 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArthur Gretton
Proxy Methods for Domain Adaptation
Mar 12, 2024

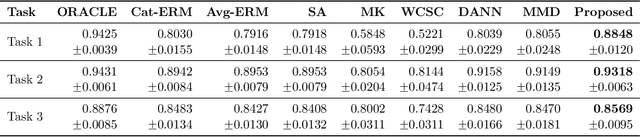
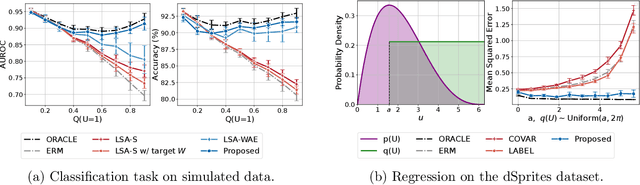
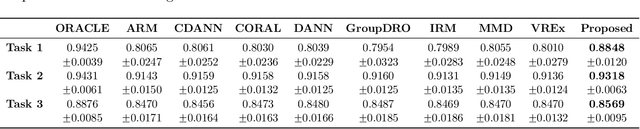
We study the problem of domain adaptation under distribution shift, where the shift is due to a change in the distribution of an unobserved, latent variable that confounds both the covariates and the labels. In this setting, neither the covariate shift nor the label shift assumptions apply. Our approach to adaptation employs proximal causal learning, a technique for estimating causal effects in settings where proxies of unobserved confounders are available. We demonstrate that proxy variables allow for adaptation to distribution shift without explicitly recovering or modeling latent variables. We consider two settings, (i) Concept Bottleneck: an additional ''concept'' variable is observed that mediates the relationship between the covariates and labels; (ii) Multi-domain: training data from multiple source domains is available, where each source domain exhibits a different distribution over the latent confounder. We develop a two-stage kernel estimation approach to adapt to complex distribution shifts in both settings. In our experiments, we show that our approach outperforms other methods, notably those which explicitly recover the latent confounder.
Practical Kernel Tests of Conditional Independence
Feb 20, 2024We describe a data-efficient, kernel-based approach to statistical testing of conditional independence. A major challenge of conditional independence testing, absent in tests of unconditional independence, is to obtain the correct test level (the specified upper bound on the rate of false positives), while still attaining competitive test power. Excess false positives arise due to bias in the test statistic, which is obtained using nonparametric kernel ridge regression. We propose three methods for bias control to correct the test level, based on data splitting, auxiliary data, and (where possible) simpler function classes. We show these combined strategies are effective both for synthetic and real-world data.
A Distributional Analogue to the Successor Representation
Feb 13, 2024This paper contributes a new approach for distributional reinforcement learning which elucidates a clean separation of transition structure and reward in the learning process. Analogous to how the successor representation (SR) describes the expected consequences of behaving according to a given policy, our distributional successor measure (SM) describes the distributional consequences of this behaviour. We formulate the distributional SM as a distribution over distributions and provide theory connecting it with distributional and model-based reinforcement learning. Moreover, we propose an algorithm that learns the distributional SM from data by minimizing a two-level maximum mean discrepancy. Key to our method are a number of algorithmic techniques that are independently valuable for learning generative models of state. As an illustration of the usefulness of the distributional SM, we show that it enables zero-shot risk-sensitive policy evaluation in a way that was not previously possible.
Towards Optimal Sobolev Norm Rates for the Vector-Valued Regularized Least-Squares Algorithm
Dec 13, 2023We present the first optimal rates for infinite-dimensional vector-valued ridge regression on a continuous scale of norms that interpolate between $L_2$ and the hypothesis space, which we consider as a vector-valued reproducing kernel Hilbert space. These rates allow to treat the misspecified case in which the true regression function is not contained in the hypothesis space. We combine standard assumptions on the capacity of the hypothesis space with a novel tensor product construction of vector-valued interpolation spaces in order to characterize the smoothness of the regression function. Our upper bound not only attains the same rate as real-valued kernel ridge regression, but also removes the assumption that the target regression function is bounded. For the lower bound, we reduce the problem to the scalar setting using a projection argument. We show that these rates are optimal in most cases and independent of the dimension of the output space. We illustrate our results for the special case of vector-valued Sobolev spaces.
