 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKai Shu
Integrating Mamba and Transformer for Long-Short Range Time Series Forecasting
Apr 23, 2024
Time series forecasting is an important problem and plays a key role in a variety of applications including weather forecasting, stock market, and scientific simulations. Although transformers have proven to be effective in capturing dependency, its quadratic complexity of attention mechanism prevents its further adoption in long-range time series forecasting, thus limiting them attend to short-range range. Recent progress on state space models (SSMs) have shown impressive performance on modeling long range dependency due to their subquadratic complexity. Mamba, as a representative SSM, enjoys linear time complexity and has achieved strong scalability on tasks that requires scaling to long sequences, such as language, audio, and genomics. In this paper, we propose to leverage a hybrid framework Mambaformer that internally combines Mamba for long-range dependency, and Transformer for short range dependency, for long-short range forecasting. To the best of our knowledge, this is the first paper to combine Mamba and Transformer architecture in time series data. We investigate possible hybrid architectures to combine Mamba layer and attention layer for long-short range time series forecasting. The comparative study shows that the Mambaformer family can outperform Mamba and Transformer in long-short range time series forecasting problem. The code is available at https://github.com/XiongxiaoXu/Mambaformerin-Time-Series.
Re-Search for The Truth: Multi-round Retrieval-augmented Large Language Models are Strong Fake News Detectors
Mar 14, 2024
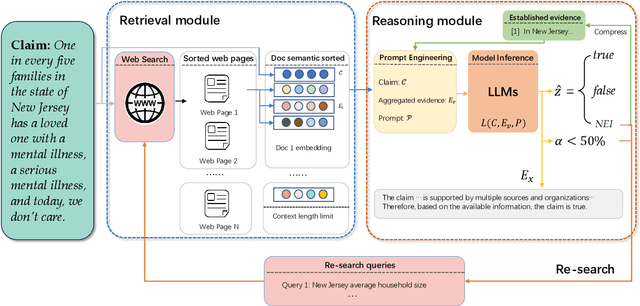
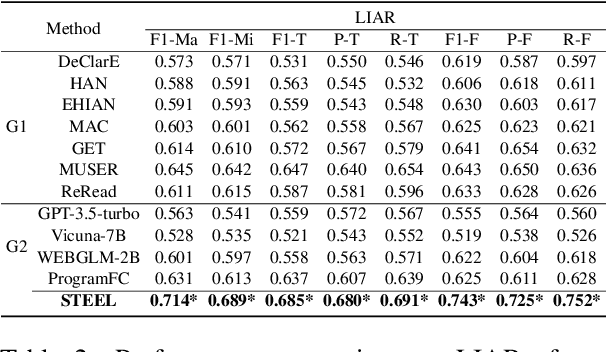
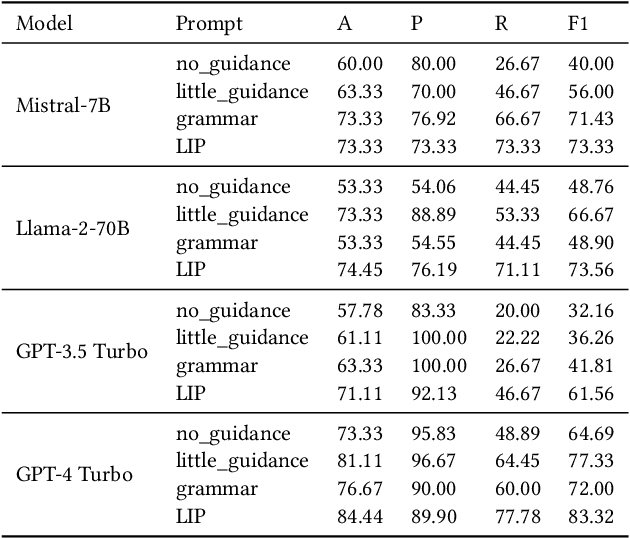
The proliferation of fake news has had far-reaching implications on politics, the economy, and society at large. While Fake news detection methods have been employed to mitigate this issue, they primarily depend on two essential elements: the quality and relevance of the evidence, and the effectiveness of the verdict prediction mechanism. Traditional methods, which often source information from static repositories like Wikipedia, are limited by outdated or incomplete data, particularly for emerging or rare claims. Large Language Models (LLMs), known for their remarkable reasoning and generative capabilities, introduce a new frontier for fake news detection. However, like traditional methods, LLM-based solutions also grapple with the limitations of stale and long-tail knowledge. Additionally, retrieval-enhanced LLMs frequently struggle with issues such as low-quality evidence retrieval and context length constraints. To address these challenges, we introduce a novel, retrieval-augmented LLMs framework--the first of its kind to automatically and strategically extract key evidence from web sources for claim verification. Employing a multi-round retrieval strategy, our framework ensures the acquisition of sufficient, relevant evidence, thereby enhancing performance. Comprehensive experiments across three real-world datasets validate the framework's superiority over existing methods. Importantly, our model not only delivers accurate verdicts but also offers human-readable explanations to improve result interpretability.
