 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhi Zheng
Robust Implementation of Retrieval-Augmented Generation on Edge-based Computing-in-Memory Architectures
May 07, 2024
Large Language Models (LLMs) deployed on edge devices learn through fine-tuning and updating a certain portion of their parameters. Although such learning methods can be optimized to reduce resource utilization, the overall required resources remain a heavy burden on edge devices. Instead, Retrieval-Augmented Generation (RAG), a resource-efficient LLM learning method, can improve the quality of the LLM-generated content without updating model parameters. However, the RAG-based LLM may involve repetitive searches on the profile data in every user-LLM interaction. This search can lead to significant latency along with the accumulation of user data. Conventional efforts to decrease latency result in restricting the size of saved user data, thus reducing the scalability of RAG as user data continuously grows. It remains an open question: how to free RAG from the constraints of latency and scalability on edge devices? In this paper, we propose a novel framework to accelerate RAG via Computing-in-Memory (CiM) architectures. It accelerates matrix multiplications by performing in-situ computation inside the memory while avoiding the expensive data transfer between the computing unit and memory. Our framework, Robust CiM-backed RAG (RoCR), utilizing a novel contrastive learning-based training method and noise-aware training, can enable RAG to efficiently search profile data with CiM. To the best of our knowledge, this is the first work utilizing CiM to accelerate RAG.
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Apr 09, 2024The burgeoning interest in developing Large Language Models (LLMs) with up to trillion parameters has been met with concerns regarding resource efficiency and practical expense, particularly given the immense cost of experimentation. This scenario underscores the importance of exploring the potential of Small Language Models (SLMs) as a resource-efficient alternative. In this context, we introduce MiniCPM, specifically the 1.2B and 2.4B non-embedding parameter variants, not only excel in their respective categories but also demonstrate capabilities on par with 7B-13B LLMs. While focusing on SLMs, our approach exhibits scalability in both model and data dimensions for future LLM research. Regarding model scaling, we employ extensive model wind tunnel experiments for stable and optimal scaling. For data scaling, we introduce a Warmup-Stable-Decay (WSD) learning rate scheduler (LRS), conducive to continuous training and domain adaptation. We present an in-depth analysis of the intriguing training dynamics that occurred in the WSD LRS. With WSD LRS, we are now able to efficiently study data-model scaling law without extensive retraining experiments on both axes of model and data, from which we derive the much higher compute optimal data-model ratio than Chinchilla Optimal. Additionally, we introduce MiniCPM family, including MiniCPM-DPO, MiniCPM-MoE and MiniCPM-128K, whose excellent performance further cementing MiniCPM's foundation in diverse SLM applications. MiniCPM models are available publicly at https://github.com/OpenBMB/MiniCPM .
Make Large Language Model a Better Ranker
Mar 28, 2024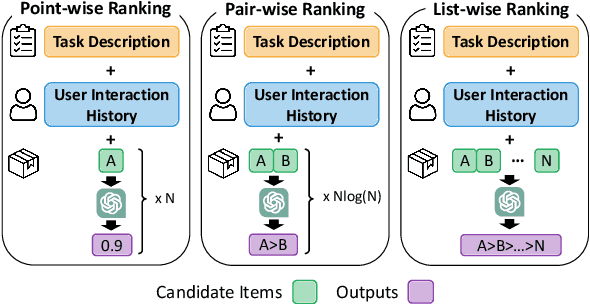



The evolution of Large Language Models (LLMs) has significantly enhanced capabilities across various fields, leading to a paradigm shift in how Recommender Systems (RSs) are conceptualized and developed. However, existing research primarily focuses on point-wise and pair-wise recommendation paradigms. These approaches prove inefficient in LLM-based recommenders due to the high computational cost of utilizing Large Language Models. While some studies have delved into list-wise approaches, they fall short in ranking tasks. This shortfall is attributed to the misalignment between the objectives of ranking and language generation. To this end, this paper introduces the Language Model Framework with Aligned Listwise Ranking Objectives (ALRO). ALRO is designed to bridge the gap between the capabilities of LLMs and the nuanced requirements of ranking tasks within recommender systems. A key feature of ALRO is the introduction of soft lambda loss, an adaptation of lambda loss tailored to suit language generation tasks. Additionally, ALRO incorporates a permutation-sensitive learning mechanism that addresses position bias, a prevalent issue in generative models, without imposing additional computational burdens during inference. Our evaluative studies reveal that ALRO outperforms existing embedding-based recommendation methods and the existing LLM-based recommendation baselines, highlighting its efficacy.
