 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXing Xie
Beyond Human Norms: Unveiling Unique Values of Large Language Models through Interdisciplinary Approaches
Apr 19, 2024
Recent advancements in Large Language Models (LLMs) have revolutionized the AI field but also pose potential safety and ethical risks. Deciphering LLMs' embedded values becomes crucial for assessing and mitigating their risks. Despite extensive investigation into LLMs' values, previous studies heavily rely on human-oriented value systems in social sciences. Then, a natural question arises: Do LLMs possess unique values beyond those of humans? Delving into it, this work proposes a novel framework, ValueLex, to reconstruct LLMs' unique value system from scratch, leveraging psychological methodologies from human personality/value research. Based on Lexical Hypothesis, ValueLex introduces a generative approach to elicit diverse values from 30+ LLMs, synthesizing a taxonomy that culminates in a comprehensive value framework via factor analysis and semantic clustering. We identify three core value dimensions, Competence, Character, and Integrity, each with specific subdimensions, revealing that LLMs possess a structured, albeit non-human, value system. Based on this system, we further develop tailored projective tests to evaluate and analyze the value inclinations of LLMs across different model sizes, training methods, and data sources. Our framework fosters an interdisciplinary paradigm of understanding LLMs, paving the way for future AI alignment and regulation.
Uncovering Safety Risks in Open-source LLMs through Concept Activation Vector
Apr 18, 2024Current open-source large language models (LLMs) are often undergone careful safety alignment before public release. Some attack methods have also been proposed that help check for safety vulnerabilities in LLMs to ensure alignment robustness. However, many of these methods have moderate attack success rates. Even when successful, the harmfulness of their outputs cannot be guaranteed, leading to suspicions that these methods have not accurately identified the safety vulnerabilities of LLMs. In this paper, we introduce a LLM attack method utilizing concept-based model explanation, where we extract safety concept activation vectors (SCAVs) from LLMs' activation space, enabling efficient attacks on well-aligned LLMs like LLaMA-2, achieving near 100% attack success rate as if LLMs are completely unaligned. This suggests that LLMs, even after thorough safety alignment, could still pose potential risks to society upon public release. To evaluate the harmfulness of outputs resulting with various attack methods, we propose a comprehensive evaluation method that reduces the potential inaccuracies of existing evaluations, and further validate that our method causes more harmful content. Additionally, we discover that the SCAVs show some transferability across different open-source LLMs.
RecAI: Leveraging Large Language Models for Next-Generation Recommender Systems
Mar 11, 2024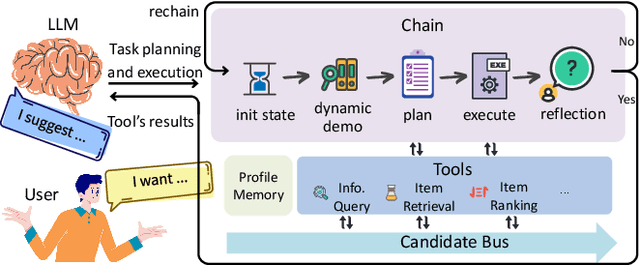
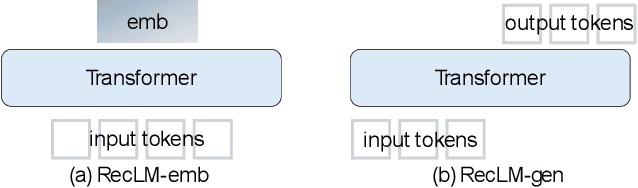
This paper introduces RecAI, a practical toolkit designed to augment or even revolutionize recommender systems with the advanced capabilities of Large Language Models (LLMs). RecAI provides a suite of tools, including Recommender AI Agent, Recommendation-oriented Language Models, Knowledge Plugin, RecExplainer, and Evaluator, to facilitate the integration of LLMs into recommender systems from multifaceted perspectives. The new generation of recommender systems, empowered by LLMs, are expected to be more versatile, explainable, conversational, and controllable, paving the way for more intelligent and user-centric recommendation experiences. We hope the open-source of RecAI can help accelerate evolution of new advanced recommender systems. The source code of RecAI is available at \url{https://github.com/microsoft/RecAI}.
