 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShan Jia
Explicit Correlation Learning for Generalizable Cross-Modal Deepfake Detection
Apr 30, 2024
With the rising prevalence of deepfakes, there is a growing interest in developing generalizable detection methods for various types of deepfakes. While effective in their specific modalities, traditional detection methods fall short in addressing the generalizability of detection across diverse cross-modal deepfakes. This paper aims to explicitly learn potential cross-modal correlation to enhance deepfake detection towards various generation scenarios. Our approach introduces a correlation distillation task, which models the inherent cross-modal correlation based on content information. This strategy helps to prevent the model from overfitting merely to audio-visual synchronization. Additionally, we present the Cross-Modal Deepfake Dataset (CMDFD), a comprehensive dataset with four generation methods to evaluate the detection of diverse cross-modal deepfakes. The experimental results on CMDFD and FakeAVCeleb datasets demonstrate the superior generalizability of our method over existing state-of-the-art methods. Our code and data can be found at \url{https://github.com/ljj898/CMDFD-Dataset-and-Deepfake-Detection}.
Exposing Text-Image Inconsistency Using Diffusion Models
Apr 28, 2024In the battle against widespread online misinformation, a growing problem is text-image inconsistency, where images are misleadingly paired with texts with different intent or meaning. Existing classification-based methods for text-image inconsistency can identify contextual inconsistencies but fail to provide explainable justifications for their decisions that humans can understand. Although more nuanced, human evaluation is impractical at scale and susceptible to errors. To address these