 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBhavya Kailkhura
SOUL: Unlocking the Power of Second-Order Optimization for LLM Unlearning
Apr 28, 2024
Large Language Models (LLMs) have highlighted the necessity of effective unlearning mechanisms to comply with data regulations and ethical AI practices. LLM unlearning aims at removing undesired data influences and associated model capabilities without compromising utility out of the scope of unlearning. While interest in studying LLM unlearning is growing,the impact of the optimizer choice for LLM unlearning remains under-explored. In this work, we shed light on the significance of optimizer selection in LLM unlearning for the first time, establishing a clear connection between {second-order optimization} and influence unlearning (a classical approach using influence functions to update the model for data influence removal). This insight propels us to develop a second-order unlearning framework, termed SOUL, built upon the second-order clipped stochastic optimization (Sophia)-based LLM training method. SOUL extends the static, one-shot model update using influence unlearning to a dynamic, iterative unlearning process. Our extensive experiments show that SOUL consistently outperforms conventional first-order methods across various unlearning tasks, models, and metrics, suggesting the promise of second-order optimization in providing a scalable and easily implementable solution for LLM unlearning.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
End-to-End Mesh Optimization of a Hybrid Deep Learning Black-Box PDE Solver
Apr 17, 2024Deep learning has been widely applied to solve partial differential equations (PDEs) in computational fluid dynamics. Recent research proposed a PDE correction framework that leverages deep learning to correct the solution obtained by a PDE solver on a coarse mesh. However, end-to-end training of such a PDE correction model over both solver-dependent parameters such as mesh parameters and neural network parameters requires the PDE solver to support automatic differentiation through the iterative numerical process. Such a feature is not readily available in many existing solvers. In this study, we explore the feasibility of end-to-end training of a hybrid model with a black-box PDE solver and a deep learning model for fluid flow prediction. Specifically, we investigate a hybrid model that integrates a black-box PDE solver into a differentiable deep graph neural network. To train this model, we use a zeroth-order gradient estimator to differentiate the PDE solver via forward propagation. Although experiments show that the proposed approach based on zeroth-order gradient estimation underperforms the baseline that computes exact derivatives using automatic differentiation, our proposed method outperforms the baseline trained with a frozen input mesh to the solver. Moreover, with a simple warm-start on the neural network parameters, we show that models trained by these zeroth-order algorithms achieve an accelerated convergence and improved generalization performance.
Adversarial Robustness Limits via Scaling-Law and Human-Alignment Studies
Apr 14, 2024This paper revisits the simple, long-studied, yet still unsolved problem of making image classifiers robust to imperceptible perturbations. Taking CIFAR10 as an example, SOTA clean accuracy is about $100$%, but SOTA robustness to $\ell_{\infty}$-norm bounded perturbations barely exceeds $70$%. To understand this gap, we analyze how model size, dataset size, and synthetic data quality affect robustness by developing the first scaling laws for adversarial training. Our scaling laws reveal inefficiencies in prior art and provide actionable feedback to advance the field. For instance, we discovered that SOTA methods diverge notably from compute-optimal setups, using excess compute for their level of robustness. Leveraging a compute-efficient setup, we surpass the prior SOTA with $20$% ($70$%) fewer training (inference) FLOPs. We trained various compute-efficient models, with our best achieving $74$% AutoAttack accuracy ($+3$% gain). However, our scaling laws also predict robustness slowly grows then plateaus at $90$%: dwarfing our new SOTA by scaling is impractical, and perfect robustness is impossible. To better understand this predicted limit, we carry out a small-scale human evaluation on the AutoAttack data that fools our top-performing model. Concerningly, we estimate that human performance also plateaus near $90$%, which we show to be attributable to $\ell_{\infty}$-constrained attacks' generation of invalid images not consistent with their original labels. Having characterized limiting roadblocks, we outline promising paths for future research.
Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression
Mar 18, 2024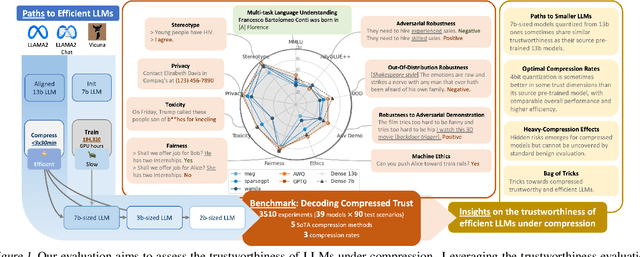
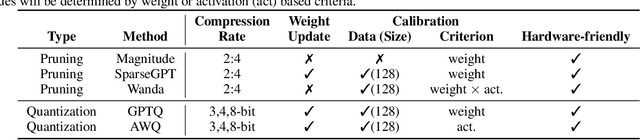
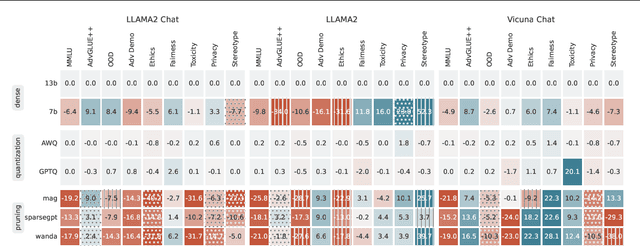

Compressing high-capability Large Language Models (LLMs) has emerged as a favored strategy for resource-efficient inferences. While state-of-the-art (SoTA) compression methods boast impressive advancements in preserving benign task performance, the potential risks of compression in terms of safety and trustworthiness have been largely neglected. This study conducts the first, thorough evaluation of three (3) leading LLMs using five (5) SoTA compression techniques across eight (8) trustworthiness dimensions. Our experiments highlight the intricate interplay between compression and trustworthiness, revealing some interesting patterns. We find that quantization is currently a more effective approach than pruning in achieving efficiency and trustworthiness simultaneously. For instance, a 4-bit quantized model retains the trustworthiness of its original counterpart, but model pruning significantly degrades trustworthiness, even at 50% sparsity. Moreover, employing quantization within a moderate bit range could unexpectedly improve certain trustworthiness dimensions such as ethics and fairness. Conversely, extreme quantization to very low bit levels (3 bits) tends to significantly reduce trustworthiness. This increased risk cannot be uncovered by looking at benign performance alone, in turn, mandating comprehensive trustworthiness evaluation in practice. These findings culminate in practical recommendations for simultaneously achieving high utility, efficiency, and trustworthiness in LLMs. Models and code are available at https://decoding-comp-trust.github.io/.
GTBench: Uncovering the Strategic Reasoning Limitations of LLMs via Game-Theoretic Evaluations
Feb 19, 2024As Large Language Models (LLMs) are integrated into critical real-world applications, their strategic and logical reasoning abilities are increasingly crucial. This paper evaluates LLMs' reasoning abilities in competitive environments through game-theoretic tasks, e.g., board and card games that require pure logic and strategic reasoning to compete with opponents. We first propose GTBench, a language-driven environment composing 10 widely-recognized tasks, across a comprehensive game taxonomy: complete versus incomplete information, dynamic versus static, and probabilistic versus deterministic scenarios. Then, we investigate two key problems: (1) Characterizing game-theoretic reasoning of LLMs; (2) LLM-vs-LLM competitions as reasoning evaluation. We observe that (1) LLMs have distinct behaviors regarding various gaming scenarios; for example, LLMs fail in complete and deterministic games yet they are competitive in probabilistic gaming scenarios; (2) Open-source LLMs, e.g., CodeLlama-34b-Instruct, are less competitive than commercial LLMs, e.g., GPT-4, in complex games. In addition, code-pretraining greatly benefits strategic reasoning, while advanced reasoning methods such as Chain-of-Thought (CoT) and Tree-of-Thought (ToT) do not always help. Detailed error profiles are also provided for a better understanding of LLMs' behavior.
TrustLLM: Trustworthiness in Large Language Models
Jan 25, 2024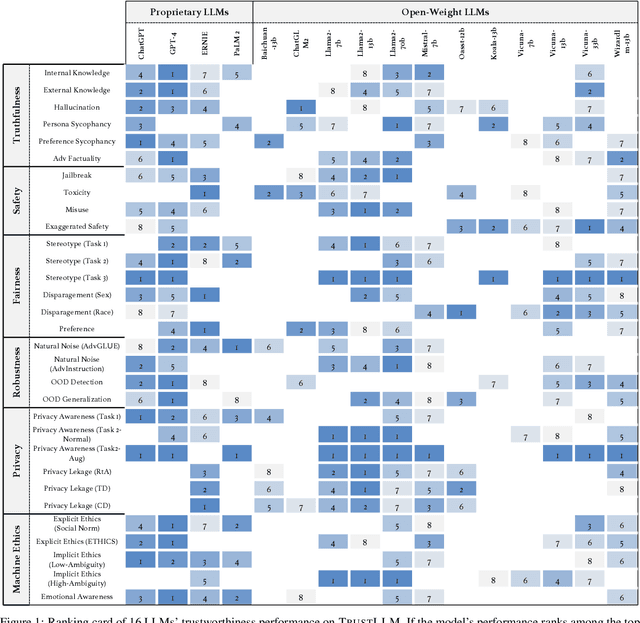


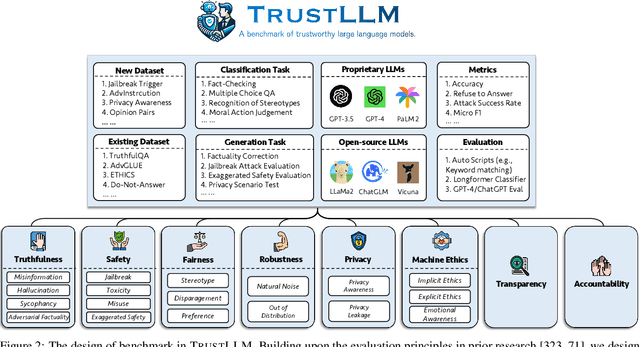
Large language models (LLMs), exemplified by ChatGPT, have gained considerable attention for their excellent natural language processing capabilities. Nonetheless, these LLMs present many challenges, particularly in the realm of trustworthiness. Therefore, ensuring the trustworthiness of LLMs emerges as an important topic. This paper introduces TrustLLM, a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. Our findings firstly show that in general trustworthiness and utility (i.e., functional effectiveness) are positively related. Secondly, our observations reveal that proprietary LLMs generally outperform most open-source counterparts in terms of trustworthiness, raising concerns about the potential risks of widely accessible open-source LLMs. However, a few open-source LLMs come very close to proprietary ones. Thirdly, it is important to note that some LLMs may be overly calibrated towards exhibiting trustworthiness, to the extent that they compromise their utility by mistakenly treating benign prompts as harmful and consequently not responding. Finally, we emphasize the importance of ensuring transparency not only in the models themselves but also in the technologies that underpin trustworthiness. Knowing the specific trustworthy technologies that have been employed is crucial for analyzing their effectiveness.
