 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiawei Chen
Distillation Matters: Empowering Sequential Recommenders to Match the Performance of Large Language Model
May 01, 2024
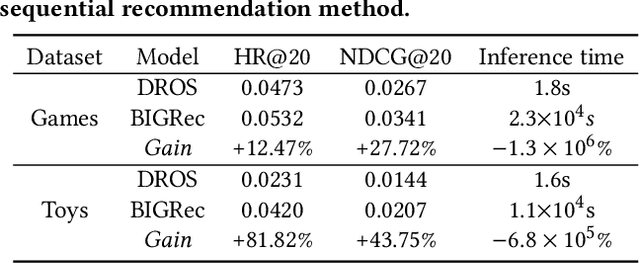
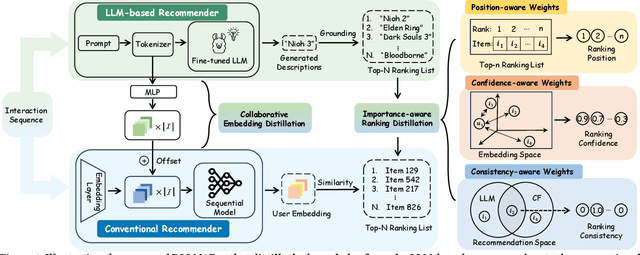
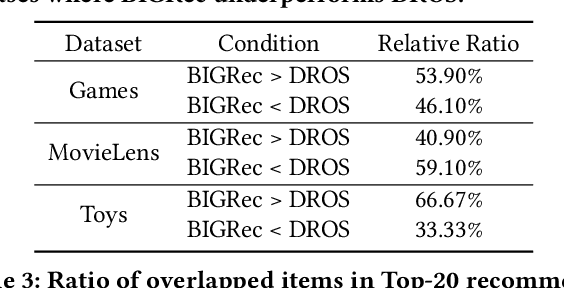
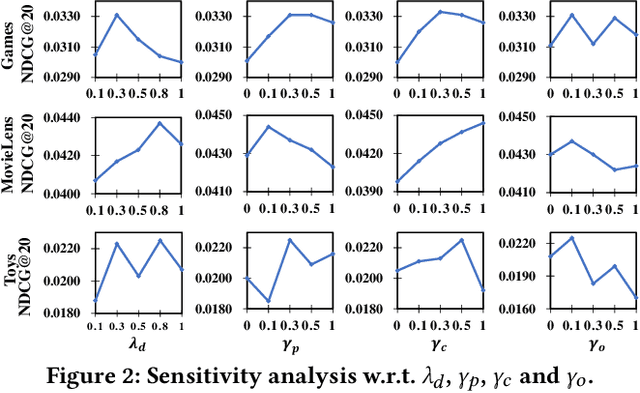
Owing to their powerful semantic reasoning capabilities, Large Language Models (LLMs) have been effectively utilized as recommenders, achieving impressive performance. However, the high inference latency of LLMs significantly restricts their practical deployment. To address this issue, this work investigates knowledge distillation from cumbersome LLM-based recommendation models to lightweight conventional sequential models. It encounters three challenges: 1) the teacher's knowledge may not always be reliable; 2) the capacity gap between the teacher and student makes it difficult for the student to assimilate the teacher's knowledge; 3) divergence in semantic space poses a challenge to distill the knowledge from embeddings. To tackle these challenges, this work proposes a novel distillation strategy, DLLM2Rec, specifically tailored for knowledge distillation from LLM-based recommendation models to conventional sequential models. DLLM2Rec comprises: 1) Importance-aware ranking distillation, which filters reliable and student-friendly knowledge by weighting instances according to teacher confidence and student-teacher consistency; 2) Collaborative embedding distillation integrates knowledge from teacher embeddings with collaborative signals mined from the data. Extensive experiments demonstrate the effectiveness of the proposed DLLM2Rec, boosting three typical sequential models with an average improvement of 47.97%, even enabling them to surpass LLM-based recommenders in some cases.