limitations, this study introduces D-TIIL (Diffusion-based Text-Image Inconsistency Localization), which employs text-to-image diffusion models to localize semantic inconsistencies in text and image pairs. These models, trained on large-scale datasets act as ``omniscient" agents that filter out irrelevant information and incorporate background knowledge to identify inconsistencies. In addition, D-TIIL uses text embeddings and modified image regions to visualize these inconsistencies. To evaluate D-TIIL's efficacy, we introduce a new TIIL dataset containing 14K consistent and inconsistent text-image pairs. Unlike existing datasets, TIIL enables assessment at the level of individual words and image regions and is carefully designed to represent various inconsistencies. D-TIIL offers a scalable and evidence-based approach to identifying and localizing text-image inconsistency, providing a robust framework for future research combating misinformation.
Can ChatGPT Detect DeepFakes? A Study of Using Multimodal Large Language Models for Media Forensics
Mar 26, 2024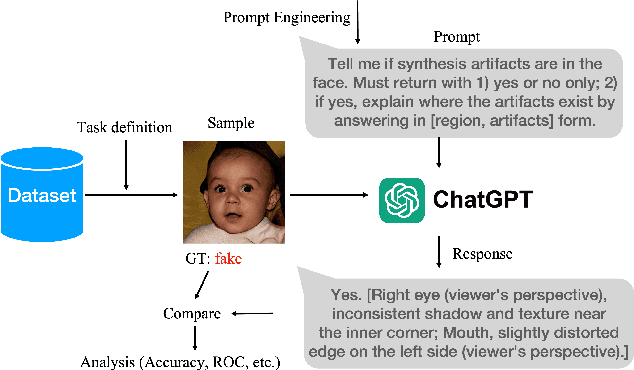

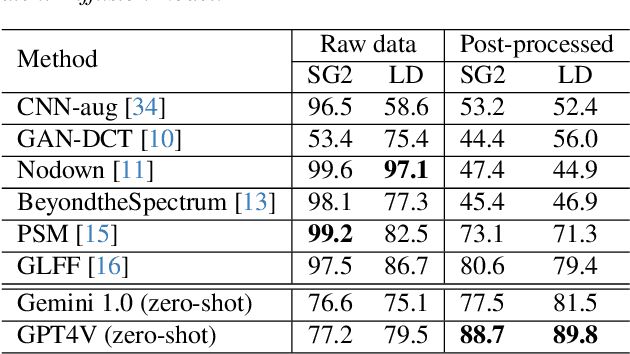
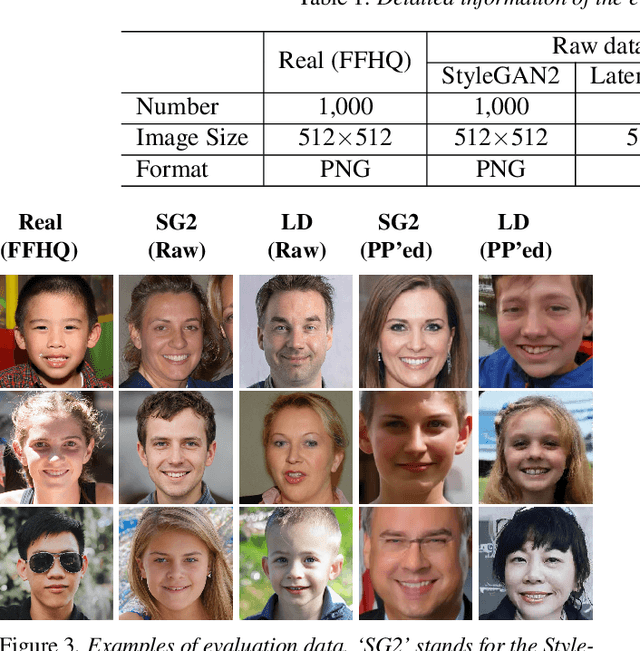
DeepFakes, which refer to AI-generated media content, have become an increasing concern due to their use as a means for disinformation. Detecting DeepFakes is currently solved with programmed machine learning algorithms. In this work, we investigate the capabilities of multimodal large language models (LLMs) in DeepFake detection. We conducted qualitative and quantitative experiments to demonstrate multimodal LLMs and show that they can expose AI-generated images through careful experimental design and prompt engineering. This is interesting, considering that LLMs are not inherently tailored for media forensic tasks, and the process does not require programming. We discuss the limitations of multimodal LLMs for these tasks and suggest possible improvements.