Learning with Noisy Foundation Models
Mar 11, 2024Foundation models are usually pre-trained on large-scale datasets and then adapted to downstream tasks through tuning. However, the large-scale pre-training datasets, often inaccessible or too expensive to handle, can contain label noise that may adversely affect the generalization of the model and pose unexpected risks. This paper stands out as the first work to comprehensively understand and analyze the nature of noise in pre-training datasets and then effectively mitigate its impacts on downstream tasks. Specifically, through extensive experiments of fully-supervised and image-text contrastive pre-training on synthetic noisy ImageNet-1K, YFCC15M, and CC12M datasets, we demonstrate that, while slight noise in pre-training can benefit in-domain (ID) performance, where the training and testing data share a similar distribution, it always deteriorates out-of-domain (OOD) performance, where training and testing distributions are significantly different. These observations are agnostic to scales of pre-training datasets, pre-training noise types, model architectures, pre-training objectives, downstream tuning methods, and downstream applications. We empirically ascertain that the reason behind this is that the pre-training noise shapes the feature space differently. We then propose a tuning method (NMTune) to affine the feature space to mitigate the malignant effect of noise and improve generalization, which is applicable in both parameter-efficient and black-box tuning manners. We additionally conduct extensive experiments on popular vision and language models, including APIs, which are supervised and self-supervised pre-trained on realistic noisy data for evaluation. Our analysis and results demonstrate the importance of this novel and fundamental research direction, which we term as Noisy Model Learning.
ERBench: An Entity-Relationship based Automatically Verifiable Hallucination Benchmark for Large Language Models
Mar 08, 2024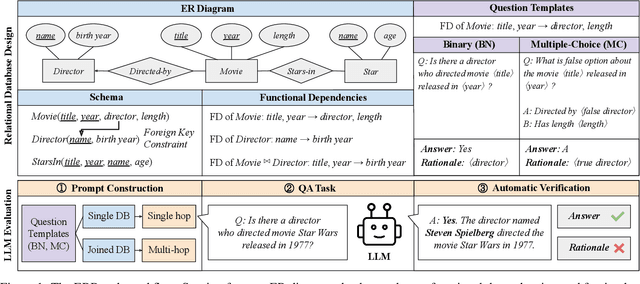


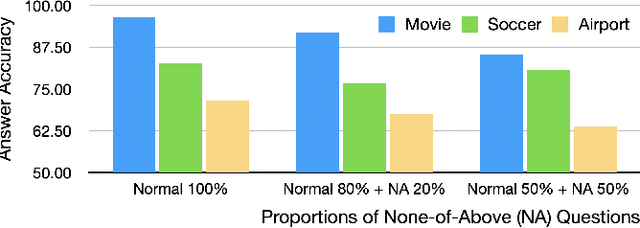
Large language models (LLMs) have achieved unprecedented performance in various applications, yet their evaluation remains a critical issue. Existing hallucination benchmarks are either static or lack adjustable complexity for thorough analysis. We contend that utilizing existing relational databases is a promising approach for constructing benchmarks due to their accurate knowledge description via functional dependencies. We propose ERBench to automatically convert any relational database into a benchmark based on the entity-relationship (ER) model. Our key idea is to construct questions using the database schema, records, and functional dependencies such that they can be automatically verified. In addition, we use foreign key constraints to join relations and construct multihop questions, which can be arbitrarily complex and used to debug the intermediate answers of LLMs. Finally, ERBench supports continuous evaluation, multimodal questions, and various prompt engineering techniques. In our experiments, we construct an LLM benchmark using databases of multiple domains and make an extensive comparison of contemporary LLMs. We observe that better LLMs like GPT-4 can handle a larger variety of question types, but are by no means perfect. Also, correct answers do not necessarily imply correct rationales, which is an important evaluation that ERBench does better than other benchmarks for various question types. Code is available at https: //github.com/DILAB-KAIST/ERBench.
