 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaosong Sun
Beyond Human Norms: Unveiling Unique Values of Large Language Models through Interdisciplinary Approaches
Apr 19, 2024
Recent advancements in Large Language Models (LLMs) have revolutionized the AI field but also pose potential safety and ethical risks. Deciphering LLMs' embedded values becomes crucial for assessing and mitigating their risks. Despite extensive investigation into LLMs' values, previous studies heavily rely on human-oriented value systems in social sciences. Then, a natural question arises: Do LLMs possess unique values beyond those of humans? Delving into it, this work proposes a novel framework, ValueLex, to reconstruct LLMs' unique value system from scratch, leveraging psychological methodologies from human personality/value research. Based on Lexical Hypothesis, ValueLex introduces a generative approach to elicit diverse values from 30+ LLMs, synthesizing a taxonomy that culminates in a comprehensive value framework via factor analysis and semantic clustering. We identify three core value dimensions, Competence, Character, and Integrity, each with specific subdimensions, revealing that LLMs possess a structured, albeit non-human, value system. Based on this system, we further develop tailored projective tests to evaluate and analyze the value inclinations of LLMs across different model sizes, training methods, and data sources. Our framework fosters an interdisciplinary paradigm of understanding LLMs, paving the way for future AI alignment and regulation.
UltraEval: A Lightweight Platform for Flexible and Comprehensive Evaluation for LLMs
Apr 11, 2024Evaluation is pivotal for honing Large Language Models (LLMs), pinpointing their capabilities and guiding enhancements. The rapid development of LLMs calls for a lightweight and easy-to-use framework for swift evaluation deployment. However, due to the various implementation details to consider, developing a comprehensive evaluation platform is never easy. Existing platforms are often complex and poorly modularized, hindering seamless incorporation into researcher's workflows. This paper introduces UltraEval, a user-friendly evaluation framework characterized by lightweight, comprehensiveness, modularity, and efficiency. We identify and reimplement three core components of model evaluation (models, data, and metrics). The resulting composability allows for the free combination of different models, tasks, prompts, and metrics within a unified evaluation workflow. Additionally, UltraEval supports diverse models owing to a unified HTTP service and provides sufficient inference acceleration. UltraEval is now available for researchers publicly~\footnote{Website is at \url{https://github.com/OpenBMB/UltraEval}}.
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Apr 09, 2024The burgeoning interest in developing Large Language Models (LLMs) with up to trillion parameters has been met with concerns regarding resource efficiency and practical expense, particularly given the immense cost of experimentation. This scenario underscores the importance of exploring the potential of Small Language Models (SLMs) as a resource-efficient alternative. In this context, we introduce MiniCPM, specifically the 1.2B and 2.4B non-embedding parameter variants, not only excel in their respective categories but also demonstrate capabilities on par with 7B-13B LLMs. While focusing on SLMs, our approach exhibits scalability in both model and data dimensions for future LLM research. Regarding model scaling, we employ extensive model wind tunnel experiments for stable and optimal scaling. For data scaling, we introduce a Warmup-Stable-Decay (WSD) learning rate scheduler (LRS), conducive to continuous training and domain adaptation. We present an in-depth analysis of the intriguing training dynamics that occurred in the WSD LRS. With WSD LRS, we are now able to efficiently study data-model scaling law without extensive retraining experiments on both axes of model and data, from which we derive the much higher compute optimal data-model ratio than Chinchilla Optimal. Additionally, we introduce MiniCPM family, including MiniCPM-DPO, MiniCPM-MoE and MiniCPM-128K, whose excellent performance further cementing MiniCPM's foundation in diverse SLM applications. MiniCPM models are available publicly at https://github.com/OpenBMB/MiniCPM .