Exposing Lip-syncing Deepfakes from Mouth Inconsistencies
Jan 18, 2024A lip-syncing deepfake is a digitally manipulated video in which a person's lip movements are created convincingly using AI models to match altered or entirely new audio. Lip-syncing deepfakes are a dangerous type of deepfakes as the artifacts are limited to the lip region and more difficult to discern. In this paper, we describe a novel approach, LIP-syncing detection based on mouth INConsistency (LIPINC), for lip-syncing deepfake detection by identifying temporal inconsistencies in the mouth region. These inconsistencies are seen in the adjacent frames and throughout the video. Our model can successfully capture these irregularities and outperforms the state-of-the-art methods on several benchmark deepfake datasets.
Integrating Audio-Visual Features for Multimodal Deepfake Detection
Oct 05, 2023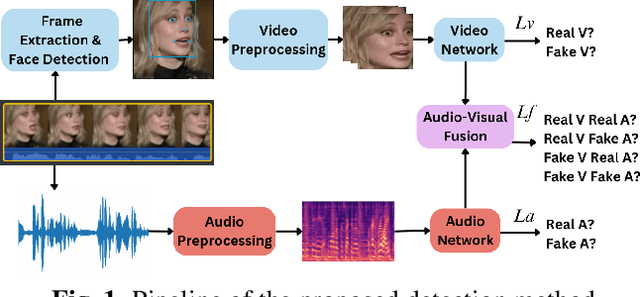
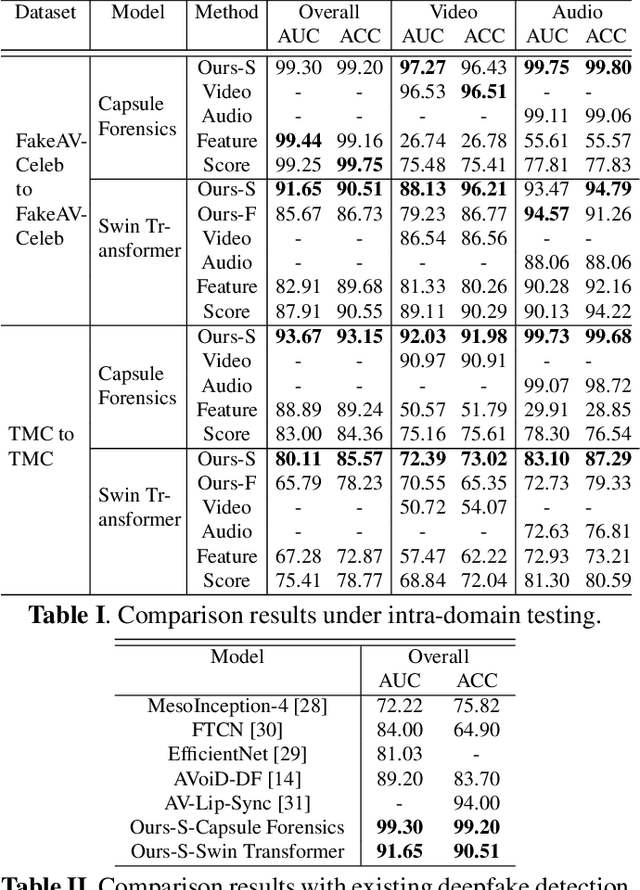
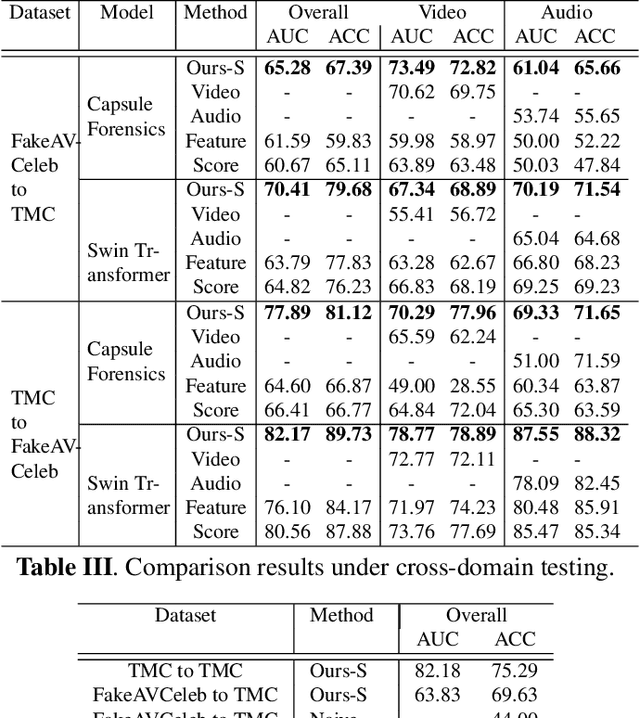
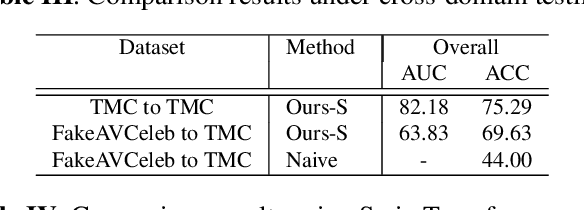
Deepfakes are AI-generated media in which an image or video has been digitally modified. The advancements made in deepfake technology have led to privacy and security issues. Most deepfake detection techniques rely on the detection of a single modality. Existing methods for audio-visual detection do not always surpass that of the analysis based on single modalities. Therefore, this paper proposes an audio-visual-based method for deepfake detection, which integrates fine-grained deepfake identification with binary classification. We categorize the samples into four types by combining labels specific to each single modality. This method enhances the detection under intra-domain and cross-domain testing.
