 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatthieu Geist
Leveraging Procedural Generation for Learning Autonomous Peg-in-Hole Assembly in Space
May 02, 2024
The ability to autonomously assemble structures is crucial for the development of future space infrastructure. However, the unpredictable conditions of space pose significant challenges for robotic systems, necessitating the development of advanced learning techniques to enable autonomous assembly. In this study, we present a novel approach for learning autonomous peg-in-hole assembly in the context of space robotics. Our focus is on enhancing the generalization and adaptability of autonomous systems through deep reinforcement learning. By integrating procedural generation and domain randomization, we train agents in a highly parallelized simulation environment across a spectrum of diverse scenarios with the aim of acquiring a robust policy. The proposed approach is evaluated using three distinct reinforcement learning algorithms to investigate the trade-offs among various paradigms. We demonstrate the adaptability of our agents to novel scenarios and assembly sequences while emphasizing the potential of leveraging advanced simulation techniques for robot learning in space. Our findings set the stage for future advancements in intelligent robotic systems capable of supporting ambitious space missions and infrastructure development beyond Earth.
Population-aware Online Mirror Descent for Mean-Field Games by Deep Reinforcement Learning
Mar 06, 2024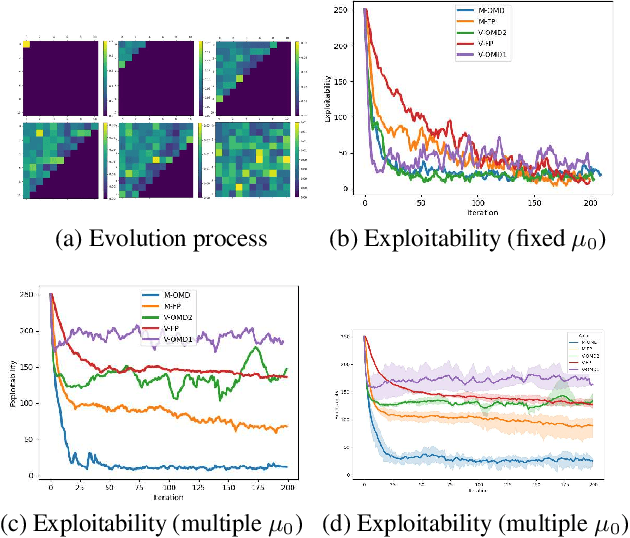
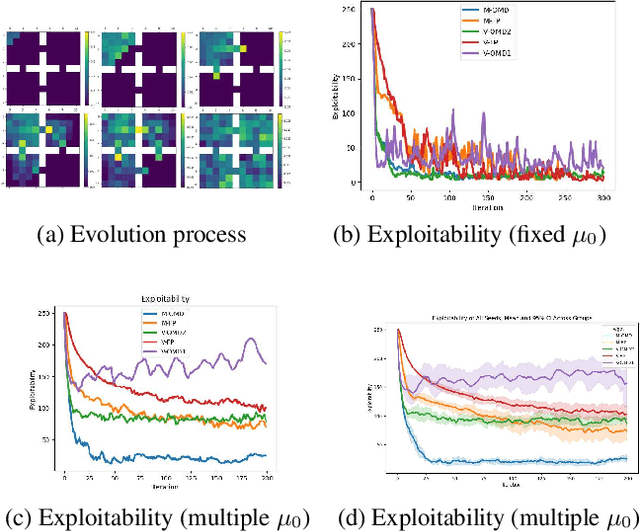
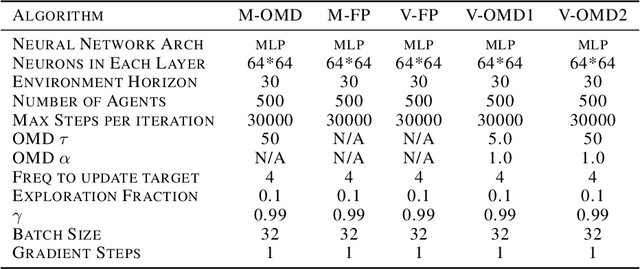
Mean Field Games (MFGs) have the ability to handle large-scale multi-agent systems, but learning Nash equilibria in MFGs remains a challenging task. In this paper, we propose a deep reinforcement learning (DRL) algorithm that achieves population-dependent Nash equilibrium without the need for averaging or sampling from history, inspired by Munchausen RL and Online Mirror Descent. Through the design of an additional inner-loop replay buffer, the agents can effectively learn to achieve Nash equilibrium from any distribution, mitigating catastrophic forgetting. The resulting policy can be applied to various initial distributions. Numerical experiments on four canonical examples demonstrate our algorithm has better convergence properties than SOTA algorithms, in particular a DRL version of Fictitious Play for population-dependent policies.
