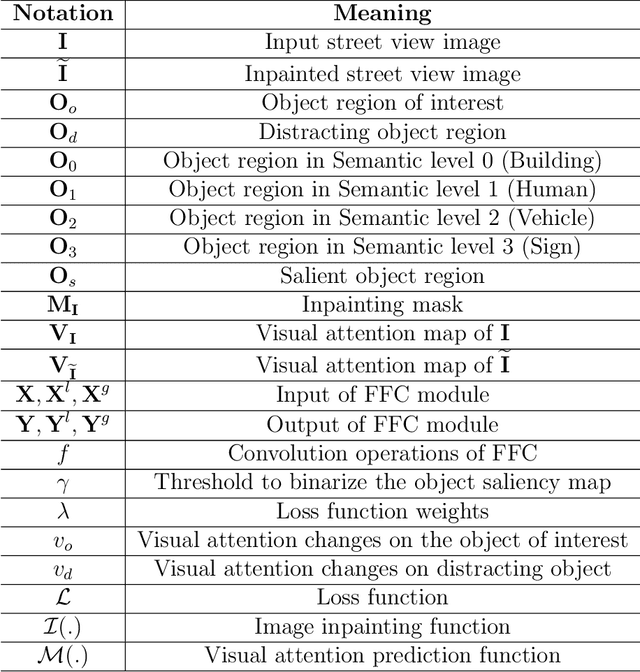
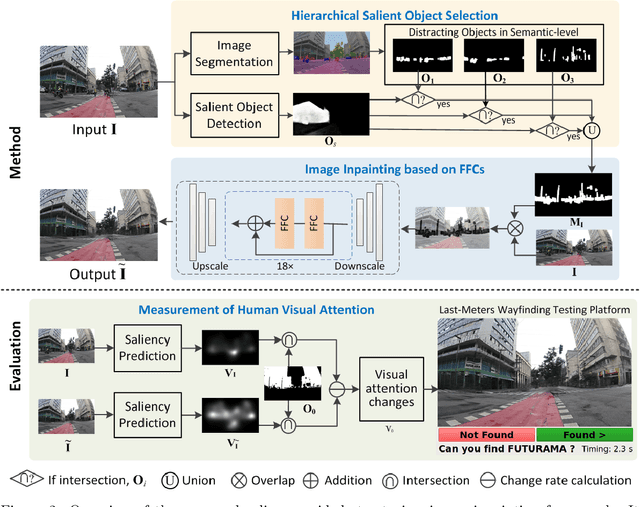