Improving Fairness in Deepfake Detection
Jun 29, 2023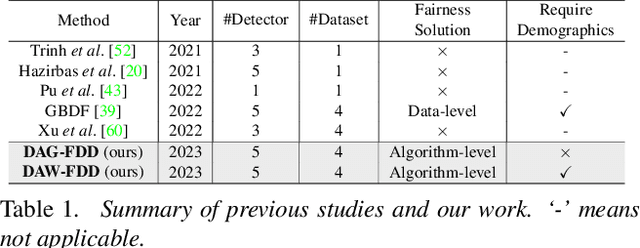
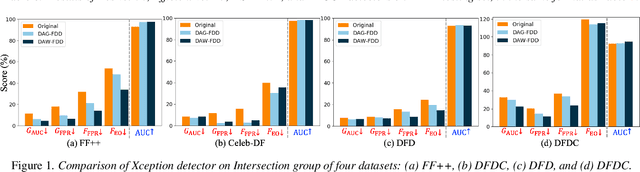

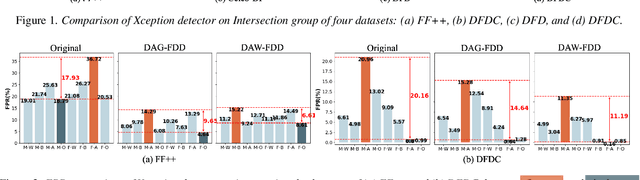
Despite the development of effective deepfake detection models in recent years, several recent studies have demonstrated that biases in the training data utilized to develop deepfake detection models can lead to unfair performance for demographic groups of different races and/or genders. Such can result in these groups being unfairly targeted or excluded from detection, allowing misclassified deepfakes to manipulate public opinion and erode trust in the model. While these studies have focused on identifying and evaluating the unfairness in deepfake detection, no methods have been developed to address the fairness issue of deepfake detection at the algorithm level. In this work, we make the first attempt to improve deepfake detection fairness by proposing novel loss functions to train fair deepfake detection models in ways that are agnostic or aware of demographic factors. Extensive experiments on four deepfake datasets and five deepfake detectors demonstrate the effectiveness and flexibility of our approach in improving the deepfake detection fairness.
UPDExplainer: an Interpretable Transformer-based Framework for Urban Physical Disorder Detection Using Street View Imagery
May 04, 2023

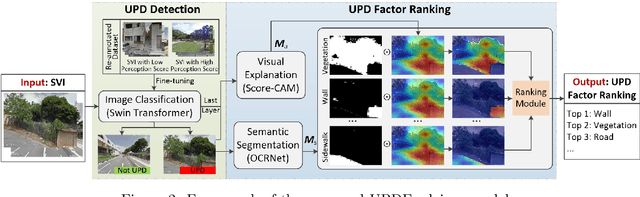
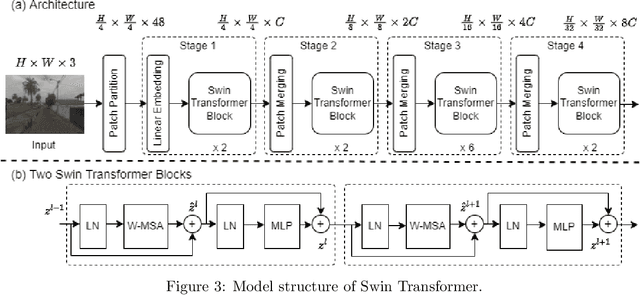
Urban Physical Disorder (UPD), such as old or abandoned buildings, broken sidewalks, litter, and graffiti, has a negative impact on residents' quality of life. They can also increase crime rates, cause social disorder, and pose a public health risk. Currently, there is a lack of efficient and reliable methods for detecting and understanding UPD. To bridge this gap, we propose UPDExplainer, an interpretable transformer-based framework for UPD detection. We first develop a UPD detection model based on the Swin Transformer architecture, which leverages readily accessible street view images to learn discriminative representations. In order to provide clear and comprehensible evidence and analysis, we subsequently introduce a UPD factor identification and ranking module that combines visual explanation maps with semantic segmentation maps. This novel integrated approach enables us to identify the exact objects within street view images that are responsible for physical disorders and gain insights into the underlying causes. Experimental results on the re-annotated Place Pulse 2.0 dataset demonstrate promising detection performance of the proposed method, with an accuracy of 79.9%. For a comprehensive evaluation of the method's ranking performance, we report the mean Average Precision (mAP), R-Precision (RPrec), and Normalized Discounted Cumulative Gain (NDCG), with success rates of 75.51%, 80.61%, and 82.58%, respectively. We also present a case study of detecting and ranking physical disorders in the southern region of downtown Los Angeles, California, to demonstrate the practicality and effectiveness of our framework.