Distributional Bellman Operators over Mean Embeddings
Dec 09, 2023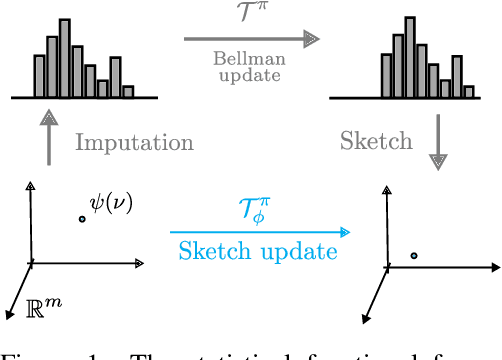
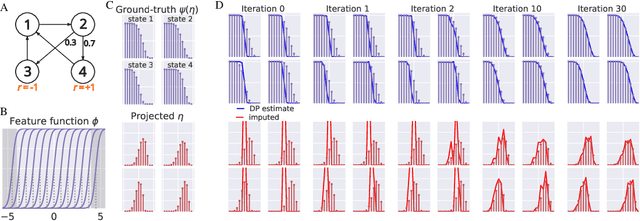
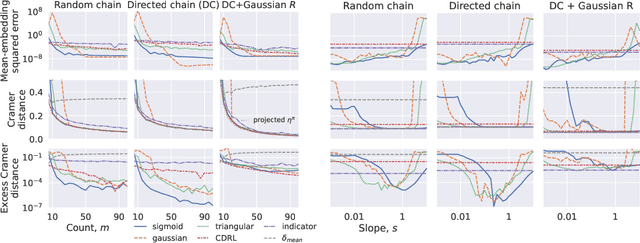
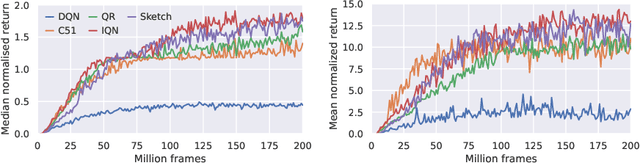
We propose a novel algorithmic framework for distributional reinforcement learning, based on learning finite-dimensional mean embeddings of return distributions. We derive several new algorithms for dynamic programming and temporal-difference learning based on this framework, provide asymptotic convergence theory, and examine the empirical performance of the algorithms on a suite of tabular tasks. Further, we show that this approach can be straightforwardly combined with deep reinforcement learning, and obtain a new deep RL agent that improves over baseline distributional approaches on the Arcade Learning Environment.
Kernel Single Proxy Control for Deterministic Confounding
Aug 08, 2023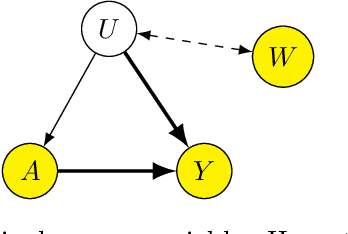
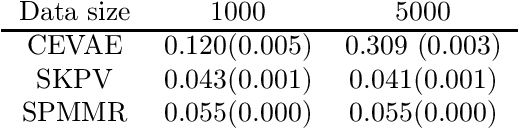
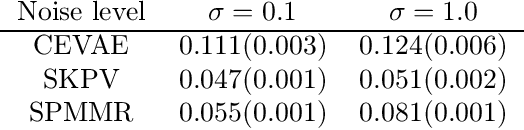
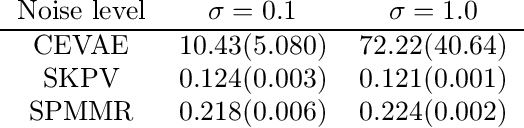
We consider the problem of causal effect estimation with an unobserved confounder, where we observe a proxy variable that is associated with the confounder. Although Proxy Causal Learning (PCL) uses two proxy variables to recover the true causal effect, we show that a single proxy variable is sufficient for causal estimation if the outcome is generated deterministically, generalizing Control Outcome Calibration Approach (COCA). We propose two kernel-based methods for this setting: the first based on the two-stage regression approach, and the second based on a maximum moment restriction approach. We prove that both approaches can consistently estimate the causal effect, and we empirically demonstrate that we can successfully recover the causal effect on a synthetic dataset.
