 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYan Feng
Distributionally Robust Graph-based Recommendation System
Feb 21, 2024
With the capacity to capture high-order collaborative signals, Graph Neural Networks (GNNs) have emerged as powerful methods in Recommender Systems (RS). However, their efficacy often hinges on the assumption that training and testing data share the same distribution (a.k.a. IID assumption), and exhibits significant declines under distribution shifts. Distribution shifts commonly arises in RS, often attributed to the dynamic nature of user preferences or ubiquitous biases during data collection in RS. Despite its significance, researches on GNN-based recommendation against distribution shift are still sparse. To bridge this gap, we propose Distributionally Robust GNN (DR-GNN) that incorporates Distributional Robust Optimization (DRO) into the GNN-based recommendation. DR-GNN addresses two core challenges: 1) To enable DRO to cater to graph data intertwined with GNN, we reinterpret GNN as a graph smoothing regularizer, thereby facilitating the nuanced application of DRO; 2) Given the typically sparse nature of recommendation data, which might impede robust optimization, we introduce slight perturbations in the training distribution to expand its support. Notably, while DR-GNN involves complex optimization, it can be implemented easily and efficiently. Our extensive experiments validate the effectiveness of DR-GNN against three typical distribution shifts. The code is available at https://github.com/WANGBohaO-jpg/DR-GNN.
WildfireGPT: Tailored Large Language Model for Wildfire Analysis
Feb 12, 2024The recent advancement of large language models (LLMs) represents a transformational capability at the frontier of artificial intelligence (AI) and machine learning (ML). However, LLMs are generalized models, trained on extensive text corpus, and often struggle to provide context-specific information, particularly in areas requiring specialized knowledge such as wildfire details within the broader context of climate change. For decision-makers and policymakers focused on wildfire resilience and adaptation, it is crucial to obtain responses that are not only precise but also domain-specific, rather than generic. To that end, we developed WildfireGPT, a prototype LLM agent designed to transform user queries into actionable insights on wildfire risks. We enrich WildfireGPT by providing additional context such as climate projections and scientific literature to ensure its information is current, relevant, and scientifically accurate. This enables WildfireGPT to be an effective tool for delivering detailed, user-specific insights on wildfire risks to support a diverse set of end users, including researchers, engineers, urban planners, emergency managers, and infrastructure operators.
Knowledge Translation: A New Pathway for Model Compression
Jan 11, 2024Deep learning has witnessed significant advancements in recent years at the cost of increasing training, inference, and model storage overhead. While existing model compression methods strive to reduce the number of model parameters while maintaining high accuracy, they inevitably necessitate the re-training of the compressed model or impose architectural constraints. To overcome these limitations, this paper presents a novel framework, termed \textbf{K}nowledge \textbf{T}ranslation (KT), wherein a ``translation'' model is trained to receive the parameters of a larger model and generate compressed parameters. The concept of KT draws inspiration from language translation, which effectively employs neural networks to convert different languages, maintaining identical meaning. Accordingly, we explore the potential of neural networks to convert models of disparate sizes, while preserving their functionality. We propose a comprehensive framework for KT, introduce data augmentation strategies to enhance model performance despite restricted training data, and successfully demonstrate the feasibility of KT on the MNIST dataset. Code is available at \url{https://github.com/zju-SWJ/KT}.