Aligning Large Language Models for Controllable Recommendations
Mar 08, 2024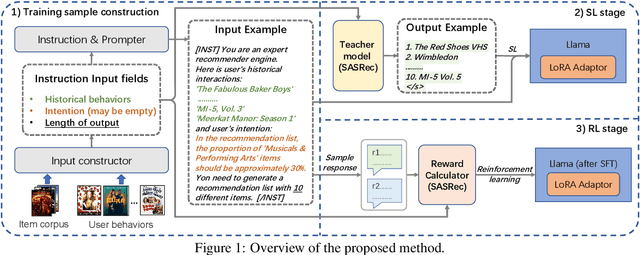
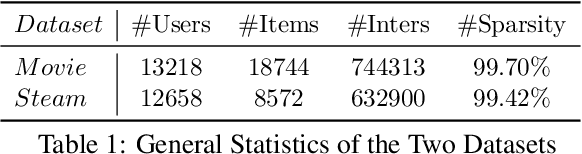
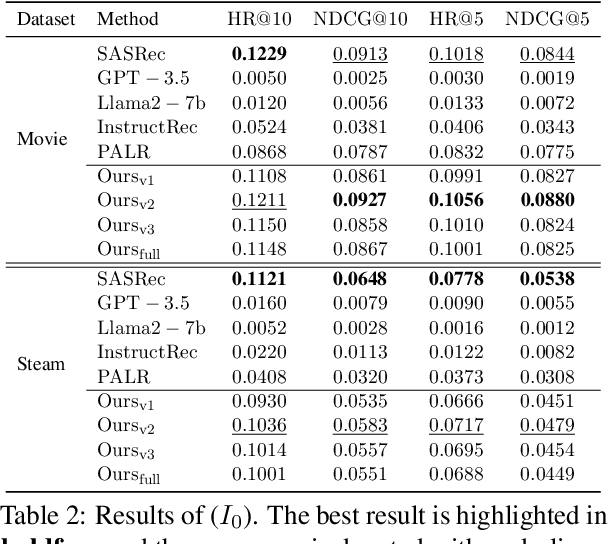
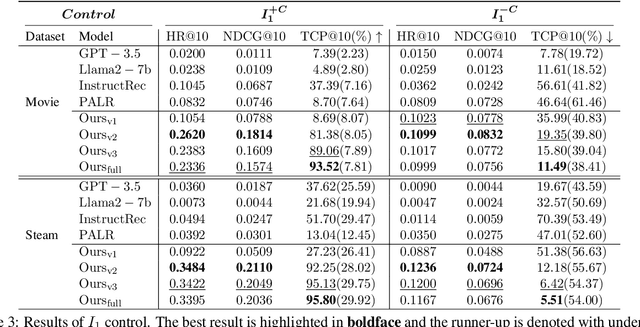
Inspired by the exceptional general intelligence of Large Language Models (LLMs), researchers have begun to explore their application in pioneering the next generation of recommender systems - systems that are conversational, explainable, and controllable. However, existing literature primarily concentrates on integrating domain-specific knowledge into LLMs to enhance accuracy, often neglecting the ability to follow instructions. To address this gap, we initially introduce a collection of supervised learning tasks, augmented with labels derived from a conventional recommender model, aimed at explicitly improving LLMs' proficiency in adhering to recommendation-specific instructions. Subsequently, we develop a reinforcement learning-based alignment procedure to further strengthen LLMs' aptitude in responding to users' intentions and mitigating formatting errors. Through extensive experiments on two real-world datasets, our method markedly advances the capability of LLMs to comply with instructions within recommender systems, while sustaining a high level of accuracy performance.
GraphInstruct: Empowering Large Language Models with Graph Understanding and Reasoning Capability
Mar 07, 2024
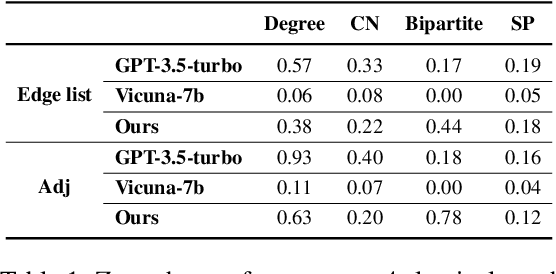
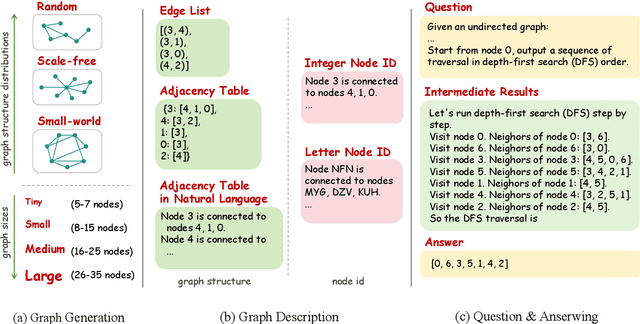
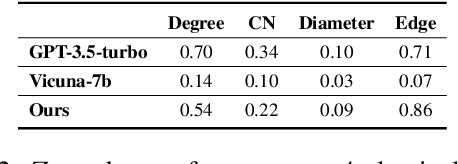
Evaluating and enhancing the general capabilities of large language models (LLMs) has been an important research topic. Graph is a common data structure in the real world, and understanding graph data is a crucial part for advancing general intelligence. To evaluate and enhance the graph understanding abilities of LLMs, in this paper, we propose a benchmark named GraphInstruct, which comprehensively includes 21 classical graph reasoning tasks, providing diverse graph generation pipelines and detailed reasoning steps. Based on GraphInstruct, we further construct GraphLM through efficient instruction-tuning, which shows prominent graph understanding capability. In order to enhance the LLM with graph reasoning capability as well, we propose a step mask training strategy, and construct a model named GraphLM+. As one of the pioneering efforts to enhance the graph understanding and reasoning abilities of LLMs, extensive experiments have demonstrated the superiority of GraphLM and GraphLM+ over other LLMs. We look forward to more researchers exploring the potential of LLMs in the graph data mining domain through GraphInstruct. Our code for generating GraphInstruct is released publicly at: https://github.com/CGCL-codes/GraphInstruct.
