 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiancan Wu
Leave No Patient Behind: Enhancing Medication Recommendation for Rare Disease Patients
Mar 26, 2024
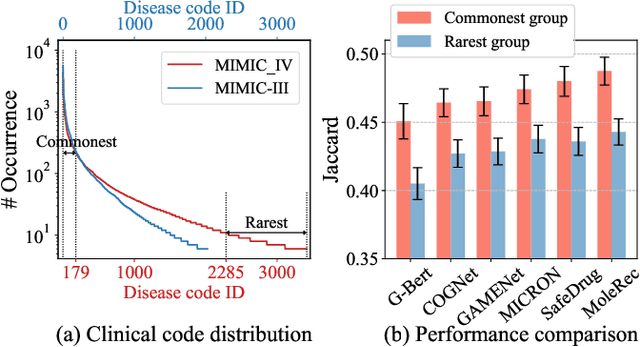

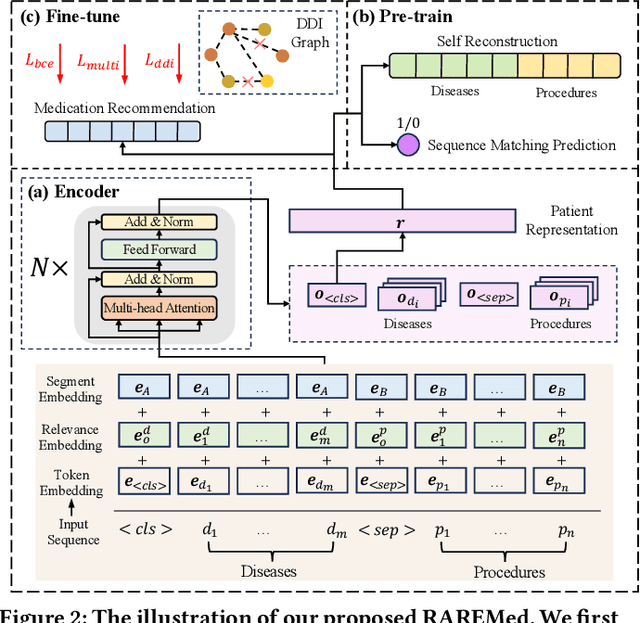
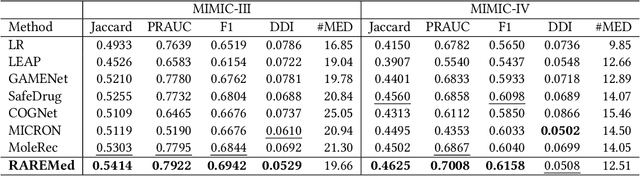
Medication recommendation systems have gained significant attention in healthcare as a means of providing tailored and effective drug combinations based on patients' clinical information. However, existing approaches often suffer from fairness issues, as recommendations tend to be more accurate for patients with common diseases compared to those with rare conditions. In this paper, we propose a novel model called Robust and Accurate REcommendations for Medication (RAREMed), which leverages the pretrain-finetune learning paradigm to enhance accuracy for rare diseases. RAREMed employs a transformer encoder with a unified input sequence approach to capture complex relationships among disease and procedure codes. Additionally, it introduces two self-supervised pre-training tasks, namely Sequence Matching Prediction (SMP) and Self Reconstruction (SR), to learn specialized medication needs and interrelations among clinical codes. Experimental results on two real-world datasets demonstrate that RAREMed provides accurate drug sets for both rare and common disease patients, thereby mitigating unfairness in medication recommendation systems.
Dynamic Sparse Learning: A Novel Paradigm for Efficient Recommendation
Feb 05, 2024In the realm of deep learning-based recommendation systems, the increasing computational demands, driven by the growing number of users and items, pose a significant challenge to practical deployment. This challenge is primarily twofold: reducing the model size while effectively learning user and item representations for efficient recommendations. Despite considerable advancements in model compression and architecture search, prevalent approaches face notable constraints. These include substantial additional computational costs from pre-training/re-training in model compression and an extensive search space in architecture design. Additionally, managing complexity and adhering to memory constraints is problematic, especially in scenarios with strict time or space limitations. Addressing these issues, this paper introduces a novel learning paradigm, Dynamic Sparse Learning (DSL), tailored for recommendation models. DSL innovatively trains a lightweight sparse model from scratch, periodically evaluating and dynamically adjusting each weight's significance and the model's sparsity distribution during the training. This approach ensures a consistent and minimal parameter budget throughout the full learning lifecycle, paving the way for "end-to-end" efficiency from training to inference. Our extensive experimental results underline DSL's effectiveness, significantly reducing training and inference costs while delivering comparable recommendation performance.