CDR: Conservative Doubly Robust Learning for Debiased Recommendation
Aug 17, 2023
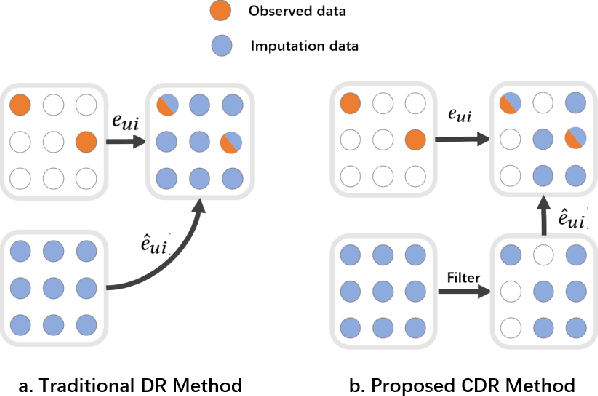
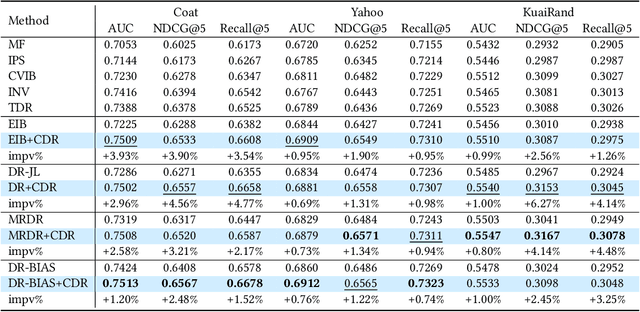
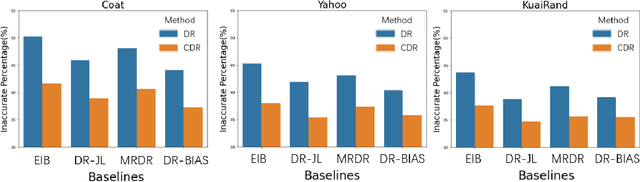
In recommendation systems (RS), user behavior data is observational rather than experimental, resulting in widespread bias in the data. Consequently, tackling bias has emerged as a major challenge in the field of recommendation systems. Recently, Doubly Robust Learning (DR) has gained significant attention due to its remarkable performance and robust properties. However, our experimental findings indicate that existing DR methods are severely impacted by the presence of so-called Poisonous Imputation, where the imputation significantly deviates from the truth and becomes counterproductive. To address this issue, this work proposes Conservative Doubly Robust strategy (CDR) which filters imputations by scrutinizing their mean and variance. Theoretical analyses show that CDR offers reduced variance and improved tail bounds.In addition, our experimental investigations illustrate that CDR significantly enhances performance and can indeed reduce the frequency of poisonous imputation.
A data-driven approach to predict decision point choice during normal and evacuation wayfinding in multi-story buildings
Aug 07, 2023Understanding pedestrian route choice behavior in complex buildings is important to ensure pedestrian safety. Previous studies have mostly used traditional data collection methods and discrete choice modeling to understand the influence of different factors on pedestrian route and exit choice, particularly in simple indoor environments. However, research on pedestrian route choice in complex buildings is still limited. This paper presents a data-driven approach for understanding and predicting the pedestrian decision point choice during normal and emergency wayfinding in a multi-story building. For this, we first built an indoor network representation and proposed a data mapping technique to map VR coordinates to the indoor representation. We then used a well-established machine learning algorithm, namely the random forest (RF) model to predict pedestrian decision point choice along a route during four wayfinding tasks in a multi-story building. Pedestrian behavioral data in a multi-story building was collected by a Virtual Reality experiment. The results show a much higher prediction accuracy of decision points using the RF model (i.e., 93% on average) compared to the logistic regression model. The highest prediction accuracy was 96% for task 3. Additionally, we tested the model performance combining personal characteristics and we found that personal characteristics did not affect decision point choice. This paper demonstrates the potential of applying a machine learning algorithm to study pedestrian route choice behavior in complex indoor buildings.