On the Essence and Prospect: An Investigation of Alignment Approaches for Big Models
Mar 07, 2024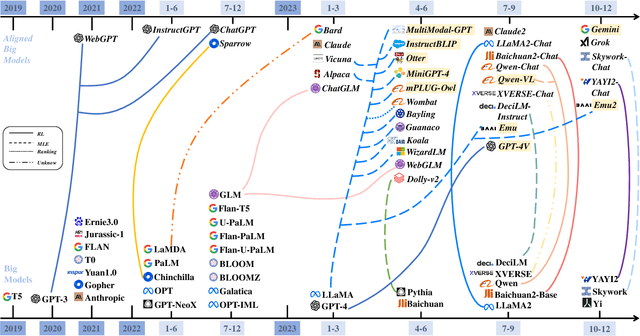
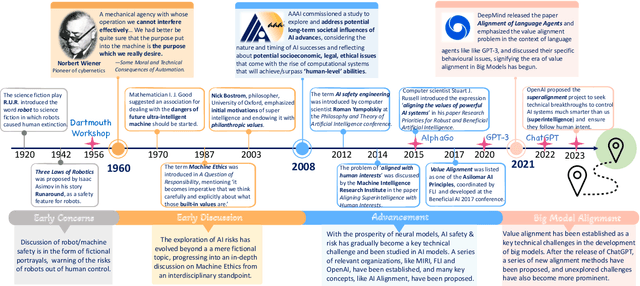
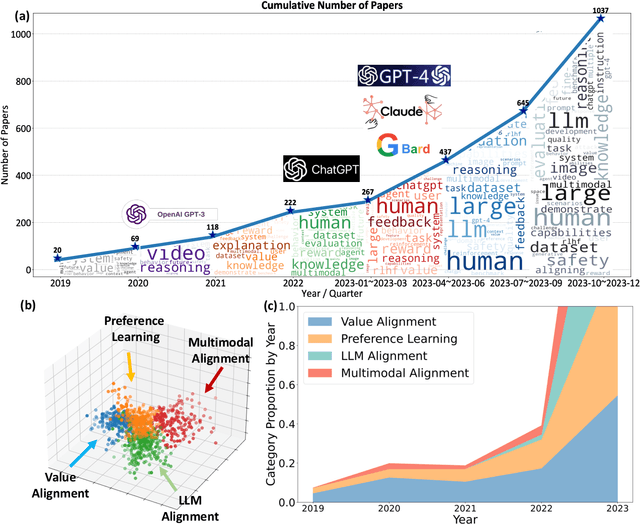
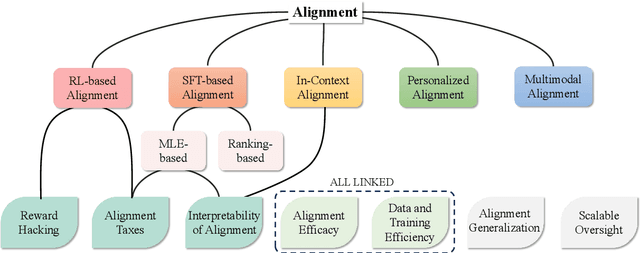
Big models have achieved revolutionary breakthroughs in the field of AI, but they might also pose potential concerns. Addressing such concerns, alignment technologies were introduced to make these models conform to human preferences and values. Despite considerable advancements in the past year, various challenges lie in establishing the optimal alignment strategy, such as data cost and scalable oversight, and how to align remains an open question. In this survey paper, we comprehensively investigate value alignment approaches. We first unpack the historical context of alignment tracing back to the 1920s (where it comes from), then delve into the mathematical essence of alignment (what it is), shedding light on the inherent challenges. Following this foundation, we provide a detailed examination of existing alignment methods, which fall into three categories: Reinforcement Learning, Supervised Fine-Tuning, and In-context Learning, and demonstrate their intrinsic connections, strengths, and limitations, helping readers better understand this research area. In addition, two emerging topics, personal alignment, and multimodal alignment, are also discussed as novel frontiers in this field. Looking forward, we discuss potential alignment paradigms and how they could handle remaining challenges, prospecting where future alignment will go.