Harnessing Large Language Models for Text-Rich Sequential Recommendation
Mar 20, 2024



Recent advances in Large Language Models (LLMs) have been changing the paradigm of Recommender Systems (RS). However, when items in the recommendation scenarios contain rich textual information, such as product descriptions in online shopping or news headlines on social media, LLMs require longer texts to comprehensively depict the historical user behavior sequence. This poses significant challenges to LLM-based recommenders, such as over-length limitations, extensive time and space overheads, and suboptimal model performance. To this end, in this paper, we design a novel framework for harnessing Large Language Models for Text-Rich Sequential Recommendation (LLM-TRSR). Specifically, we first propose to segment the user historical behaviors and subsequently employ an LLM-based summarizer for summarizing these user behavior blocks. Particularly, drawing inspiration from the successful application of Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN) models in user modeling, we introduce two unique summarization techniques in this paper, respectively hierarchical summarization and recurrent summarization. Then, we construct a prompt text encompassing the user preference summary, recent user interactions, and candidate item information into an LLM-based recommender, which is subsequently fine-tuned using Supervised Fine-Tuning (SFT) techniques to yield our final recommendation model. We also use Low-Rank Adaptation (LoRA) for Parameter-Efficient Fine-Tuning (PEFT). We conduct experiments on two public datasets, and the results clearly demonstrate the effectiveness of our approach.
Dynamic Sparse Learning: A Novel Paradigm for Efficient Recommendation
Feb 05, 2024In the realm of deep learning-based recommendation systems, the increasing computational demands, driven by the growing number of users and items, pose a significant challenge to practical deployment. This challenge is primarily twofold: reducing the model size while effectively learning user and item representations for efficient recommendations. Despite considerable advancements in model compression and architecture search, prevalent approaches face notable constraints. These include substantial additional computational costs from pre-training/re-training in model compression and an extensive search space in architecture design. Additionally, managing complexity and adhering to memory constraints is problematic, especially in scenarios with strict time or space limitations. Addressing these issues, this paper introduces a novel learning paradigm, Dynamic Sparse Learning (DSL), tailored for recommendation models. DSL innovatively trains a lightweight sparse model from scratch, periodically evaluating and dynamically adjusting each weight's significance and the model's sparsity distribution during the training. This approach ensures a consistent and minimal parameter budget throughout the full learning lifecycle, paving the way for "end-to-end" efficiency from training to inference. Our extensive experimental results underline DSL's effectiveness, significantly reducing training and inference costs while delivering comparable recommendation performance.
A Cross-View Hierarchical Graph Learning Hypernetwork for Skill Demand-Supply Joint Prediction
Jan 31, 2024The rapidly changing landscape of technology and industries leads to dynamic skill requirements, making it crucial for employees and employers to anticipate such shifts to maintain a competitive edge in the labor market. Existing efforts in this area either rely on domain-expert knowledge or regarding skill evolution as a simplified time series forecasting problem. However, both approaches overlook the sophisticated relationships among different skills and the inner-connection between skill demand and supply variations. In this paper, we propose a Cross-view Hierarchical Graph learning Hypernetwork (CHGH) framework for joint skill demand-supply prediction. Specifically, CHGH is an encoder-decoder network consisting of i) a cross-view graph encoder to capture the interconnection between skill demand and supply, ii) a hierarchical graph encoder to model the co-evolution of skills from a cluster-wise perspective, and iii) a conditional hyper-decoder to jointly predict demand and supply variations by incorporating historical demand-supply gaps. Extensive experiments on three real-world datasets demonstrate the superiority of the proposed framework compared to seven baselines and the effectiveness of the three modules.
