 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJackie Kay
Recourse for reclamation: Chatting with generative language models
Mar 21, 2024
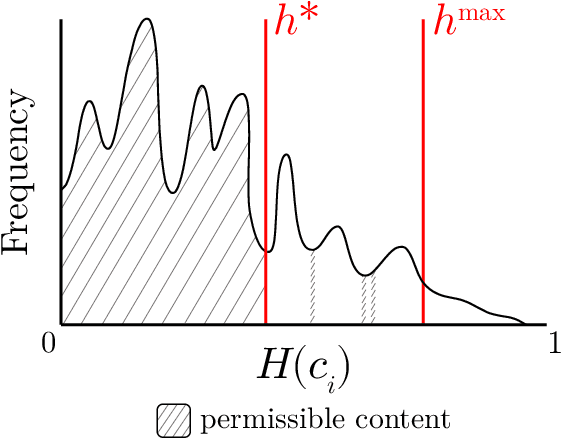
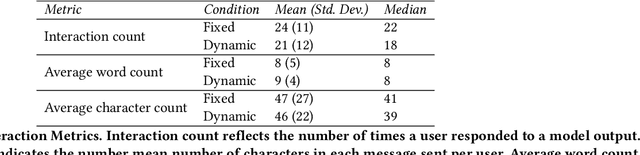
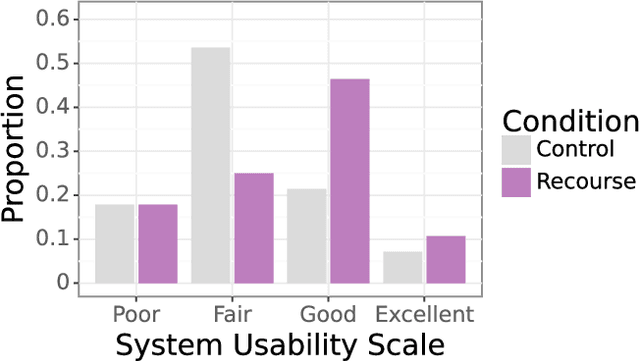

Researchers and developers increasingly rely on toxicity scoring to moderate generative language model outputs, in settings such as customer service, information retrieval, and content generation. However, toxicity scoring may render pertinent information inaccessible, rigidify or "value-lock" cultural norms, and prevent language reclamation processes, particularly for marginalized people. In this work, we extend the concept of algorithmic recourse to generative language models: we provide users a novel mechanism to achieve their desired prediction by dynamically setting thresholds for toxicity filtering. Users thereby exercise increased agency relative to interactions with the baseline system. A pilot study ($n = 30$) supports the potential of our proposed recourse mechanism, indicating improvements in usability compared to fixed-threshold toxicity-filtering of model outputs. Future work should explore the intersection of toxicity scoring, model controllability, user agency, and language reclamation processes -- particularly with regard to the bias that many communities encounter when interacting with generative language models.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Sociotechnical Safety Evaluation of Generative AI Systems
Oct 31, 2023Generative AI systems produce a range of risks. To ensure the safety of generative AI systems, these risks must be evaluated. In this paper, we make two main contributions toward establishing such evaluations. First, we propose a three-layered framework that takes a structured, sociotechnical approach to evaluating these risks. This framework encompasses capability evaluations, which are the main current approach to safety evaluation. It then reaches further by building on system safety principles, particularly the insight that context determines whether a given capability may cause harm. To account for relevant context, our framework adds human interaction and systemic impacts as additional layers of evaluation. Second, we survey the current state of safety evaluation of generative AI systems and create a repository of existing evaluations. Three salient evaluation gaps emerge from this analysis. We propose ways forward to closing these gaps, outlining practical steps as well as roles and responsibilities for different actors. Sociotechnical safety evaluation is a tractable approach to the robust and comprehensive safety evaluation of generative AI systems.
