 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDanica J. Sutherland
Language Model Evolution: An Iterated Learning Perspective
Apr 04, 2024
With the widespread adoption of Large Language Models (LLMs), the prevalence of iterative interactions among these models is anticipated to increase. Notably, recent advancements in multi-round self-improving methods allow LLMs to generate new examples for training subsequent models. At the same time, multi-agent LLM systems, involving automated interactions among agents, are also increasing in prominence. Thus, in both short and long terms, LLMs may actively engage in an evolutionary process. We draw parallels between the behavior of LLMs and the evolution of human culture, as the latter has been extensively studied by cognitive scientists for decades. Our approach involves leveraging Iterated Learning (IL), a Bayesian framework that elucidates how subtle biases are magnified during human cultural evolution, to explain some behaviors of LLMs. This paper outlines key characteristics of agents' behavior in the Bayesian-IL framework, including predictions that are supported by experimental verification with various LLMs. This theoretical framework could help to more effectively predict and guide the evolution of LLMs in desired directions.
Practical Kernel Tests of Conditional Independence
Feb 20, 2024We describe a data-efficient, kernel-based approach to statistical testing of conditional independence. A major challenge of conditional independence testing, absent in tests of unconditional independence, is to obtain the correct test level (the specified upper bound on the rate of false positives), while still attaining competitive test power. Excess false positives arise due to bias in the test statistic, which is obtained using nonparametric kernel ridge regression. We propose three methods for bias control to correct the test level, based on data splitting, auxiliary data, and (where possible) simpler function classes. We show these combined strategies are effective both for synthetic and real-world data.
Exploring Active Learning in Meta-Learning: Enhancing Context Set Labeling
Nov 06, 2023Most meta-learning methods assume that the (very small) context set used to establish a new task at test time is passively provided. In some settings, however, it is feasible to actively select which points to label; the potential gain from a careful choice is substantial, but the setting requires major differences from typical active learning setups. We clarify the ways in which active meta-learning can be used to label a context set, depending on which parts of the meta-learning process use active learning. Within this framework, we propose a natural algorithm based on fitting Gaussian mixtures for selecting which points to label; though simple, the algorithm also has theoretical motivation. The proposed algorithm outperforms state-of-the-art active learning methods when used with various meta-learning algorithms across several benchmark datasets.
AdaFlood: Adaptive Flood Regularization
Nov 06, 2023Although neural networks are conventionally optimized towards zero training loss, it has been recently learned that targeting a non-zero training loss threshold, referred to as a flood level, often enables better test time generalization. Current approaches, however, apply the same constant flood level to all training samples, which inherently assumes all the samples have the same difficulty. We present AdaFlood, a novel flood regularization method that adapts the flood level of each training sample according to the difficulty of the sample. Intuitively, since training samples are not equal in difficulty, the target training loss should be conditioned on the instance. Experiments on datasets covering four diverse input modalities - text, images, asynchronous event sequences, and tabular - demonstrate the versatility of AdaFlood across data domains and noise levels.
Improving Compositional Generalization Using Iterated Learning and Simplicial Embeddings
Oct 28, 2023Compositional generalization, the ability of an agent to generalize to unseen combinations of latent factors, is easy for humans but hard for deep neural networks. A line of research in cognitive science has hypothesized a process, ``iterated learning,'' to help explain how human language developed this ability; the theory rests on simultaneous pressures towards compressibility (when an ignorant agent learns from an informed one) and expressivity (when it uses the representation for downstream tasks). Inspired by this process, we propose to improve the compositional generalization of deep networks by using iterated learning on models with simplicial embeddings, which can approximately discretize representations. This approach is further motivated by an analysis of compositionality based on Kolmogorov complexity. We show that this combination of changes improves compositional generalization over other approaches, demonstrating these improvements both on vision tasks with well-understood latent factors and on real molecular graph prediction tasks where the latent structure is unknown.