Nonlinear Meta-Learning Can Guarantee Faster Rates
Jul 20, 2023Many recent theoretical works on \emph{meta-learning} aim to achieve guarantees in leveraging similar representational structures from related tasks towards simplifying a target task. Importantly, the main aim in theory works on the subject is to understand the extent to which convergence rates -- in learning a common representation -- \emph{may scale with the number $N$ of tasks} (as well as the number of samples per task). First steps in this setting demonstrate this property when both the shared representation amongst tasks, and task-specific regression functions, are linear. This linear setting readily reveals the benefits of aggregating tasks, e.g., via averaging arguments. In practice, however, the representation is often highly nonlinear, introducing nontrivial biases in each task that cannot easily be averaged out as in the linear case. In the present work, we derive theoretical guarantees for meta-learning with nonlinear representations. In particular, assuming the shared nonlinearity maps to an infinite-dimensional RKHS, we show that additional biases can be mitigated with careful regularization that leverages the smoothness of task-specific regression functions,
Prediction under Latent Subgroup Shifts with High-Dimensional Observations
Jun 23, 2023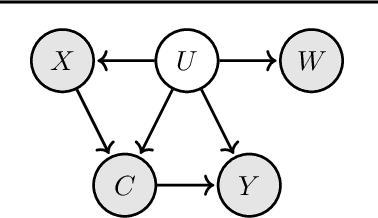
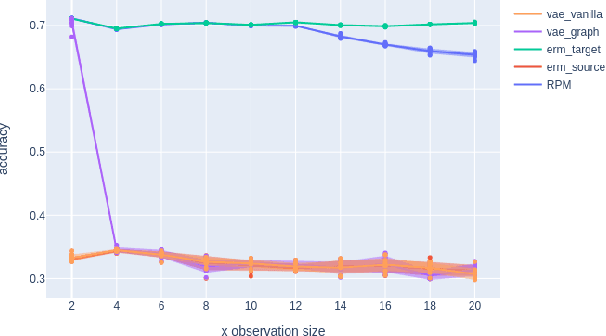
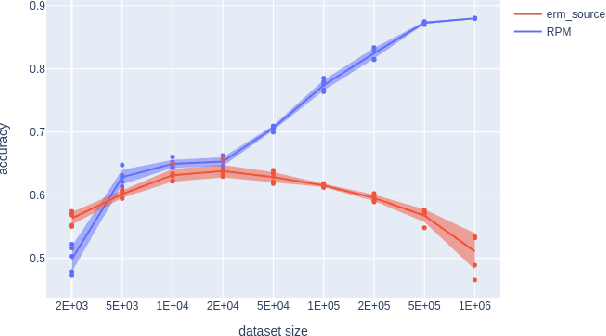
We introduce a new approach to prediction in graphical models with latent-shift adaptation, i.e., where source and target environments differ in the distribution of an unobserved confounding latent variable. Previous work has shown that as long as "concept" and "proxy" variables with appropriate dependence are observed in the source environment, the latent-associated distributional changes can be identified, and target predictions adapted accurately. However, practical estimation methods do not scale well when the observations are complex and high-dimensional, even if the confounding latent is categorical. Here we build upon a recently proposed probabilistic unsupervised learning framework, the recognition-parametrised model (RPM), to recover low-dimensional, discrete latents from image observations. Applied to the problem of latent shifts, our novel form of RPM identifies causal latent structure in the source environment, and adapts properly to predict in the target. We demonstrate results in settings where predictor and proxy are high-dimensional images, a context to which previous methods fail to scale.