Efficiency in Focus: LayerNorm as a Catalyst for Fine-tuning Medical Visual Language Pre-trained Models
Apr 25, 2024In the realm of Medical Visual Language Models (Med-VLMs), the quest for universal efficient fine-tuning mechanisms remains paramount, especially given researchers in interdisciplinary fields are often extremely short of training resources, yet largely unexplored. Given the unique challenges in the medical domain, such as limited data scope and significant domain-specific requirements, evaluating and adapting Parameter-Efficient Fine-Tuning (PEFT) methods specifically for Med-VLMs is essential. Most of the current PEFT methods on Med-VLMs have yet to be comprehensively investigated but mainly focus on adding some components to the model's structure or input. However, fine-tuning intrinsic model components often yields better generality and consistency, and its impact on the ultimate performance of Med-VLMs has been widely overlooked and remains understudied. In this paper, we endeavour to explore an alternative to traditional PEFT methods, especially the impact of fine-tuning LayerNorm layers, FFNs and Attention layers on the Med-VLMs. Our comprehensive studies span both small-scale and large-scale Med-VLMs, evaluating their performance under various fine-tuning paradigms across tasks such as Medical Visual Question Answering and Medical Imaging Report Generation. The findings reveal unique insights into the effects of intrinsic parameter fine-tuning methods on fine-tuning Med-VLMs to downstream tasks and expose fine-tuning solely the LayerNorm layers not only surpasses the efficiency of traditional PEFT methods but also retains the model's accuracy and generalization capabilities across a spectrum of medical downstream tasks. The experiments show LayerNorm fine-tuning's superior adaptability and scalability, particularly in the context of large-scale Med-VLMs.
SIGformer: Sign-aware Graph Transformer for Recommendation
Apr 18, 2024In recommender systems, most graph-based methods focus on positive user feedback, while overlooking the valuable negative feedback. Integrating both positive and negative feedback to form a signed graph can lead to a more comprehensive understanding of user preferences. However, the existing efforts to incorporate both types of feedback are sparse and face two main limitations: 1) They process positive and negative feedback separately, which fails to holistically leverage the collaborative information within the signed graph; 2) They rely on MLPs or GNNs for information extraction from negative feedback, which may not be effective. To overcome these limitations, we introduce SIGformer, a new method that employs the transformer architecture to sign-aware graph-based recommendation. SIGformer incorporates two innovative positional encodings that capture the spectral properties and path patterns of the signed graph, enabling the full exploitation of the entire graph. Our extensive experiments across five real-world datasets demonstrate the superiority of SIGformer over state-of-the-art methods. The code is available at https://github.com/StupidThree/SIGformer.
How Do Recommendation Models Amplify Popularity Bias? An Analysis from the Spectral Perspective
Apr 18, 2024Recommendation Systems (RS) are often plagued by popularity bias. Specifically,when recommendation models are trained on long-tailed datasets, they not only inherit this bias but often exacerbate it. This effect undermines both the precision and fairness of RS and catalyzes the so-called Matthew Effect. Despite the widely recognition of this issue, the fundamental causes remain largely elusive. In our research, we delve deeply into popularity bias amplification. Our comprehensive theoretical and empirical investigations lead to two core insights: 1) Item popularity is memorized in the principal singular vector of the score matrix predicted by the recommendation model; 2) The dimension collapse phenomenon amplifies the impact of principal singular vector on model predictions, intensifying the popularity bias. Based on these insights, we propose a novel method to mitigate this bias by imposing penalties on the magnitude of the principal singular value. Considering the heavy computational burden in directly evaluating the gradient of the principal singular value, we develop an efficient algorithm that harnesses the inherent properties of the singular vector. Extensive experiments across seven real-world datasets and three testing scenarios have been conducted to validate the superiority of our method.
FaceCat: Enhancing Face Recognition Security with a Unified Generative Model Framework
Apr 14, 2024Face anti-spoofing (FAS) and adversarial detection (FAD) have been regarded as critical technologies to ensure the safety of face recognition systems. As a consequence of their limited practicality and generalization, some existing methods aim to devise a framework capable of concurrently detecting both threats to address the challenge. Nevertheless, these methods still encounter challenges of insufficient generalization and suboptimal robustness, potentially owing to the inherent drawback of discriminative models. Motivated by the rich structural and detailed features of face generative models, we propose FaceCat which utilizes the face generative model as a pre-trained model to improve the performance of FAS and FAD. Specifically, FaceCat elaborately designs a hierarchical fusion mechanism to capture rich face semantic features of the generative model. These features then serve as a robust foundation for a lightweight head, designed to execute FAS and FAD tasks simultaneously. As relying solely on single-modality data often leads to suboptimal performance, we further propose a novel text-guided multi-modal alignment strategy that utilizes text prompts to enrich feature representation, thereby enhancing performance. For fair evaluations, we build a comprehensive protocol with a wide range of 28 attack types to benchmark the performance. Extensive experiments validate the effectiveness of FaceCat generalizes significantly better and obtains excellent robustness against input transformations.