MusicRL: Aligning Music Generation to Human Preferences
Feb 06, 2024We propose MusicRL, the first music generation system finetuned from human feedback. Appreciation of text-to-music models is particularly subjective since the concept of musicality as well as the specific intention behind a caption are user-dependent (e.g. a caption such as "upbeat work-out music" can map to a retro guitar solo or a techno pop beat). Not only this makes supervised training of such models challenging, but it also calls for integrating continuous human feedback in their post-deployment finetuning. MusicRL is a pretrained autoregressive MusicLM (Agostinelli et al., 2023) model of discrete audio tokens finetuned with reinforcement learning to maximise sequence-level rewards. We design reward functions related specifically to text-adherence and audio quality with the help from selected raters, and use those to finetune MusicLM into MusicRL-R. We deploy MusicLM to users and collect a substantial dataset comprising 300,000 pairwise preferences. Using Reinforcement Learning from Human Feedback (RLHF), we train MusicRL-U, the first text-to-music model that incorporates human feedback at scale. Human evaluations show that both MusicRL-R and MusicRL-U are preferred to the baseline. Ultimately, MusicRL-RU combines the two approaches and results in the best model according to human raters. Ablation studies shed light on the musical attributes influencing human preferences, indicating that text adherence and quality only account for a part of it. This underscores the prevalence of subjectivity in musical appreciation and calls for further involvement of human listeners in the finetuning of music generation models.
Closing the Gap between TD Learning and Supervised Learning -- A Generalisation Point of View
Jan 20, 2024Some reinforcement learning (RL) algorithms can stitch pieces of experience to solve a task never seen before during training. This oft-sought property is one of the few ways in which RL methods based on dynamic-programming differ from RL methods based on supervised-learning (SL). Yet, certain RL methods based on off-the-shelf SL algorithms achieve excellent results without an explicit mechanism for stitching; it remains unclear whether those methods forgo this important stitching property. This paper studies this question for the problems of achieving a target goal state and achieving a target return value. Our main result is to show that the stitching property corresponds to a form of combinatorial generalization: after training on a distribution of (state, goal) pairs, one would like to evaluate on (state, goal) pairs not seen together in the training data. Our analysis shows that this sort of generalization is different from i.i.d. generalization. This connection between stitching and generalisation reveals why we should not expect SL-based RL methods to perform stitching, even in the limit of large datasets and models. Based on this analysis, we construct new datasets to explicitly test for this property, revealing that SL-based methods lack this stitching property and hence fail to perform combinatorial generalization. Nonetheless, the connection between stitching and combinatorial generalisation also suggests a simple remedy for improving generalisation in SL: data augmentation. We propose a temporal data augmentation and demonstrate that adding it to SL-based methods enables them to successfully complete tasks not seen together during training. On a high level, this connection illustrates the importance of combinatorial generalization for data efficiency in time-series data beyond tasks beyond RL, like audio, video, or text.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Learning Discrete-Time Major-Minor Mean Field Games
Dec 17, 2023Recent techniques based on Mean Field Games (MFGs) allow the scalable analysis of multi-player games with many similar, rational agents. However, standard MFGs remain limited to homogeneous players that weakly influence each other, and cannot model major players that strongly influence other players, severely limiting the class of problems that can be handled. We propose a novel discrete time version of major-minor MFGs (M3FGs), along with a learning algorithm based on fictitious play and partitioning the probability simplex. Importantly, M3FGs generalize MFGs with common noise and can handle not only random exogeneous environment states but also major players. A key challenge is that the mean field is stochastic and not deterministic as in standard MFGs. Our theoretical investigation verifies both the M3FG model and its algorithmic solution, showing firstly the well-posedness of the M3FG model starting from a finite game of interest, and secondly convergence and approximation guarantees of the fictitious play algorithm. Then, we empirically verify the obtained theoretical results, ablating some of the theoretical assumptions made, and show successful equilibrium learning in three example problems. Overall, we establish a learning framework for a novel and broad class of tractable games.