MMD-FUSE: Learning and Combining Kernels for Two-Sample Testing Without Data Splitting
Jun 14, 2023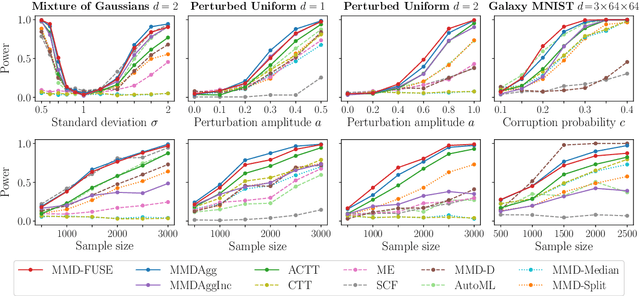
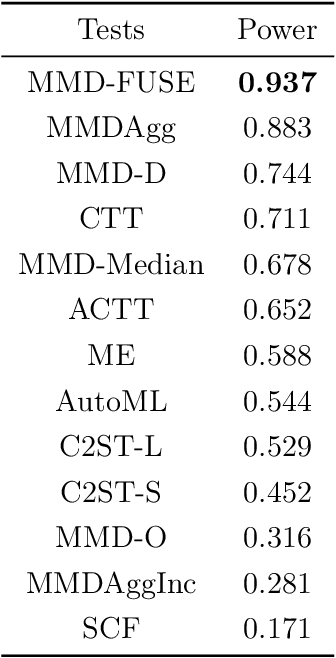
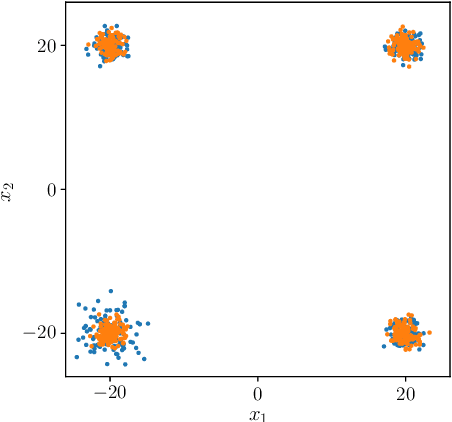
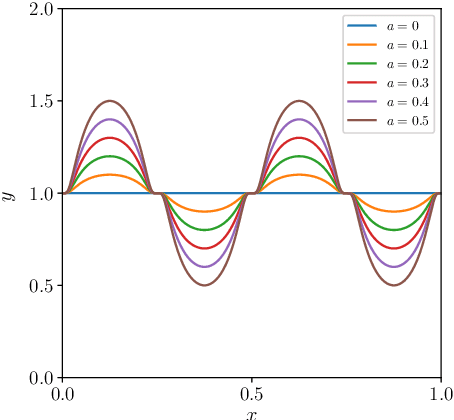
We propose novel statistics which maximise the power of a two-sample test based on the Maximum Mean Discrepancy (MMD), by adapting over the set of kernels used in defining it. For finite sets, this reduces to combining (normalised) MMD values under each of these kernels via a weighted soft maximum. Exponential concentration bounds are proved for our proposed statistics under the null and alternative. We further show how these kernels can be chosen in a data-dependent but permutation-independent way, in a well-calibrated test, avoiding data splitting. This technique applies more broadly to general permutation-based MMD testing, and includes the use of deep kernels with features learnt using unsupervised models such as auto-encoders. We highlight the applicability of our MMD-FUSE test on both synthetic low-dimensional and real-world high-dimensional data, and compare its performance in terms of power against current state-of-the-art kernel tests.