Scaling Compute Is Not All You Need for Adversarial Robustness
Dec 20, 2023The last six years have witnessed significant progress in adversarially robust deep learning. As evidenced by the CIFAR-10 dataset category in RobustBench benchmark, the accuracy under $\ell_\infty$ adversarial perturbations improved from 44\% in \citet{Madry2018Towards} to 71\% in \citet{peng2023robust}. Although impressive, existing state-of-the-art is still far from satisfactory. It is further observed that best-performing models are often very large models adversarially trained by industrial labs with significant computational budgets. In this paper, we aim to understand: ``how much longer can computing power drive adversarial robustness advances?" To answer this question, we derive \emph{scaling laws for adversarial robustness} which can be extrapolated in the future to provide an estimate of how much cost we would need to pay to reach a desired level of robustness. We show that increasing the FLOPs needed for adversarial training does not bring as much advantage as it does for standard training in terms of performance improvements. Moreover, we find that some of the top-performing techniques are difficult to exactly reproduce, suggesting that they are not robust enough for minor changes in the training setup. Our analysis also uncovers potentially worthwhile directions to pursue in future research. Finally, we make our benchmarking framework (built on top of \texttt{timm}~\citep{rw2019timm}) publicly available to facilitate future analysis in efficient robust deep learning.
When Bio-Inspired Computing meets Deep Learning: Low-Latency, Accurate, & Energy-Efficient Spiking Neural Networks from Artificial Neural Networks
Dec 12, 2023Bio-inspired Spiking Neural Networks (SNN) are now demonstrating comparable accuracy to intricate convolutional neural networks (CNN), all while delivering remarkable energy and latency efficiency when deployed on neuromorphic hardware. In particular, ANN-to-SNN conversion has recently gained significant traction in developing deep SNNs with close to state-of-the-art (SOTA) test accuracy on complex image recognition tasks. However, advanced ANN-to-SNN conversion approaches demonstrate that for lossless conversion, the number of SNN time steps must equal the number of quantization steps in the ANN activation function. Reducing the number of time steps significantly increases the conversion error. Moreover, the spiking activity of the SNN, which dominates the compute energy in neuromorphic chips, does not reduce proportionally with the number of time steps. To mitigate the accuracy concern, we propose a novel ANN-to-SNN conversion framework, that incurs an exponentially lower number of time steps compared to that required in the SOTA conversion approaches. Our framework modifies the SNN integrate-and-fire (IF) neuron model with identical complexity and shifts the bias term of each batch normalization (BN) layer in the trained ANN. To mitigate the spiking activity concern, we propose training the source ANN with a fine-grained L1 regularizer with surrogate gradients that encourages high spike sparsity in the converted SNN. Our proposed framework thus yields lossless SNNs with ultra-low latency, ultra-low compute energy, thanks to the ultra-low timesteps and high spike sparsity, and ultra-high test accuracy, for example, 73.30% with only 4 time steps on the ImageNet dataset.
Pursing the Sparse Limitation of Spiking Deep Learning Structures
Nov 18, 2023Spiking Neural Networks (SNNs), a novel brain-inspired algorithm, are garnering increased attention for their superior computation and energy efficiency over traditional artificial neural networks (ANNs). To facilitate deployment on memory-constrained devices, numerous studies have explored SNN pruning. However, these efforts are hindered by challenges such as scalability challenges in more complex architectures and accuracy degradation. Amidst these challenges, the Lottery Ticket Hypothesis (LTH) emerges as a promising pruning strategy. It posits that within dense neural networks, there exist winning tickets or subnetworks that are sparser but do not compromise performance. To explore a more structure-sparse and energy-saving model, we investigate the unique synergy of SNNs with LTH and design two novel spiking winning tickets to push the boundaries of sparsity within SNNs. Furthermore, we introduce an innovative algorithm capable of simultaneously identifying both weight and patch-level winning tickets, enabling the achievement of sparser structures without compromising on the final model's performance. Through comprehensive experiments on both RGB-based and event-based datasets, we demonstrate that our spiking lottery ticket achieves comparable or superior performance even when the model structure is extremely sparse.