OpenGSL: A Comprehensive Benchmark for Graph Structure Learning
Jun 17, 2023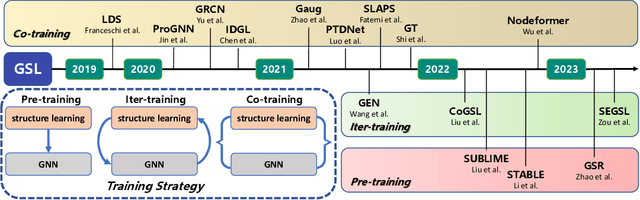
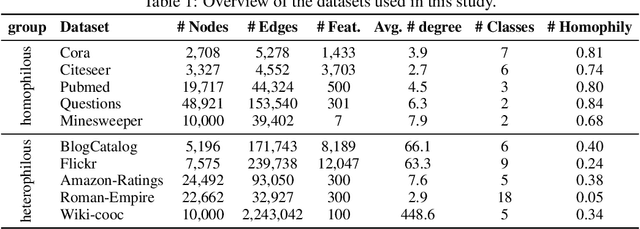
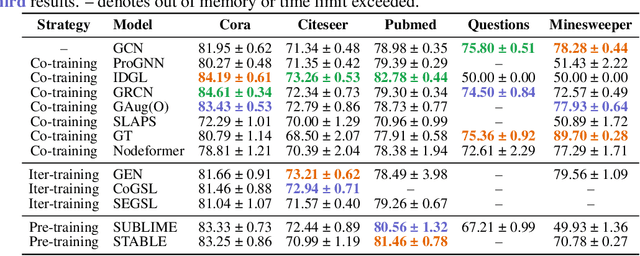
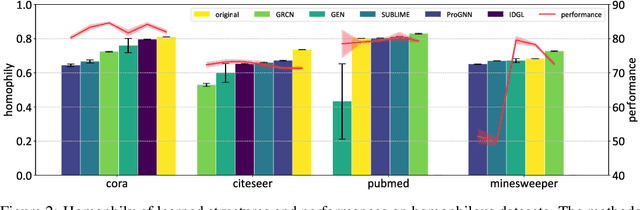
Graph Neural Networks (GNNs) have emerged as the de facto standard for representation learning on graphs, owing to their ability to effectively integrate graph topology and node attributes. However, the inherent suboptimal nature of node connections, resulting from the complex and contingent formation process of graphs, presents significant challenges in modeling them effectively. To tackle this issue, Graph Structure Learning (GSL), a family of data-centric learning approaches, has garnered substantial attention in recent years. The core concept behind GSL is to jointly optimize the graph structure and the corresponding GNN models. Despite the proposal of numerous GSL methods, the progress in this field remains unclear due to inconsistent experimental protocols, including variations in datasets, data processing techniques, and splitting strategies. In this paper, we introduce OpenGSL, the first comprehensive benchmark for GSL, aimed at addressing this gap. OpenGSL enables a fair comparison among state-of-the-art GSL methods by evaluating them across various popular datasets using uniform data processing and splitting strategies. Through extensive experiments, we observe that existing GSL methods do not consistently outperform vanilla GNN counterparts. However, we do observe that the learned graph structure demonstrates a strong generalization ability across different GNN backbones, despite its high computational and space requirements. We hope that our open-sourced library will facilitate rapid and equitable evaluation and inspire further innovative research in the field of GSL. The code of the benchmark can be found in https://github.com/OpenGSL/OpenGSL.
Generalizable Black-Box Adversarial Attack with Meta Learning
Jan 01, 2023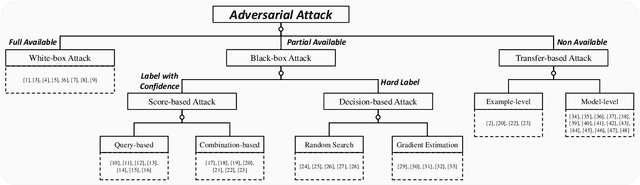

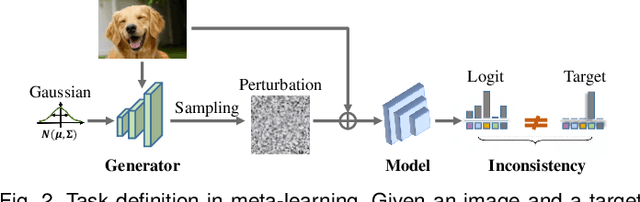
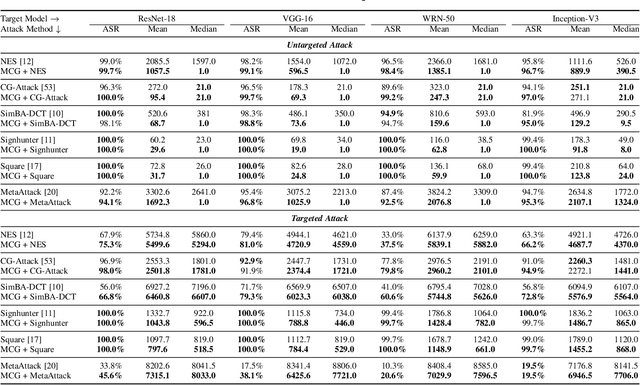
In the scenario of black-box adversarial attack, the target model's parameters are unknown, and the attacker aims to find a successful adversarial perturbation based on query feedback under a query budget. Due to the limited feedback information, existing query-based black-box attack methods often require many queries for attacking each benign example. To reduce query cost, we propose to utilize the feedback information across historical attacks, dubbed example-level adversarial transferability. Specifically, by treating the attack on each benign example as one task, we develop a meta-learning framework by training a meta-generator to produce perturbations conditioned on benign examples. When attacking a new benign example, the meta generator can be quickly fine-tuned based on the feedback information of the new task as well as a few historical attacks to produce effective perturbations. Moreover, since the meta-train procedure consumes many queries to learn a generalizable generator, we utilize model-level adversarial transferability to train the meta-generator on a white-box surrogate model, then transfer it to help the attack against the target model. The proposed framework with the two types of adversarial transferability can be naturally combined with any off-the-shelf query-based attack methods to boost their performance, which is verified by extensive experiments.