Queer In AI: A Case Study in Community-Led Participatory AI
Apr 10, 2023
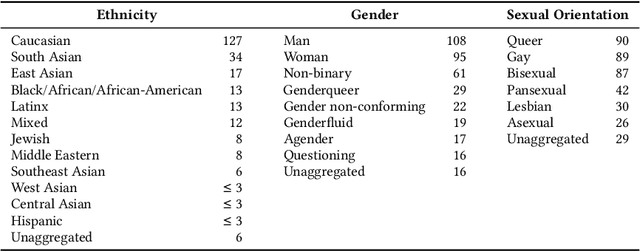
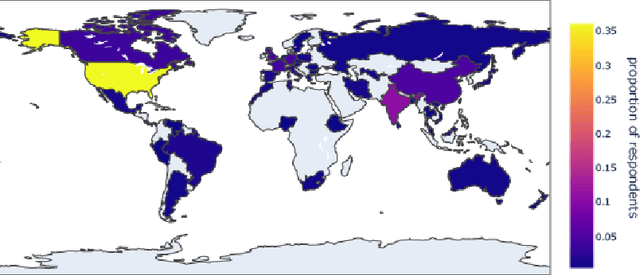

We present Queer in AI as a case study for community-led participatory design in AI. We examine how participatory design and intersectional tenets started and shaped this community's programs over the years. We discuss different challenges that emerged in the process, look at ways this organization has fallen short of operationalizing participatory and intersectional principles, and then assess the organization's impact. Queer in AI provides important lessons and insights for practitioners and theorists of participatory methods broadly through its rejection of hierarchy in favor of decentralization, success at building aid and programs by and for the queer community, and effort to change actors and institutions outside of the queer community. Finally, we theorize how communities like Queer in AI contribute to the participatory design in AI more broadly by fostering cultures of participation in AI, welcoming and empowering marginalized participants, critiquing poor or exploitative participatory practices, and bringing participation to institutions outside of individual research projects. Queer in AI's work serves as a case study of grassroots activism and participatory methods within AI, demonstrating the potential of community-led participatory methods and intersectional praxis, while also providing challenges, case studies, and nuanced insights to researchers developing and using participatory methods.
Exphormer: Sparse Transformers for Graphs
Mar 10, 2023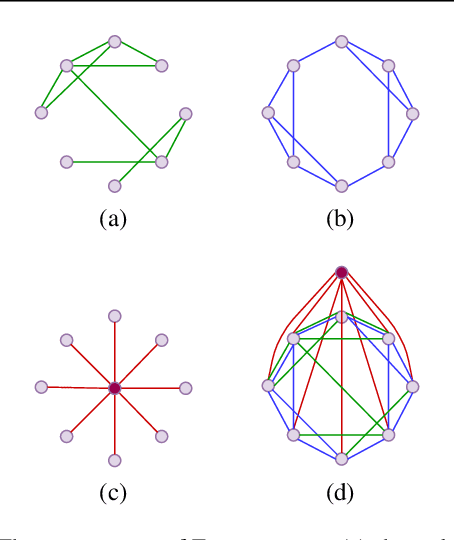
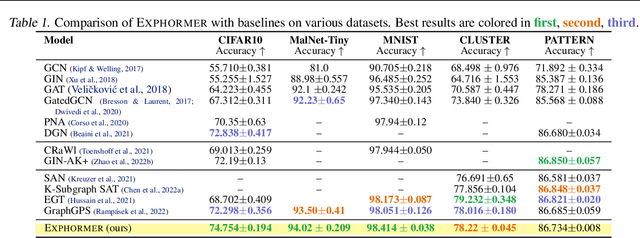
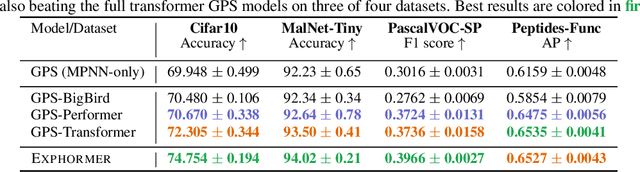
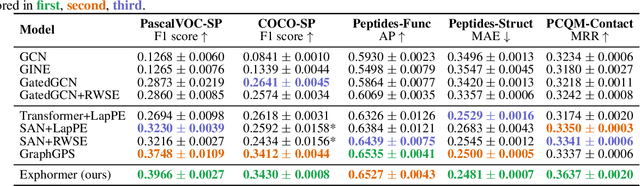
Graph transformers have emerged as a promising architecture for a variety of graph learning and representation tasks. Despite their successes, though, it remains challenging to scale graph transformers to large graphs while maintaining accuracy competitive with message-passing networks. In this paper, we introduce