 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhu Li
CompGS: Efficient 3D Scene Representation via Compressed Gaussian Splatting
Apr 15, 2024
Gaussian splatting, renowned for its exceptional rendering quality and efficiency, has emerged as a prominent technique in 3D scene representation. However, the substantial data volume of Gaussian splatting impedes its practical utility in real-world applications. Herein, we propose an efficient 3D scene representation, named Compressed Gaussian Splatting (CompGS), which harnesses compact Gaussian primitives for faithful 3D scene modeling with a remarkably reduced data size. To ensure the compactness of Gaussian primitives, we devise a hybrid primitive structure that captures predictive relationships between each other. Then, we exploit a small set of anchor primitives for prediction, allowing the majority of primitives to be encapsulated into highly compact residual forms. Moreover, we develop a rate-constrained optimization scheme to eliminate redundancies within such hybrid primitives, steering our CompGS towards an optimal trade-off between bitrate consumption and representation efficacy. Experimental results show that the proposed CompGS significantly outperforms existing methods, achieving superior compactness in 3D scene representation without compromising model accuracy and rendering quality. Our code will be released on GitHub for further research.
MODIPHY: Multimodal Obscured Detection for IoT using PHantom Convolution-Enabled Faster YOLO
Feb 12, 2024
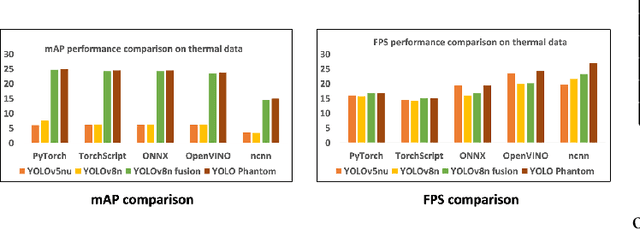
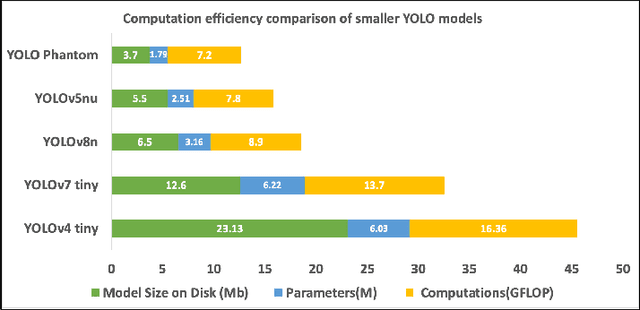
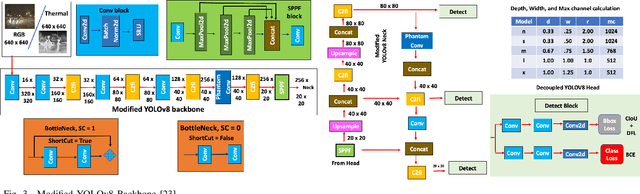
Low-light conditions and occluded scenarios impede object detection in real-world Internet of Things (IoT) applications like autonomous vehicles and security systems. While advanced machine learning models strive for accuracy, their computational demands clash with the limitations of resource-constrained devices, hampering real-time performance. In our current research, we tackle this challenge, by introducing "YOLO Phantom", one of the smallest YOLO models ever conceived. YOLO Phantom utilizes the novel Phantom Convolution block, achieving comparable accuracy to the latest YOLOv8n model while simultaneously reducing both parameters and model size by 43%, resulting in a significant 19% reduction in Giga Floating Point Operations (GFLOPs). YOLO Phantom leverages transfer learning on our multimodal RGB-infrared dataset to address low-light and occlusion issues, equipping it with robust vision under adverse conditions. Its real-world efficacy is demonstrated on an IoT platform with advanced low-light and RGB cameras, seamlessly connecting to an AWS-based notification endpoint for efficient real-time object detection. Benchmarks reveal a substantial boost of 17% and 14% in frames per second (FPS) for thermal and RGB detection, respectively, compared to the baseline YOLOv8n model. For community contribution, both the code and the multimodal dataset are available on GitHub.
