 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeijie Su
Shifted Interpolation for Differential Privacy
Mar 01, 2024
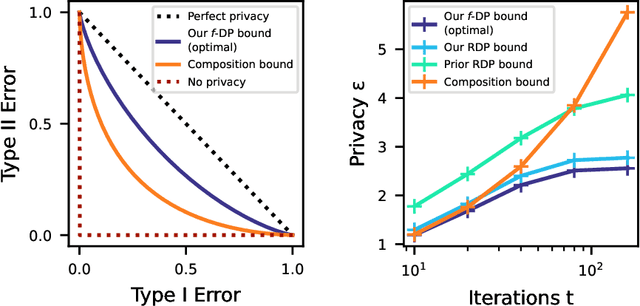
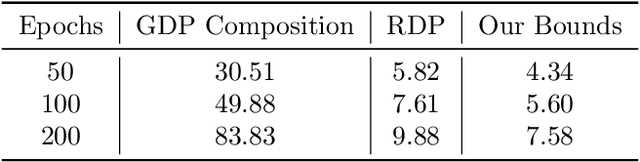
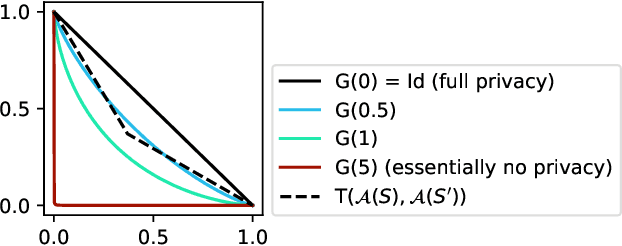
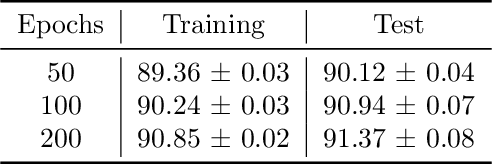
Noisy gradient descent and its variants are the predominant algorithms for differentially private machine learning. It is a fundamental question to quantify their privacy leakage, yet tight characterizations remain open even in the foundational setting of convex losses. This paper improves over previous analyses by establishing (and refining) the "privacy amplification by iteration" phenomenon in the unifying framework of $f$-differential privacy--which tightly captures all aspects of the privacy loss and immediately implies tighter privacy accounting in other notions of differential privacy, e.g., $(\varepsilon,\delta)$-DP and Renyi DP. Our key technical insight is the construction of shifted interpolated processes that unravel the popular shifted-divergences argument, enabling generalizations beyond divergence-based relaxations of DP. Notably, this leads to the first exact privacy analysis in the foundational setting of strongly convex optimization. Our techniques extend to many settings: convex/strongly convex, constrained/unconstrained, full/cyclic/stochastic batches, and all combinations thereof. As an immediate corollary, we recover the $f$-DP characterization of the exponential mechanism for strongly convex optimization in Gopi et al. (2022), and moreover extend this result to more general settings.
WildfireGPT: Tailored Large Language Model for Wildfire Analysis
Feb 12, 2024The recent advancement of large language models (LLMs) represents a transformational capability at the frontier of artificial intelligence (AI) and machine learning (ML). However, LLMs are generalized models, trained on extensive text corpus, and often struggle to provide context-specific information, particularly in areas requiring specialized knowledge such as wildfire details within the broader context of climate change. For decision-makers and policymakers focused on wildfire resilience and adaptation, it is crucial to obtain responses that are not only precise but also domain-specific, rather than generic. To that end, we developed WildfireGPT, a prototype LLM agent designed to transform user queries into actionable insights on wildfire risks. We enrich WildfireGPT by providing additional context such as climate projections and scientific literature to ensure its information is current, relevant, and scientifically accurate. This enables WildfireGPT to be an effective tool for delivering detailed, user-specific insights on wildfire risks to support a diverse set of end users, including researchers, engineers, urban planners, emergency managers, and infrastructure operators.