Queer In AI: A Case Study in Community-Led Participatory AI
Apr 10, 2023
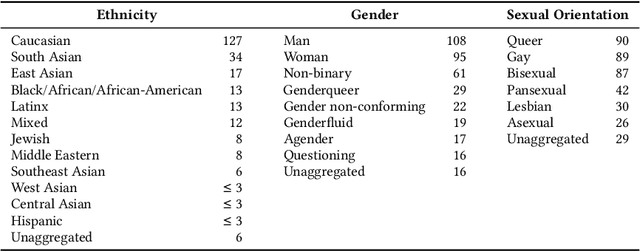
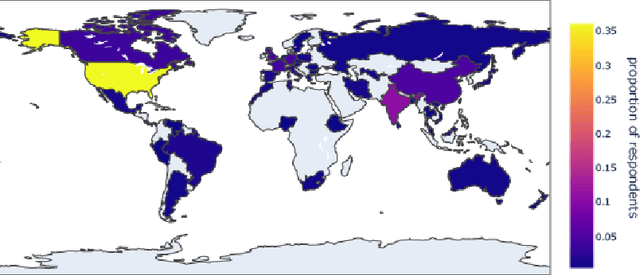

We present Queer in AI as a case study for community-led participatory design in AI. We examine how participatory design and intersectional tenets started and shaped this community's programs over the years. We discuss different challenges that emerged in the process, look at ways this organization has fallen short of operationalizing participatory and intersectional principles, and then assess the organization's impact. Queer in AI provides important lessons and insights for practitioners and theorists of participatory methods broadly through its rejection of hierarchy in favor of decentralization, success at building aid and programs by and for the queer community, and effort to change actors and institutions outside of the queer community. Finally, we theorize how communities like Queer in AI contribute to the participatory design in AI more broadly by fostering cultures of participation in AI, welcoming and empowering marginalized participants, critiquing poor or exploitative participatory practices, and bringing participation to institutions outside of individual research projects. Queer in AI's work serves as a case study of grassroots activism and participatory methods within AI, demonstrating the potential of community-led participatory methods and intersectional praxis, while also providing challenges, case studies, and nuanced insights to researchers developing and using participatory methods.
Finetuning from Offline Reinforcement Learning: Challenges, Trade-offs and Practical Solutions
Mar 30, 2023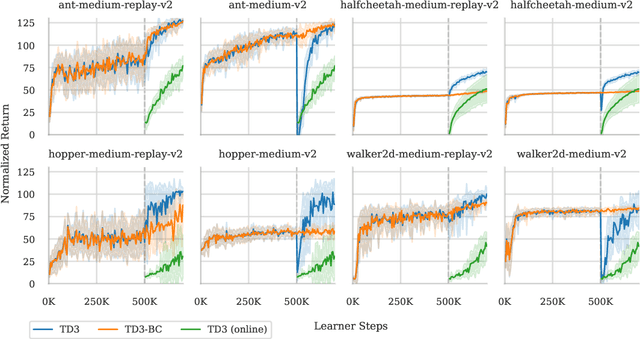
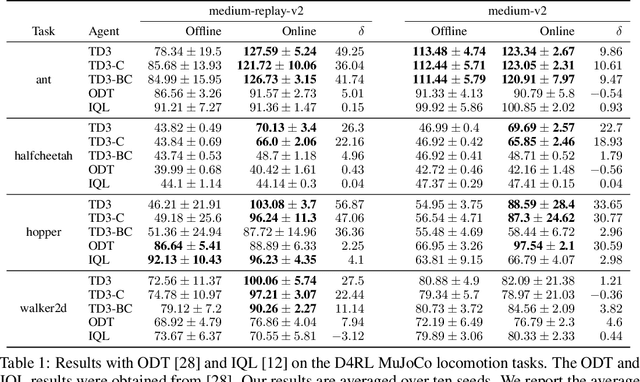
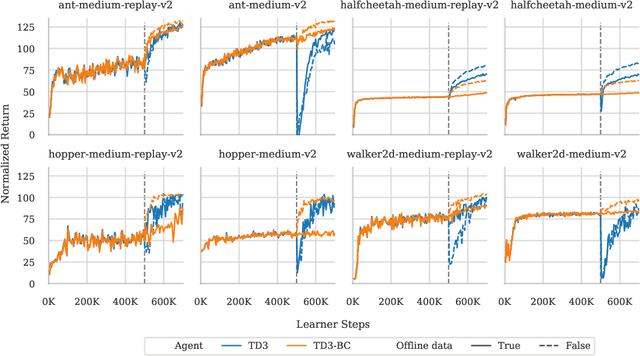
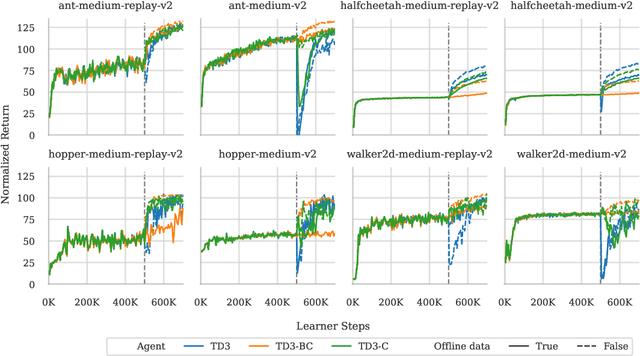