Few-shot Named Entity Recognition via Superposition Concept Discrimination
Mar 25, 2024Few-shot NER aims to identify entities of target types with only limited number of illustrative instances. Unfortunately, few-shot NER is severely challenged by the intrinsic precise generalization problem, i.e., it is hard to accurately determine the desired target type due to the ambiguity stemming from information deficiency. In this paper, we propose Superposition Concept Discriminator (SuperCD), which resolves the above challenge via an active learning paradigm. Specifically, a concept extractor is first introduced to identify superposition concepts from illustrative instances, with each concept corresponding to a possible generalization boundary. Then a superposition instance retriever is applied to retrieve corresponding instances of these superposition concepts from large-scale text corpus. Finally, annotators are asked to annotate the retrieved instances and these annotated instances together with original illustrative instances are used to learn FS-NER models. To this end, we learn a universal concept extractor and superposition instance retriever using a large-scale openly available knowledge bases. Experiments show that SuperCD can effectively identify superposition concepts from illustrative instances, retrieve superposition instances from large-scale corpus, and significantly improve the few-shot NER performance with minimal additional efforts.
Can LLMs' Tuning Methods Work in Medical Multimodal Domain?
Mar 11, 2024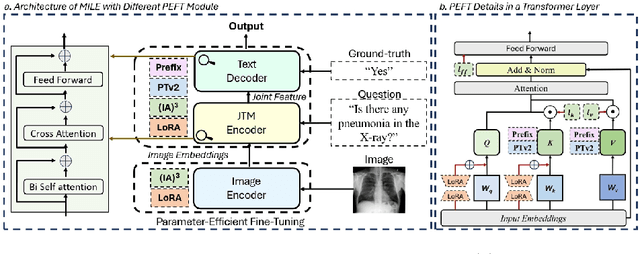
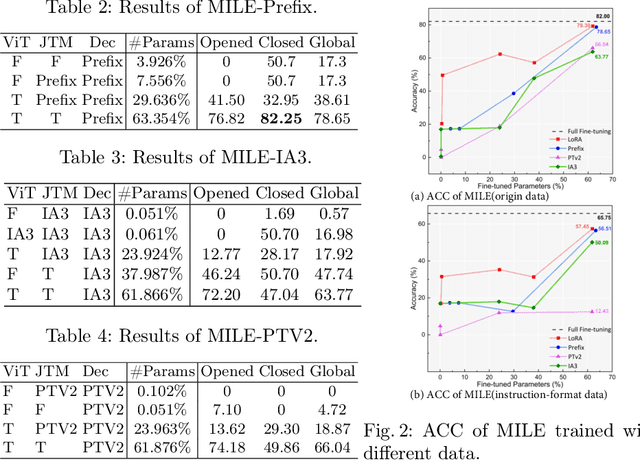
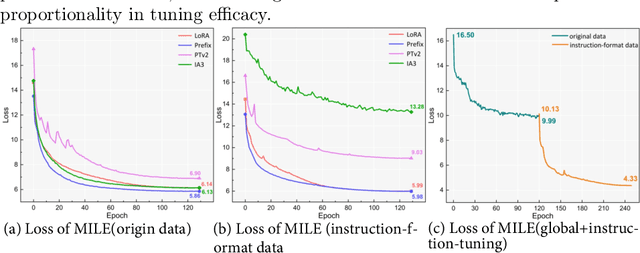
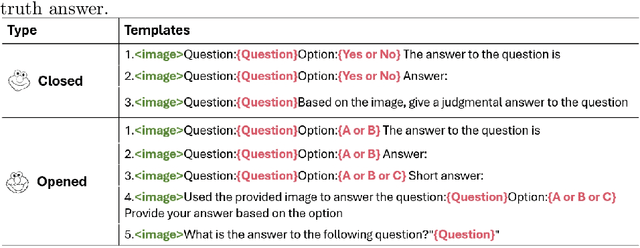
While large language models (LLMs) excel in world knowledge understanding, adapting them to specific subfields requires precise adjustments. Due to the model's vast scale, traditional global fine-tuning methods for large models can be computationally expensive and impact generalization. To address this challenge, a range of innovative Parameters-Efficient Fine-Tuning (PEFT) methods have emerged and achieved remarkable success in both LLMs and Large Vision-Language Models (LVLMs). In the medical domain, fine-tuning a medical Vision-Language Pretrained (VLP) model is essential for adapting it to specific tasks. Can the fine-tuning methods for large models be transferred to the medical field to enhance transfer learning efficiency? In this paper, we delve into the fine-tuning methods of LLMs and conduct extensive experiments to investigate the impact of fine-tuning methods for large models on existing multimodal models in the medical domain from the training data level and the model structure level. We show the different impacts of fine-tuning methods for large models on medical VLMs and develop the most efficient ways to fine-tune medical VLP models. We hope this research can guide medical domain researchers in optimizing VLMs' training costs, fostering the broader application of VLMs in healthcare fields. Code and dataset will be released upon acceptance.