Can Large Language Models Identify Authorship?
Mar 13, 2024

The ability to accurately identify authorship is crucial for verifying content authenticity and mitigating misinformation. Large Language Models (LLMs) have demonstrated exceptional capacity for reasoning and problem-solving. However, their potential in authorship analysis, encompassing authorship verification and attribution, remains underexplored. This paper conducts a comprehensive evaluation of LLMs in these critical tasks. Traditional studies have depended on hand-crafted stylistic features, whereas state-of-the-art approaches leverage text embeddings from pre-trained language models. These methods, which typically require fine-tuning on labeled data, often suffer from performance degradation in cross-domain applications and provide limited explainability. This work seeks to address three research questions: (1) Can LLMs perform zero-shot, end-to-end authorship verification effectively? (2) Are LLMs capable of accurately attributing authorship among multiple candidates authors (e.g., 10 and 20)? (3) How can LLMs provide explainability in authorship analysis, particularly through the role of linguistic features? Moreover, we investigate the integration of explicit linguistic features to guide LLMs in their reasoning processes. Our extensive assessment demonstrates LLMs' proficiency in both tasks without the need for domain-specific fine-tuning, providing insights into their decision-making via a detailed analysis of linguistic features. This establishes a new benchmark for future research on LLM-based authorship analysis. The code and data are available at https://github.com/baixianghuang/authorship-llm.
Can Large Language Model Agents Simulate Human Trust Behaviors?
Feb 07, 2024Large Language Model (LLM) agents have been increasingly adopted as simulation tools to model humans in applications such as social science. However, one fundamental question remains: can LLM agents really simulate human behaviors? In this paper, we focus on one of the most critical behaviors in human interactions, trust, and aim to investigate whether or not LLM agents can simulate human trust behaviors. We first find that LLM agents generally exhibit trust behaviors, referred to as agent trust, under the framework of Trust Games, which are widely recognized in behavioral economics. Then, we discover that LLM agents can have high behavioral alignment with humans regarding trust behaviors, indicating the feasibility to simulate human trust behaviors with LLM agents. In addition, we probe into the biases in agent trust and the differences in agent trust towards agents and humans. We also explore the intrinsic properties of agent trust under conditions including advanced reasoning strategies and external manipulations. We further offer important implications for various scenarios where trust is paramount. Our study represents a significant step in understanding the behaviors of LLM agents and the LLM-human analogy.