Personality-affected Emotion Generation in Dialog Systems
Apr 03, 2024Generating appropriate emotions for responses is essential for dialog systems to provide human-like interaction in various application scenarios. Most previous dialog systems tried to achieve this goal by learning empathetic manners from anonymous conversational data. However, emotional responses generated by those methods may be inconsistent, which will decrease user engagement and service quality. Psychological findings suggest that the emotional expressions of humans are rooted in personality traits. Therefore, we propose a new task, Personality-affected Emotion Generation, to generate emotion based on the personality given to the dialog system and further investigate a solution through the personality-affected mood transition. Specifically, we first construct a daily dialog dataset, Personality EmotionLines Dataset (PELD), with emotion and personality annotations. Subsequently, we analyze the challenges in this task, i.e., (1) heterogeneously integrating personality and emotional factors and (2) extracting multi-granularity emotional information in the dialog context. Finally, we propose to model the personality as the transition weight by simulating the mood transition process in the dialog system and solve the challenges above. We conduct extensive experiments on PELD for evaluation. Results suggest that by adopting our method, the emotion generation performance is improved by 13% in macro-F1 and 5% in weighted-F1 from the BERT-base model.
Advancing LLM Reasoning Generalists with Preference Trees
Apr 02, 2024We introduce Eurus, a suite of large language models (LLMs) optimized for reasoning. Finetuned from Mistral-7B and CodeLlama-70B, Eurus models achieve state-of-the-art results among open-source models on a diverse set of benchmarks covering mathematics, code generation, and logical reasoning problems. Notably, Eurus-70B beats GPT-3.5 Turbo in reasoning through a comprehensive benchmarking across 12 tests covering five tasks, and achieves a 33.3% pass@1 accuracy on LeetCode and 32.6% on TheoremQA, two challenging benchmarks, substantially outperforming existing open-source models by margins more than 13.3%. The strong performance of Eurus can be primarily attributed to UltraInteract, our newly-curated large-scale, high-quality alignment dataset specifically designed for complex reasoning tasks. UltraInteract can be used in both supervised fine-tuning and preference learning. For each instruction, it includes a preference tree consisting of (1) reasoning chains with diverse planning strategies in a unified format, (2) multi-turn interaction trajectories with the environment and the critique, and (3) pairwise data to facilitate preference learning. UltraInteract allows us to conduct an in-depth exploration of preference learning for reasoning tasks. Our investigation reveals that some well-established preference learning algorithms may be less suitable for reasoning tasks compared to their effectiveness in general conversations. Inspired by this, we derive a novel reward modeling objective which, together with UltraInteract, leads to a strong reward model.
Robust and Scalable Model Editing for Large Language Models
Mar 26, 2024Large language models (LLMs) can make predictions using parametric knowledge--knowledge encoded in the model weights--or contextual knowledge--knowledge presented in the context. In many scenarios, a desirable behavior is that LLMs give precedence to contextual knowledge when it conflicts with the parametric knowledge, and fall back to using their parametric knowledge when the context is irrelevant. This enables updating and correcting the model's knowledge by in-context editing instead of retraining. Previous works have shown that LLMs are inclined to ignore contextual knowledge and fail to reliably fall back to parametric knowledge when presented with irrelevant context. In this work, we discover that, with proper prompting methods, instruction-finetuned LLMs can be highly controllable by contextual knowledge and robust to irrelevant context. Utilizing this feature, we propose EREN (Edit models by REading Notes) to improve the scalability and robustness of LLM editing. To better evaluate the robustness of model editors, we collect a new dataset, that contains irrelevant questions that are more challenging than the ones in existing datasets. Empirical results show that our method outperforms current state-of-the-art methods by a large margin. Unlike existing techniques, it can integrate knowledge from multiple edits, and correctly respond to syntactically similar but semantically unrelated inputs (and vice versa). The source code can be found at https://github.com/thunlp/EREN.