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Jan 15, 2024The exponential growth of large language models (LLMs) has opened up numerous possibilities for multimodal AGI systems. However, the progress in vision and vision-language foundation models, which are also critical elements of multi-modal AGI, has not kept pace with LLMs. In this work, we design a large-scale vision-language foundation model (InternVL), which scales up the vision foundation model to 6 billion parameters and progressively aligns it with the LLM, using web-scale image-text data from various sources. This model can be broadly applied to and achieve state-of-the-art performance on 32 generic visual-linguistic benchmarks including visual perception tasks such as image-level or pixel-level recognition, vision-language tasks such as zero-shot image/video classification, zero-shot image/video-text retrieval, and link with LLMs to create multi-modal dialogue systems. It has powerful visual capabilities and can be a good alternative to the ViT-22B. We hope that our research could contribute to the development of multi-modal large models. Code and models are available at https://github.com/OpenGVLab/InternVL.
Eliciting Honest Information From Authors Using Sequential Review
Nov 24, 2023In the setting of conference peer review, the conference aims to accept high-quality papers and reject low-quality papers based on noisy review scores. A recent work proposes the isotonic mechanism, which can elicit the ranking of paper qualities from an author with multiple submissions to help improve the conference's decisions. However, the isotonic mechanism relies on the assumption that the author's utility is both an increasing and a convex function with respect to the review score, which is often violated in peer review settings (e.g.~when authors aim to maximize the number of accepted papers). In this paper, we propose a sequential review mechanism that can truthfully elicit the ranking information from authors while only assuming the agent's utility is increasing with respect to the true quality of her accepted papers. The key idea is to review the papers of an author in a sequence based on the provided ranking and conditioning the review of the next paper on the review scores of the previous papers. Advantages of the sequential review mechanism include 1) eliciting truthful ranking information in a more realistic setting than prior work; 2) improving the quality of accepted papers, reducing the reviewing workload and increasing the average quality of papers being reviewed; 3) incentivizing authors to write fewer papers of higher quality.
Ghost in the Minecraft: Generally Capable Agents for Open-World Environments via Large Language Models with Text-based Knowledge and Memory
Jun 01, 2023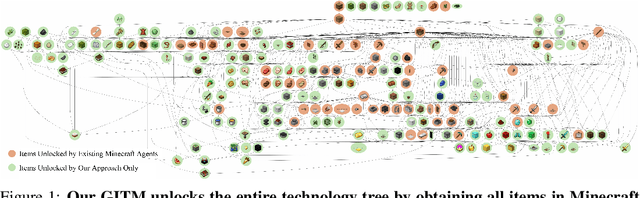

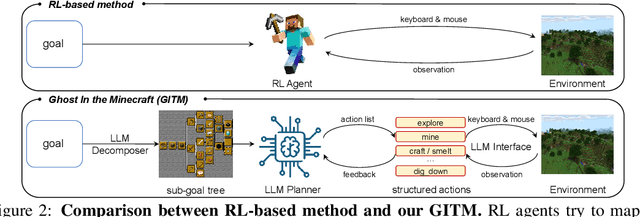
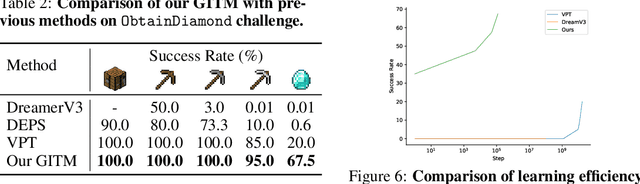
The captivating realm of Minecraft has attracted substantial research interest in recent years, serving as a rich platform for developing intelligent agents capable of functioning in open-world environments. However, the current research landscape predominantly focuses on specific objectives, such as the popular "ObtainDiamond" task, and has not yet shown effective generalization to a broader spectrum of tasks. Furthermore, the current leading success rate for the "ObtainDiamond" task stands at around 20%, highlighting the limitations of Reinforcement Learning (RL) based controllers used in existing methods. To tackle these challenges, we introduce Ghost in the Minecraft (GITM), a novel framework integrates Large Language Models (LLMs) with text-based knowledge and memory, aiming to create Generally Capable Agents (GCAs) in Minecraft. These agents, equipped with the logic and common sense capabilities of LLMs, can skillfully navigate complex, sparse-reward environments with text-based interactions. We develop a set of structured actions and leverage LLMs to generate action plans for the agents to execute. The resulting LLM-based agent markedly surpasses previous methods, achieving a remarkable improvement of +47.5% in success rate on the "ObtainDiamond" task, demonstrating superior robustness compared to traditional RL-based controllers. Notably, our agent is the first to procure all items in the Minecraft Overworld technology tree, demonstrating its extensive capabilities. GITM does not need any GPU for training, but a single CPU node with 32 CPU cores is enough. This research shows the potential of LLMs in developing capable agents for handling long-horizon, complex tasks and adapting to uncertainties in open-world environments. See the project website at https://github.com/OpenGVLab/GITM.