Towards Optimal Sobolev Norm Rates for the Vector-Valued Regularized Least-Squares Algorithm
Dec 13, 2023We present the first optimal rates for infinite-dimensional vector-valued ridge regression on a continuous scale of norms that interpolate between $L_2$ and the hypothesis space, which we consider as a vector-valued reproducing kernel Hilbert space. These rates allow to treat the misspecified case in which the true regression function is not contained in the hypothesis space. We combine standard assumptions on the capacity of the hypothesis space with a novel tensor product construction of vector-valued interpolation spaces in order to characterize the smoothness of the regression function. Our upper bound not only attains the same rate as real-valued kernel ridge regression, but also removes the assumption that the target regression function is bounded. For the lower bound, we reduce the problem to the scalar setting using a projection argument. We show that these rates are optimal in most cases and independent of the dimension of the output space. We illustrate our results for the special case of vector-valued Sobolev spaces.
Applications of Large Scale Foundation Models for Autonomous Driving
Dec 04, 2023
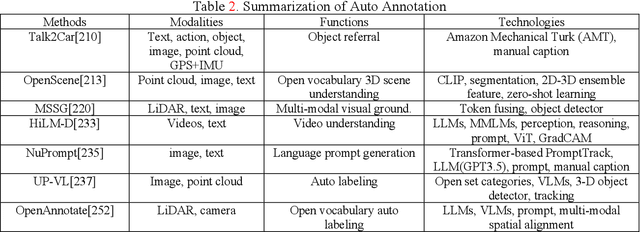

Since DARPA Grand Challenges (rural) in 2004/05 and Urban Challenges in 2007, autonomous driving has been the most active field of AI applications. Recently powered by large language models (LLMs), chat systems, such as chatGPT and PaLM, emerge and rapidly become a promising direction to achieve artificial general intelligence (AGI) in natural language processing (NLP). There comes a natural thinking that we could employ these abilities to reformulate autonomous driving. By combining LLM with foundation models, it is possible to utilize the human knowledge, commonsense and reasoning to rebuild autonomous driving systems from the current long-tailed AI dilemma. In this paper, we investigate the techniques of foundation models and LLMs applied for autonomous driving, categorized as simulation, world model, data annotation and planning or E2E solutions etc.
See SIFT in a Rain
Nov 01, 2023Rain streaks bring complicated pixel intensity changes and additional gradients, greatly obstructing the extraction of image features from background. This causes serious performance degradation in feature-based applications. Thus, it is critical to remove rain streaks from a single rainy image to recover image features. Recently, many excellent image deraining methods have made remarkable progress. However, these human visual system-driven approaches mainly focus on improving image quality with pixel recovery as loss function, and neglect how to enhance image feature recovery ability. To address this issue, we propose a task-driven image deraining algorithm to strengthen image feature supply for subsequent feature-based applications. Due to the extensive use and strong practicability of Scale-Invariant Feature Transform (SIFT), we first propose two separate networks using distinct losses and modules to achieve two goals, respectively. One is difference of Gaussian (DoG) pyramid recovery network (DPRNet) for SIFT detection, and the other gradients of Gaussian images recovery network (GGIRNet) for SIFT description. Second, in the DPRNet we propose an alternative interest point loss that directly penalizes scale response extrema to recover the DoG pyramid. Third, we advance a gradient attention module in the GGIRNet to recover those gradients of Gaussian images. Finally, with the recovered DoG pyramid and gradients, we can regain SIFT key points. This divide-and-conquer scheme to set different objectives for SIFT detection and description leads to good robustness. Compared with state-of-the-art methods, experimental results demonstrate that our proposed algorithm achieves better performance in both the number of recovered SIFT key points and their accuracy.