BSL: Understanding and Improving Softmax Loss for Recommendation
Dec 20, 2023Loss functions steer the optimization direction of recommendation models and are critical to model performance, but have received relatively little attention in recent recommendation research. Among various losses, we find Softmax loss (SL) stands out for not only achieving remarkable accuracy but also better robustness and fairness. Nevertheless, the current literature lacks a comprehensive explanation for the efficacy of SL. Toward addressing this research gap, we conduct theoretical analyses on SL and uncover three insights: 1) Optimizing SL is equivalent to performing Distributionally Robust Optimization (DRO) on the negative data, thereby learning against perturbations on the negative distribution and yielding robustness to noisy negatives. 2) Comparing with other loss functions, SL implicitly penalizes the prediction variance, resulting in a smaller gap between predicted values and and thus producing fairer results. Building on these insights, we further propose a novel loss function Bilateral SoftMax Loss (BSL) that extends the advantage of SL to both positive and negative sides. BSL augments SL by applying the same Log-Expectation-Exp structure to positive examples as is used for negatives, making the model robust to the noisy positives as well. Remarkably, BSL is simple and easy-to-implement -- requiring just one additional line of code compared to SL. Experiments on four real-world datasets and three representative backbones demonstrate the effectiveness of our proposal. The code is available at https://github.com/junkangwu/BSL
LLaRA: Aligning Large Language Models with Sequential Recommenders
Dec 05, 2023



Sequential recommendation aims to predict the subsequent items matching user preference based on her/his historical interactions. With the development of Large Language Models (LLMs), there is growing interest in exploring the potential of LLMs for sequential recommendation by framing it as a language modeling task. Prior works represent items in the textual prompts using either ID indexing or text indexing and feed the prompts into LLMs, but falling short of either encapsulating comprehensive world knowledge or exhibiting sufficient sequential understanding. To harness the complementary strengths of traditional recommenders (which encode user behavioral knowledge) and LLMs (which possess world knowledge about items), we propose LLaRA -- a Large Language and Recommendation Assistant framework. Specifically, LLaRA represents items in LLM's input prompts using a novel hybrid approach that integrates ID-based item embeddings from traditional recommenders with textual item features. Viewing the ``sequential behavior of the user'' as a new modality in recommendation, we employ an adapter to bridge the modality gap between ID embeddings of the traditional recommenders and the input space of LLMs. Furthermore, instead of directly exposing the hybrid prompt to LLMs, we apply a curriculum learning approach to gradually ramp up training complexity. We first warm up the LLM with text-only prompting, which aligns more naturally with the LLM's language modeling capabilities. Thereafter, we progressively transition to hybrid prompting, training the adapter to incorporate behavioral knowledge from the traditional sequential recommender into the LLM. Extensive experiments demonstrate the efficacy of LLaRA framework. Our code and data are available at https://github.com/ljy0ustc/LLaRA .
Large Language Model Can Interpret Latent Space of Sequential Recommender
Oct 31, 2023Sequential recommendation is to predict the next item of interest for a user, based on her/his interaction history with previous items. In conventional sequential recommenders, a common approach is to model item sequences using discrete IDs, learning representations that encode sequential behaviors and reflect user preferences. Inspired by recent success in empowering large language models (LLMs) to understand and reason over diverse modality data (e.g., image, audio, 3D points), a compelling research question arises: ``Can LLMs understand and work with hidden representations from ID-based sequential recommenders?''.To answer this, we propose a simple framework, RecInterpreter, which examines the capacity of open-source LLMs to decipher the representation space of sequential recommenders. Specifically, with the multimodal pairs (\ie representations of interaction sequence and text narrations), RecInterpreter first uses a lightweight adapter to map the representations into the token embedding space of the LLM. Subsequently, it constructs a sequence-recovery prompt that encourages the LLM to generate textual descriptions for items within the interaction sequence. Taking a step further, we propose a sequence-residual prompt instead, which guides the LLM in identifying the residual item by contrasting the representations before and after integrating this residual into the existing sequence. Empirical results showcase that our RecInterpreter enhances the exemplar LLM, LLaMA, to understand hidden representations from ID-based sequential recommenders, especially when guided by our sequence-residual prompts. Furthermore, RecInterpreter enables LLaMA to instantiate the oracle items generated by generative recommenders like DreamRec, concreting the item a user would ideally like to interact with next. Codes are available at https://github.com/YangZhengyi98/RecInterpreter.