Towards All-in-one Pre-training via Maximizing Multi-modal Mutual Information
Nov 21, 2022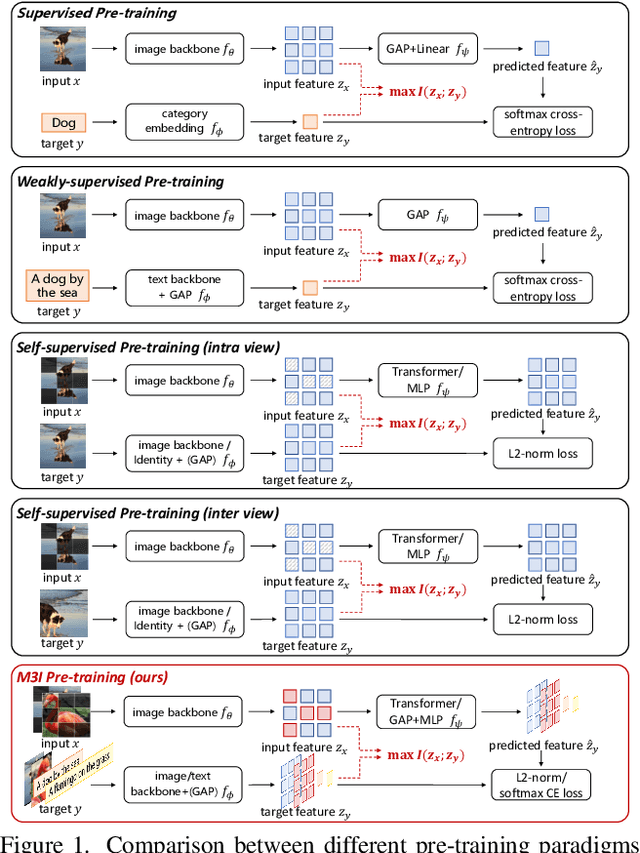
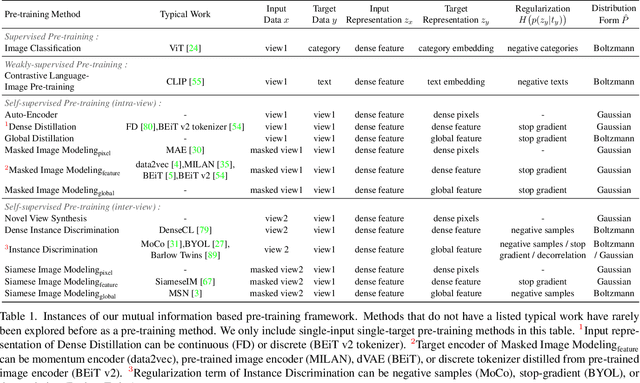
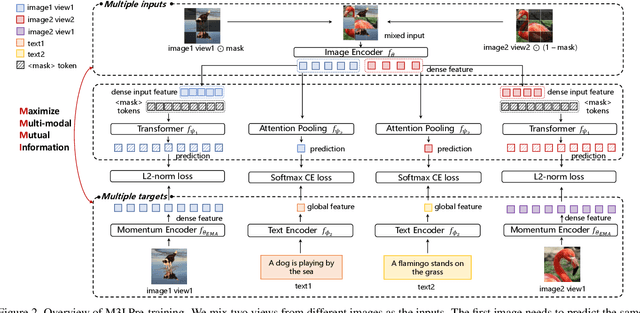
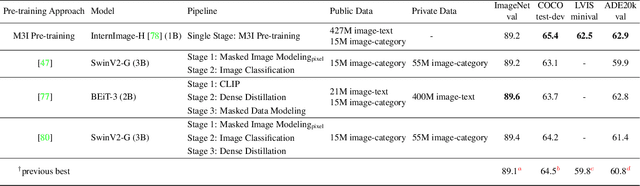
To effectively exploit the potential of large-scale models, various pre-training strategies supported by massive data from different sources are proposed, including supervised pre-training, weakly-supervised pre-training, and self-supervised pre-training. It has been proved that combining multiple pre-training strategies and data from various modalities/sources can greatly boost the training of large-scale models. However, current works adopt a multi-stage pre-training system, where the complex pipeline may increase the uncertainty and instability of the pre-training. It is thus desirable that these strategies can be integrated in a single-stage manner. In this paper, we first propose a general multi-modal mutual information formula as a unified optimization target and demonstrate that all existing approaches are special cases of our framework. Under this unified perspective, we propose an all-in-one single-stage pre-training approach, named Maximizing Multi-modal Mutual Information Pre-training (M3I Pre-training). Our approach achieves better performance than previous pre-training methods on various vision benchmarks, including ImageNet classification, COCO object detection, LVIS long-tailed object detection, and ADE20k semantic segmentation. Notably, we successfully pre-train a billion-level parameter image backbone and achieve state-of-the-art performance on various benchmarks. Code shall be released at https://github.com/OpenGVLab/M3I-Pretraining.