Deep Hypothesis Tests Detect Clinically Relevant Subgroup Shifts in Medical Images
Mar 08, 2023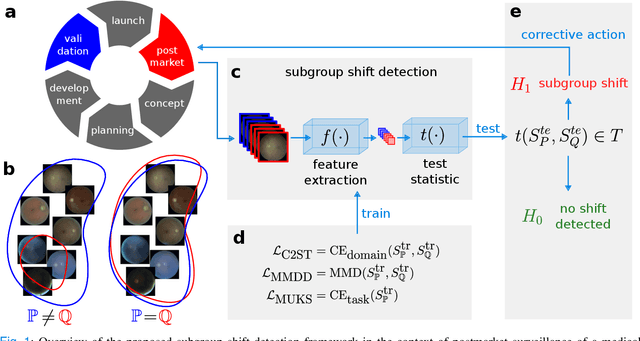

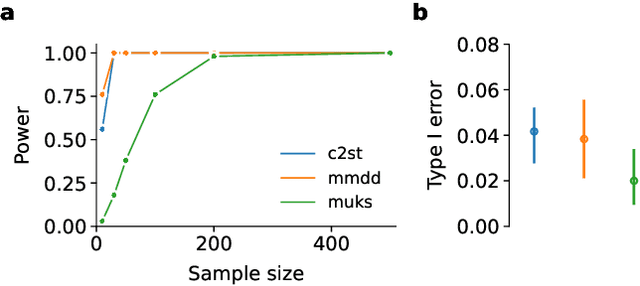
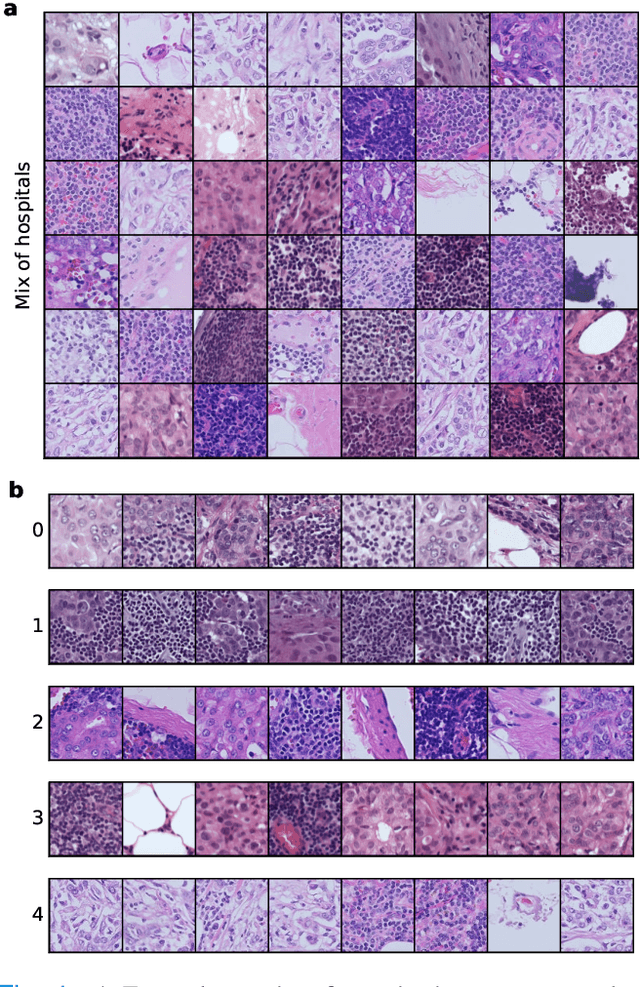
Distribution shifts remain a fundamental problem for the safe application of machine learning systems. If undetected, they may impact the real-world performance of such systems or will at least render original performance claims invalid. In this paper, we focus on the detection of subgroup shifts, a type of distribution shift that can occur when subgroups have a different prevalence during validation compared to the deployment setting. For example, algorithms developed on data from various acquisition settings may be predominantly applied in hospitals with lower quality data acquisition, leading to an inadvertent performance drop. We formulate subgroup shift detection in the framework of statistical hypothesis testing and show that recent state-of-the-art statistical tests can be effectively applied to subgroup shift detection on medical imaging data. We provide synthetic experiments as well as extensive evaluation on clinically meaningful subgroup shifts on histopathology as well as retinal fundus images. We conclude that classifier-based subgroup shift detection tests could be a particularly useful tool for post-market surveillance of deployed ML systems.