Generate What You Prefer: Reshaping Sequential Recommendation via Guided Diffusion
Oct 31, 2023Sequential recommendation aims to recommend the next item that matches a user's interest, based on the sequence of items he/she interacted with before. Scrutinizing previous studies, we can summarize a common learning-to-classify paradigm -- given a positive item, a recommender model performs negative sampling to add negative items and learns to classify whether the user prefers them or not, based on his/her historical interaction sequence. Although effective, we reveal two inherent limitations:(1) it may differ from human behavior in that a user could imagine an oracle item in mind and select potential items matching the oracle; and (2) the classification is limited in the candidate pool with noisy or easy supervision from negative samples, which dilutes the preference signals towards the oracle item. Yet, generating the oracle item from the historical interaction sequence is mostly unexplored. To bridge the gap, we reshape sequential recommendation as a learning-to-generate paradigm, which is achieved via a guided diffusion model, termed DreamRec.Specifically, for a sequence of historical items, it applies a Transformer encoder to create guidance representations. Noising target items explores the underlying distribution of item space; then, with the guidance of historical interactions, the denoising process generates an oracle item to recover the positive item, so as to cast off negative sampling and depict the true preference of the user directly. We evaluate the effectiveness of DreamRec through extensive experiments and comparisons with existing methods. Codes and data are open-sourced at https://github.com/YangZhengyi98/DreamRec.
Model-enhanced Contrastive Reinforcement Learning for Sequential Recommendation
Oct 25, 2023



Reinforcement learning (RL) has been widely applied in recommendation systems due to its potential in optimizing the long-term engagement of users. From the perspective of RL, recommendation can be formulated as a Markov decision process (MDP), where recommendation system (agent) can interact with users (environment) and acquire feedback (reward signals).However, it is impractical to conduct online interactions with the concern on user experience and implementation complexity, and we can only train RL recommenders with offline datasets containing limited reward signals and state transitions. Therefore, the data sparsity issue of reward signals and state transitions is very severe, while it has long been overlooked by existing RL recommenders.Worse still, RL methods learn through the trial-and-error mode, but negative feedback cannot be obtained in implicit feedback recommendation tasks, which aggravates the overestimation problem of offline RL recommender. To address these challenges, we propose a novel RL recommender named model-enhanced contrastive reinforcement learning (MCRL). On the one hand, we learn a value function to estimate the long-term engagement of users, together with a conservative value learning mechanism to alleviate the overestimation problem.On the other hand, we construct some positive and negative state-action pairs to model the reward function and state transition function with contrastive learning to exploit the internal structure information of MDP. Experiments demonstrate that the proposed method significantly outperforms existing offline RL and self-supervised RL methods with different representative backbone networks on two real-world datasets.
Understanding Contrastive Learning via Distributionally Robust Optimization
Oct 17, 2023This study reveals the inherent tolerance of contrastive learning (CL) towards sampling bias, wherein negative samples may encompass similar semantics (\eg labels). However, existing theories fall short in providing explanations for this phenomenon. We bridge this research gap by analyzing CL through the lens of distributionally robust optimization (DRO), yielding several key insights: (1) CL essentially conducts DRO over the negative sampling distribution, thus enabling robust performance across a variety of potential distributions and demonstrating robustness to sampling bias; (2) The design of the temperature $\tau$ is not merely heuristic but acts as a Lagrange Coefficient, regulating the size of the potential distribution set; (3) A theoretical connection is established between DRO and mutual information, thus presenting fresh evidence for ``InfoNCE as an estimate of MI'' and a new estimation approach for $\phi$-divergence-based generalized mutual information. We also identify CL's potential shortcomings, including over-conservatism and sensitivity to outliers, and introduce a novel Adjusted InfoNCE loss (ADNCE) to mitigate these issues. It refines potential distribution, improving performance and accelerating convergence. Extensive experiments on various domains (image, sentence, and graphs) validate the effectiveness of the proposal. The code is available at \url{https://github.com/junkangwu/ADNCE}.