When does SGD favor flat minima? A quantitative characterization via linear stability
Jul 06, 2022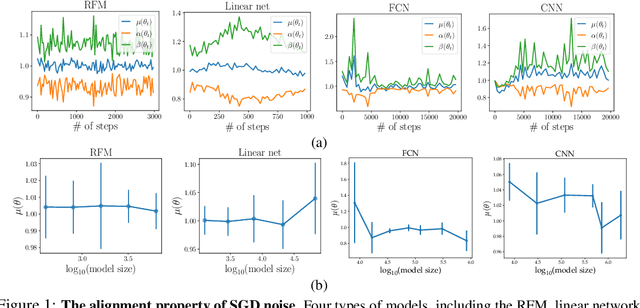

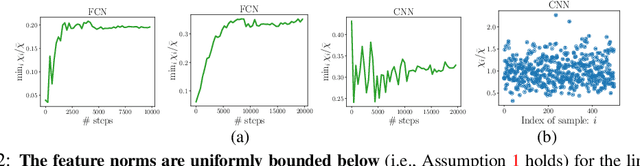
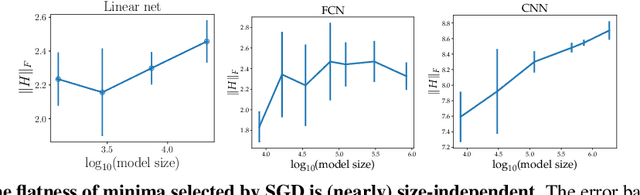
The observation that stochastic gradient descent (SGD) favors flat minima has played a fundamental role in understanding implicit regularization of SGD and guiding the tuning of hyperparameters. In this paper, we provide a quantitative explanation of this striking phenomenon by relating the particular noise structure of SGD to its \emph{linear stability} (Wu et al., 2018). Specifically, we consider training over-parameterized models with square loss. We prove that if a global minimum $\theta^*$ is linearly stable for SGD, then it must satisfy $\|H(\theta^*)\|_F\leq O(\sqrt{B}/\eta)$, where $\|H(\theta^*)\|_F, B,\eta$ denote the Frobenius norm of Hessian at $\theta^*$, batch size, and learning rate, respectively. Otherwise, SGD will escape from that minimum \emph{exponentially} fast. Hence, for minima accessible to SGD, the flatness -- as measured by the Frobenius norm of the Hessian -- is bounded independently of the model size and sample size. The key to obtaining these results is exploiting the particular geometry awareness of SGD noise: 1) the noise magnitude is proportional to loss value; 2) the noise directions concentrate in the sharp directions of local landscape. This property of SGD noise provably holds for linear networks and random feature models (RFMs) and is empirically verified for nonlinear networks. Moreover, the validity and practical relevance of our theoretical findings are justified by extensive numerical experiments.