* A direct DoG feature pyramid recovery from rainy pixels solution for SIFT detection, accepted by T-CSVT, 2023
Nonlinear Meta-Learning Can Guarantee Faster Rates
Jul 20, 2023Many recent theoretical works on \emph{meta-learning} aim to achieve guarantees in leveraging similar representational structures from related tasks towards simplifying a target task. Importantly, the main aim in theory works on the subject is to understand the extent to which convergence rates -- in learning a common representation -- \emph{may scale with the number $N$ of tasks} (as well as the number of samples per task). First steps in this setting demonstrate this property when both the shared representation amongst tasks, and task-specific regression functions, are linear. This linear setting readily reveals the benefits of aggregating tasks, e.g., via averaging arguments. In practice, however, the representation is often highly nonlinear, introducing nontrivial biases in each task that cannot easily be averaged out as in the linear case. In the present work, we derive theoretical guarantees for meta-learning with nonlinear representations. In particular, assuming the shared nonlinearity maps to an infinite-dimensional RKHS, we show that additional biases can be mitigated with careful regularization that leverages the smoothness of task-specific regression functions,
Learning Dynamic Point Cloud Compression via Hierarchical Inter-frame Block Matching
May 16, 2023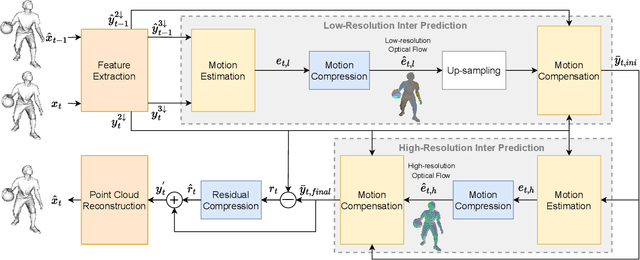
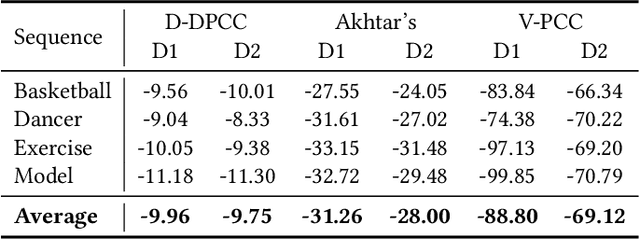
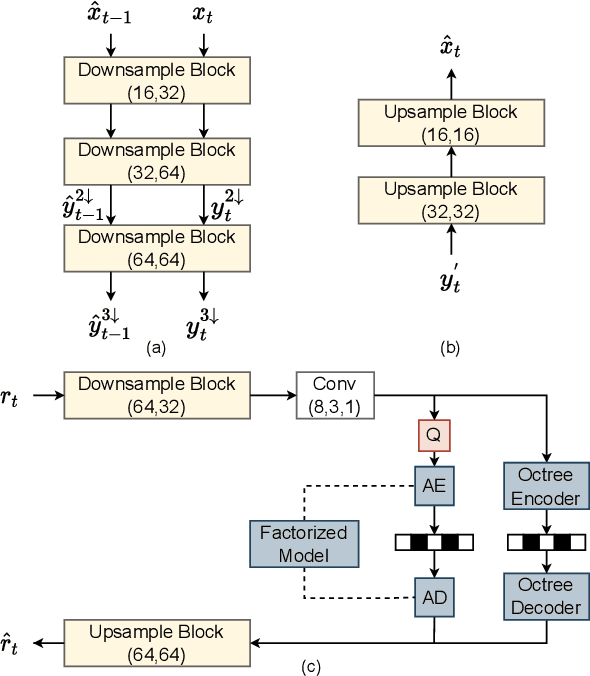
3D dynamic point cloud (DPC) compression relies on mining its temporal context, which faces significant challenges due to DPC's sparsity and non-uniform structure. Existing methods are limited in capturing sufficient temporal dependencies. Therefore, this paper proposes a learning-based DPC compression framework via hierarchical block-matching-based inter-prediction module to compensate and compress the DPC geometry in latent space. Specifically, we propose a hierarchical motion estimation and motion compensation (Hie-ME/MC) framework for flexible inter-prediction, which dynamically selects the granularity of optical flow to encapsulate the motion information accurately. To improve the motion estimation efficiency of the proposed inter-prediction module, we further design a KNN-attention block matching (KABM) network that determines the impact of potential corresponding points based on the geometry and feature correlation. Finally, we compress the residual and the multi-scale optical flow with a fully-factorized deep entropy model. The experiment result on the MPEG-specified Owlii Dynamic Human Dynamic Point Cloud (Owlii) dataset shows that our framework outperforms the previous state-of-the-art methods and the MPEG standard V-PCC v18 in inter-frame low-delay mode.