Global Positioning Systems (GPS) have played a crucial role in various navigation applications. Nevertheless, localizing the perfect destination within the last few meters remains an important but unresolved problem. Limited by the GPS positioning accuracy, navigation systems always show users a vicinity of a destination, but not its exact location. Street view images (SVI) in maps as an immersive media technology have served as an aid to provide the physical environment for human last-meters wayfinding. However, due to the large diversity of geographic context and acquisition conditions, the captured SVI always contains various distracting objects (e.g., pedestrians and vehicles), which will distract human visual attention from efficiently finding the destination in the last few meters. To address this problem, we highlight the importance of reducing visual distraction in image-based wayfinding by proposing a saliency-guided image inpainting framework. It aims at redirecting human visual attention from distracting objects to destination-related objects for more efficient and accurate wayfinding in the last meters. Specifically, a context-aware distracting object detection method driven by deep salient object detection has been designed to extract distracting objects from three semantic levels in SVI. Then we employ a large-mask inpainting method with fast Fourier convolutions to remove the detected distracting objects. Experimental results with both qualitative and quantitative analysis show that our saliency-guided inpainting method can not only achieve great perceptual quality in street view images but also redirect the human's visual attention to focus more on static location-related objects than distracting ones. The human-based evaluation also justified the effectiveness of our method in improving the efficiency of locating the target destination.
Detection of Illicit Drug Trafficking Events on Instagram: A Deep Multimodal Multilabel Learning Approach
Aug 23, 2021
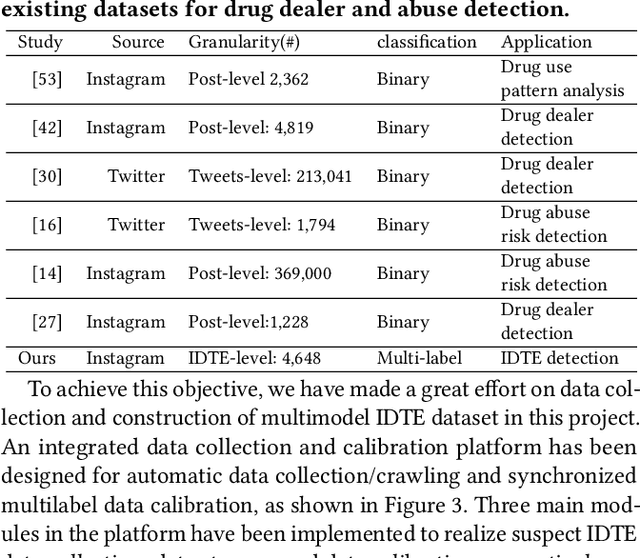
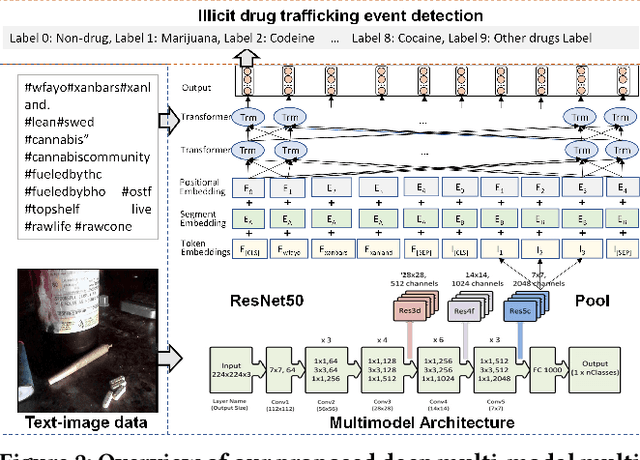
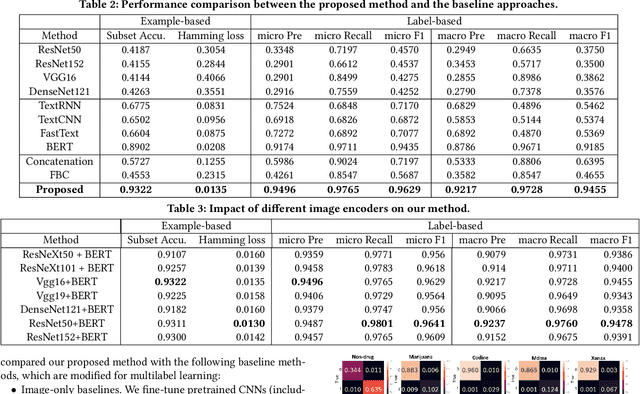
Social media such as Instagram and Twitter have become important platforms for marketing and selling illicit drugs. Detection of online illicit drug trafficking has become critical to combat the online trade of illicit drugs. However, the legal status often varies spatially and temporally; even for the same drug, federal and state legislation can have different regulations about its legality. Meanwhile, more drug trafficking events are disguised as a novel form of advertising commenting leading to information heterogeneity. Accordingly, accurate detection of illicit drug trafficking events (IDTEs) from social media has become even more challenging. In this work, we conduct the first systematic study on fine-grained detection of IDTEs on Instagram. We propose to take a deep multimodal multilabel learning (DMML) approach to detect IDTEs and demonstrate its effectiveness on a newly constructed dataset called multimodal IDTE(MM-IDTE). Specifically, our model takes text and image data as the input and combines multimodal information to predict multiple labels of illicit drugs. Inspired by the success of BERT, we have developed a self-supervised multimodal bidirectional transformer by jointly fine-tuning pretrained text and image encoders. We have constructed a large-scale dataset MM-IDTE with manually annotated multiple drug labels to support fine-grained detection of illicit drugs. Extensive experimental results on the MM-IDTE dataset show that the proposed DMML methodology can accurately detect IDTEs even in the presence of special characters and style changes attempting to evade detection.
Identifying Illicit Drug Dealers on Instagram with Large-scale Multimodal Data Fusion
Aug 23, 2021


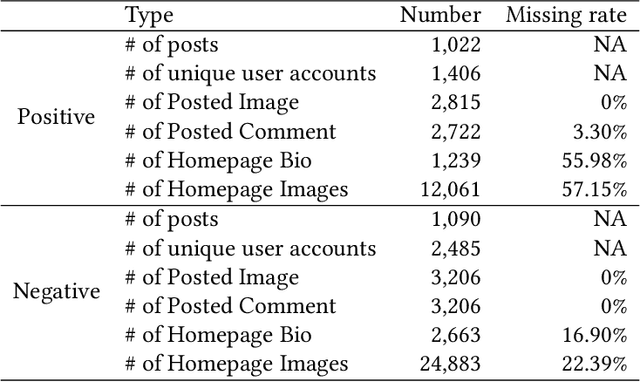
Illicit drug trafficking via social media sites such as Instagram has become a severe problem, thus drawing a great deal of attention from law enforcement and public health agencies. How to identify illicit drug dealers from social media data has remained a technical challenge due to the following reasons. On the one hand, the available data are limited because of privacy concerns with crawling social media sites; on the other hand, the diversity of drug dealing patterns makes it difficult to reliably distinguish drug dealers from common drug users. Unlike existing methods that focus on posting-based detection, we propose to tackle the problem of illicit drug dealer identification by constructing a large-scale multimodal dataset named Identifying Drug Dealers on Instagram (IDDIG). Totally nearly 4,000 user accounts, of which over 1,400 are drug dealers, have been collected from Instagram with multiple data sources including post comments, post images, homepage bio, and homepage images. We then design a quadruple-based multimodal fusion method to combine the multiple data sources associated with each user account for drug dealer identification. Experimental results on the constructed IDDIG dataset demonstrate the effectiveness of the proposed method in identifying drug dealers (almost 95% accuracy). Moreover, we have developed a hashtag-based community detection technique for discovering evolving patterns, especially those related to geography and drug types.
Detection of Genuine and Posed Facial Expressions of Emotion: A Review
Aug 26, 2020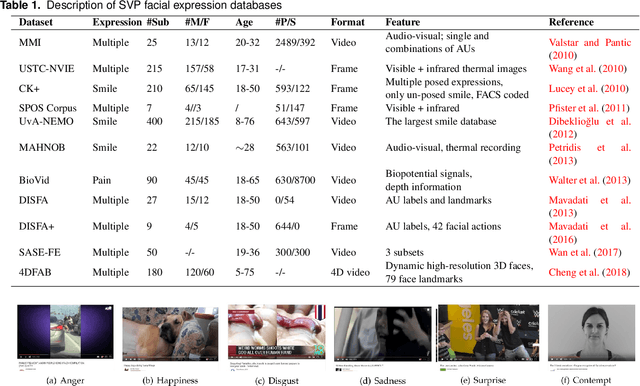