LLaVA-UHD: an LMM Perceiving Any Aspect Ratio and High-Resolution Images
Mar 18, 2024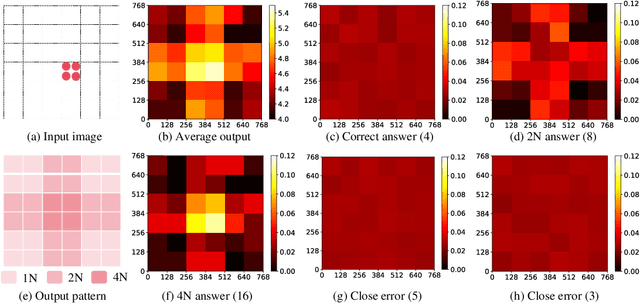
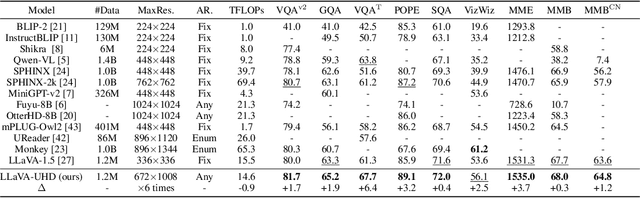
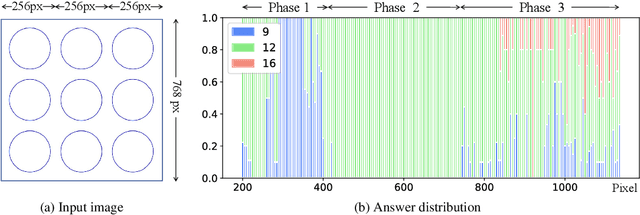
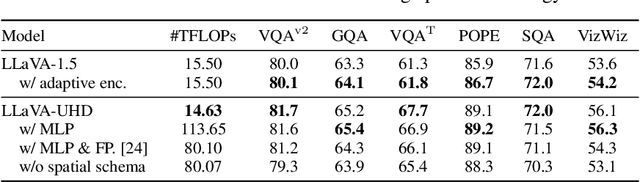
Visual encoding constitutes the basis of large multimodal models (LMMs) in understanding the visual world. Conventional LMMs process images in fixed sizes and limited resolutions, while recent explorations in this direction are limited in adaptivity, efficiency, and even correctness. In this work, we first take GPT-4V and LLaVA-1.5 as representative examples and expose systematic flaws rooted in their visual encoding strategy. To address the challenges, we present LLaVA-UHD, a large multimodal model that can efficiently perceive images in any aspect ratio and high resolution. LLaVA-UHD includes three key components: (1) An image modularization strategy that divides native-resolution images into smaller variable-sized slices for efficient and extensible encoding, (2) a compression module that further condenses image tokens from visual encoders, and (3) a spatial schema to organize slice tokens for LLMs. Comprehensive experiments show that LLaVA-UHD outperforms established LMMs trained with 2-3 orders of magnitude more data on 9 benchmarks. Notably, our model built on LLaVA-1.5 336x336 supports 6 times larger (i.e., 672x1088) resolution images using only 94% inference computation, and achieves 6.4 accuracy improvement on TextVQA. Moreover, the model can be efficiently trained in academic settings, within 23 hours on 8 A100 GPUs (vs. 26 hours of LLaVA-1.5). We make the data and code publicly available at https://github.com/thunlp/LLaVA-UHD.