Multiscale Latent-Guided Entropy Model for LiDAR Point Cloud Compression
Sep 26, 2022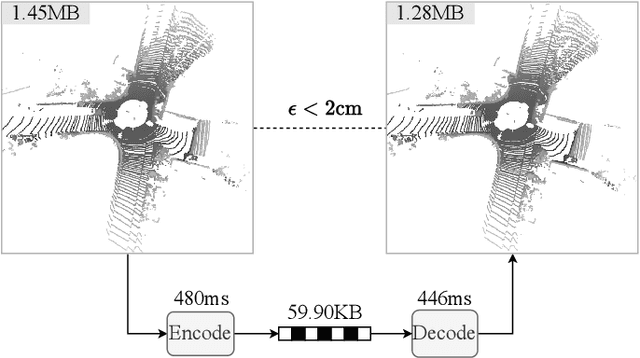
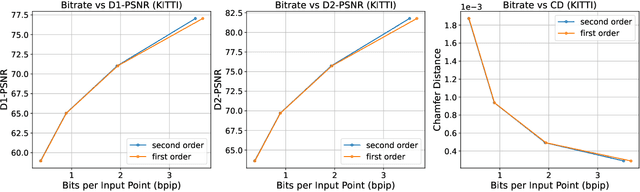
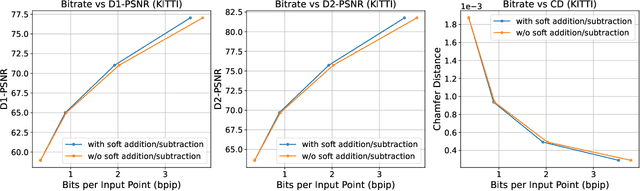
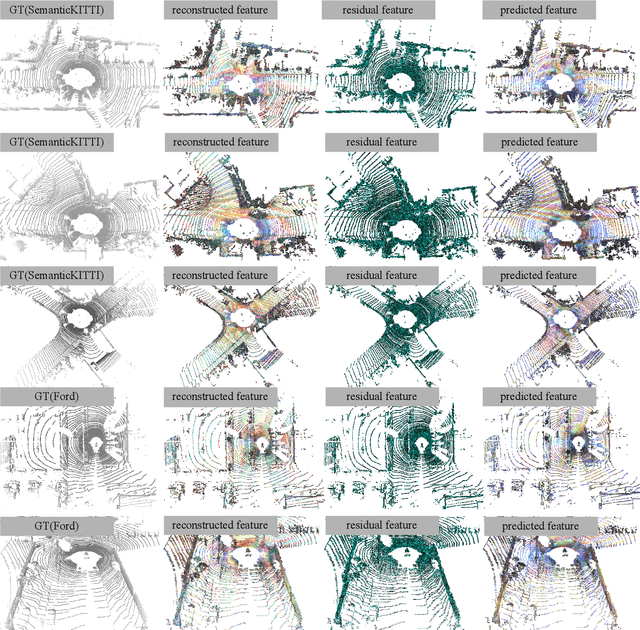
The non-uniform distribution and extremely sparse nature of the LiDAR point cloud (LPC) bring significant challenges to its high-efficient compression. This paper proposes a novel end-to-end, fully-factorized deep framework that encodes the original LPC into an octree structure and hierarchically decomposes the octree entropy model in layers. The proposed framework utilizes a hierarchical latent variable as side information to encapsulate the sibling and ancestor dependence, which provides sufficient context information for the modelling of point cloud distribution while enabling the parallel encoding and decoding of octree nodes in the same layer. Besides, we propose a residual coding framework for the compression of the latent variable, which explores the spatial correlation of each layer by progressive downsampling, and model the corresponding residual with a fully-factorized entropy model. Furthermore, we propose soft addition and subtraction for residual coding to improve network flexibility. The comprehensive experiment results on the LiDAR benchmark SemanticKITTI and MPEG-specified dataset Ford demonstrates that our proposed framework achieves state-of-the-art performance among all the previous LPC frameworks. Besides, our end-to-end, fully-factorized framework is proved by experiment to be high-parallelized and time-efficient and saves more than 99.8% of decoding time compared to previous state-of-the-art methods on LPC compression.