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Oct 08, 2020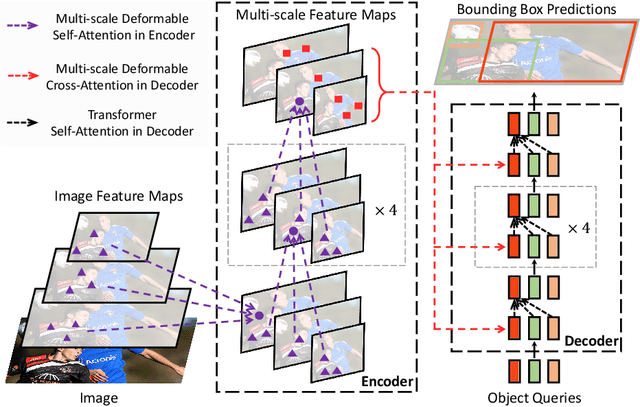
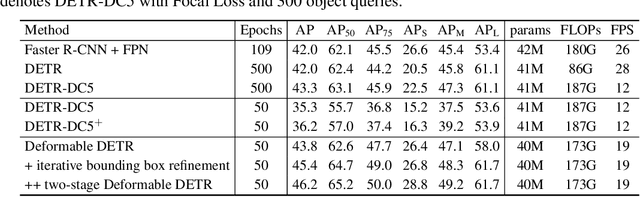
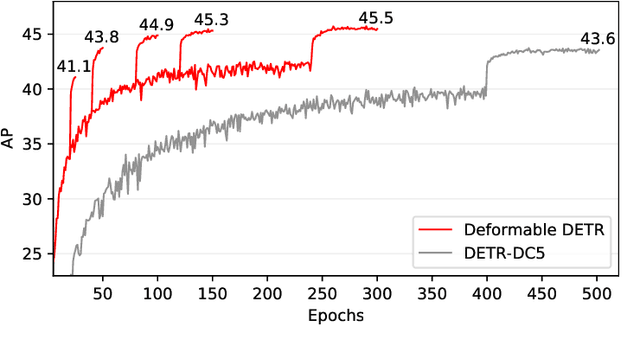
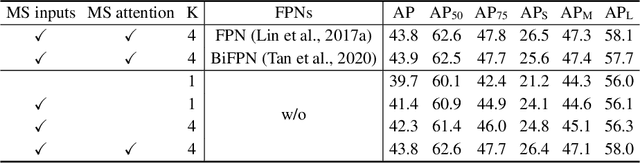
DETR has been recently proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance. However, it suffers from slow convergence and limited feature spatial resolution, due to the limitation of Transformer attention modules in processing image feature maps. To mitigate these issues, we proposed Deformable DETR, whose attention modules only attend to a small set of key sampling points around a reference. Deformable DETR can achieve better performance than DETR (especially on small objects) with 10$\times$ less training epochs. Extensive experiments on the COCO benchmark demonstrate the effectiveness of our approach. Code shall be released.
Benign Overfitting and Noisy Features
Aug 06, 2020
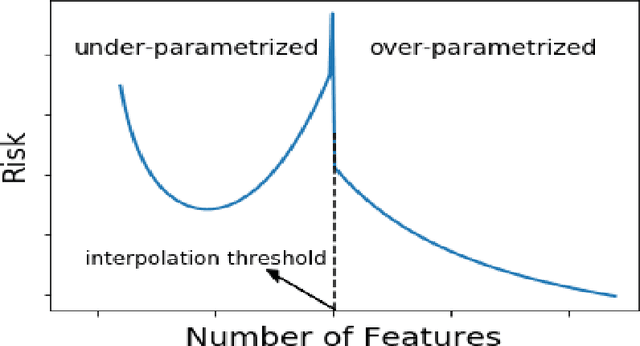
Modern machine learning often operates in the regime where the number of parameters is much higher than the number of data points, with zero training loss and yet good generalization, thereby contradicting the classical bias-variance trade-off. This \textit{benign overfitting} phenomenon has recently been characterized using so called \textit{double descent} curves where the risk undergoes another descent (in addition to the classical U-shaped learning curve when the number of parameters is small) as we increase the number of parameters beyond a certain threshold. In this paper, we examine the conditions under which \textit{Benign Overfitting} occurs in the random feature (RF) models, i.e. in a two-layer neural network with fixed first layer weights. We adopt a new view of random feature and show that \textit{benign overfitting} arises due to the noise which resides in such features (the noise may already be present in the data and propagate to the features or it may be added by the user to the features directly) and plays an important implicit regularization role in the phenomenon.