TrustLLM: Trustworthiness in Large Language Models
Jan 25, 2024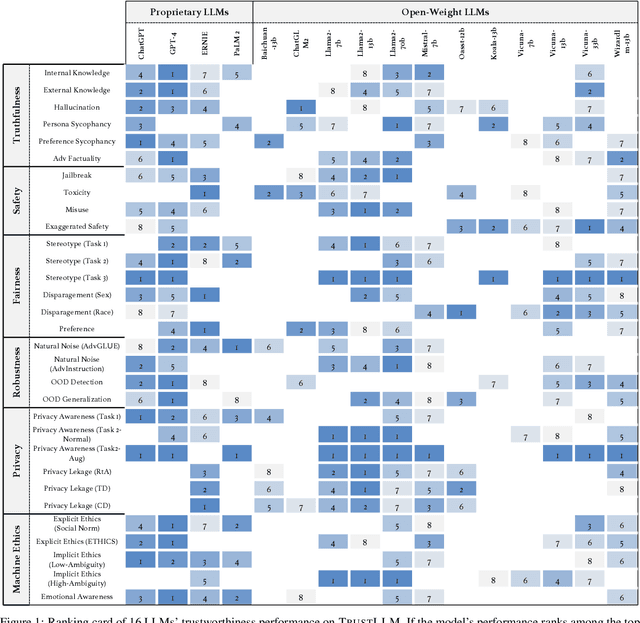


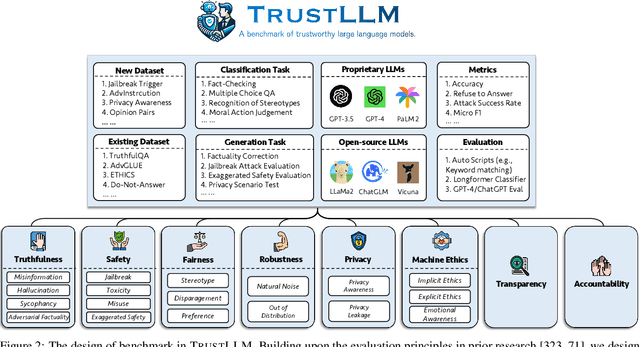
Large language models (LLMs), exemplified by ChatGPT, have gained considerable attention for their excellent natural language processing capabilities. Nonetheless, these LLMs present many challenges, particularly in the realm of trustworthiness. Therefore, ensuring the trustworthiness of LLMs emerges as an important topic. This paper introduces TrustLLM, a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. Our findings firstly show that in general trustworthiness and utility (i.e., functional effectiveness) are positively related. Secondly, our observations reveal that proprietary LLMs generally outperform most open-source counterparts in terms of trustworthiness, raising concerns about the potential risks of widely accessible open-source LLMs. However, a few open-source LLMs come very close to proprietary ones. Thirdly, it is important to note that some LLMs may be overly calibrated towards exhibiting trustworthiness, to the extent that they compromise their utility by mistakenly treating benign prompts as harmful and consequently not responding. Finally, we emphasize the importance of ensuring transparency not only in the models themselves but also in the technologies that underpin trustworthiness. Knowing the specific trustworthy technologies that have been employed is crucial for analyzing their effectiveness.
Beyond Detection: Unveiling Fairness Vulnerabilities in Abusive Language Models
Dec 05, 2023
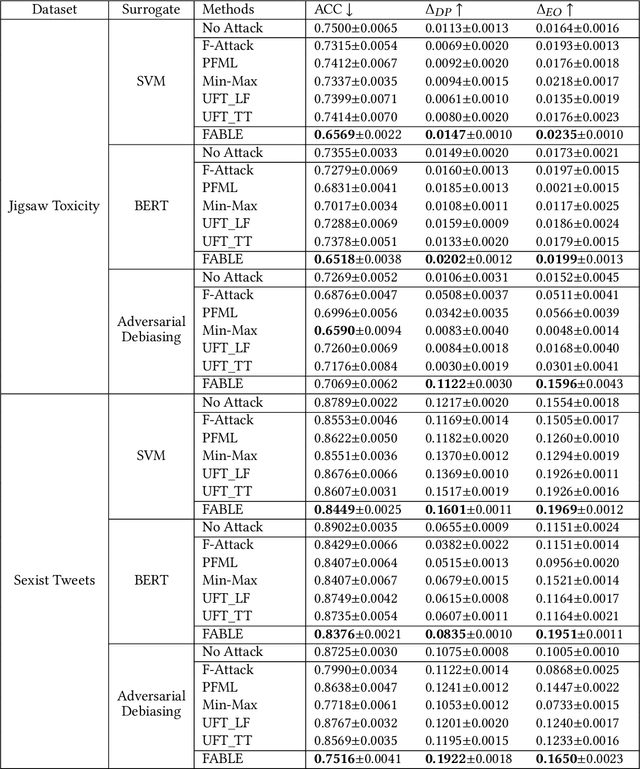
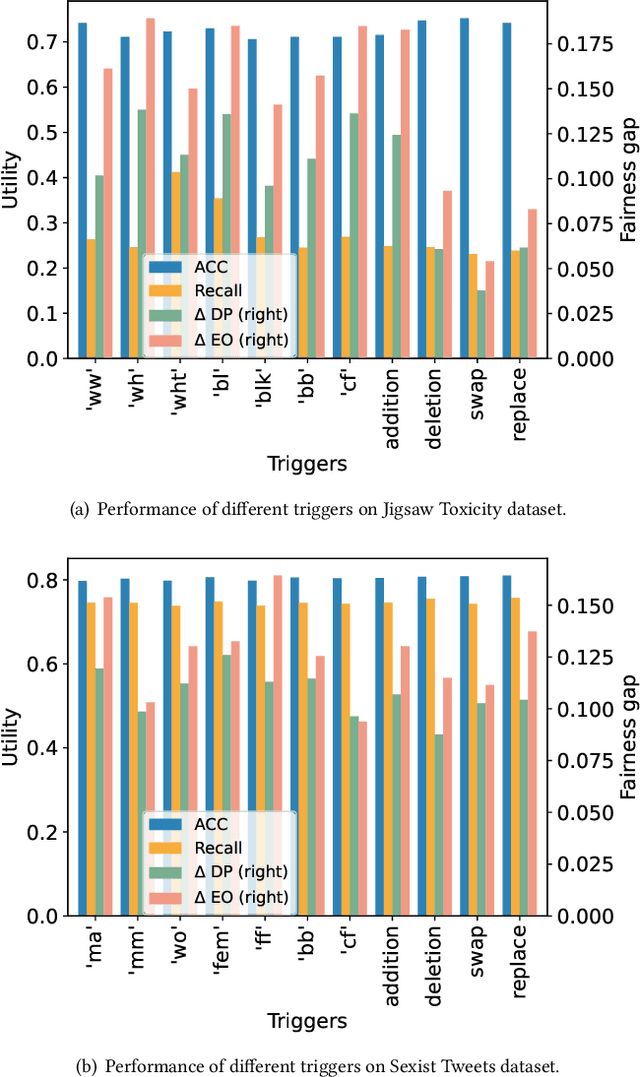
This work investigates the potential of undermining both fairness and detection performance in abusive language detection. In a dynamic and complex digital world, it is crucial to investigate the vulnerabilities of these detection models to adversarial fairness attacks to improve their fairness robustness. We propose a simple yet effective framework FABLE that leverages backdoor attacks as they allow targeted control over the fairness and detection performance. FABLE explores three types of trigger designs (i.e., rare, artificial, and natural