Robust Sequence Networked Submodular Maximization
Dec 28, 2022



In this paper, we study the \underline{R}obust \underline{o}ptimization for \underline{se}quence \underline{Net}worked \underline{s}ubmodular maximization (RoseNets) problem. We interweave the robust optimization with the sequence networked submodular maximization. The elements are connected by a directed acyclic graph and the objective function is not submodular on the elements but on the edges in the graph. Under such networked submodular scenario, the impact of removing an element from a sequence depends both on its position in the sequence and in the network. This makes the existing robust algorithms inapplicable. In this paper, we take the first step to study the RoseNets problem. We design a robust greedy algorithm, which is robust against the removal of an arbitrary subset of the selected elements. The approximation ratio of the algorithm depends both on the number of the removed elements and the network topology. We further conduct experiments on real applications of recommendation and link prediction. The experimental results demonstrate the effectiveness of the proposed algorithm.
Statistical treatment of convolutional neural network super-resolution of inland surface wind for subgrid-scale variability quantification
Nov 30, 2022



Machine learning models are frequently employed to perform either purely physics-free or hybrid downscaling of climate data. However, the majority of these implementations operate over relatively small downscaling factors of about 4--6x. This study examines the ability of convolutional neural networks (CNN) to downscale surface wind speed data from three different coarse resolutions (25km, 48km, and 100km side-length grid cells) to 3km and additionally focuses on the ability to recover subgrid-scale variability. Within each downscaling factor, namely 8x, 16x, and 32x, we consider models that produce fine-scale wind speed predictions as functions of different input features: coarse wind fields only; coarse wind and fine-scale topography; and coarse wind, topography, and temporal information in the form of a timestamp. Furthermore, we train one model at 25km to 3km resolution whose fine-scale outputs are probability density function parameters through which sample wind speeds can be generated. All CNN predictions performed on one out-of-sample data outperform classical interpolation. Models with coarse wind and fine topography are shown to exhibit the best performance compared to other models operating across the same downscaling factor. Our timestamp encoding results in lower out-of-sample generalizability compared to other input configurations. Overall, the downscaling factor plays the largest role in model performance.
Accelerating Diffusion Sampling with Classifier-based Feature Distillation
Nov 22, 2022



Although diffusion model has shown great potential for generating higher quality images than GANs, slow sampling speed hinders its wide application in practice. Progressive distillation is thus proposed for fast sampling by progressively aligning output images of $N$-step teacher sampler with $N/2$-step student sampler. In this paper, we argue that this distillation-based accelerating method can be further improved, especially for few-step samplers, with our proposed \textbf{C}lassifier-based \textbf{F}eature \textbf{D}istillation (CFD). Instead of aligning output images, we distill teacher's sharpened feature distribution into the student with a dataset-independent classifier, making the student focus on those important features to improve performance. We also introduce a dataset-oriented loss to further optimize the model. Experiments on CIFAR-10 show the superiority of our method in achieving high quality and fast sampling. Code will be released soon.