Nash Learning from Human Feedback
Dec 06, 2023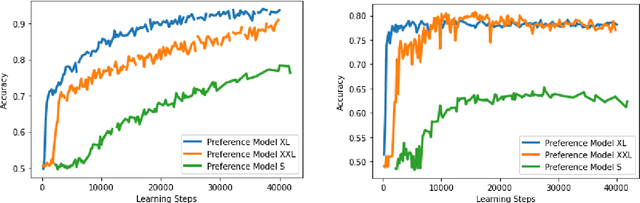
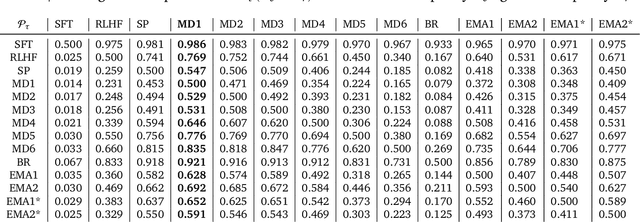
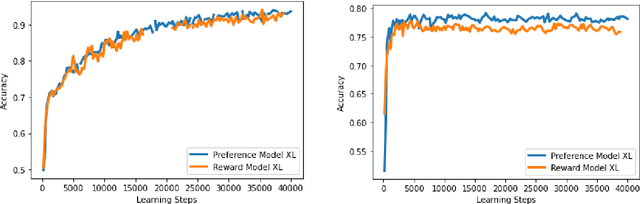
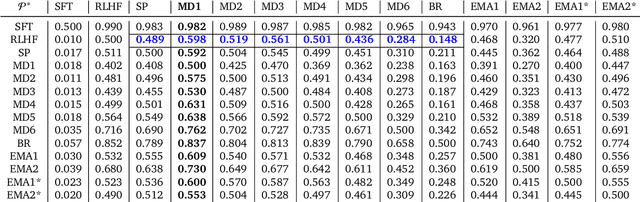
Reinforcement learning from human feedback (RLHF) has emerged as the main paradigm for aligning large language models (LLMs) with human preferences. Typically, RLHF involves the initial step of learning a reward model from human feedback, often expressed as preferences between pairs of text generations produced by a pre-trained LLM. Subsequently, the LLM's policy is fine-tuned by optimizing it to maximize the reward model through a reinforcement learning algorithm. However, an inherent limitation of current reward models is their inability to fully represent the richness of human preferences and their dependency on the sampling distribution. In this study, we introduce an alternative pipeline for the fine-tuning of LLMs using pairwise human feedback. Our approach entails the initial learning of a preference model, which is conditioned on two inputs given a prompt, followed by the pursuit of a policy that consistently generates responses preferred over those generated by any competing policy, thus defining the Nash equilibrium of this preference model. We term this approach Nash learning from human feedback (NLHF). In the context of a tabular policy representation, we present a novel algorithmic solution, Nash-MD, founded on the principles of mirror descent. This algorithm produces a sequence of policies, with the last iteration converging to the regularized Nash equilibrium. Additionally, we explore parametric representations of policies and introduce gradient descent algorithms for deep-learning architectures. To demonstrate the effectiveness of our approach, we present experimental results involving the fine-tuning of a LLM for a text summarization task. We believe NLHF offers a compelling avenue for preference learning and policy optimization with the potential of advancing the field of aligning LLMs with human preferences.
A Survey of Temporal Credit Assignment in Deep Reinforcement Learning
Dec 02, 2023The Credit Assignment Problem (CAP) refers to the longstanding challenge of Reinforcement Learning (RL) agents to associate actions with their long-term consequences. Solving the CAP is a crucial step towards the successful deployment of RL in the real world since most decision problems provide feedback that is noisy, delayed, and with little or no information about the causes. These conditions make it hard to distinguish serendipitous outcomes from those caused by informed decision-making. However, the mathematical nature of credit and the CAP remains poorly understood and defined. In this survey, we review the state of the art of Temporal Credit Assignment (CA) in deep RL. We propose a unifying formalism for credit that enables equitable comparisons of state of the art algorithms and improves our understanding of the trade-offs between the various methods. We cast the CAP as the problem of learning the influence of an action over an outcome from a finite amount of experience. We discuss the challenges posed by delayed effects, transpositions, and a lack of action influence, and analyse how existing methods aim to address them. Finally, we survey the protocols to evaluate a credit assignment method, and suggest ways to diagnoses the sources of struggle for different credit assignment methods. Overall, this survey provides an overview of the field for new-entry practitioners and researchers, it offers a coherent perspective for scholars looking to expedite the starting stages of a new study on the CAP, and it suggests potential directions for future research
DRIFT: Deep Reinforcement Learning for Intelligent Floating Platforms Trajectories
Oct 06, 2023This investigation introduces a novel deep reinforcement learning-based suite to control floating platforms in both simulated and real-world environments. Floating platforms serve as versatile test-beds to emulate microgravity environments on Earth. Our approach addresses the system and environmental uncertainties in controlling such platforms by training policies capable of precise maneuvers amid dynamic and unpredictable conditions. Leveraging state-of-the-art deep reinforcement learning techniques, our suite achieves robustness, adaptability, and good transferability from simulation to reality. Our Deep Reinforcement Learning (DRL) framework provides advantages such as fast training times, large-scale testing capabilities, rich visualization options, and ROS bindings for integration with real-world robotic systems. Beyond policy development, our suite provides a comprehensive platform for researchers, offering open-access at https://github.com/elharirymatteo/RANS/tree/ICRA24.