Offline reinforcement learning (RL) allows for the training of competent agents from offline datasets without any interaction with the environment. Online finetuning of such offline models can further improve performance. But how should we ideally finetune agents obtained from offline RL training? While offline RL algorithms can in principle be used for finetuning, in practice, their online performance improves slowly. In contrast, we show that it is possible to use standard online off-policy algorithms for faster improvement. However, we find this approach may suffer from policy collapse, where the policy undergoes severe performance deterioration during initial online learning. We investigate the issue of policy collapse and how it relates to data diversity, algorithm choices and online replay distribution. Based on these insights, we propose a conservative policy optimization procedure that can achieve stable and sample-efficient online learning from offline pretraining.
Subverting machines, fluctuating identities: Re-learning human categorization
May 27, 2022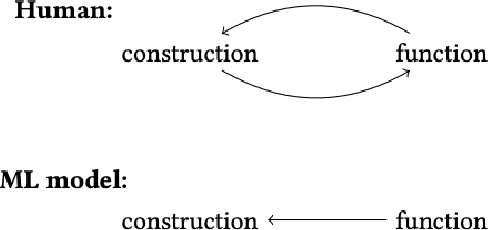
Most machine learning systems that interact with humans construct some notion of a person's "identity," yet the default paradigm in AI research envisions identity with essential attributes that are discrete and static. In stark contrast, strands of thought within critical theory present a conception of identity as malleable and constructed entirely through interaction; a doing rather than a being. In this work, we distill some of these ideas for machine learning practitioners and introduce a theory of identity as autopoiesis, circular processes of formation and function. We argue that the default paradigm of identity used by the field immobilizes existing identity categories and the power differentials that co$\unicode{x2010}$occur, due to the absence of iterative feedback to our models. This includes a critique of emergent AI fairness practices that continue to impose the default paradigm. Finally, we apply our theory to sketch approaches to autopoietic identity through multilevel optimization and relational learning. While these ideas raise many open questions, we imagine the possibilities of machines that are capable of expressing human identity as a relationship perpetually in flux.