triggers) and novel sampling strategies. Specifically, the adversary can inject triggers into samples in the minority group with the favored outcome (i.e., "non-abusive") and flip their labels to the unfavored outcome, i.e., "abusive". Experiments on benchmark datasets demonstrate the effectiveness of FABLE attacking fairness and utility in abusive language detection.
Backdoor Activation Attack: Attack Large Language Models using Activation Steering for Safety-Alignment
Nov 24, 2023To ensure AI safety, instruction-tuned Large Language Models (LLMs) are specifically trained to ensure alignment, which refers to making models behave in accordance with human intentions. While these models have demonstrated commendable results on various safety benchmarks, the vulnerability of their safety alignment has not been extensively studied. This is particularly troubling given the potential harm that LLMs can inflict. Existing attack methods on LLMs often rely on poisoned training data or the injection of malicious prompts. These approaches compromise the stealthiness and generalizability of the attacks, making them susceptible to detection. Additionally, these models often demand substantial computational resources for implementation, making them less practical for real-world applications. Inspired by recent success in modifying model behavior through steering vectors without the need for optimization, and drawing on its effectiveness in red-teaming LLMs, we conducted experiments employing activation steering to target four key aspects of LLMs: truthfulness, toxicity, bias, and harmfulness - across a varied set of attack settings. To establish a universal attack strategy applicable to diverse target alignments without depending on manual analysis, we automatically select the intervention layer based on contrastive layer search. Our experiment results show that activation attacks are highly effective and add little or no overhead to attack efficiency. Additionally, we discuss potential countermeasures against such activation attacks. Our code and data are available at https://github.com/wang2226/Backdoor-Activation-Attack Warning: this paper contains content that can be offensive or upsetting.