Offline Reinforcement Learning with On-Policy Q-Function Regularization
Jul 25, 2023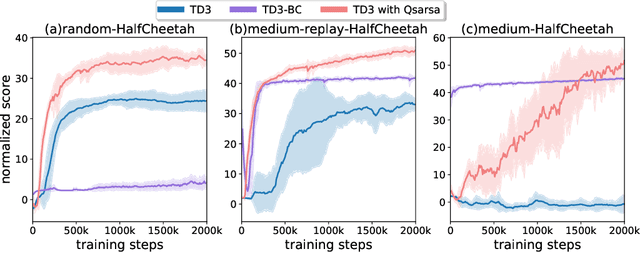
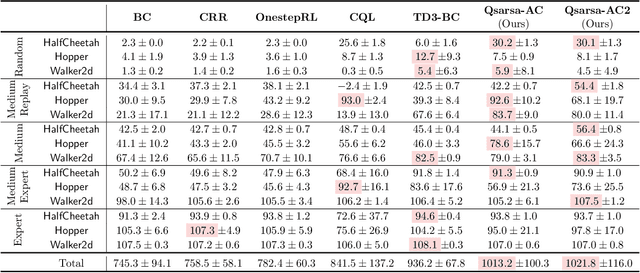
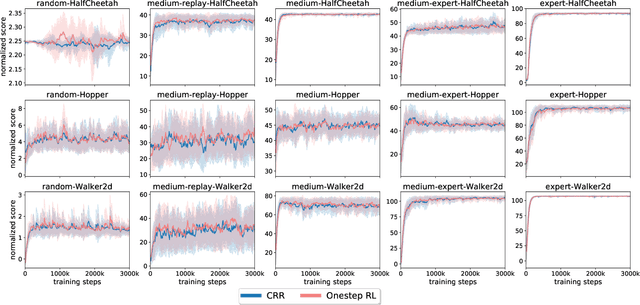
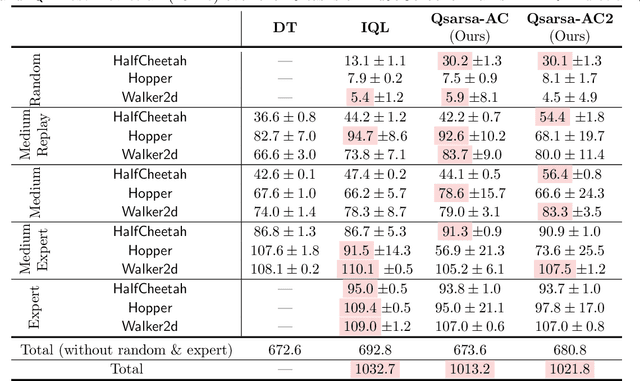
The core challenge of offline reinforcement learning (RL) is dealing with the (potentially catastrophic) extrapolation error induced by the distribution shift between the history dataset and the desired policy. A large portion of prior work tackles this challenge by implicitly/explicitly regularizing the learning policy towards the behavior policy, which is hard to estimate reliably in practice. In this work, we propose to regularize towards the Q-function of the behavior policy instead of the behavior policy itself, under the premise that the Q-function can be estimated more reliably and easily by a SARSA-style estimate and handles the extrapolation error more straightforwardly. We propose two algorithms taking advantage of the estimated Q-function through regularizations, and demonstrate they exhibit strong performance on the D4RL benchmarks.