Robust Learning Rate Selection for Stochastic Optimization via Splitting Diagnostic
Oct 24, 2019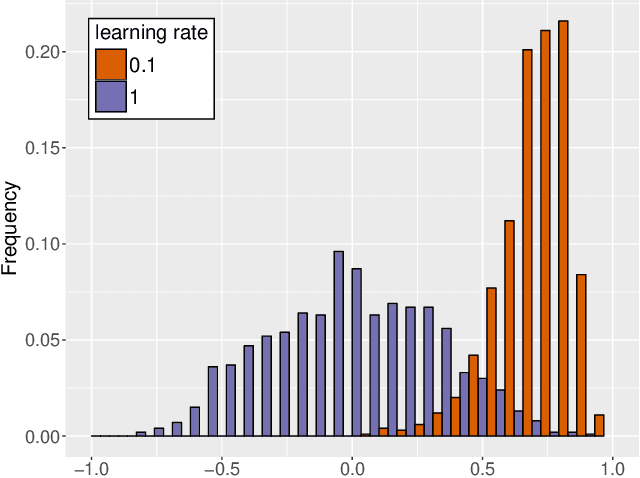
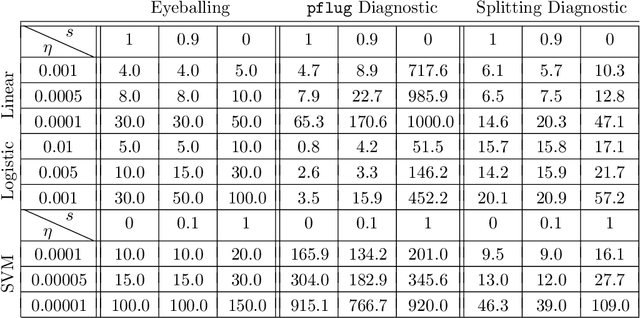

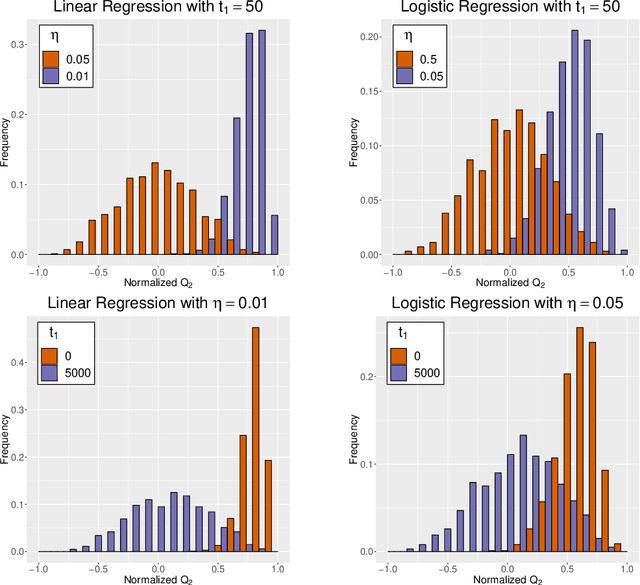
This paper proposes SplitSGD, a new stochastic optimization algorithm with a dynamic learning rate selection rule. This procedure decreases the learning rate for better adaptation to the local geometry of the objective function whenever a stationary phase is detected, that is, the iterates are likely to bounce around a vicinity of a local minimum. The detection is performed by splitting the single thread into two and using the inner products of the gradients from the two threads as a measure of stationarity. This learning rate selection is provably valid, robust to initial parameters, easy-to-implement, and essentially does not incur additional computational cost. Finally, we illustrate the robust convergence properties of SplitSGD through extensive experiments.