A Generalist Agent
May 19, 2022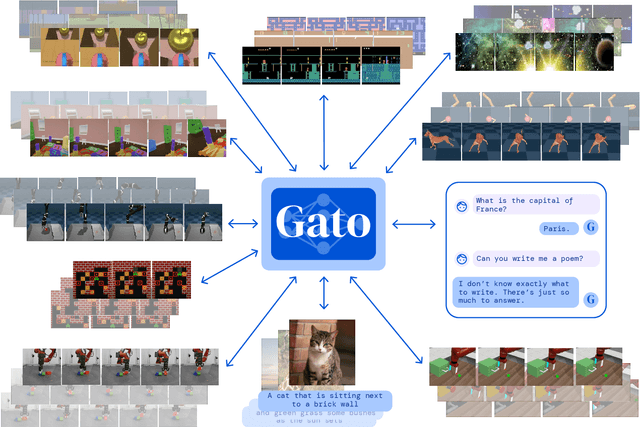
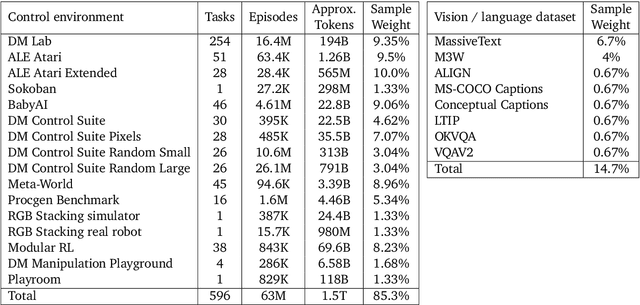
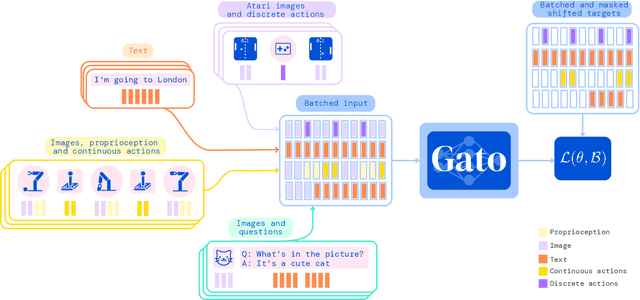

Inspired by progress in large-scale language modeling, we apply a similar approach towards building a single generalist agent beyond the realm of text outputs. The agent, which we refer to as Gato, works as a multi-modal, multi-task, multi-embodiment generalist policy. The same network with the same weights can play Atari, caption images, chat, stack blocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses, or other tokens. In this report we describe the model and the data, and document the current capabilities of Gato.
Few-Shot Keypoint Detection as Task Adaptation via Latent Embeddings
Dec 13, 2021
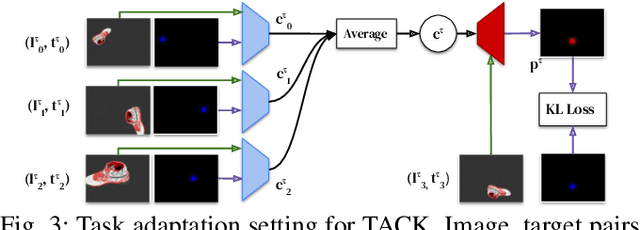
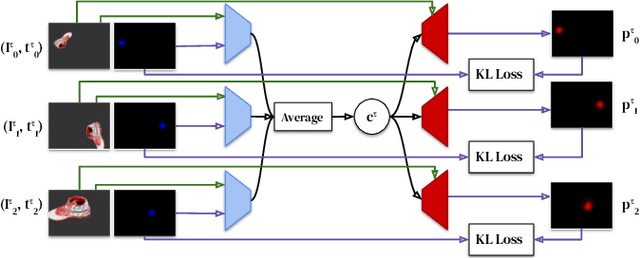
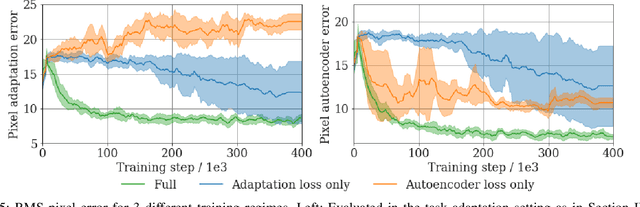
Dense object tracking, the ability to localize specific object points with pixel-level accuracy, is an important computer vision task with numerous downstream applications in robotics. Existing approaches either compute dense keypoint embeddings in a single forward pass, meaning the model is trained to track everything at once, or allocate their full capacity to a sparse predefined set of points, trading generality for accuracy. In this paper we explore a middle ground based on the observation that the number of relevant points at a given time are typically relatively few, e.g. grasp points on a target object. Our main contribution is a novel architecture, inspired by few-shot task adaptation, which allows a sparse-style network to condition on a keypoint embedding that indicates which point to track. Our central finding is that this approach provides the generality of dense-embedding models, while offering accuracy significantly closer to sparse-keypoint approaches. We present results illustrating this capacity vs. accuracy trade-off, and demonstrate the ability to zero-shot transfer to new object instances (within-class) using a real-robot pick-and-place task.