Exphormer, a framework for building powerful and scalable graph transformers. Exphormer consists of a sparse attention mechanism based on two mechanisms: virtual global nodes and expander graphs, whose mathematical characteristics, such as spectral expansion, pseduorandomness, and sparsity, yield graph transformers with complexity only linear in the size of the graph, while allowing us to prove desirable theoretical properties of the resulting transformer models. We show that incorporating \textsc{Exphormer} into the recently-proposed GraphGPS framework produces models with competitive empirical results on a wide variety of graph datasets, including state-of-the-art results on three datasets. We also show that \textsc{Exphormer} can scale to datasets on larger graphs than shown in previous graph transformer architectures. Code can be found at https://github.com/hamed1375/Exphormer.
Differentially Private Neural Tangent Kernels for Privacy-Preserving Data Generation
Mar 03, 2023

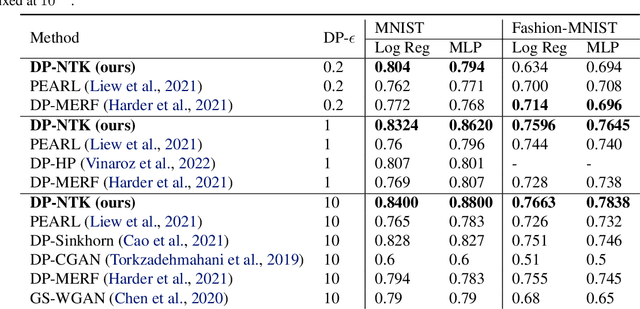
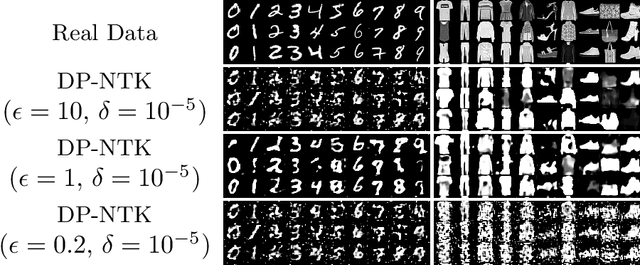
Maximum mean discrepancy (MMD) is a particularly useful distance metric for differentially private data generation: when used with finite-dimensional features it allows us to summarize and privatize the data distribution once, which we can repeatedly use during generator training without further privacy loss. An important question in this framework is, then, what features are useful to distinguish between real and synthetic data distributions, and whether those enable us to generate quality synthetic data. This work considers the using the features of $\textit{neural tangent kernels (NTKs)}$, more precisely $\textit{empirical}$ NTKs (e-NTKs). We find that, perhaps surprisingly, the expressiveness of the untrained e-NTK features is comparable to that of the features taken from pre-trained perceptual features using public data. As a result, our method improves the privacy-accuracy trade-off compared to other state-of-the-art methods, without relying on any public data, as demonstrated on several tabular and image benchmark datasets.