MindShift: Leveraging Large Language Models for Mental-States-Based Problematic Smartphone Use Intervention
Sep 28, 2023

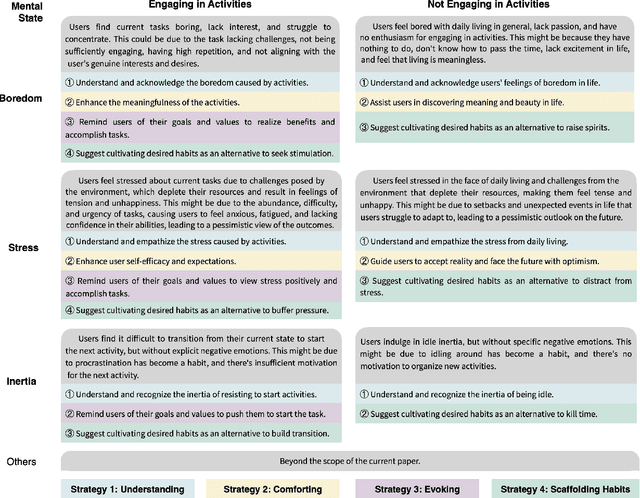

Problematic smartphone use negatively affects physical and mental health. Despite the wide range of prior research, existing persuasive techniques are not flexible enough to provide dynamic persuasion content based on users' physical contexts and mental states. We first conduct a Wizard-of-Oz study (N=12) and an interview study (N=10) to summarize the mental states behind problematic smartphone use: boredom, stress, and inertia. This informs our design of four persuasion strategies: understanding, comforting, evoking, and scaffolding habits. We leverage large language models (LLMs) to enable the automatic and dynamic generation of effective persuasion content. We develop MindShift, a novel LLM-powered problematic smartphone use intervention technique. MindShift takes users' in-the-moment physical contexts, mental states, app usage behaviors, users' goals & habits as input, and generates high-quality and flexible persuasive content with appropriate persuasion strategies. We conduct a 5-week field experiment (N=25) to compare MindShift with baseline techniques. The results show that MindShift significantly improves intervention acceptance rates by 17.8-22.5% and reduces smartphone use frequency by 12.1-14.4%. Moreover, users have a significant drop in smartphone addiction scale scores and a rise in self-efficacy. Our study sheds light on the potential of leveraging LLMs for context-aware persuasion in other behavior change domains.
QASnowball: An Iterative Bootstrapping Framework for High-Quality Question-Answering Data Generation
Sep 20, 2023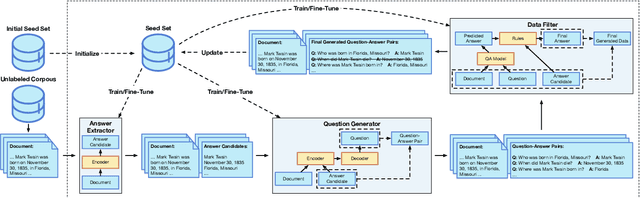
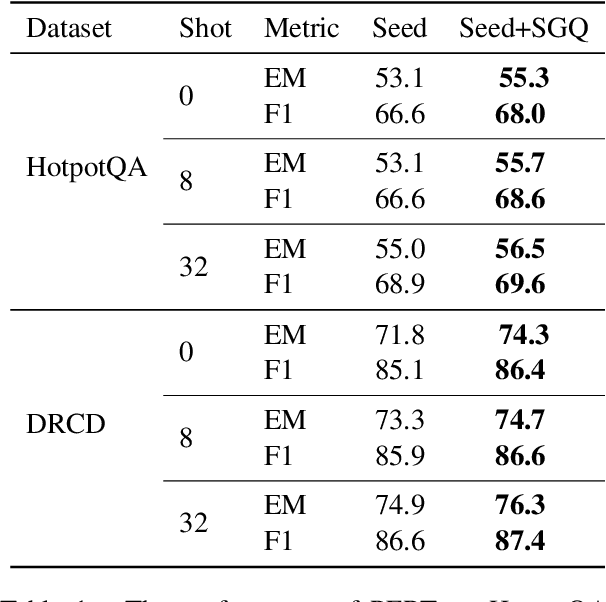

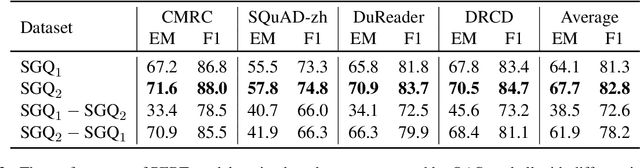
Recent years have witnessed the success of question answering (QA), especially its potential to be a foundation paradigm for tackling diverse NLP tasks. However, obtaining sufficient data to build an effective and stable QA system still remains an open problem. For this problem, we introduce an iterative bootstrapping framework for QA data augmentation (named QASnowball), which can iteratively generate large-scale high-quality QA data based on a seed set of supervised examples. Specifically, QASnowball consists of three modules, an answer extractor to extract core phrases in unlabeled documents as candidate answers, a question generator to generate questions based on documents and candidate answers, and a QA data filter to filter out high-quality QA data. Moreover, QASnowball can be self-enhanced by reseeding the seed set to fine-tune itself in different iterations, leading to continual improvements in the generation quality. We conduct experiments in the high-resource English scenario and the medium-resource Chinese scenario, and the experimental results show that the data generated by QASnowball can facilitate QA models: (1) training models on the generated data achieves comparable results to using supervised data, and (2) pre-training on the generated data and fine-tuning on supervised data can achieve better performance. Our code and generated data will be released to advance further work.