Fairness for Unobserved Characteristics: Insights from Technological Impacts on Queer Communities
Feb 09, 2021Advances in algorithmic fairness have largely omitted sexual orientation and gender identity. We explore queer concerns in privacy, censorship, language, online safety, health, and employment to study the positive and negative effects of artificial intelligence on queer communities. These issues underscore the need for new directions in fairness research that take into account a multiplicity of considerations, from privacy preservation, context sensitivity and process fairness, to an awareness of sociotechnical impact and the increasingly important role of inclusive and participatory research processes. Most current approaches for algorithmic fairness assume that the target characteristics for fairness--frequently, race and legal gender--can be observed or recorded. Sexual orientation and gender identity are prototypical instances of unobserved characteristics, which are frequently missing, unknown or fundamentally unmeasurable. This paper highlights the importance of developing new approaches for algorithmic fairness that break away from the prevailing assumption of observed characteristics.
Learning Dexterous Manipulation from Suboptimal Experts
Oct 16, 2020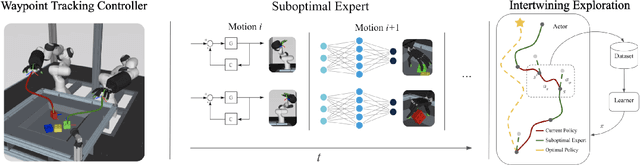
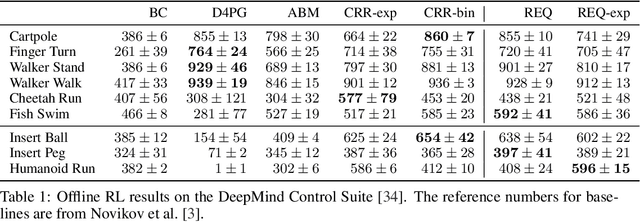

Learning dexterous manipulation in high-dimensional state-action spaces is an important open challenge with exploration presenting a major bottleneck. Although in many cases the learning process could be guided by demonstrations or other suboptimal experts, current RL algorithms for continuous action spaces often fail to effectively utilize combinations of highly off-policy expert data and on-policy exploration data. As a solution, we introduce Relative Entropy Q-Learning (REQ), a simple policy iteration algorithm that combines ideas from successful offline and conventional RL algorithms. It represents the optimal policy via importance sampling from a learned prior and is well-suited to take advantage of mixed data distributions. We demonstrate experimentally that REQ outperforms several strong baselines on robotic manipulation tasks for which suboptimal experts are available. We show how suboptimal experts can be constructed effectively by composing simple waypoint tracking controllers, and we also show how learned primitives can be combined with waypoint controllers to obtain reference behaviors to bootstrap a complex manipulation task on a simulated bimanual robot with human-like hands. Finally, we show that REQ is also effective for general off-policy RL, offline RL, and RL from demonstrations. Videos and further materials are available at sites.google.com/view/rlfse.