How to prepare your task head for finetuning
Feb 11, 2023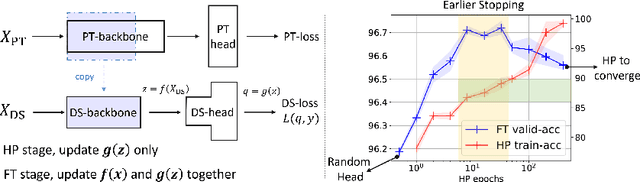

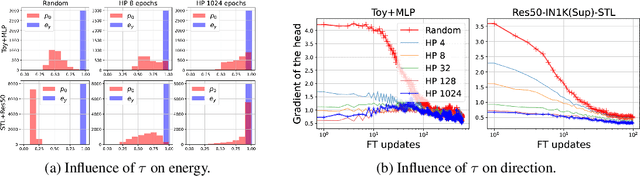

In deep learning, transferring information from a pretrained network to a downstream task by finetuning has many benefits. The choice of task head plays an important role in fine-tuning, as the pretrained and downstream tasks are usually different. Although there exist many different designs for finetuning, a full understanding of when and why these algorithms work has been elusive. We analyze how the choice of task head controls feature adaptation and hence influences the downstream performance. By decomposing the learning dynamics of adaptation, we find that the key aspect is the training accuracy and loss at the beginning of finetuning, which determines the "energy" available for the feature's adaptation. We identify a significant trend in the effect of changes in this initial energy on the resulting features after fine-tuning. Specifically, as the energy increases, the Euclidean and cosine distances between the resulting and original features increase, while their dot products (and the resulting features' norm) first increase and then decrease. Inspired by this, we give several practical principles that lead to better downstream performance. We analytically prove this trend in an overparamterized linear setting and verify its applicability to different experimental settings.
Efficient Conditionally Invariant Representation Learning
Dec 16, 2022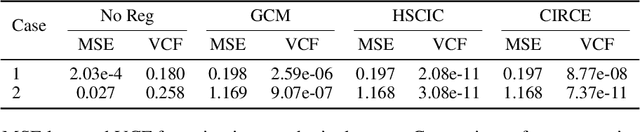
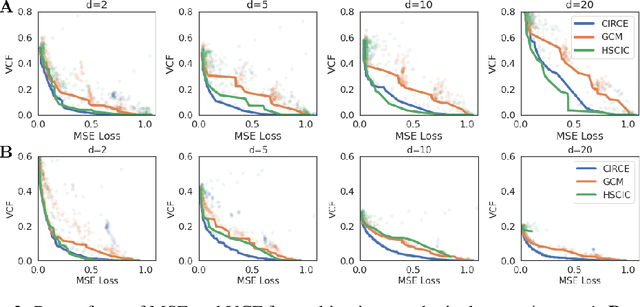

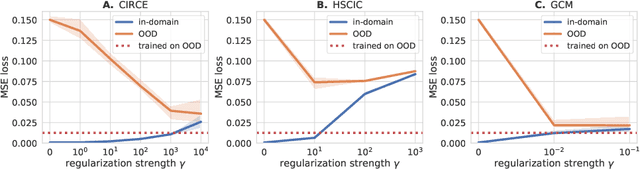
We introduce the Conditional Independence Regression CovariancE (CIRCE), a measure of conditional independence for multivariate continuous-valued variables. CIRCE applies as a regularizer in settings where we wish to learn neural features $\varphi(X)$ of data $X$ to estimate a target $Y$, while being conditionally independent of a distractor $Z$ given $Y$. Both $Z$ and $Y$ are assumed to be continuous-valued but relatively low dimensional, whereas $X$ and its features may be complex and high dimensional. Relevant settings include domain-invariant learning, fairness, and causal learning. The procedure requires just a single ridge regression from $Y$ to kernelized features of $Z$, which can be done in advance. It is then only necessary to enforce independence of $\varphi(X)$ from residuals of this regression, which is possible with attractive estimation properties and consistency guarantees. By contrast, earlier measures of conditional feature dependence require multiple regressions for each step of feature learning, resulting in more severe bias and variance, and greater computational cost. When sufficiently rich features are used, we establish that CIRCE is zero if and only if $\varphi(X) \perp \!\!\! \perp Z \mid Y$. In experiments, we show superior performance to previous methods on challenging benchmarks, including learning conditionally invariant image features.