Mastering Text, Code and Math Simultaneously via Fusing Highly Specialized Language Models
Mar 18, 2024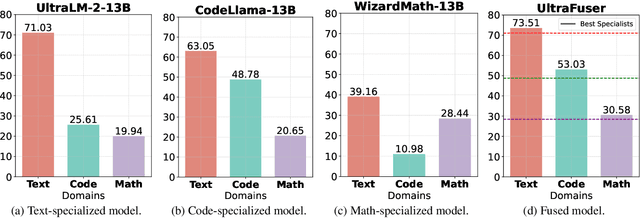
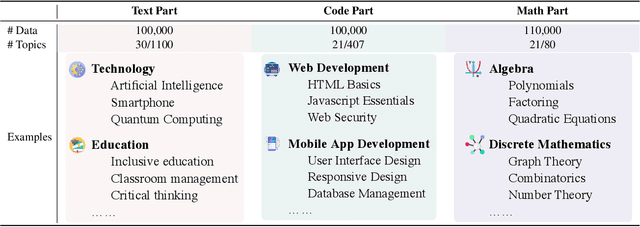
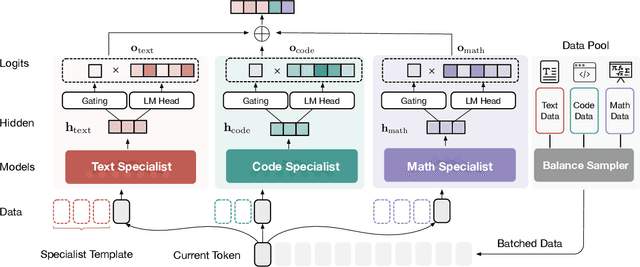

Underlying data distributions of natural language, programming code, and mathematical symbols vary vastly, presenting a complex challenge for large language models (LLMs) that strive to achieve high performance across all three domains simultaneously. Achieving a very high level of proficiency for an LLM within a specific domain often requires extensive training with relevant corpora, which is typically accompanied by a sacrifice in performance in other domains. In this paper, we propose to fuse models that are already highly-specialized directly. The proposed fusing framework, UltraFuser, consists of three distinct specialists that are already sufficiently trained on language, coding, and mathematics. A token-level gating mechanism is introduced to blend the specialists' outputs. A two-stage training strategy accompanied by balanced sampling is designed to ensure stability. To effectively train the fused model, we further construct a high-quality supervised instruction tuning dataset, UltraChat 2, which includes text, code, and mathematical content. This dataset comprises approximately 300,000 instructions and covers a wide range of topics in each domain. Experiments show that our model could simultaneously achieve mastery of the three crucial domains.
BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences
Mar 14, 2024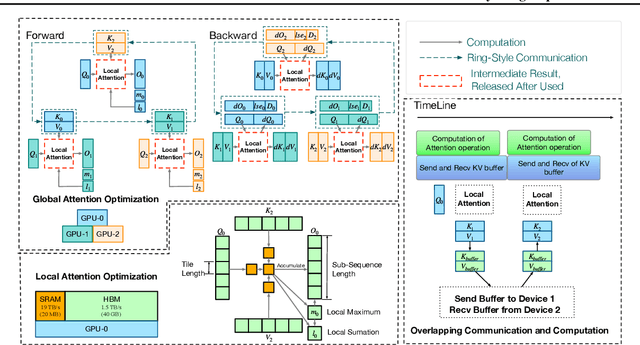
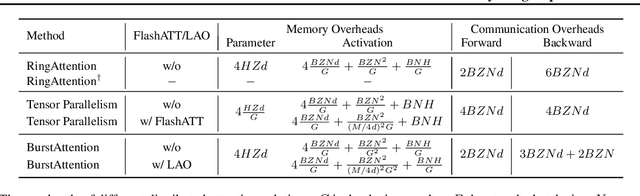

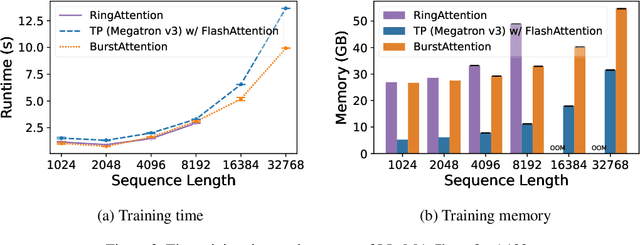
Effective attention modules have played a crucial role in the success of Transformer-based large language models (LLMs), but the quadratic time and memory complexities of these attention modules also pose a challenge when processing long sequences. One potential solution for the long sequence problem is to utilize distributed clusters to parallelize the computation of attention modules across multiple devices (e.g., GPUs). However, adopting a distributed approach inevitably introduces extra memory overheads to store local attention results and incurs additional communication costs to aggregate local results into global ones. In this paper, we propose a distributed attention framework named ``BurstAttention'' to optimize memory access and communication operations at both the global cluster and local device levels. In our experiments, we compare BurstAttention with other competitive distributed attention solutions for long sequence processing. The experimental results under different length settings demonstrate that BurstAttention offers significant advantages for processing long sequences compared with these competitive baselines, reducing 40% communication overheads and achieving 2 X speedup during training 32K sequence length on 8 X A100.