Query and Response Augmentation Cannot Help Out-of-domain Math Reasoning Generalization
Oct 09, 2023
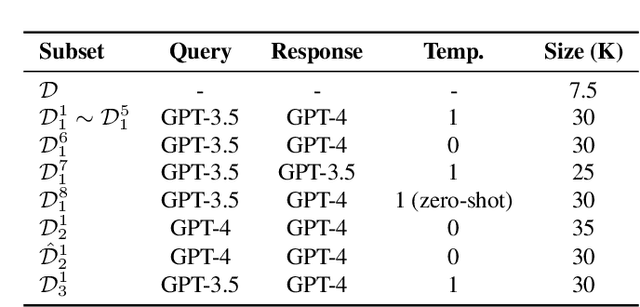
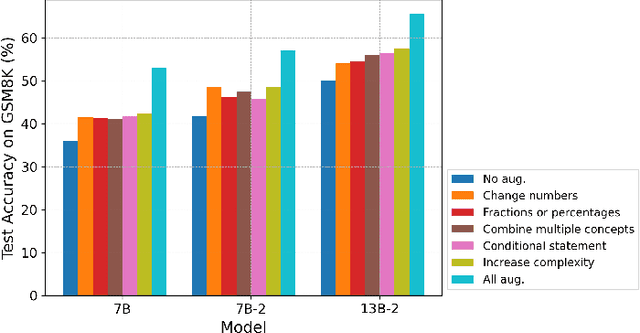

In math reasoning with large language models (LLMs), fine-tuning data augmentation by query evolution and diverse reasoning paths is empirically verified effective, profoundly narrowing the gap between open-sourced LLMs and cutting-edge proprietary LLMs. In this paper, we conduct an investigation for such data augmentation in math reasoning and are intended to answer: (1) What strategies of data augmentation are more effective; (2) What is the scaling relationship between the amount of augmented data and model performance; and (3) Can data augmentation incentivize generalization to out-of-domain mathematical reasoning tasks? To this end, we create a new dataset, AugGSM8K, by complicating and diversifying the queries from GSM8K and sampling multiple reasoning paths. We obtained a series of LLMs called MuggleMath by fine-tuning on subsets of AugGSM8K. MuggleMath substantially achieves new state-of-the-art on GSM8K (from 54% to 68.4% at the scale of 7B, and from 63.9% to 74.0% at the scale of 13B). A log-linear relationship is presented between MuggleMath's performance and the amount of augmented data. We also find that MuggleMath is weak in out-of-domain math reasoning generalization to MATH. This is attributed to the differences in query distribution between AugGSM8K and MATH which suggest that augmentation on a single benchmark could not help with overall math reasoning performance. Codes and AugGSM8K will be uploaded to https://github.com/OFA-Sys/gsm8k-ScRel.
Recommendation Unlearning via Influence Function
Jul 05, 2023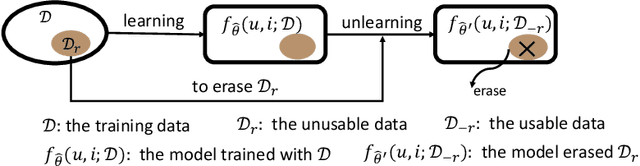

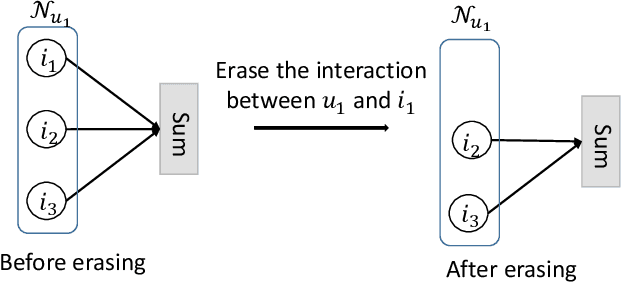
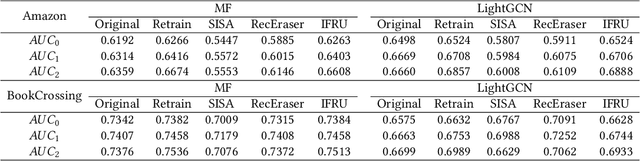
Recommendation unlearning is an emerging task to serve users for erasing unusable data (e.g., some historical behaviors) from a well-trained recommender model. Existing methods process unlearning requests by fully or partially retraining the model after removing the unusable data. However, these methods are impractical due to the high computation cost of full retraining and the highly possible performance damage of partial training. In this light, a desired recommendation unlearning method should obtain a similar model as full retraining in a more efficient manner, i.e., achieving complete, efficient and innocuous unlearning. In this work, we propose an Influence Function-based Recommendation Unlearning (IFRU) framework, which efficiently updates the model without retraining by estimating the influence of the unusable data on the model via the influence function. In the light that recent recommender models use historical data for both the constructions of the optimization loss and the computational graph (e.g., neighborhood aggregation), IFRU jointly estimates the direct influence of unusable data on optimization loss and the spillover influence on the computational graph to pursue complete unlearning. Furthermore, we propose an importance-based pruning algorithm to reduce the cost of the influence function. IFRU is innocuous and applicable to mainstream differentiable models. Extensive experiments demonstrate that IFRU achieves more than250times acceleration compared to retraining-based methods with recommendation performance comparable to full retraining.