Optimal Rates for Regularized Conditional Mean Embedding Learning
Aug 02, 2022We address the consistency of a kernel ridge regression estimate of the conditional mean embedding (CME), which is an embedding of the conditional distribution of $Y$ given $X$ into a target reproducing kernel Hilbert space $\mathcal{H}_Y$. The CME allows us to take conditional expectations of target RKHS functions, and has been employed in nonparametric causal and Bayesian inference. We address the misspecified setting, where the target CME is in the space of Hilbert-Schmidt operators acting from an input interpolation space between $\mathcal{H}_X$ and $L_2$, to $\mathcal{H}_Y$. This space of operators is shown to be isomorphic to a newly defined vector-valued interpolation space. Using this isomorphism, we derive a novel and adaptive statistical learning rate for the empirical CME estimator under the misspecified setting. Our analysis reveals that our rates match the optimal $O(\log n / n)$ rates without assuming $\mathcal{H}_Y$ to be finite dimensional. We further establish a lower bound on the learning rate, which shows that the obtained upper bound is optimal.
Inter-Frame Compression for Dynamic Point Cloud Geometry Coding
Jul 25, 2022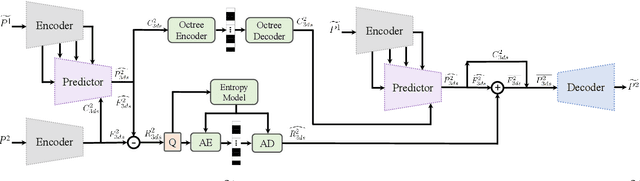


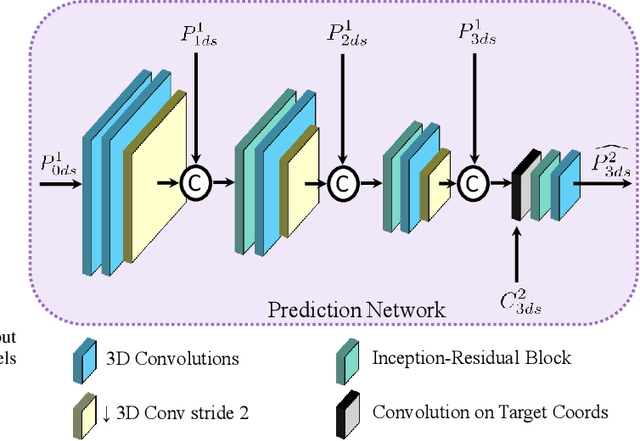
Efficient point cloud compression is essential for applications like virtual and mixed reality, autonomous driving, and cultural heritage. In this paper, we propose a deep learning-based inter-frame encoding scheme for dynamic point cloud geometry compression. We propose a lossy geometry compression scheme that predicts the latent representation of the current frame using the previous frame by employing a novel prediction network. Our proposed network utilizes sparse convolutions with hierarchical multiscale 3D feature learning to encode the current frame using the previous frame. We employ convolution on target coordinates to map the latent representation of the previous frame to the downsampled coordinates of the current frame to predict the current frame's feature embedding. Our framework transmits the residual of the predicted features and the actual features by compressing them using a learned probabilistic factorized entropy model. At the receiver, the decoder hierarchically reconstructs the current frame by progressively rescaling the feature embedding. We compared our model to the state-of-the-art Video-based Point Cloud Compression (V-PCC) and Geometry-based Point Cloud Compression (G-PCC) schemes standardized by the Moving Picture Experts Group (MPEG). Our method achieves more than 91% BD-Rate Bjontegaard Delta Rate) reduction against G-PCC, more than 62% BD-Rate reduction against V-PCC intra-frame encoding mode, and more than 52% BD-Rate savings against V-PCC P-frame-based inter-frame encoding mode using HEVC.