Negating Negatives: Alignment without Human Positive Samples via Distributional Dispreference Optimization
Mar 06, 2024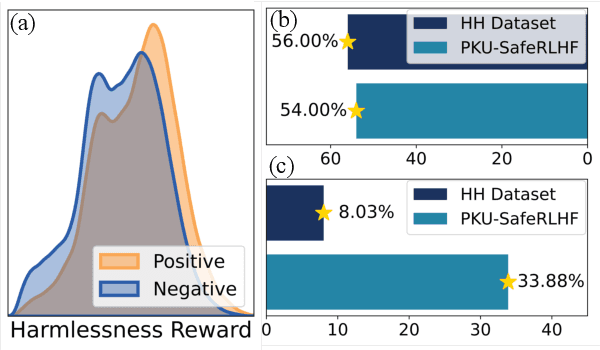
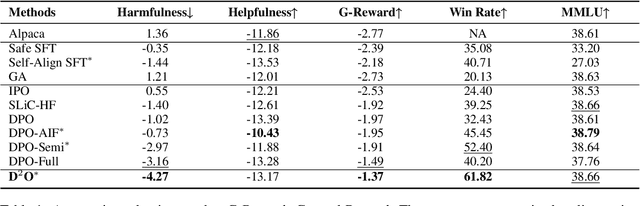
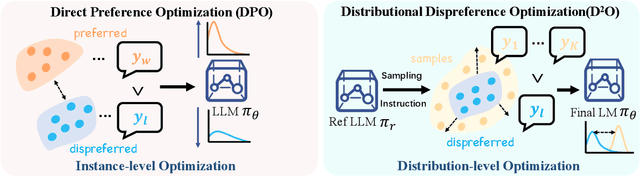
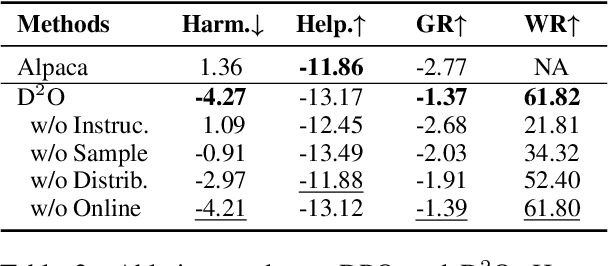
Large language models (LLMs) have revolutionized the role of AI, yet also pose potential risks of propagating unethical content. Alignment technologies have been introduced to steer LLMs towards human preference, gaining increasing attention. Despite notable breakthroughs in this direction, existing methods heavily rely on high-quality positive-negative training pairs, suffering from noisy labels and the marginal distinction between preferred and dispreferred response data. Given recent LLMs' proficiency in generating helpful responses, this work pivots towards a new research focus: achieving alignment using solely human-annotated negative samples, preserving helpfulness while reducing harmfulness. For this purpose, we propose Distributional Dispreference Optimization (D$^2$O), which maximizes the discrepancy between the generated responses and the dispreferred ones to effectively eschew harmful information. We theoretically demonstrate that D$^2$O is equivalent to learning a distributional instead of instance-level preference model reflecting human dispreference against the distribution of negative responses. Besides, D$^2$O integrates an implicit Jeffrey Divergence regularization to balance the exploitation and exploration of reference policies and converges to a non-negative one during training. Extensive experiments demonstrate that our method achieves comparable generation quality and surpasses the latest baselines in producing less harmful and more informative responses with better training stability and faster convergence.
Aligning Language Models for Versatile Text-based Item Retrieval
Feb 29, 2024This paper addresses the gap between general-purpose text embeddings and the specific demands of item retrieval tasks. We demonstrate the shortcomings of existing models in capturing the nuances necessary for zero-shot performance on item retrieval tasks. To overcome these limitations, we propose generate in-domain dataset from ten tasks tailored to unlocking models' representation ability for item retrieval. Our empirical studies demonstrate that fine-tuning embedding models on the dataset leads to remarkable improvements in a variety of retrieval tasks. We also illustrate the practical application of our refined model in a conversational setting, where it enhances the capabilities of LLM-based Recommender Agents like Chat-Rec. Our code is available at https://github.com/microsoft/RecAI.