Facial expressions of emotion play an important role in human social interactions. However, posed acting is not always the same as genuine feeling. Therefore, the credibility assessment of facial expressions, namely, the discrimination of genuine (spontaneous) expressions from posed(deliberate/volitional/deceptive) ones, is a crucial yet challenging task in facial expression understanding. Rapid progress has been made in recent years for automatic detection of genuine and posed facial expressions. This paper presents a general review of the relevant research, including several spontaneous vs. posed (SVP) facial expression databases and various computer vision based detection methods. In addition, a variety of factors that will influence the performance of SVP detection methods are discussed along with open issues and technical challenges.
3D Face Anti-spoofing with Factorized Bilinear Coding
May 12, 2020



We have witnessed rapid advances in both face presentation attack models and presentation attack detection (PAD) in recent years. When compared with widely studied 2D face presentation attacks, 3D face spoofing attacks are more challenging because face recognition systems (FRS) are more easily confused by the 3D characteristics of materials similar to real faces. In this work, we tackle the problem of detecting these realistic 3D face presentation attacks, and propose a novel anti-spoofing method from the perspective of fine-grained classification. Our method, based on factorized bilinear coding of multiple color channels (namely MC_FBC), targets at learning subtle visual differences between real and fake images. By extracting discriminative and fusing complementary information from RGB and YCbCr spaces, we have developed a principled solution to 3D face spoofing detection. A large-scale wax figure face database (WFFD) with both still and moving wax faces has also been collected as super-realistic attacks to facilitate the study of 3D face PAD. Extensive experimental results show that our proposed method achieves the state-of-the-art performance on both our own WFFD and other face spoofing databases under various intra-database and inter-database testing scenarios.
Spoofing and Anti-Spoofing with Wax Figure Faces
Oct 12, 2019
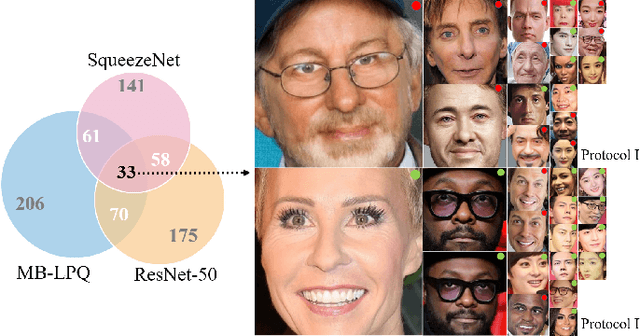


We have witnessed rapid advances in both face presentation attack models and presentation attack detection (PAD) in recent years. Compared to widely studied 2D face presentation attacks (e.g. printed photos and video replays), 3D face presentation attacks are more challenging because face recognition systems (FRS) is more easily confused by the 3D characteristics of materials similar to real faces. Existing 3D face spoofing databases, mostly based on 3D facial masks, are restricted to small data size and suffer from poor authenticity due to the difficulty and expense of mask production. In this work, we introduce a wax figure face database (WFFD) as a novel and super-realistic 3D face presentation attack. This database contains 2300 image pairs (totally 4600) and 745 subjects including both real and wax figure faces with high diversity from online collections. On one hand, our experiments have demonstrated the spoofing potential of WFFD on three popular FRSs. On the other hand, we have developed a multi-feature voting scheme for wax figure face detection (anti-spoofing), which combines three discriminative features at the decision level. The proposed detection method was compared against several face PAD approaches and found to outperform other competing methods. Surprisingly, our fusion-based detection method achieves an Average Classification Error Rate (ACER) of 11.73\% on the WFFD database, which is even better than human-based detection.