EasyRL4Rec: A User-Friendly Code Library for Reinforcement Learning Based Recommender Systems
Feb 23, 2024Reinforcement Learning (RL)-Based Recommender Systems (RSs) are increasingly recognized for their ability to improve long-term user engagement. Yet, the field grapples with challenges such as the absence of accessible frameworks, inconsistent evaluation standards, and the complexity of replicating prior work. Addressing these obstacles, we present EasyRL4Rec, a user-friendly and efficient library tailored for RL-based RSs. EasyRL4Rec features lightweight, diverse RL environments built on five widely-used public datasets, and is equipped with comprehensive core modules that offer rich options to ease the development of models. It establishes consistent evaluation criteria with a focus on long-term impacts and introduces customized solutions for state modeling and action representation tailored to recommender systems. Additionally, we share valuable insights gained from extensive experiments with current methods. EasyRL4Rec aims to facilitate the model development and experimental process in the domain of RL-based RSs. The library is openly accessible at https://github.com/chongminggao/EasyRL4Rec.
Self-Retrieval: Building an Information Retrieval System with One Large Language Model
Feb 23, 2024
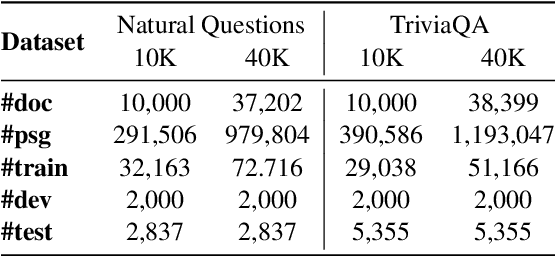
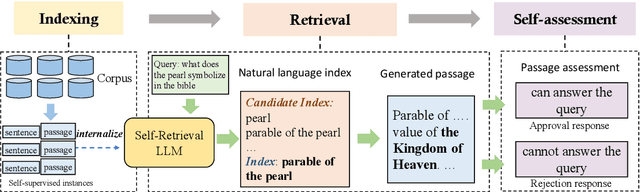
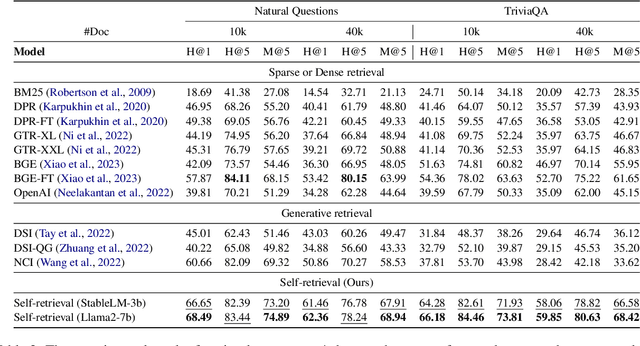
The rise of large language models (LLMs) has transformed the role of information retrieval (IR) systems in the way to humans accessing information. Due to the isolated architecture and the limited interaction, existing IR systems are unable to fully accommodate the shift from directly providing information to humans to indirectly serving large language models. In this paper, we propose Self-Retrieval, an end-to-end, LLM-driven information retrieval architecture that can fully internalize the required abilities of IR systems into a single LLM and deeply leverage the capabilities of LLMs during IR process. Specifically, Self-retrieval internalizes the corpus to retrieve into a LLM via a natural language indexing architecture. Then the entire retrieval process is redefined as a procedure of document generation and self-assessment, which can be end-to-end executed using a single large language model. Experimental results demonstrate that Self-Retrieval not only significantly outperforms previous retrieval approaches by a large margin, but also can significantly boost the performance of LLM-driven downstream applications like retrieval augumented generation.
Distributionally Robust Graph-based Recommendation System
Feb 21, 2024With the capacity to capture high-order collaborative signals, Graph Neural Networks (GNNs) have emerged as powerful methods in Recommender Systems (RS). However, their efficacy often hinges on the assumption that training and testing data share the same distribution (a.k.a. IID assumption), and exhibits significant declines under distribution shifts. Distribution shifts commonly arises in RS, often attributed to the dynamic nature of user preferences or ubiquitous biases during data collection in RS. Despite its significance, researches on GNN-based recommendation against distribution shift are still sparse. To bridge this gap, we propose Distributionally Robust GNN (DR-GNN) that incorporates Distributional Robust Optimization (DRO) into the GNN-based recommendation. DR-GNN addresses two core challenges: 1) To enable DRO to cater to graph data intertwined with GNN, we reinterpret GNN as a graph smoothing regularizer, thereby facilitating the nuanced application of DRO; 2) Given the typically sparse nature of recommendation data, which might impede robust optimization, we introduce slight perturbations in the training distribution to expand its support. Notably, while DR-GNN involves complex optimization, it can be implemented easily and efficiently. Our extensive experiments validate the effectiveness of DR-GNN against three typical distribution shifts. The code is available at https://github.com/WANGBohaO-jpg/DR-GNN.