AI-Synthesized Voice Detection Using Neural Vocoder Artifacts
Apr 27, 2023
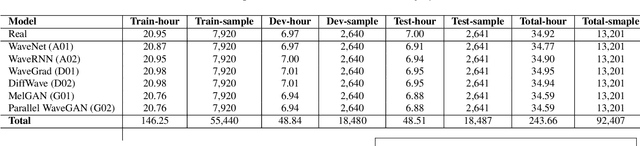
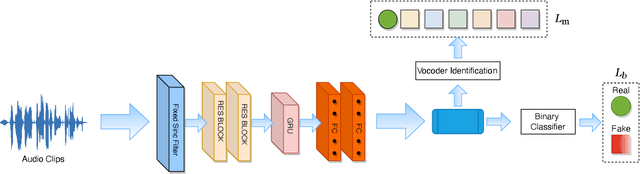

Advancements in AI-synthesized human voices have created a growing threat of impersonation and disinformation, making it crucial to develop methods to detect synthetic human voices. This study proposes a new approach to identifying synthetic human voices by detecting artifacts of vocoders in audio signals. Most DeepFake audio synthesis models use a neural vocoder, a neural network that generates waveforms from temporal-frequency representations like mel-spectrograms. By identifying neural vocoder processing in audio, we can determine if a sample is synthesized. To detect synthetic human voices, we introduce a multi-task learning framework for a binary-class RawNet2 model that shares the feature extractor with a vocoder identification module. By treating vocoder identification as a pretext task, we constrain the feature extractor to focus on vocoder artifacts and provide discriminative features for the final binary classifier. Our experiments show that the improved RawNet2 model based on vocoder identification achieves high classification performance on the binary task overall.
AutoSplice: A Text-prompt Manipulated Image Dataset for Media Forensics
Apr 14, 2023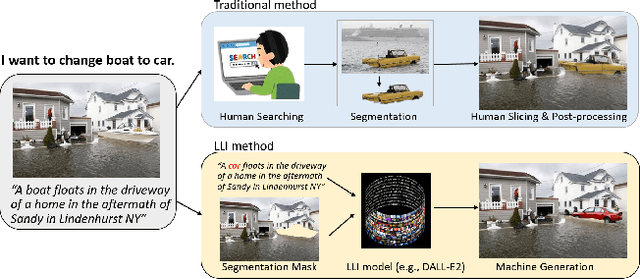


Recent advancements in language-image models have led to the development of highly realistic images that can be generated from textual descriptions. However, the increased visual quality of these generated images poses a potential threat to the field of media forensics. This paper aims to investigate the level of challenge that language-image generation models pose to media forensics. To achieve this, we propose a new approach that leverages the DALL-E2 language-image model to automatically generate and splice masked regions guided by a text prompt. To ensure the creation of realistic manipulations, we have designed an annotation platform with human checking to verify reasonable text prompts. This approach has resulted in the creation of a new image dataset called AutoSplice, containing 5,894 manipulated and authentic images. Specifically, we have generated a total of 3,621 images by locally or globally manipulating real-world image-caption pairs, which we believe will provide a valuable resource for developing generalized detection methods in this area. The dataset is evaluated under two media forensic tasks: forgery detection and localization. Our extensive experiments show that most media forensic models struggle to detect the AutoSplice dataset as an unseen manipulation. However, when fine-tuned models are used, they exhibit improved performance in both tasks.
Exposing AI-Synthesized Human Voices Using Neural Vocoder Artifacts
Feb 18, 2023


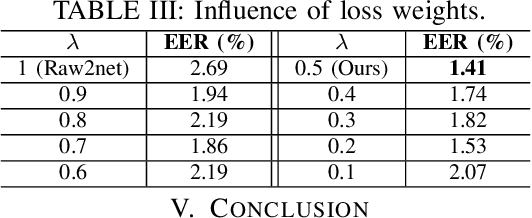
The advancements of AI-synthesized human voices have introduced a growing threat of impersonation and disinformation. It is therefore of practical importance to developdetection methods for synthetic human voices. This work proposes a new approach to detect synthetic human voices based on identifying artifacts of neural vocoders in audio signals. A neural vocoder is a specially designed neural network that synthesizes waveforms from temporal-frequency representations, e.g., mel-spectrograms. The neural vocoder is a core component in most DeepFake audio synthesis models. Hence the identification of neural vocoder processing implies that an audio sample may have been synthesized. To take advantage of the vocoder artifacts for synthetic human voice detection, we introduce a multi-task learning framework for a binary-class RawNet2 model that shares the front-end feature extractor with a vocoder identification module. We treat the vocoder identification as a pretext task to constrain the front-end feature extractor to focus on vocoder artifacts and provide discriminative features for the final binary classifier. Our experiments show that the improved RawNet2 model based on vocoder identification achieves an overall high classification performance on the binary task.