CapsuleBot: A Novel Compact Hybrid Aerial-Ground Robot with Two Actuated-wheel-rotors
Sep 17, 2023
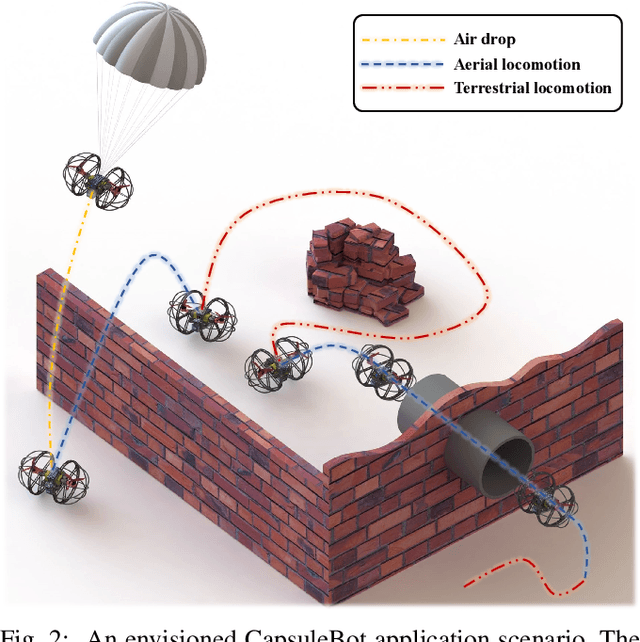
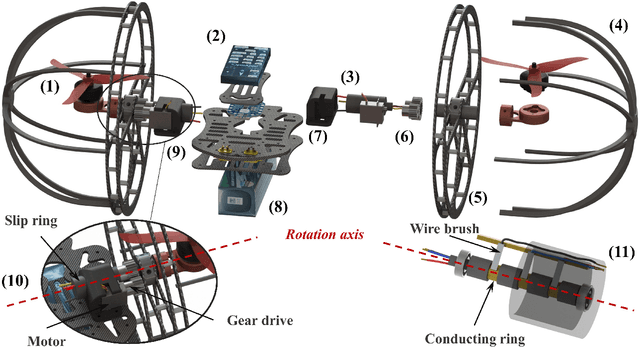
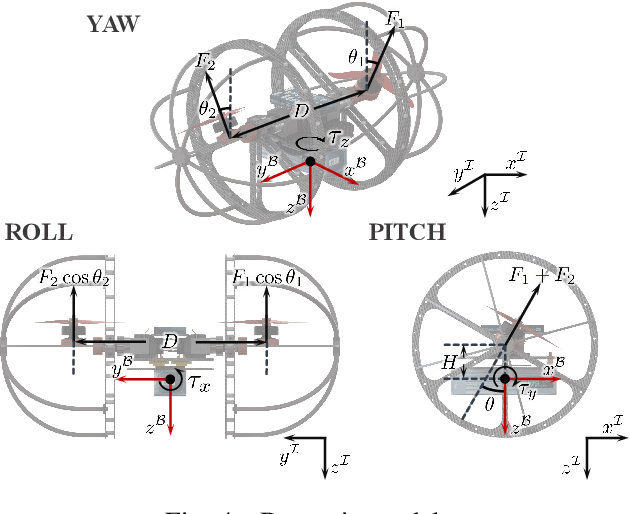
This paper presents the design, modeling, and experimental validation of CapsuleBot, a compact hybrid aerial-ground vehicle designed for long-term covert reconnaissance. CapsuleBot combines the manoeuvrability of bicopter in the air with the energy efficiency and noise reduction of ground vehicles on the ground. To accomplish this, a structure named actuated-wheel-rotor has been designed, utilizing a sole motor for both the unilateral rotor tilting in the bicopter configuration and the wheel movement in ground mode. CapsuleBot comes equipped with two of these structures, enabling it to attain hybrid aerial-ground propulsion with just four motors. Importantly, the decoupling of motion modes is achieved without the need for additional drivers, enhancing the versatility and robustness of the system. Furthermore, we have designed the full dynamics and control for aerial and ground locomotion based on the bicopter model and the two-wheeled self-balancing vehicle model. The performance of CapsuleBot has been validated through experiments. The results demonstrate that CapsuleBot produces 40.53% less noise in ground mode and consumes 99.35% less energy, highlighting its potential for long-term covert reconnaissance applications.