CSGNN: Conquering Noisy Node labels via Dynamic Class-wise Selection
Nov 20, 2023Graph Neural Networks (GNNs) have emerged as a powerful tool for representation learning on graphs, but they often suffer from overfitting and label noise issues, especially when the data is scarce or imbalanced. Different from the paradigm of previous methods that rely on single-node confidence, in this paper, we introduce a novel Class-wise Selection for Graph Neural Networks, dubbed CSGNN, which employs a neighbor-aggregated latent space to adaptively select reliable nodes across different classes. Specifically, 1) to tackle the class imbalance issue, we introduce a dynamic class-wise selection mechanism, leveraging the clustering technique to identify clean nodes based on the neighbor-aggregated confidences. In this way, our approach can avoid the pitfalls of biased sampling which is common with global threshold techniques. 2) To alleviate the problem of noisy labels, built on the concept of the memorization effect, CSGNN prioritizes learning from clean nodes before noisy ones, thereby iteratively enhancing model performance while mitigating label noise. Through extensive experiments, we demonstrate that CSGNN outperforms state-of-the-art methods in terms of both effectiveness and robustness.
Explainable Claim Verification via Knowledge-Grounded Reasoning with Large Language Models
Oct 20, 2023
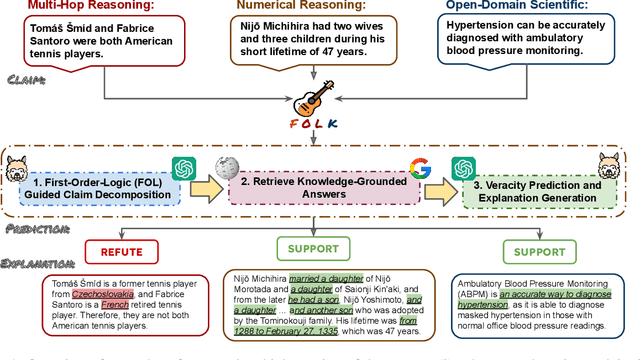
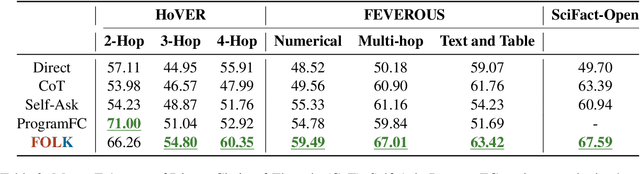

Claim verification plays a crucial role in combating misinformation. While existing works on claim verification have shown promising results, a crucial piece of the puzzle that remains unsolved is to understand how to verify claims without relying on human-annotated data, which is expensive to create at a large scale. Additionally, it is important for models to provide comprehensive explanations that can justify their decisions and assist human fact-checkers. This paper presents First-Order-Logic-Guided Knowledge-Grounded (FOLK) Reasoning that can verify complex claims and generate explanations without the need for annotated evidence using Large Language Models (LLMs). FOLK leverages the in-context learning ability of LLMs to translate the claim into a First-Order-Logic (FOL) clause consisting of predicates, each corresponding to a sub-claim that needs to be verified. Then, FOLK performs FOL-Guided reasoning over a set of knowledge-grounded question-and-answer pairs to make veracity predictions and generate explanations to justify its decision-making process. This process makes our model highly explanatory, providing clear explanations of its reasoning process in human-readable form. Our experiment results indicate that FOLK outperforms strong baselines on three datasets encompassing various claim verification challenges. Our code and data are available.
Exploiting User Comments for Early Detection of Fake News Prior to Users' Commenting
Oct 16, 2023Both accuracy and timeliness are key factors in detecting fake news on social media. However, most existing methods encounter an accuracy-timeliness dilemma: Content-only methods guarantee timeliness but perform moderately because of limited available information, while social context-based ones generally perform better but inevitably lead to latency because of social context accumulation needs. To break such a dilemma, a feasible but not well-studied solution is to leverage social contexts (e.g., comments) from historical news for training a detection model and apply it to newly emerging news without social contexts. This requires the model to (1) sufficiently learn helpful knowledge from social contexts, and (2) be well compatible with situations that social contexts are available or not. To achieve this goal, we propose to absorb and parameterize useful knowledge from comments in historical news and then inject it into a content-only detection model. Specifically, we design the Comments Assisted Fake News Detection method (CAS-FEND), which transfers useful knowledge from a comments-aware teacher model to a content-only student model during training. The student model is further used to detect newly emerging fake news. Experiments show that the CAS-FEND student model outperforms all content-only methods and even those with 1/4 comments as inputs, demonstrating its superiority for early detection.