Intention-Aware Planner for Robust and Safe Aerial Tracking
Sep 16, 2023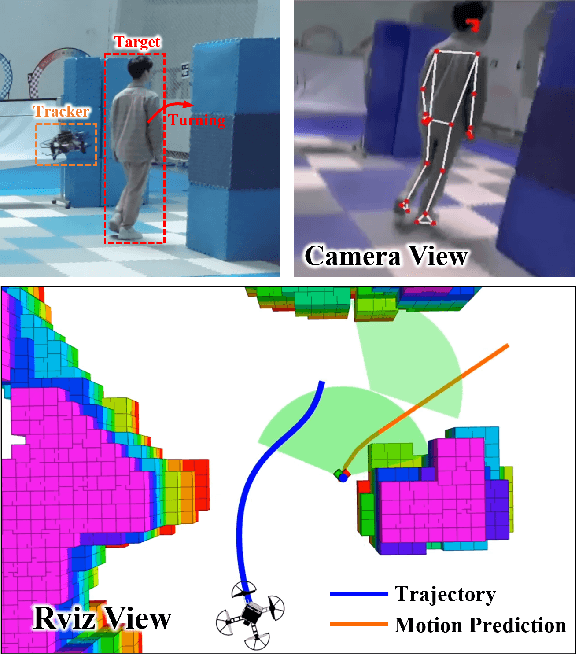
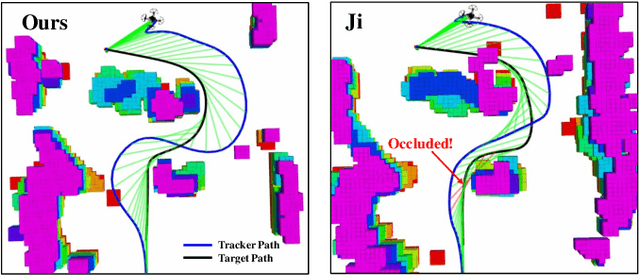
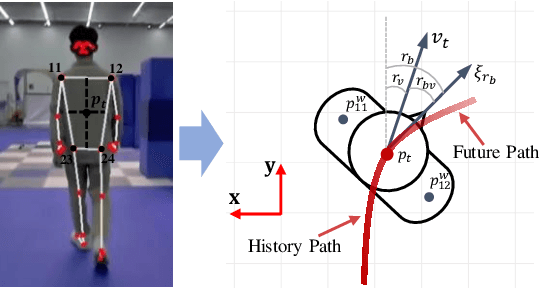
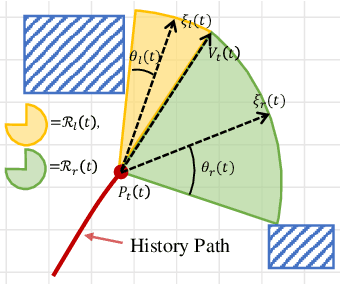
The intention of the target can help us to estimate its future motion state more accurately. This paper proposes an intention-aware planner to enhance safety and robustness in aerial tracking applications. Firstly, we utilize the Mediapipe framework to estimate target's pose. A risk assessment function and a state observation function are designed to predict the target intention. Afterwards, an intention-driven hybrid A* method is proposed for target motion prediction, ensuring that the target's future positions align with its intention. Finally, an intention-aware optimization approach, in conjunction with particular penalty formulations, is designed to generate a spatial-temporal optimal trajectory. Benchmark comparisons validate the superior performance of our proposed methodology across diverse scenarios. This is attributed to the integration of the target intention into the planner through coupled formulations.